
Inspiration
Super bacteria and cancer cells spread faster than we can study. Cells reproduce too slowly, so wanted to create an ideal simulation of cell mitosis to predict the evolution of these harmful, unicellular organisms. If these simulations can mimic results of real research, this SNPS can forecast the invasiveness of these cells and give farmers and patients an opportunity to control their futures.
What it does
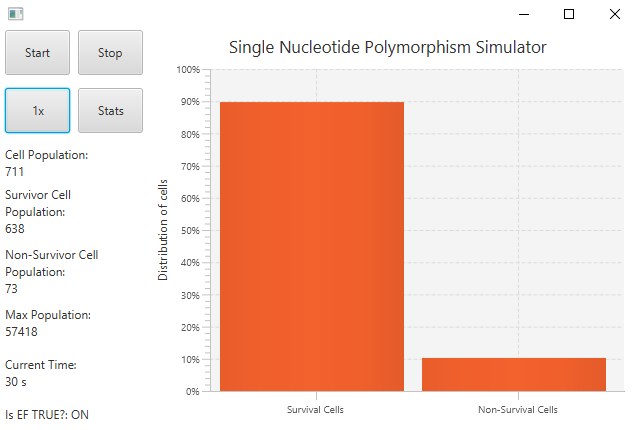
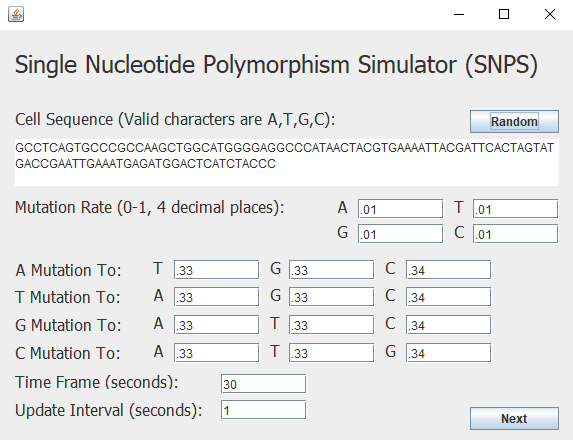
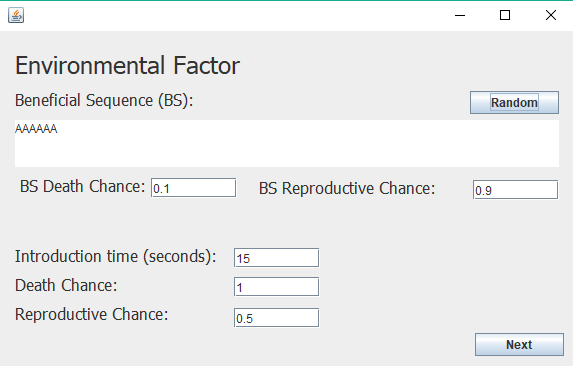
The user inputs an initial cell to be "cultured". This cell has a unique sequence of nucleotides "A,C,T, and G". Each of these "letters" have a chance to mutate, a probability set by the user based off of research data. The user will also be able to set an interval of reproduction. Eventually, an isolated environmental factor (something that affects the growth of cells, such as heat, pH levels, or pesticides) will be introduced by the user with custom parameters which include an adjusted cell reproduction rate, a new cell death rate, and most importantly, a specific "beneficial sequence" that would allow the cell to better survive in this environment if it contains the sequence in its DNA (evolutionary advantage). Cells with this beneficial sequence have better reproduction and low-deaths rates. They will pass on this beneficial sequence to their progeny, as other cells die out. This is where evolution is beautifully simulated.
An animated graph will be visualizing the population growth and the ratio of cells with the beneficial sequence to those who don't in real time. At the end of the simulation, a statistics page will show end results and useful stats.
How we built it
We chose to stay simple and use only Java. We created a GUI and a graphical animation using basic Java libraries and methods. Though our tools sound sparse, the code is huge, professional and clean, and the final product looks fantastic.
Challenges we ran into
Real life cell sequences are quite long. Human DNA has about 6 billion "letters" of code. Imagine a 100,000 population of cells, each with 6 billion base pairs to record and manipulate. That may work on expensive computers, but we wanted our program to work for anyone ranging from curious to professional. Unfortunately, personal machines will slowly process the program if certain limits are passed. The programs works fine for presentation and understanding, but the data we put in will not be of the order of magnitude of actual lengths that we would ideally want.
We also had to downsize implementations. For the simulation to be ideal, we needed to implement infinitely many factors into the program. We can come close to infinity given a long time period, but we had to be realistic and plan for 36 hours worth of implementation. We are proud to say we got in more than everything that we felt was necessary for the program to be minimally complete. There is room for more implementations in the future.
Accomplishments that we're proud of
Our simulation does indeed generate sensible data that we craft and base off science. We attempted to cover every realistic factor with what our capabilities in programming allowed us to do. There aren't any holes or bugs that we push ed under the rug; everything works the way it should.
Our ability to work well together allowed us to conquer every programming obstacle we faced, and we enjoyed each other's company. We are proud of our ability to communicate and function as a team.
What we learned
We learned many new methods in Java, and how to be creative and efficient in creating algorithms. This project required a lot of clean code, a bunch of mathematics, and a background in Biomolecular studies.
What's next for Single Nucleotide Polymorphism Simulator (SNPS)
We want our program to be able to compute data from historical research, and see if our simulation can resemble actual results. With success, SNPS can be a valuable asset to biomedical and bio-molecular engineering field of studies. The future of genomics, pest control, cancer research, and bacterial evolution may become more accurate and efficient with data analysis and prediction using our simulation.
We need to create better algorithms that simplify computation so that we can reach the 6 million-long sequence of DNA goal. Even if we had a super computer that can compute what we input, our goal is to make this program accessible to anyone on any device.
After this hackathon, we plan to add on to our program and continue for ideality in simulation. Perhaps we can make the GUI more fancy and advanced as well. Also can add more options for the animated graph such as a pause button, snapshots, etc. Finally we can add to the stats page by allowing the user to browse through all of the living cells and each of their sequences. There would be a filter that brings up all cells with the beneficial sequence highlighted.



Log in or sign up for Devpost to join the conversation.