-
-
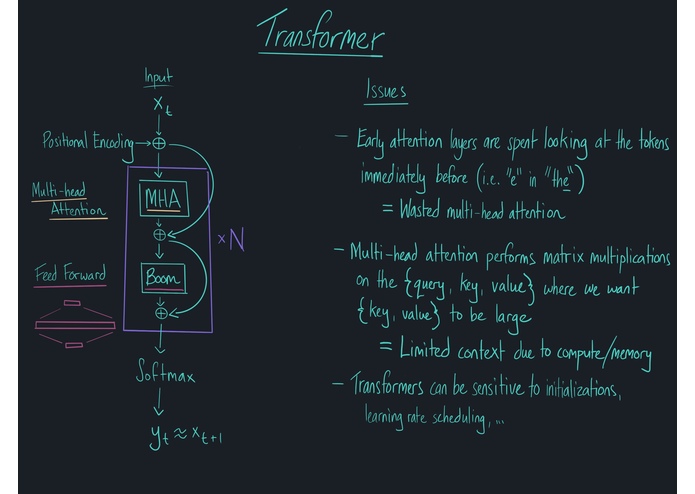
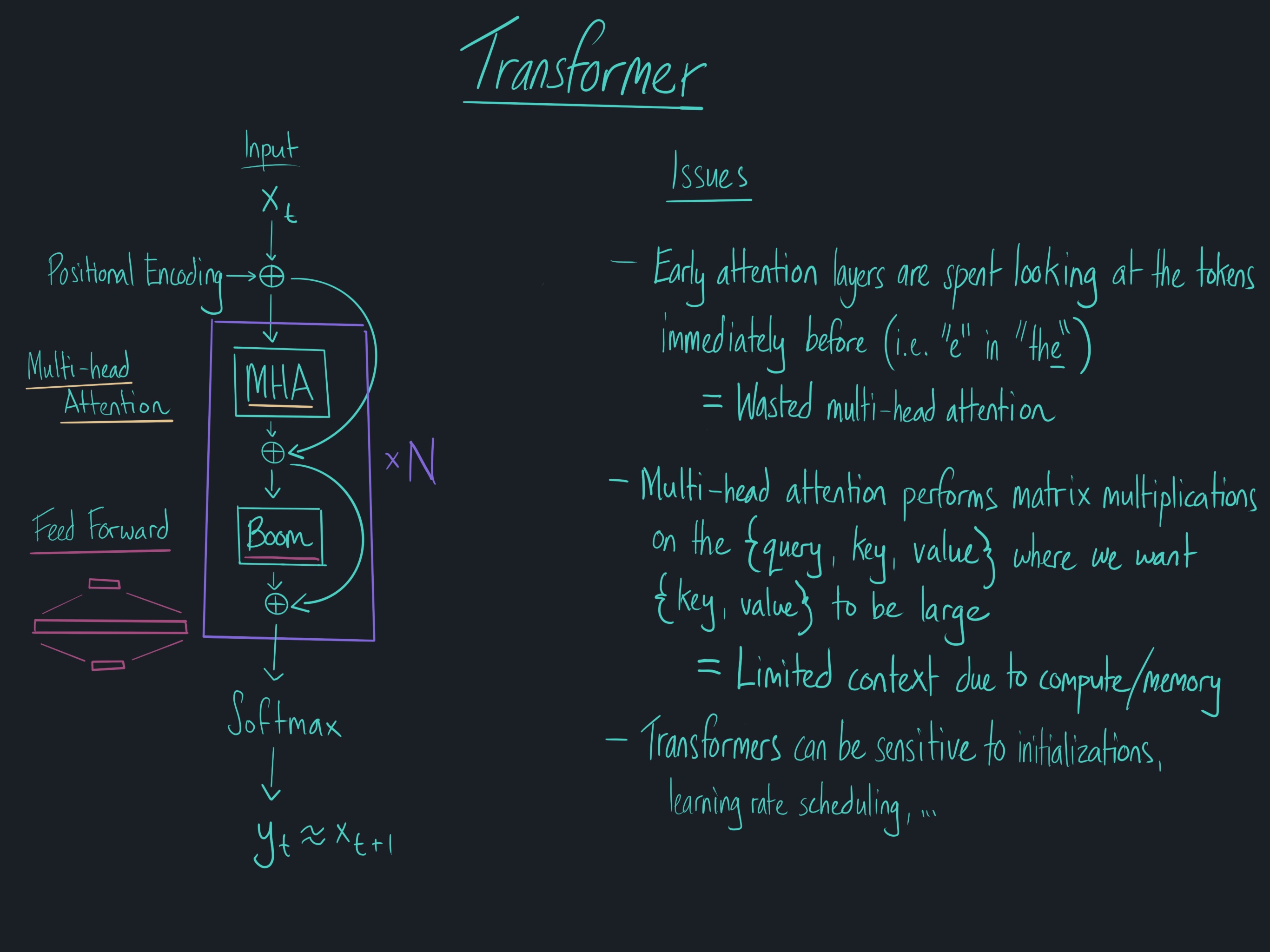
The issues with the Transformer model
-
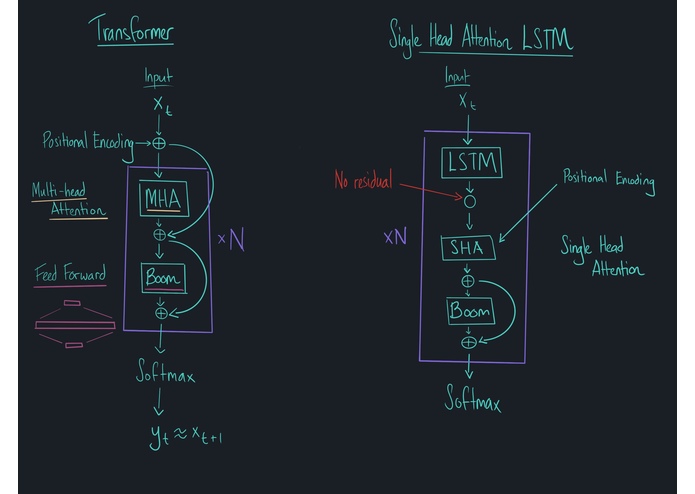
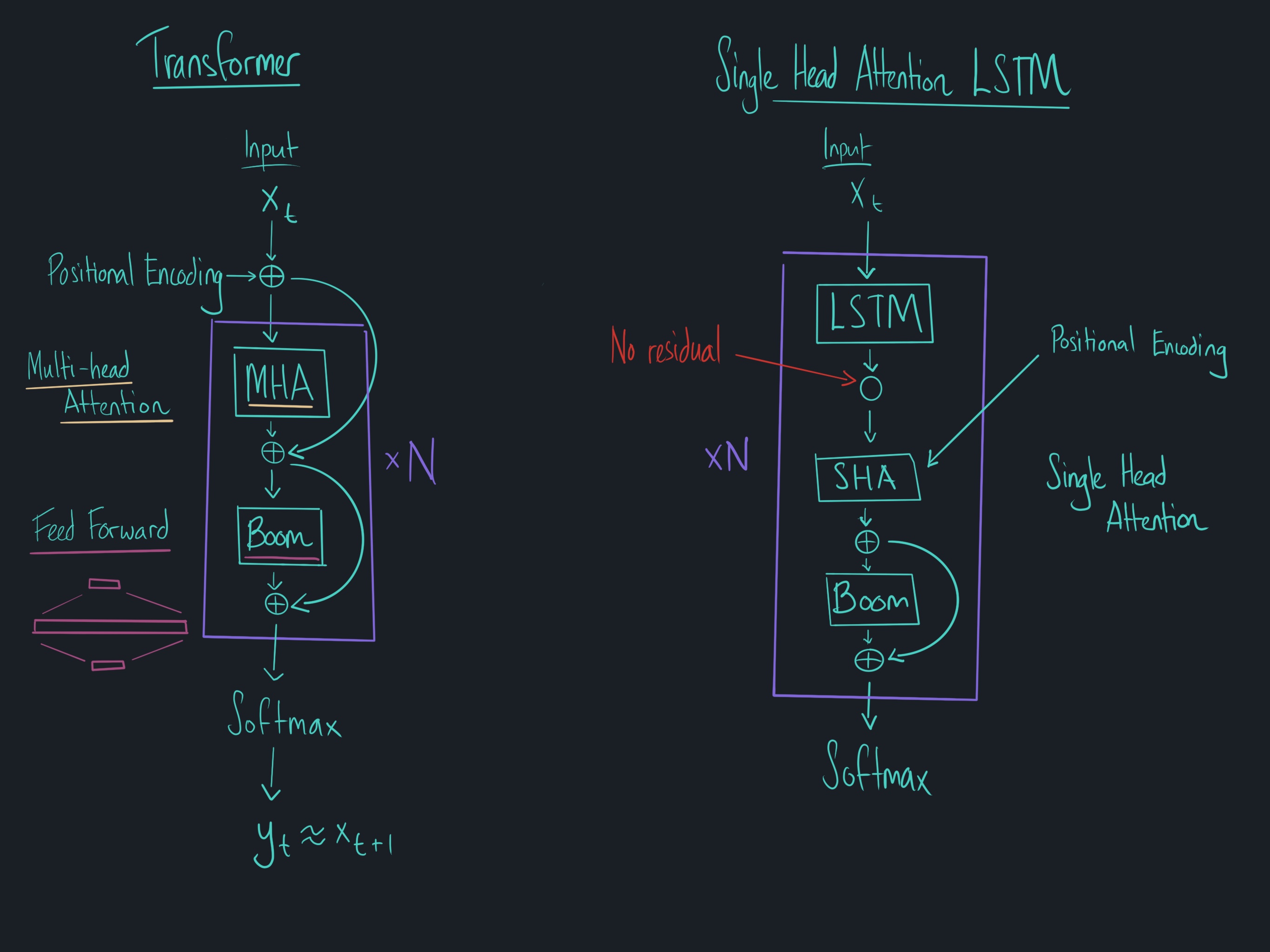
Comparing Transformer with Single Headed Attention LSTM
-
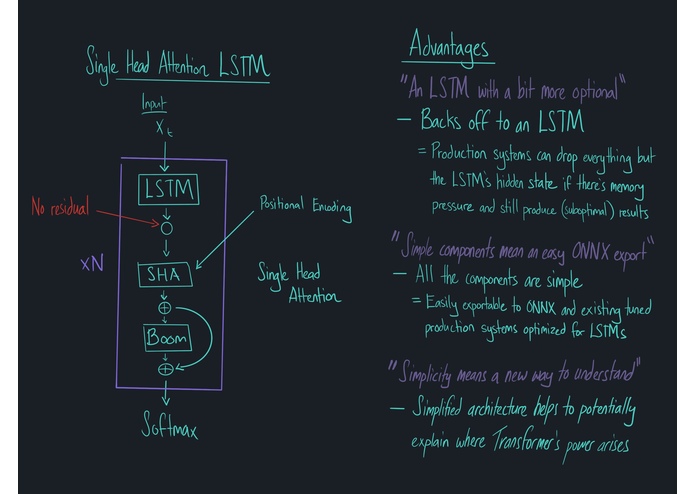
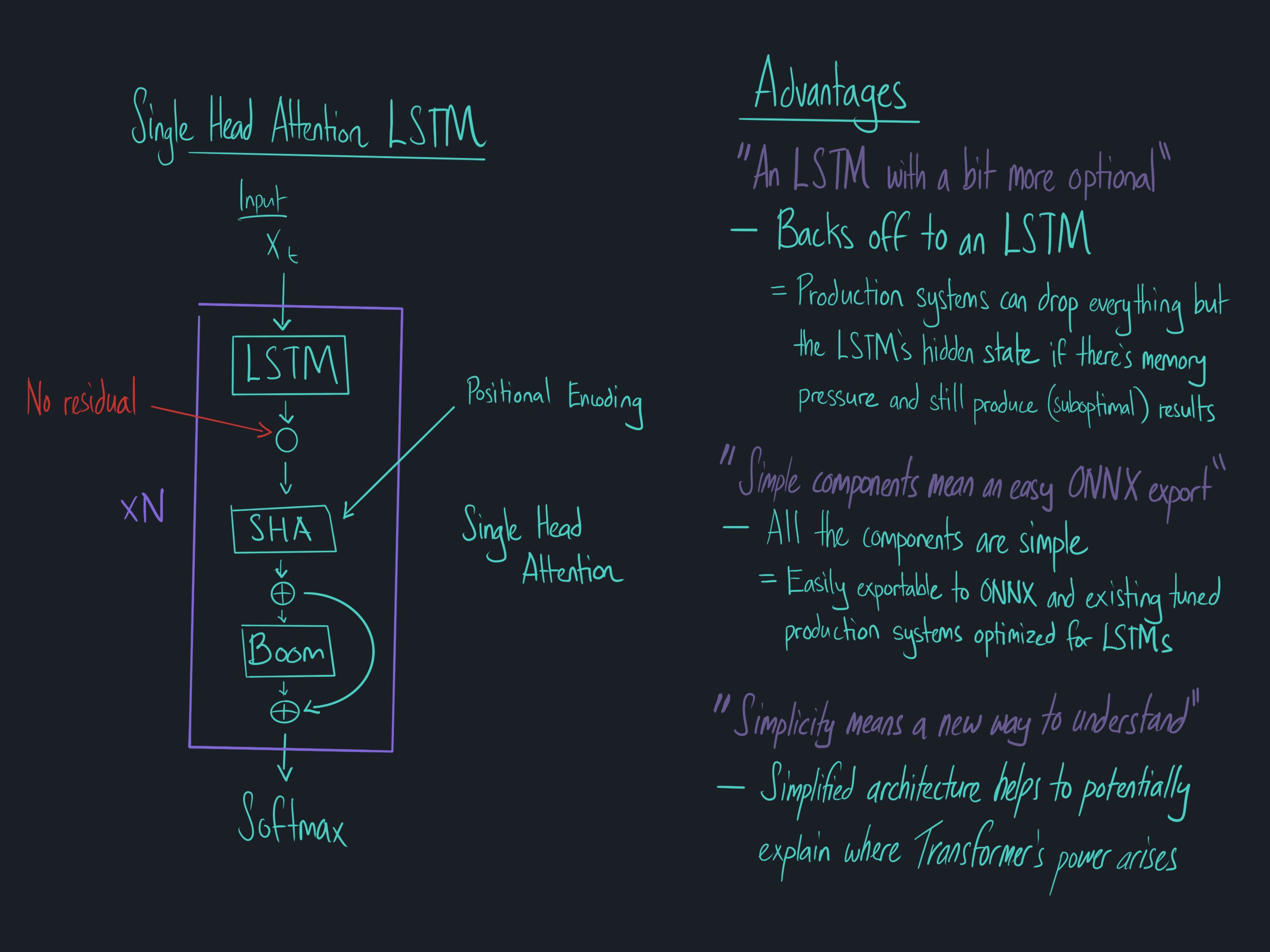
Advantages of the SHA-LSTM
Inspiration
For this work I had two primary questions:
- "What aspects of the Transformer are likely adding the most benefit?"
- "What are the simplest and fastest aspects of the Transformer architecture that could be grafted onto an LSTM to bring LSTM performance up to similar levels?"
This was motivated first to better understand and analyze aspects of the Transformer architecture as well as to encourage exploration of a broader space of neural architectures.
The resulting model is also a likely better fit for production systems, many of which use model distillation to convert a Transformer model down to a traditional LSTM, and has unique benefits of both the LSTM and Transformer model without the overheads of both.
What it does
In summary, "stop thinking with your (attention) head".
- Obtain strong results on a byte level language modeling dataset (enwik8) in under 24 hours on a single GPU (12GB Titan V)
- Support long range dependencies (up to 5000 tokens) without increasing compute time or memory usage substantially by using a simpler attention mechanism
- Avoid the fragile training process required by standard Transformer models such as a long warmup
- Back off toward a standard LSTM allowing you to drop retained memory states (needed for a Transformer model) if memory becomes a major constraint
- Provide a smaller model that features only standard components such as the LSTM, single headed attention, and feed-forward modules such that they can easily be productionized using existing optimized tools and exported to various formats (i.e. ONNX)
How I built it
The process was relatively simple:
- Start with a strong but outdated LSTM baseline
- Add in a single head of attention for each LSTM pass inspired more by computationally efficient approaches such as Merity et al's Pointer Sentinel Mixture Models and Grave et al's Continuous Cache (i.e. approaches that don't require matrix multiplications for each element in the history)
- Continue fine tuning both the model and training process until it achieved strong
Challenges I ran into
- Limited to a single GPU prevented traditional large scale hyperparameter search
- The LSTM requires a fairly large hidden state to work well whilst Transformer models are able to have an incredibly large implicit hidden state through their multi-head attention mechanisms
- Nvidia's Automatic Mixed Precision (AMP) for PyTorch gives massive speed gains but can produce complex issues (such as having to rewrite weight dropout code to handle the wrapped weight handling that AMP provides RNNs)
Accomplishments that I'm proud of
| Model | Test BPC | Params | LSTM Based |
|---|---|---|---|
| Krause mLSTM | 1.24 | 46M | ✔ |
| AWD-LSTM | 1.23 | 44M | ✔ |
| SHA-LSTM | 1.07 | 63M | ✔ |
| 12L Transformer-XL | 1.06 | 41M | |
| 18L Transformer-XL | 1.03 | 88M | |
| Adaptive Span Transformer (Small) | 1.02 | 38M |
- The previous best reported number for LSTM based architectures on enwik8 was 1.23, whilst our best model reports 1.07, beating many Transformer based models in the past two years
- The model was trained in only 24 hours on a single GPU with the Adaptive Span Transformer (small) being the only recent Transformer model to achieve the same type of training efficiency
- Proof that even a single head of attention can provide competitive results when paired with a more powerful architecture, suggesting other approaches to neural architectures may exist that stray away from the standard multi-head attention seen in Transformers
- All the results obtained, including all runs of the model, used a single GPU and no hyperparameter search or complex initialization schemes
- A quite different architecture than the standard models being seen and used in language modeling
What I learned
- Multi-head attention architectures such as the many Transformer variants are still strongest but there is an unexplored and potentially valuable research direction for many other neural architectures
- The implicit hidden state size of Transformer models still handily beat out the LSTM's explicit hidden state, though even a single head of attention can rapidly equalize that difference
- Custom CUDA is still more work than I had hoped for in recent versions and TorchScript provides strong building blocks but still has many edge cases
What's next for Single Headed Attention RNN
- Continuing to improve the training process, efficiency, and accuracy - all of which were limited by my using a single GPU and <24 hours for each run of this work
- Add in multi-head attention to see whether the gains seen in Transformer models will be applicable and whether this can increase the implicit hidden state of the LSTM similar to how it does for Transformers
- Improve the speed of the model through TorchScript and custom CUDA, neither of which are used currently






Log in or sign up for Devpost to join the conversation.