-
-
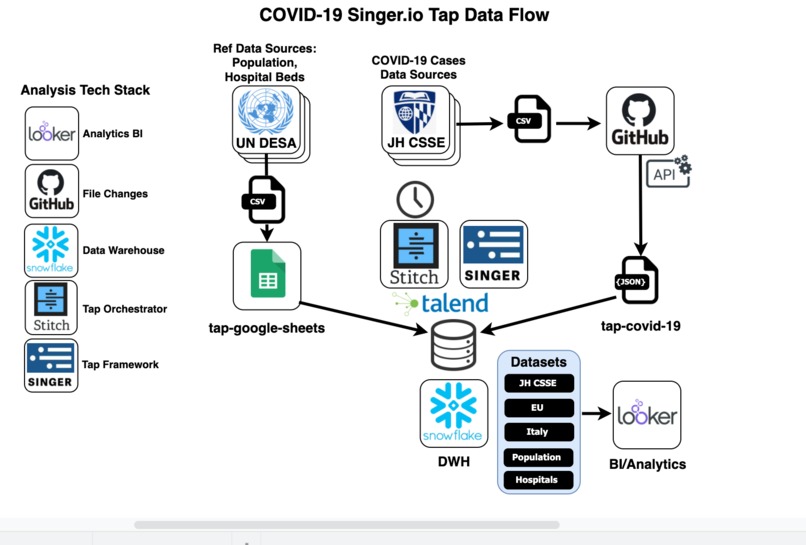
Dataflow diagram for the Singer COVID-19 tap

A GitHub Singer tap to help interested parties aggregate data from multiple sources in a more standardized format and move the data on a schedule into their preferred data warehouse/lake for further analysis.
Inspiration
A key challenge for all parties working on the COVID response worldwide has been the patchwork of data sources, from local health authorities, WHO, primary healthcare networks, state governments, etc. Most organizations originating the data have been keen to share their data-sets using .csv files hosted on GitHub, but the lack of uniformity is a challenge, and the data needs to be pulled into an analytics database daily to be useful.
We were also inspired by how quickly some groups published educational visualizations on the data around the spread of the virus, and wanted to empower many more people to have access to data they can trust, from multiple key sources in one standardized data warehouse.
What it does
In this effort we have built an open source data pipeline to allow data engineers and researchers pull the disparate sources together on a set schedule in a coherent format and structure.
In its first release, the Singer tap will give users access to the following data-sets: • Johns Hopkins CSSE: Daily Report • European Union: Daily Report • Italian Center for Systems Science & Engineering: National, Regional, Provincial Reports • The New York Times: US State & County Reports • The COVID Tracking Project: US State Daily Reports, KFF Hospital Beds, US Census Population • Neher Lab, Center of Computational Biology: Case Counts, Country Codes, Population
How we built it
Jeff Huth (@Bytecode) and Thomas Bennett (@Talend) have been collaborating with many contributors from the Singer community to build a ‘tap’ to ingest data from the various COVID sources (typically .csv files hosted on GitHub).
By building this using the Singer.io open source protocols, we are making this capability available to anybody who can run Python on their computer, using the free SINGER engine. In addition, users can run the integration for free on the StitchData.com hosted service to bring the data-sets into the most popular data warehouses or data lakes (AWS Redshift, AWS S3, Microsoft Azure SQL, Delta Lake, Google BigQuery, Data.World, Panoply, Snowflake or PostgeSQL).
Accomplishments that we're proud of
The teamwork around this project was fantastic, securing resources from Bytecode and Talend, along with executive commitment for more resources. The Singer community has also being a big contributing factor in bringing this project together and we expect more development from the community going forwards as we implement more data sources.
What's next for Singer COVID-19 open source Tap
In next steps, Talend will be running this data pipeline into a publicly accessible data warehouse and will be offering its full suite of data integration solutions to organizations on the front line of COVID research. Having access to such a data warehouse with aggregated data in a standardized format will allow even the smallest of research teams or individual data scientists to run their own analyses or visualizations.
Further information
The tap-covid-19 sourcecode can be found at https://github.com/singer-io/tap-covid-19 A slide presentation on the project can be found at https://drive.google.com/open?id=1AgoFe9S1pa8D7GWZLlrYAlkUNW03G4d3_HOkUgd_qns
Built With
- python
- singer
- stitch
- talend








Log in or sign up for Devpost to join the conversation.