-
-
SindhiSense
Inspiration
Sindhi is spoken by over 25 million people, yet it has almost no usable NLP infrastructure — no solid sentiment datasets, no pretrained classifiers, nothing close to what Urdu, Hindi, or English already have. As a Sindhi speaker and CS student, I wanted to close that gap myself instead of waiting for someone else to do it. Sentiment analysis felt like the right starting point, since it's a foundational task that other Sindhi NLP work (review mining, social media monitoring, opinion tracking for Sindhi media) can build on top of.
What it does
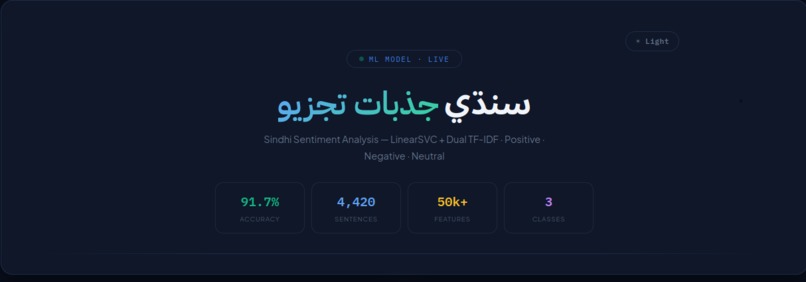
SindhiSense takes any Sindhi sentence and classifies it as positive, negative, or neutral. A user types or pastes Sindhi text into the web app, hits Analyze, and gets back the predicted sentiment. It's live as a Hugging Face Space, so anyone can try it without installing anything.
How I built it
The hardest part of this project was never the model — it was the data. There is no public, labeled Sindhi sentiment dataset, so I had to build one from scratch:
- Seed dataset: I started by extracting and semi-supervised pseudo-labeling text from Kawish and AwamiAwaz, two Sindhi newspaper corpora, producing an initial ~1,898 labeled sentences.
- Expansion pipeline: To grow that into a usable training size, I built a pipeline combining back-translation (round-tripping sentences through other languages to generate natural paraphrases) and LLM-based synthetic generation, taking the dataset to 4,400 labeled sentences.
- Modeling: The classifier uses a TF-IDF feature pipeline combining both character-level and word-level vectorizers, feeding into a classical ML classifier. This split matters a lot for Sindhi specifically — character n-grams help with the language's morphology and spelling variation, while word-level features capture broader semantic signal.
- Retraining: After expanding the dataset to 4,400 sentences, I retrained the model on the larger set and redeployed it.
- Deployment: The trained model is deployed as a Hugging Face Space with a simple web interface, with the model weights and dataset published publicly on Hugging Face so others can build on the work.
Challenges I ran into
One major bug surfaced during deployment: my app.py was loading the char-level and word-level TF-IDF vectorizers but stacking their output features in the wrong order relative to how the model was trained. This silently degraded predictions instead of throwing an error, which made it harder to catch. Fixing it meant carefully re-checking the exact feature order used at training time and matching it precisely in the inference code.
The bigger, non-technical challenge was data scarcity. There was no shortcut around the fact that almost no labeled Sindhi sentiment data exists anywhere — I had to build the entire pipeline myself, from raw newspaper text to a clean, labeled, and eventually expanded dataset.
Accomplishments that I'm proud of
- Built and published one of very few public, labeled Sindhi sentiment datasets, growing it from ~1,898 to 4,400 sentences through a back-translation + LLM-generation pipeline.
- Shipped a fully working, publicly accessible demo — not just a notebook.
- Did the entire data collection, labeling, expansion, modeling, debugging, and deployment pipeline solo.
What I learned
How much of "doing NLP for a low-resource language" is really data engineering, not modeling. I also got a lot more careful about debugging silent failure modes in ML pipelines — the TF-IDF feature-order bug taught me to be much stricter about preprocessing parity between training and inference.
What's next for SindhiSense
I'm currently extending this work into Sindhi Named Entity Recognition using mBERT, and exploring a dubbing/TTS pipeline for Sindhi-language film and media. The longer-term goal is a small but real NLP toolkit for Sindhi.
Built With
- huggingface-hub
- huggingface-spaces
- natural-language-processing
- pandas
- python
- scikit-learn
- tf-idf

Log in or sign up for Devpost to join the conversation.