-
-

-
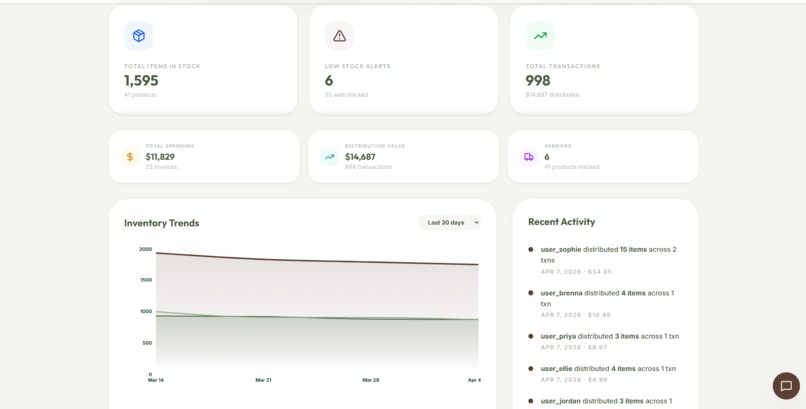
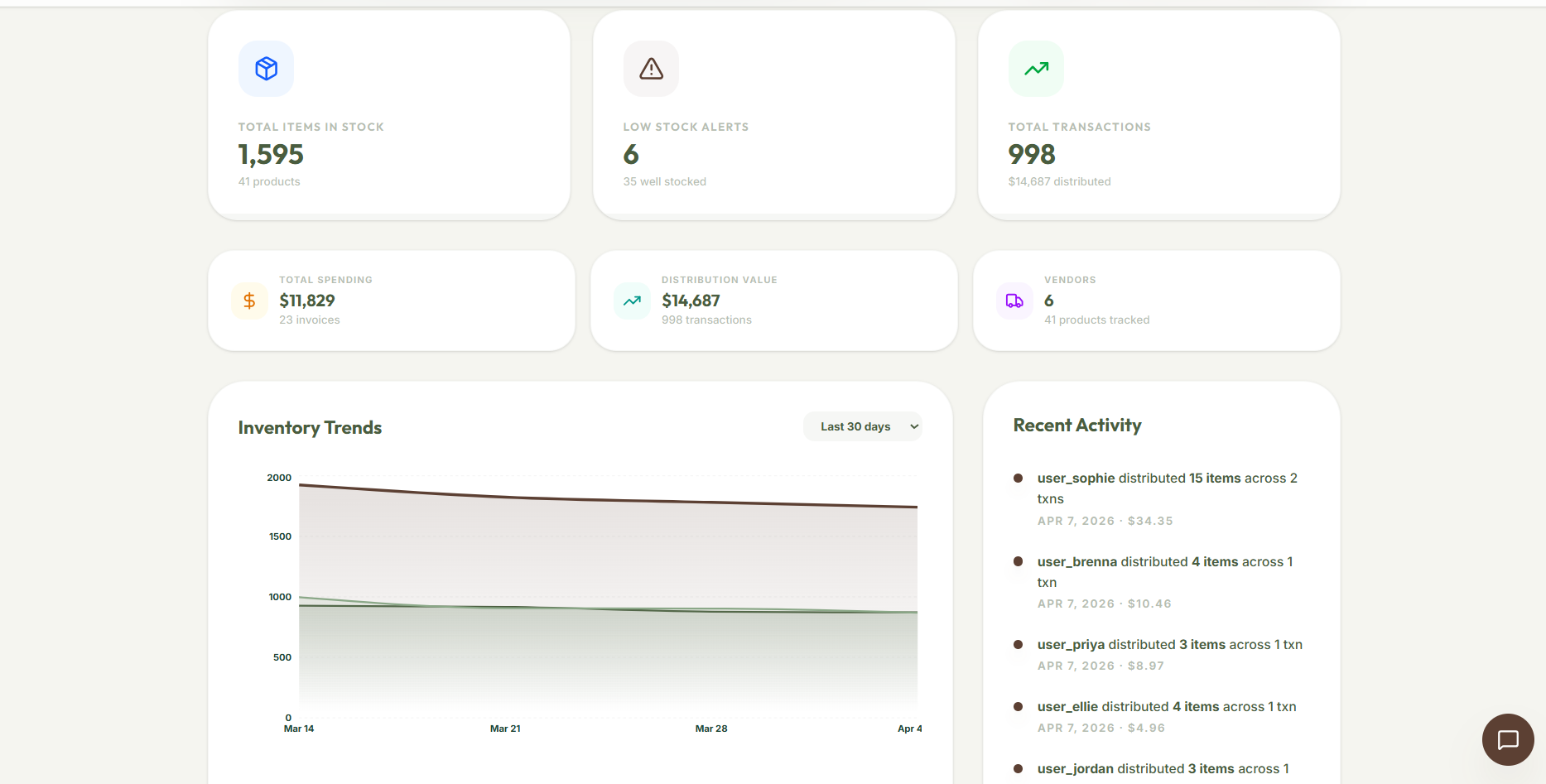
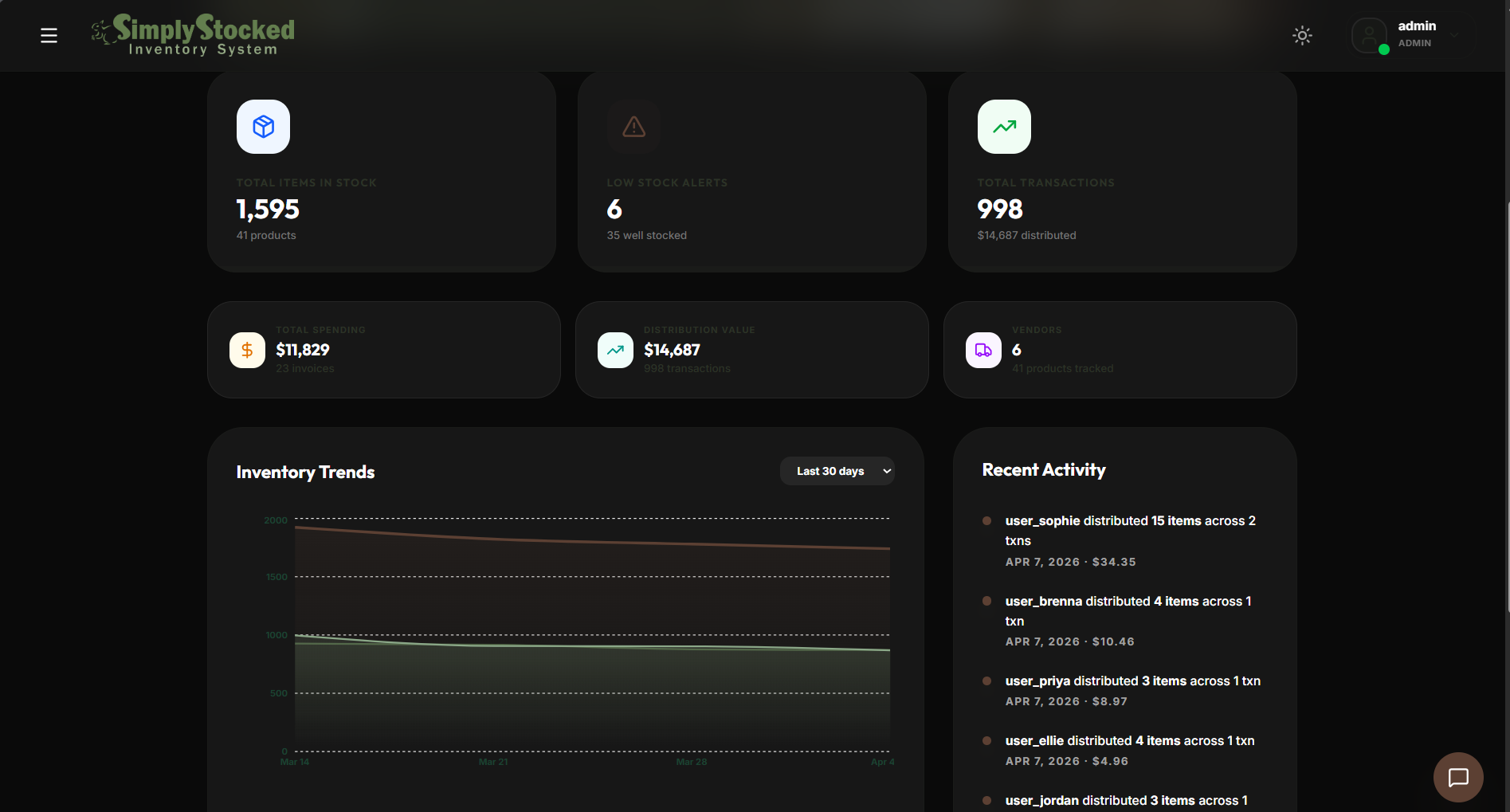
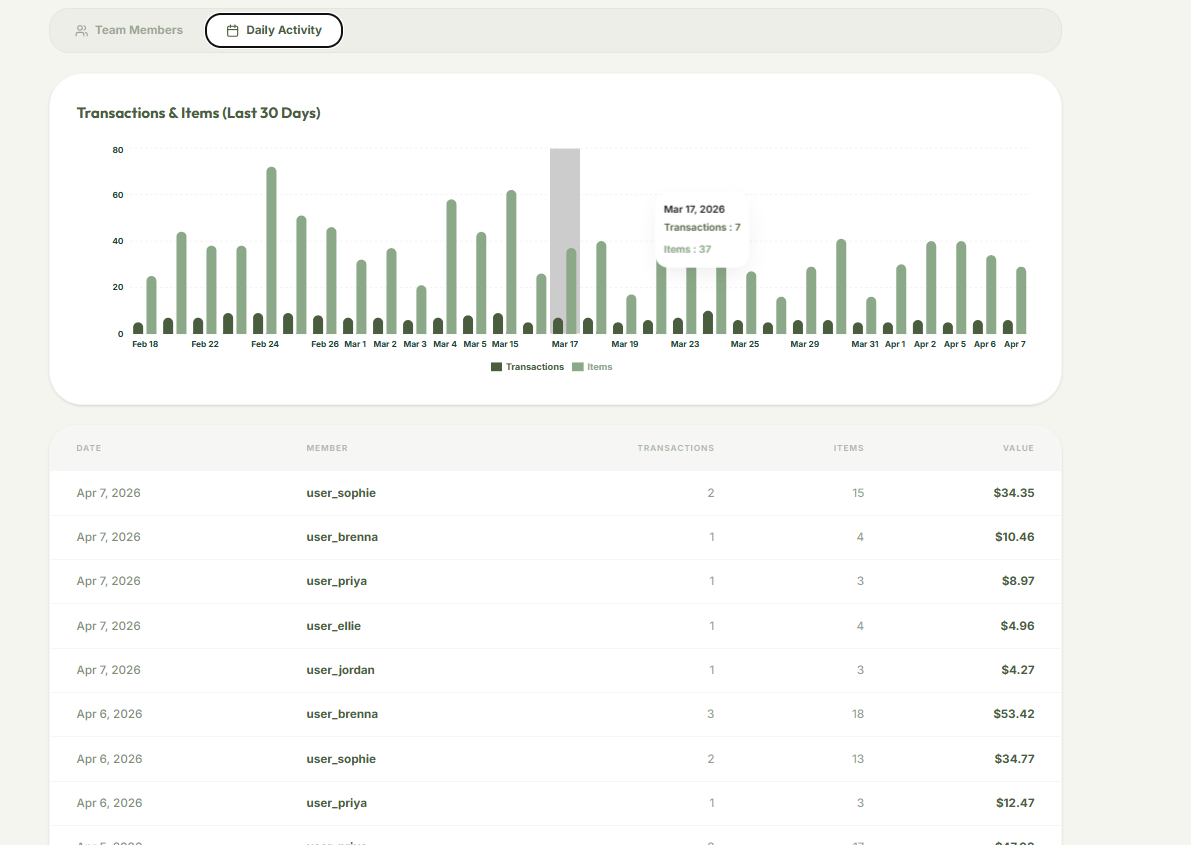
Dashboard Analytics
-
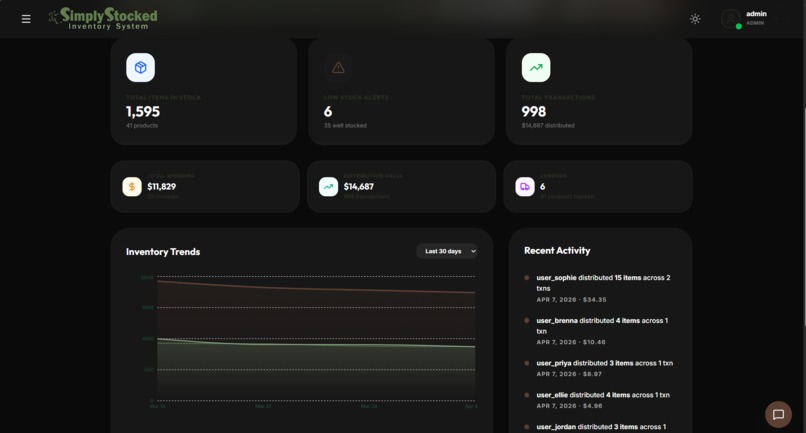
Dark Mode
-
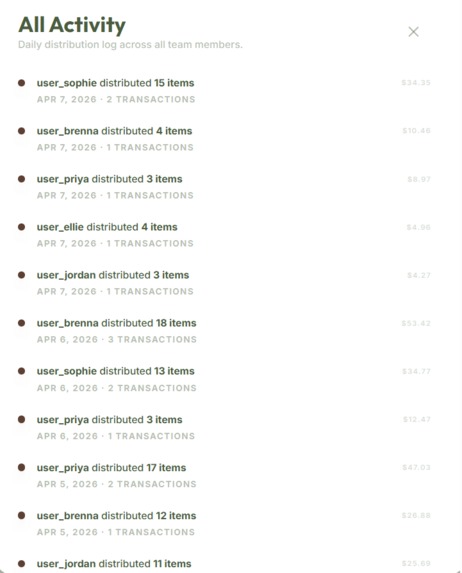
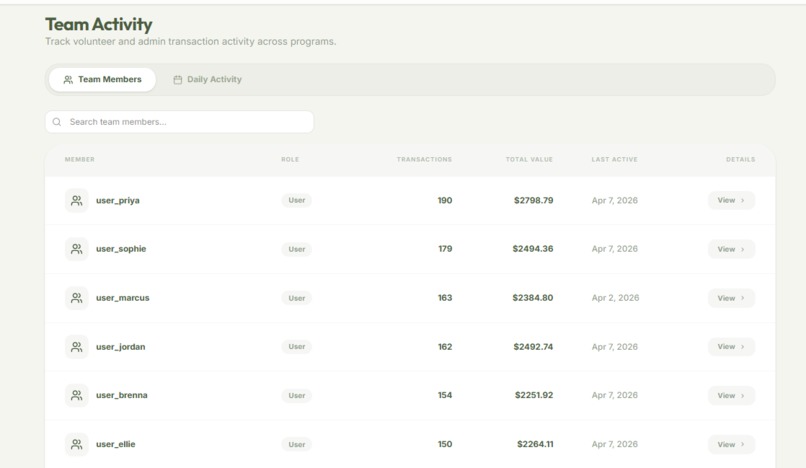
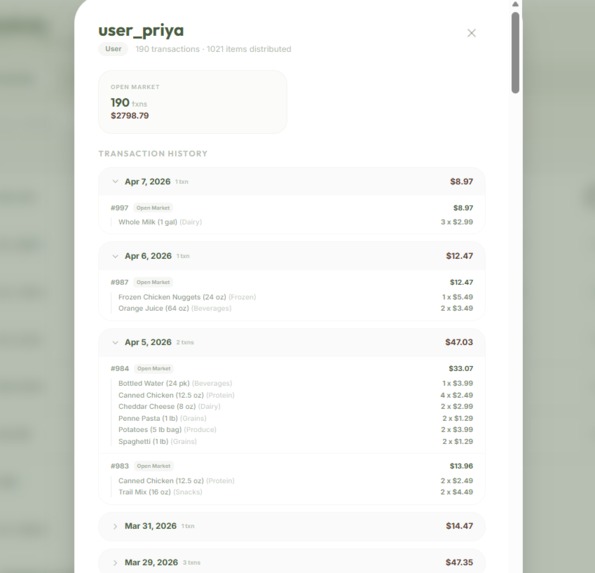
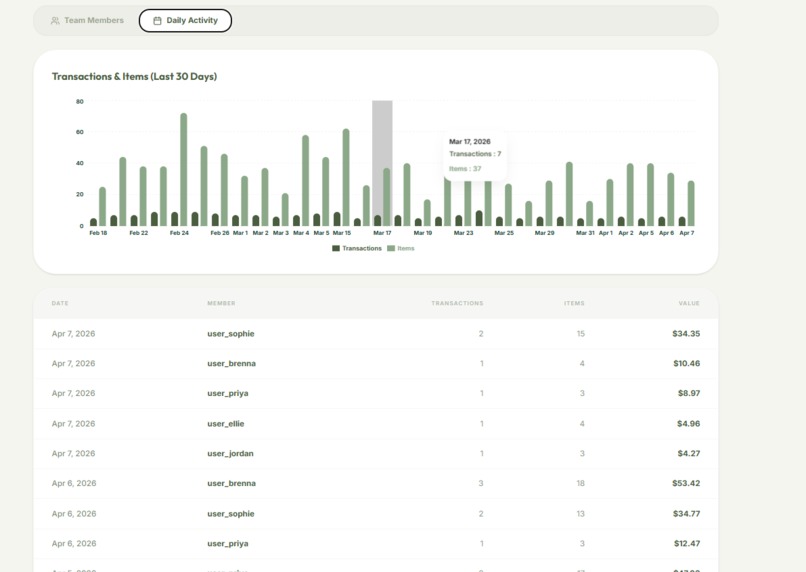
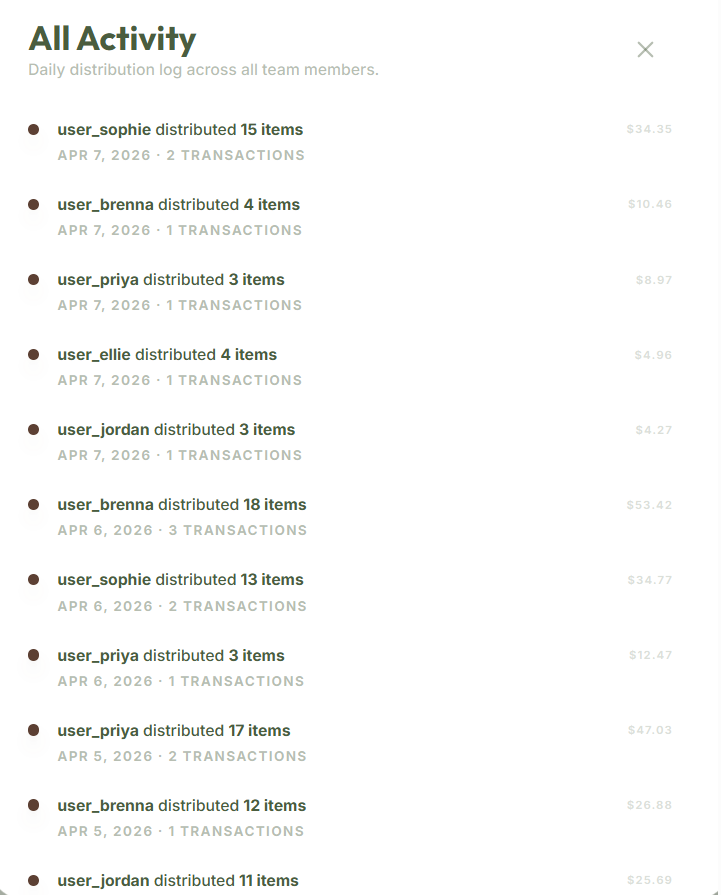
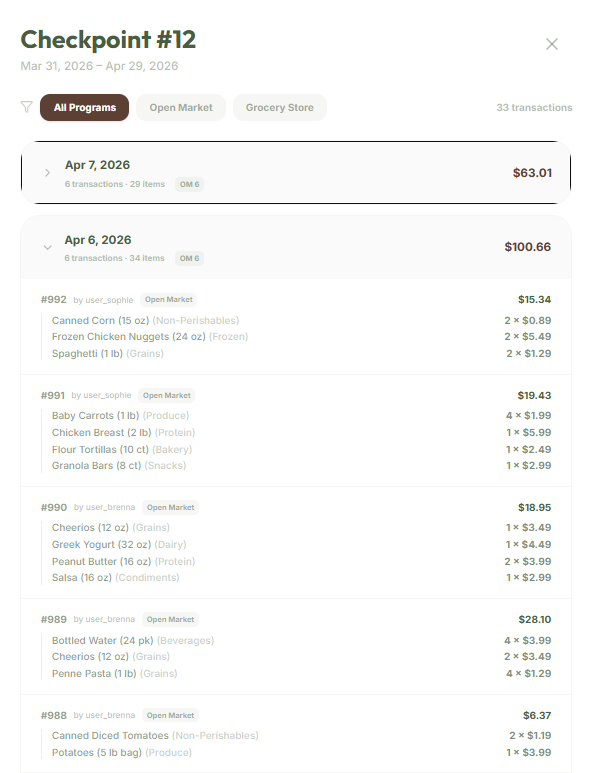
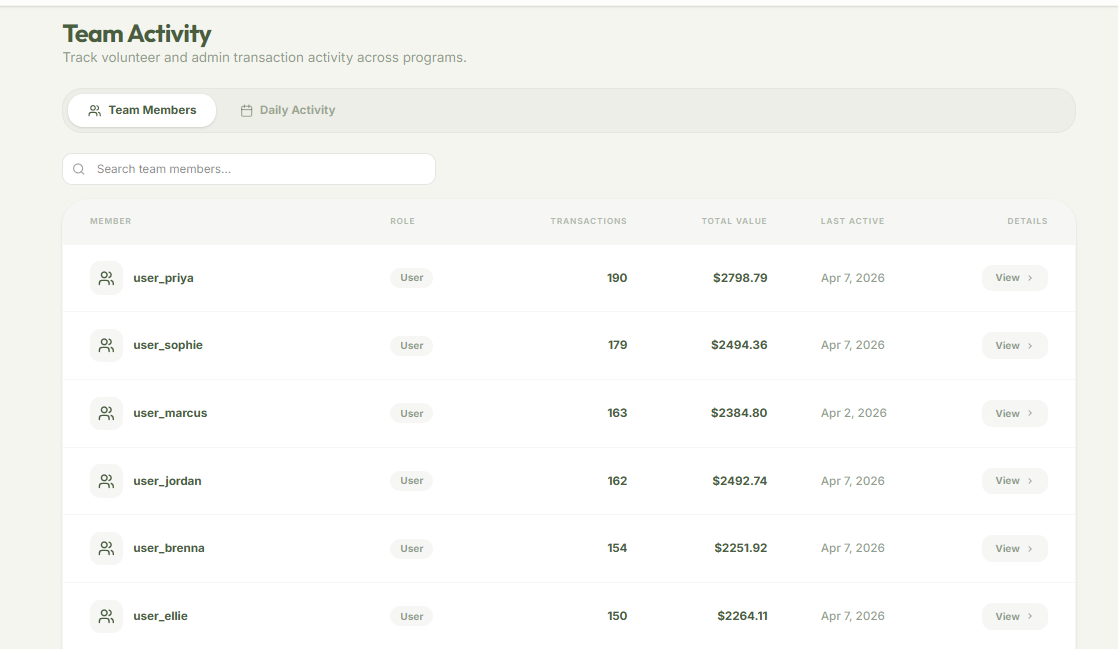
Activity Tracking
-
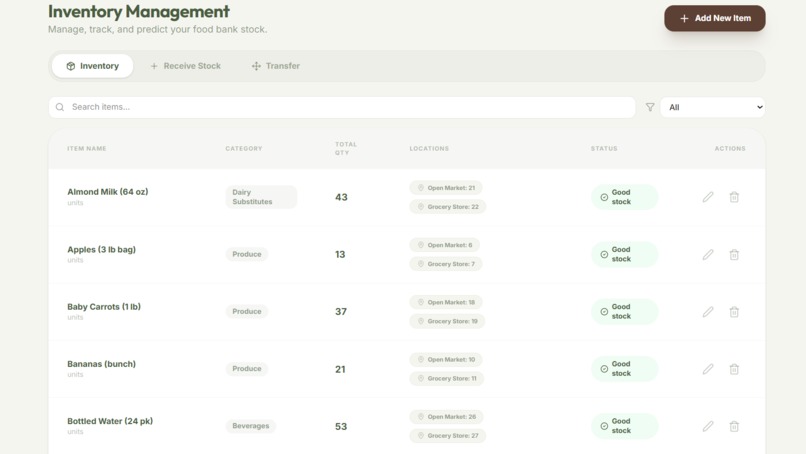
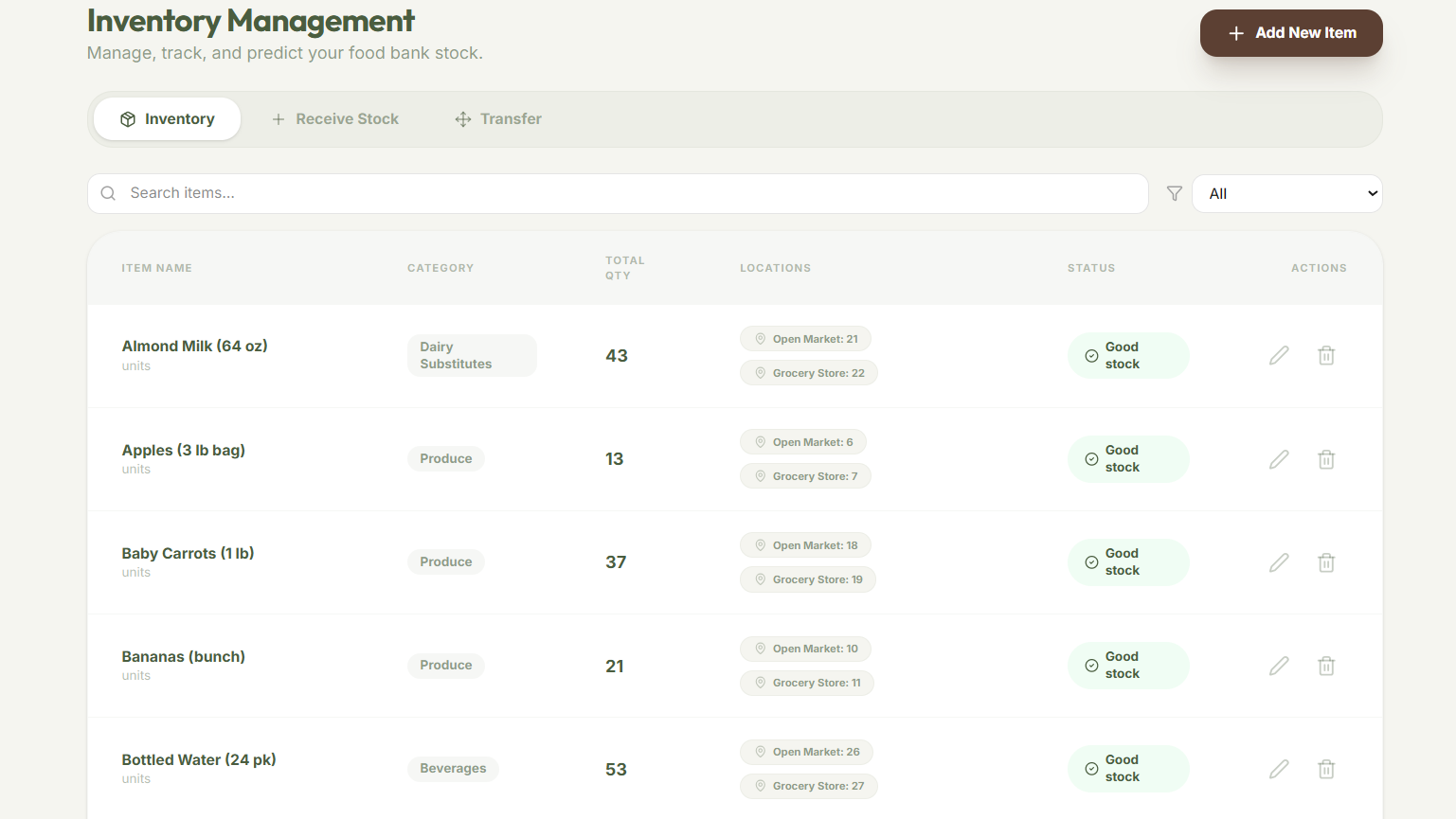
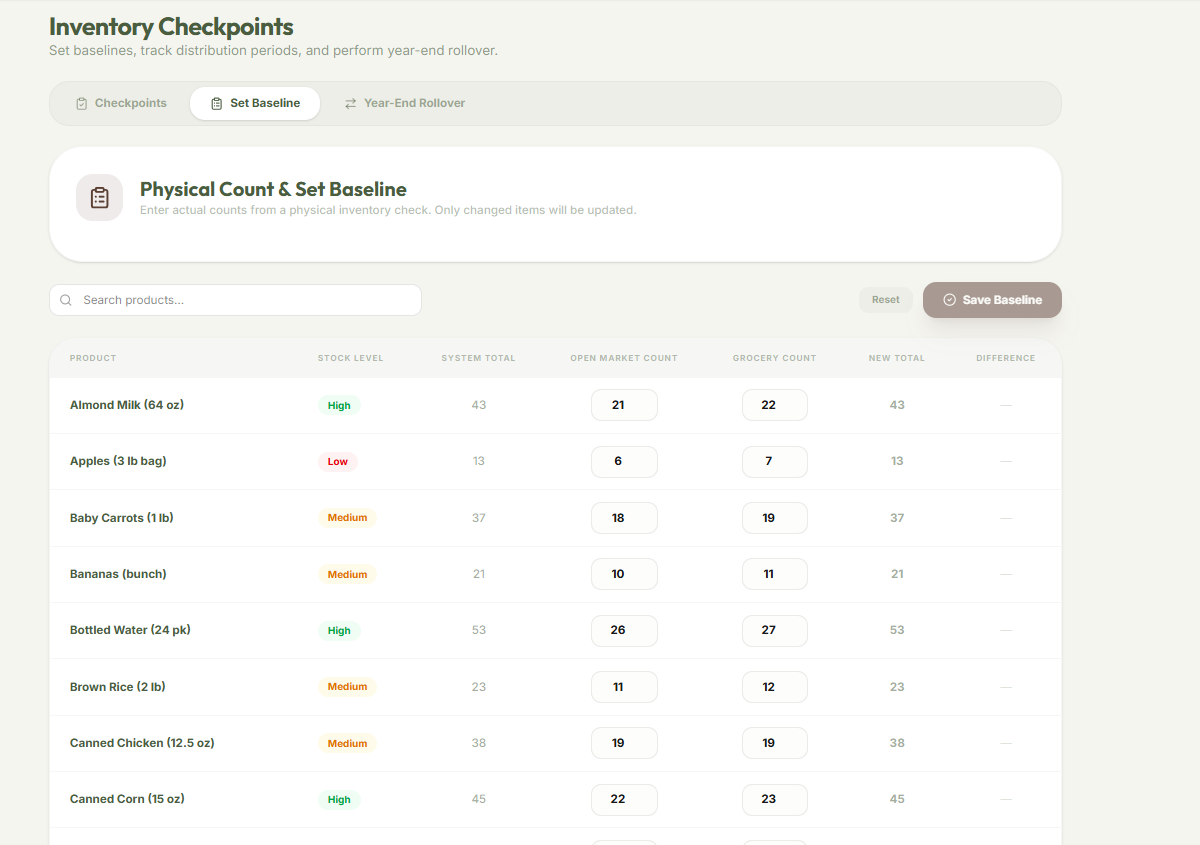
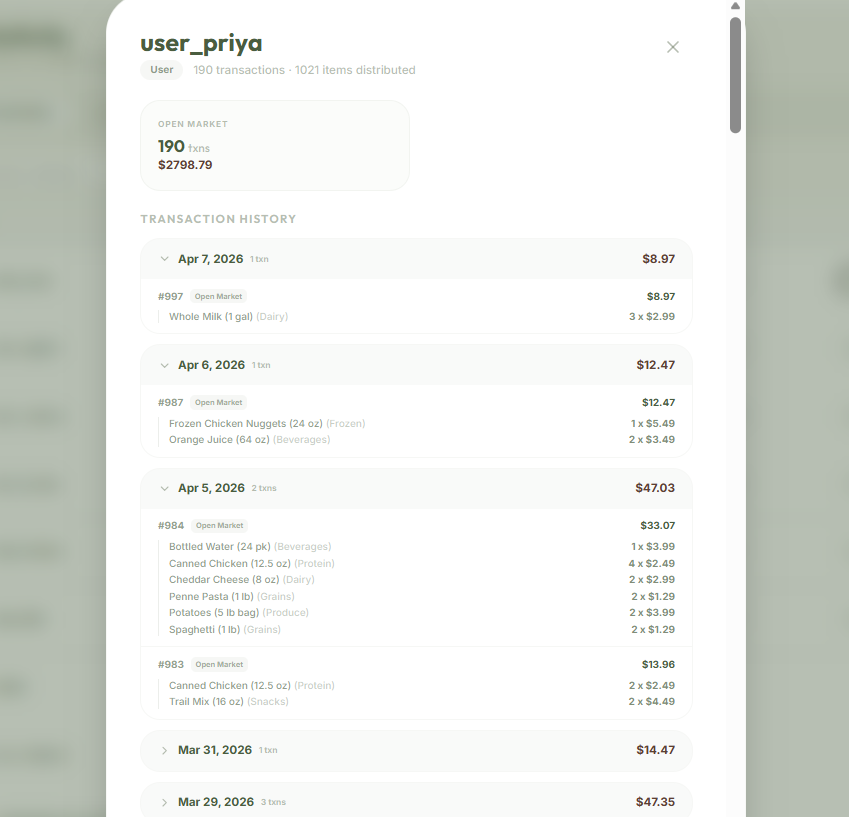
Inventory Table
-
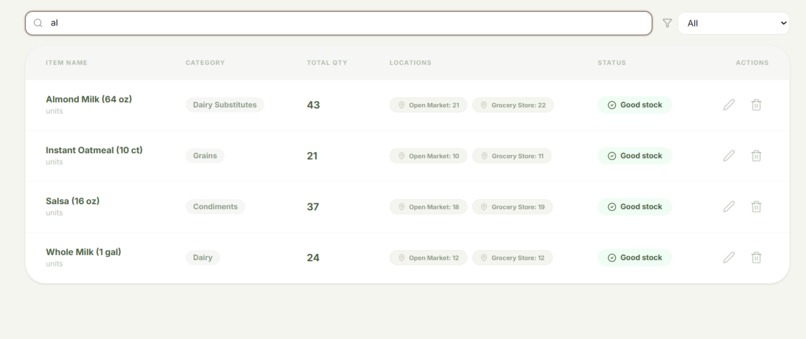
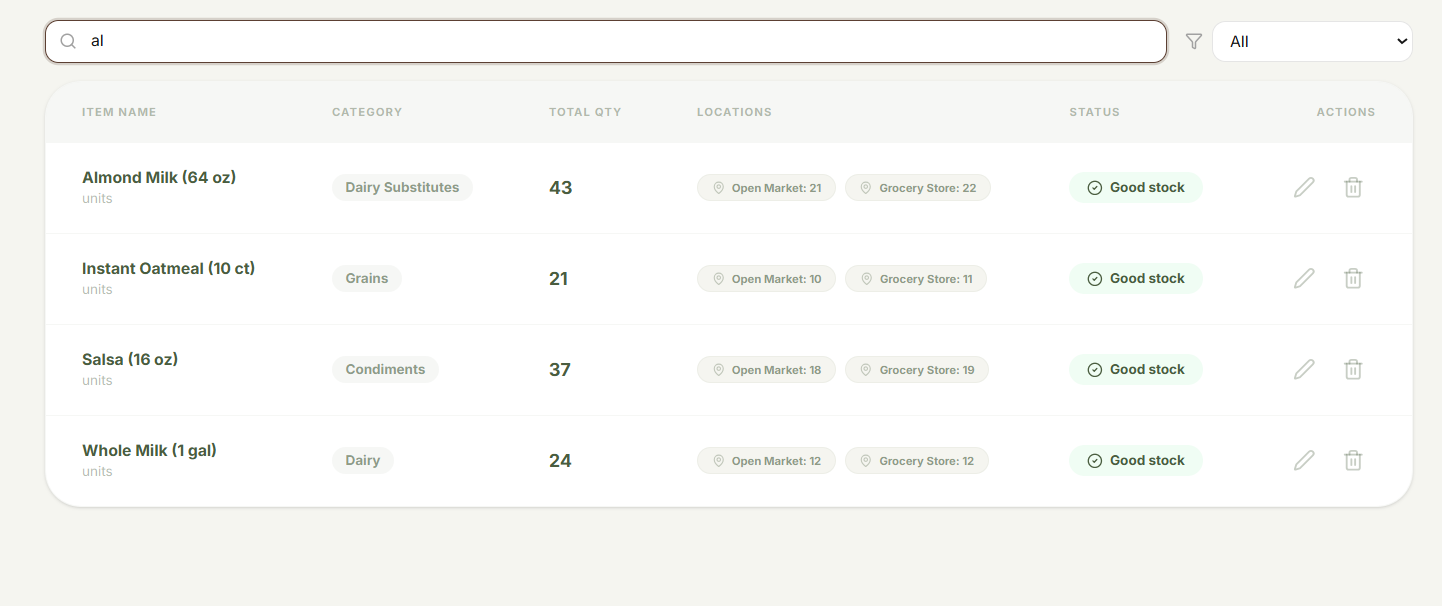
Inventory Filtering
-
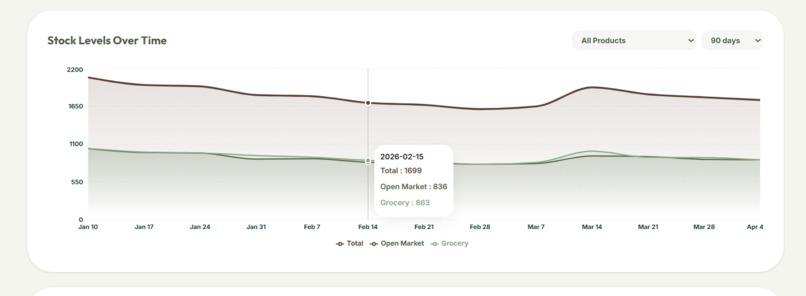
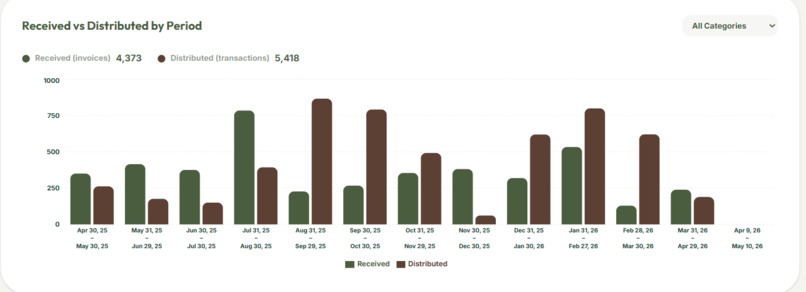
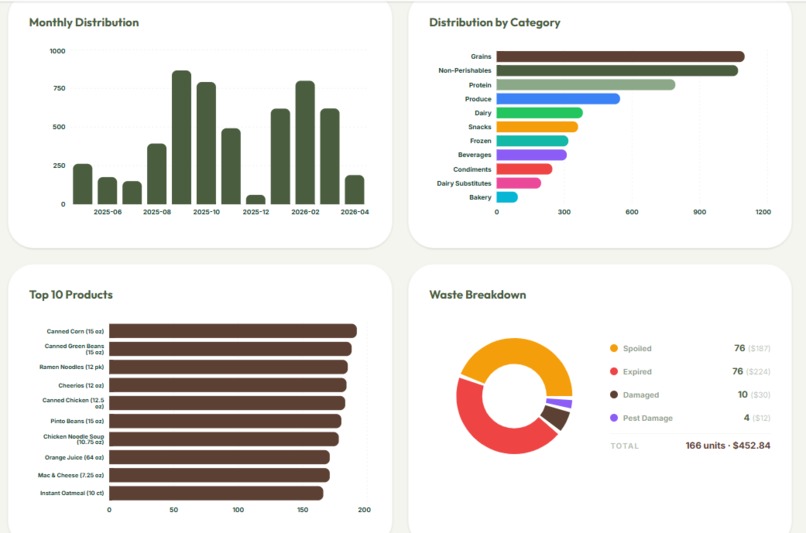
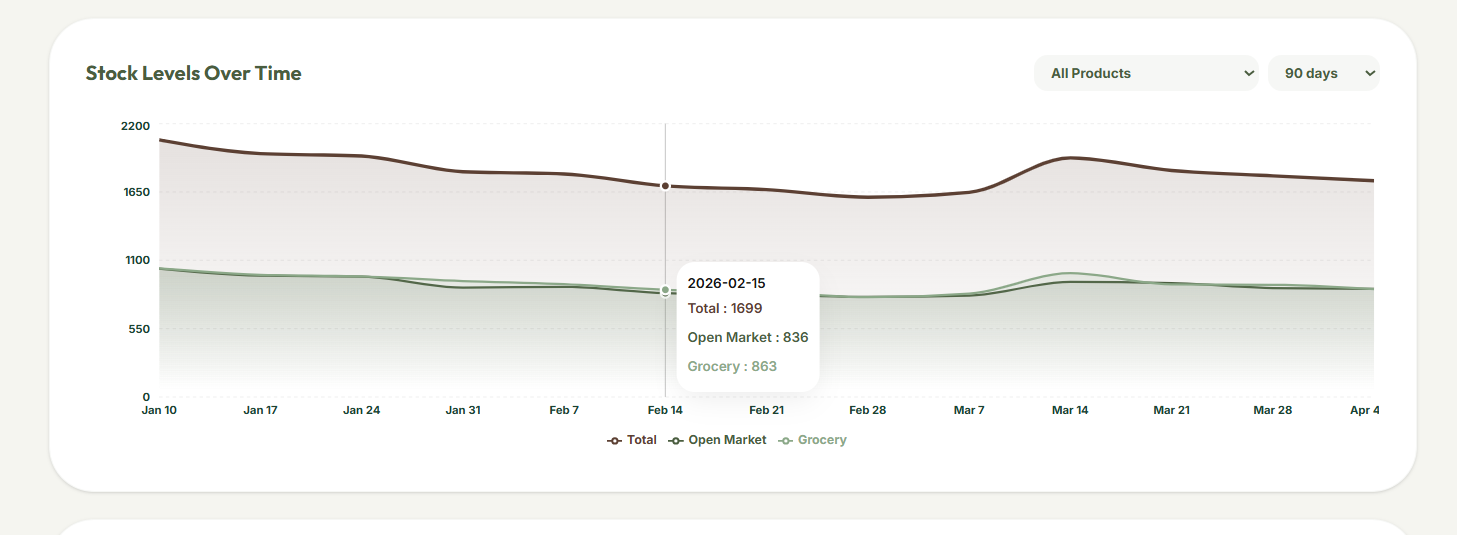
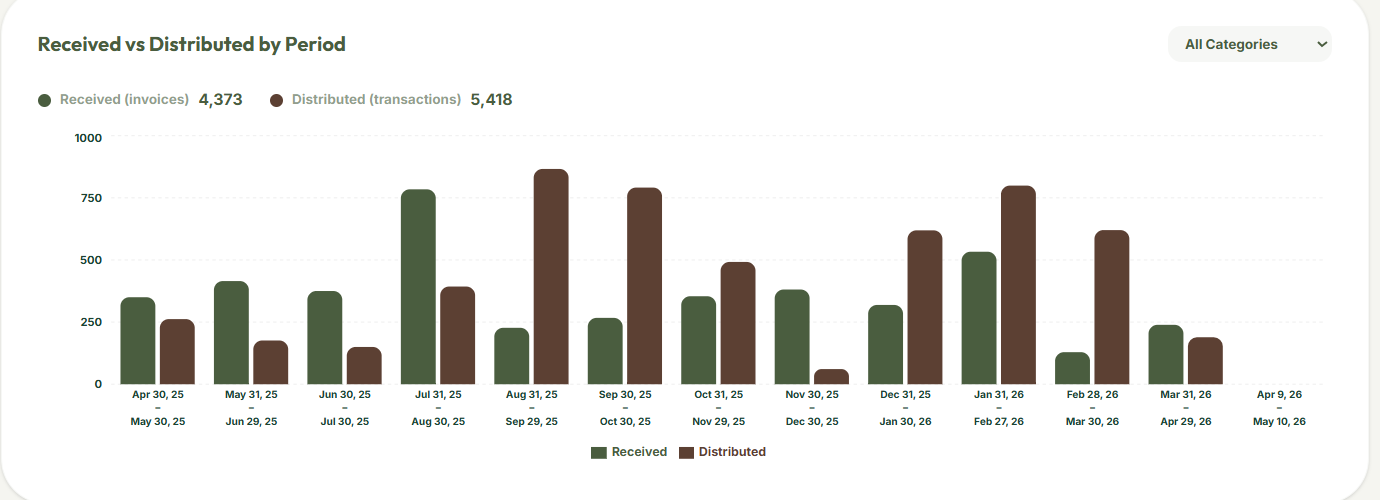
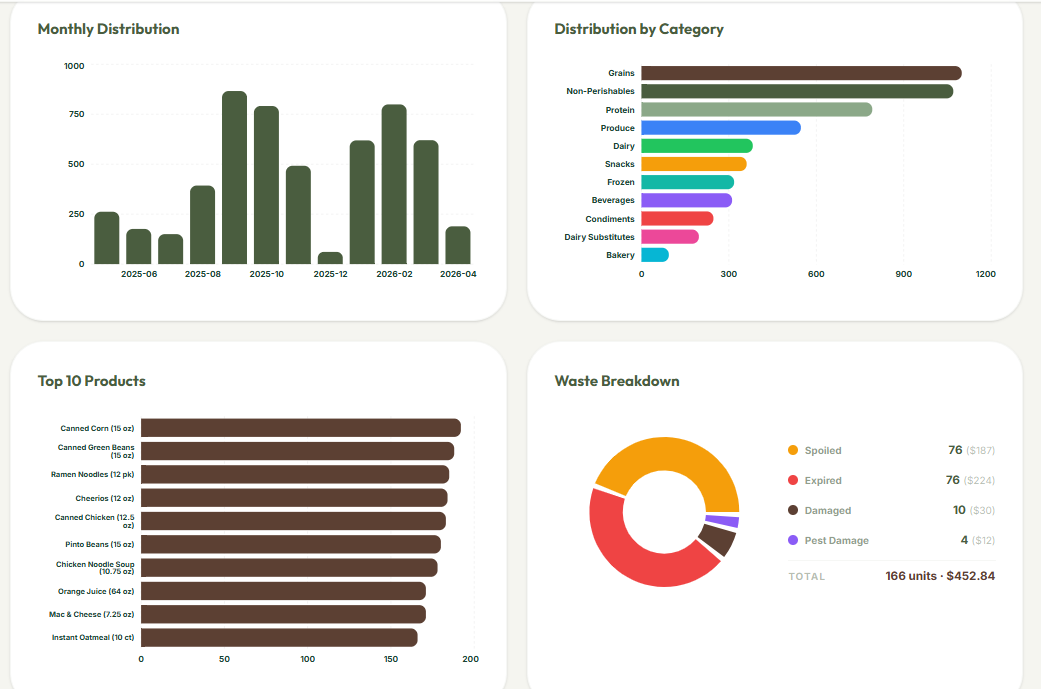
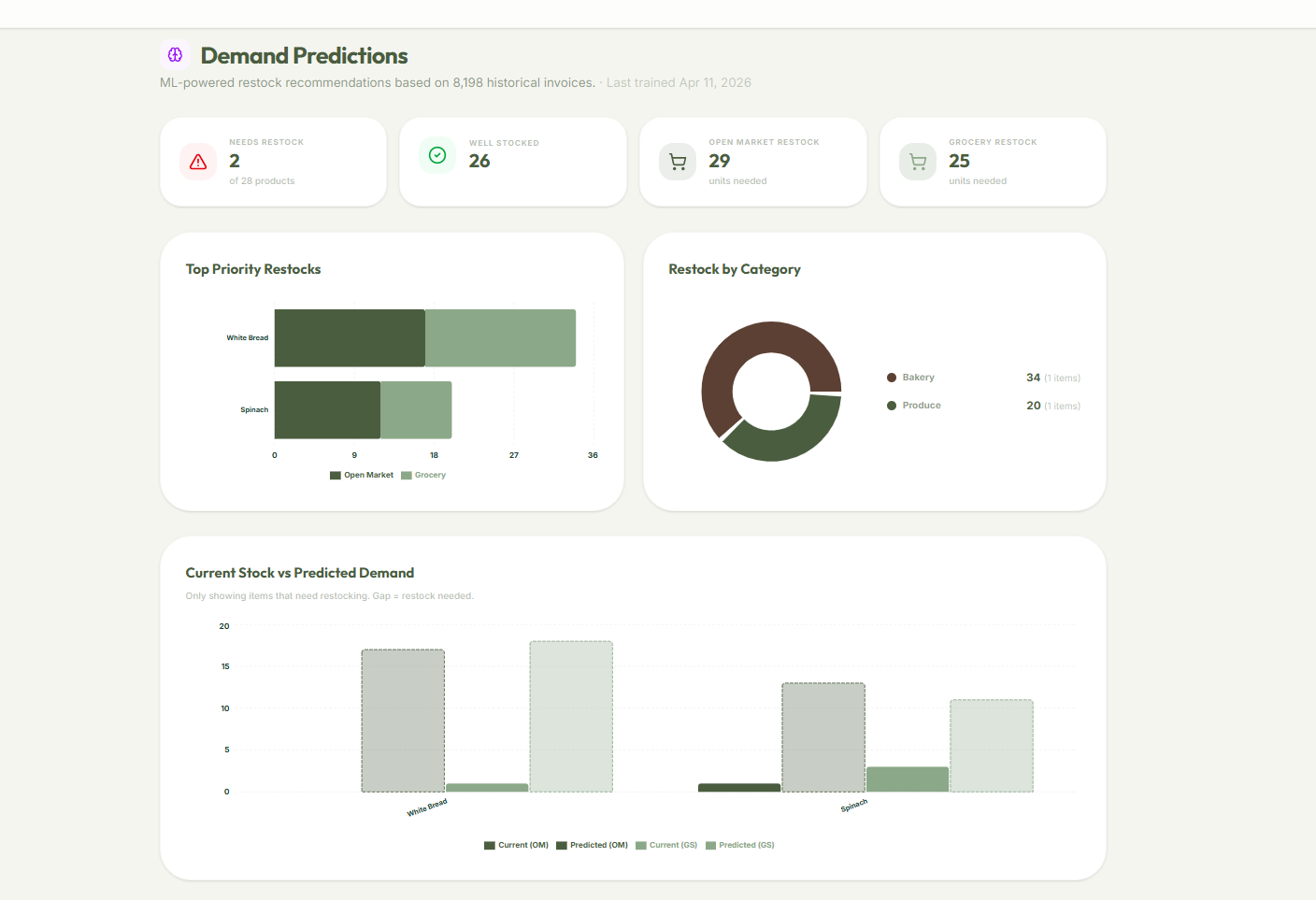
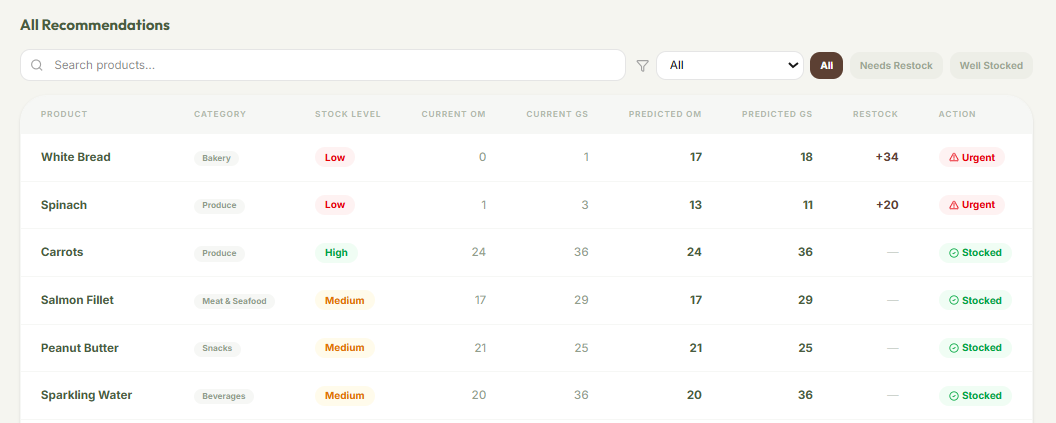
Analytics
-
-
-
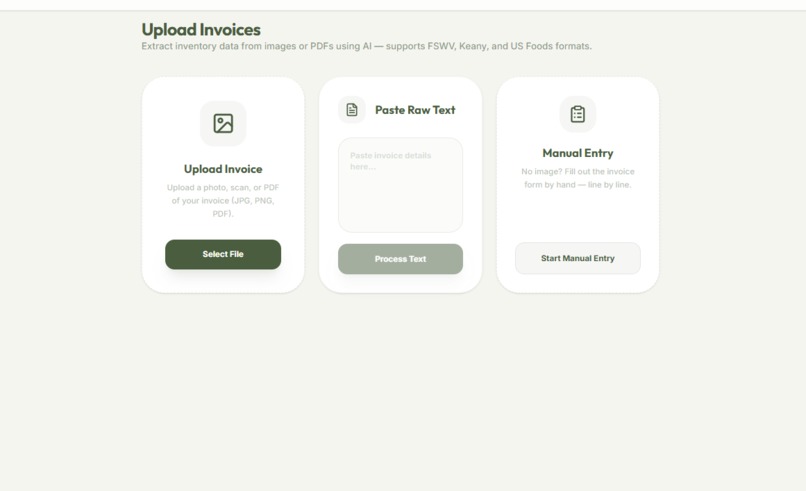
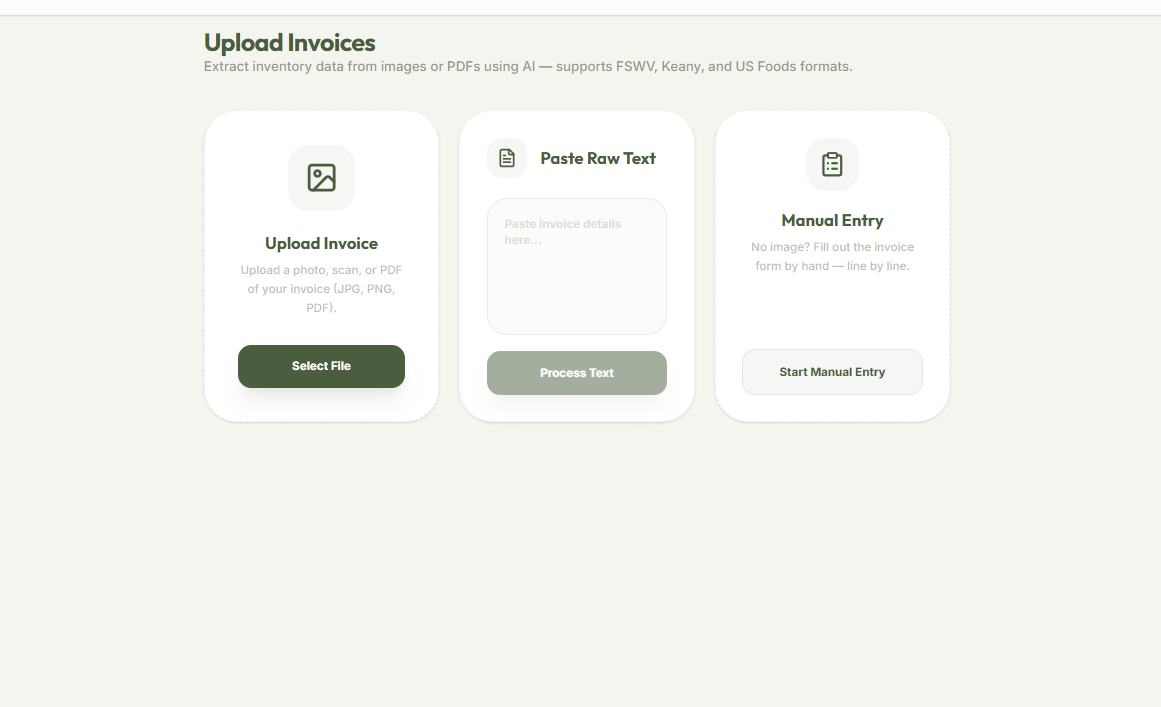
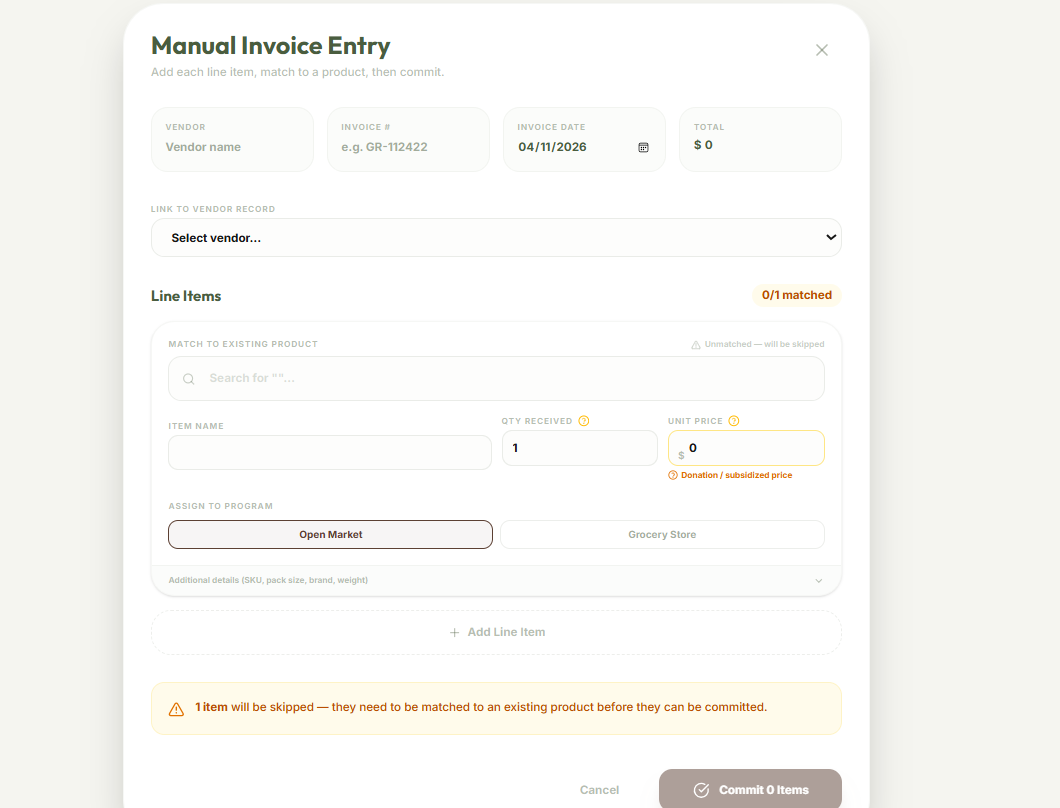
Multiple Invoice Input
-
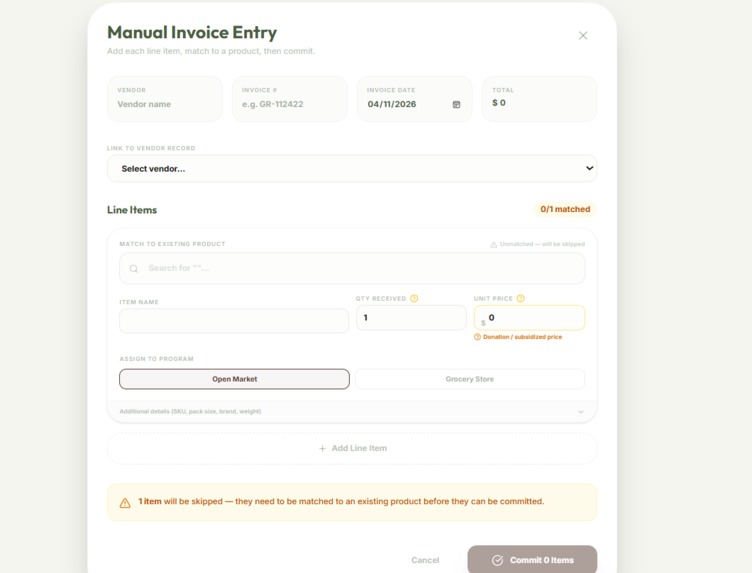
Invoice Addition
-
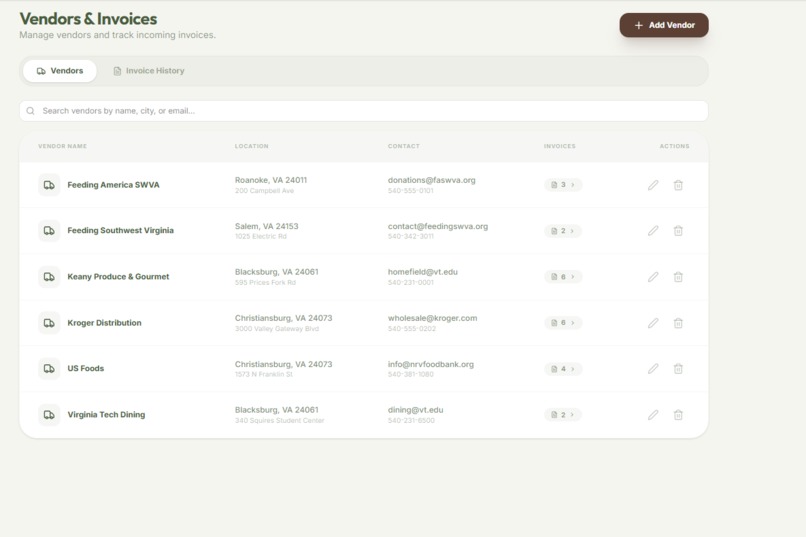
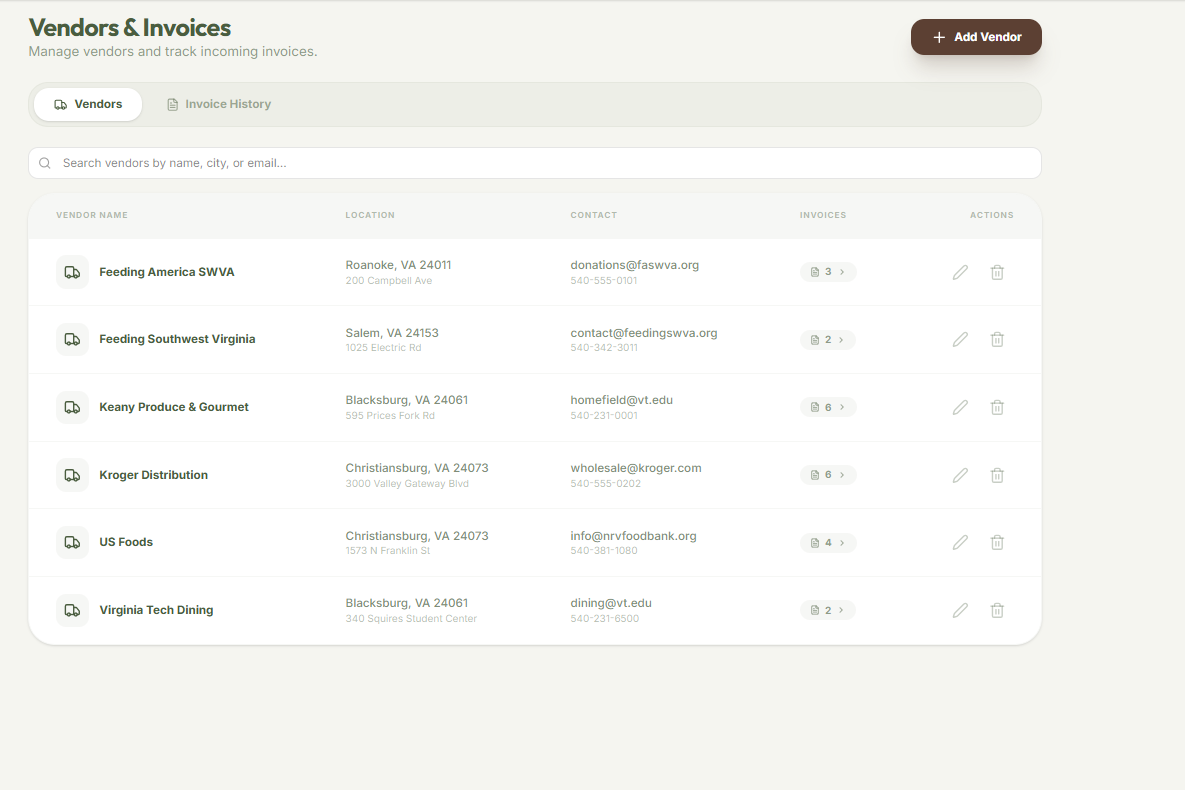
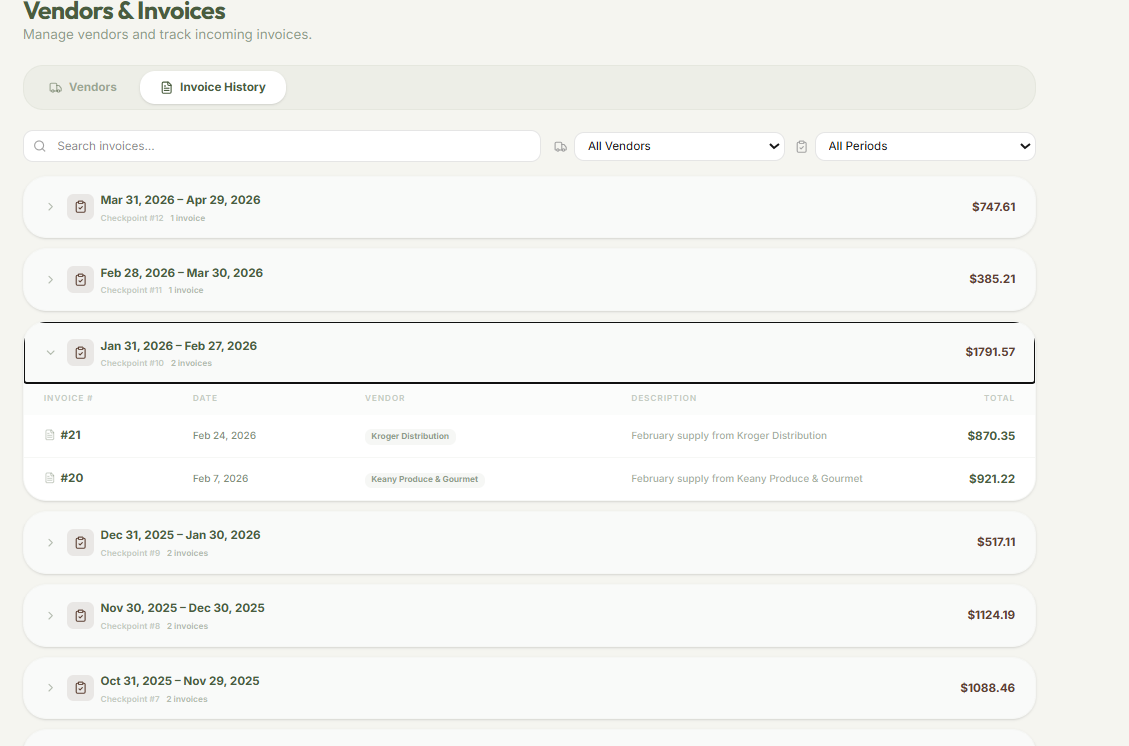
Vendor Tabling
-
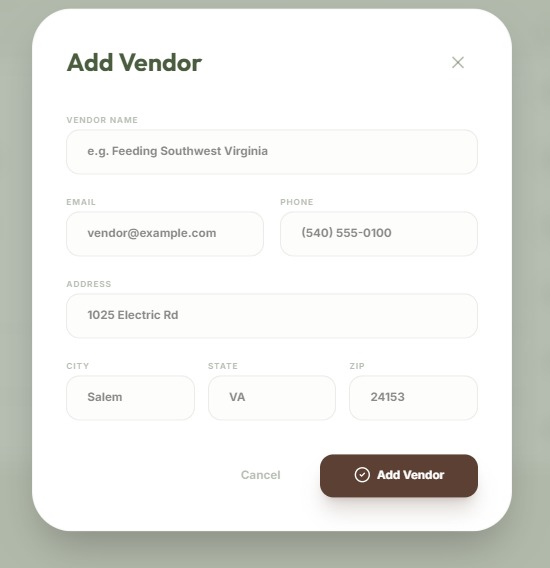
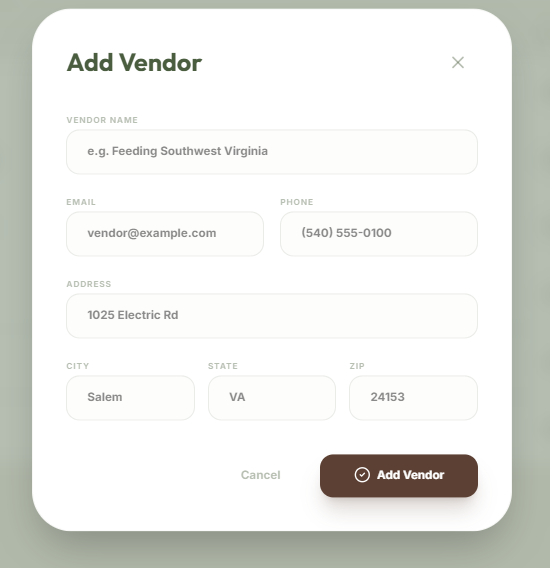
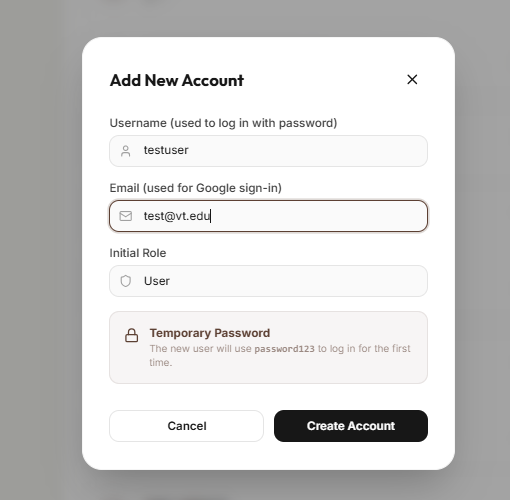
New Vendor Form
-
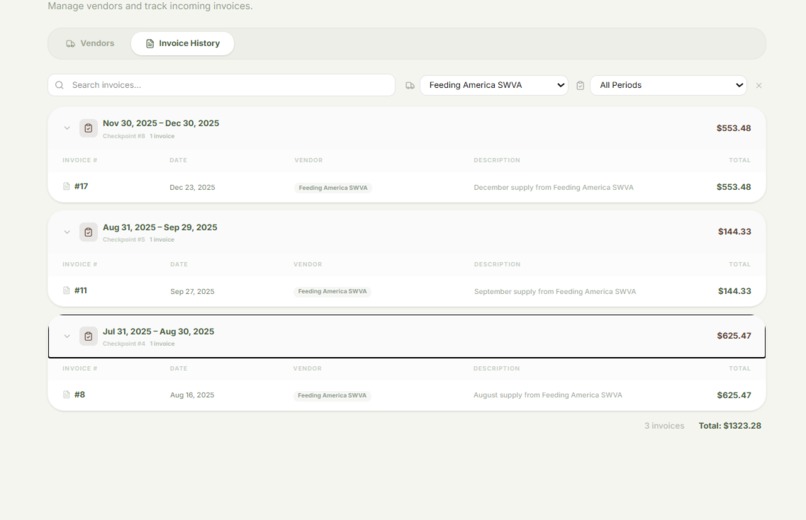
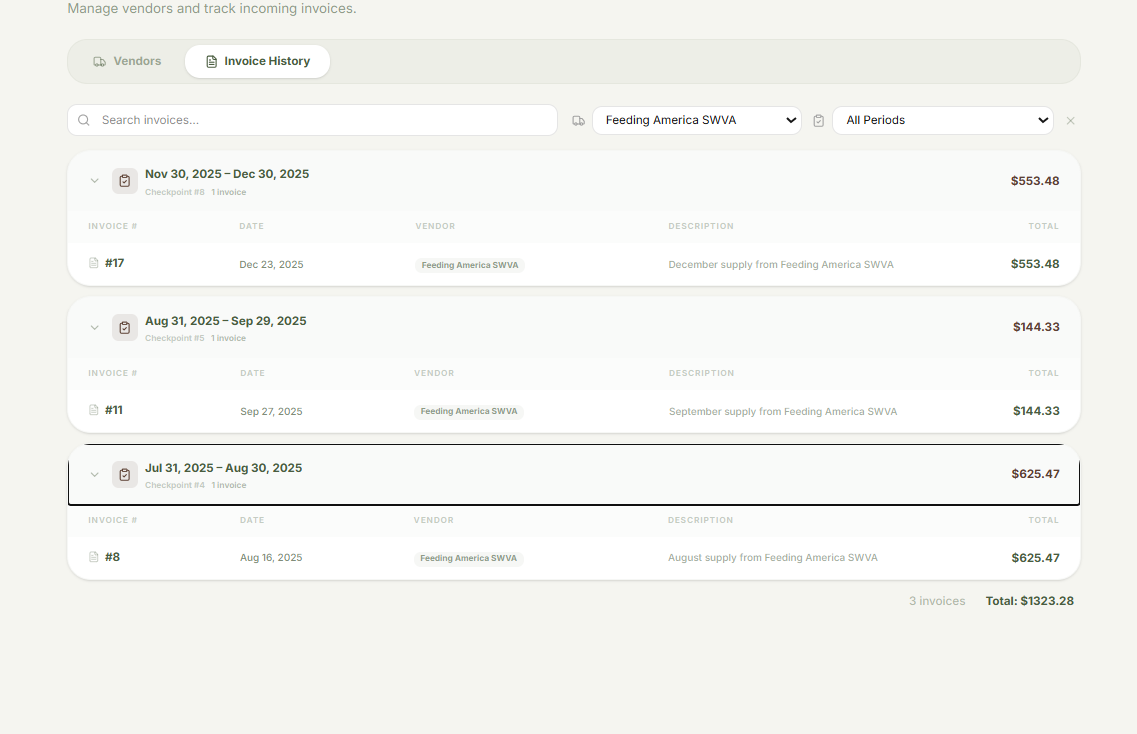
Vendor Transaction Organizing
-
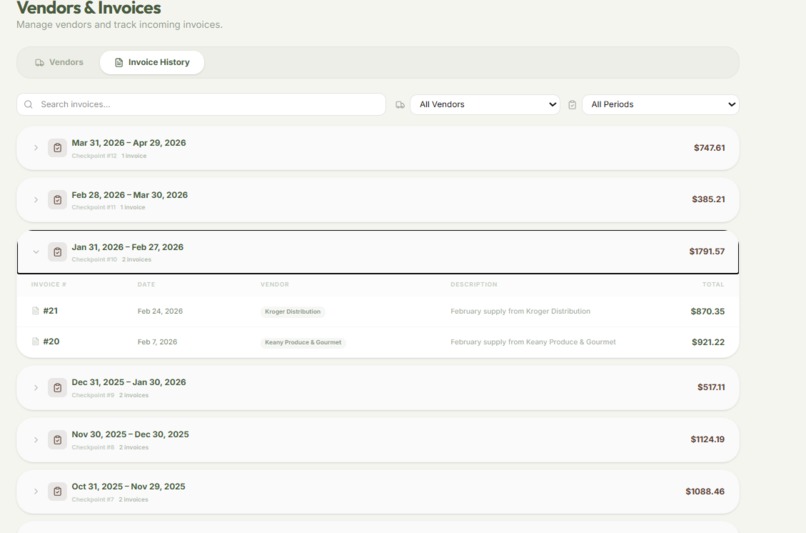
All Vendors Organizing
-
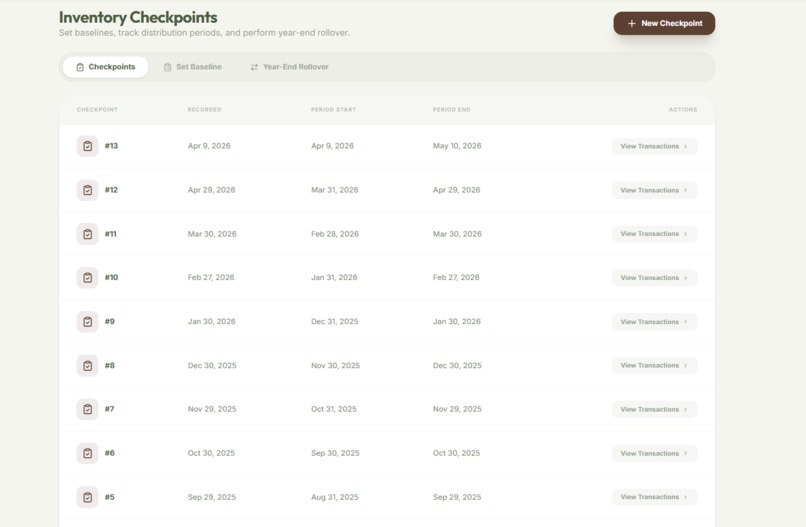
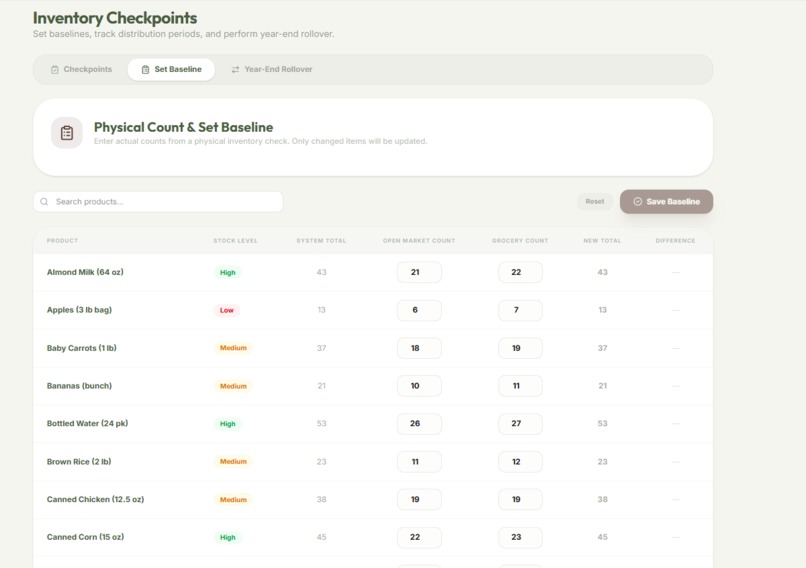
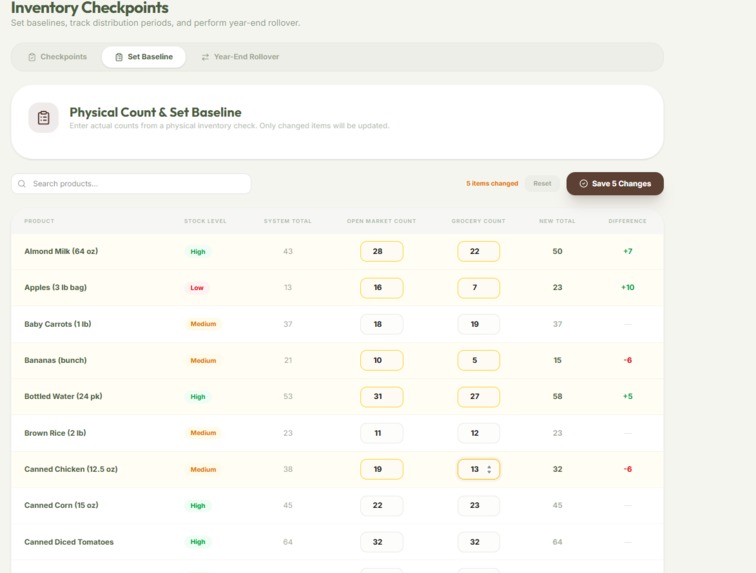
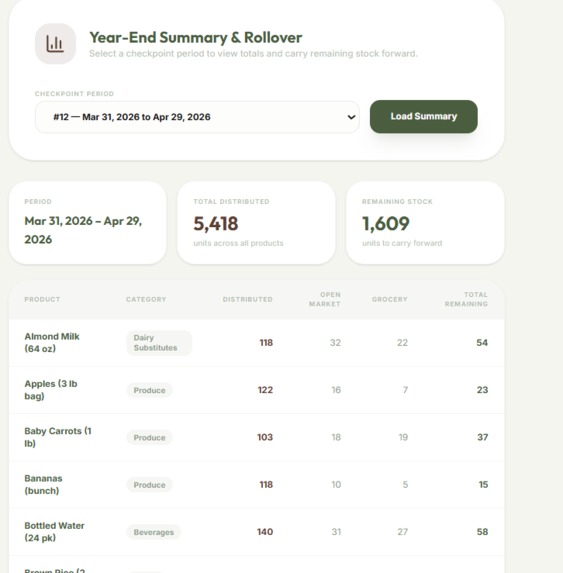
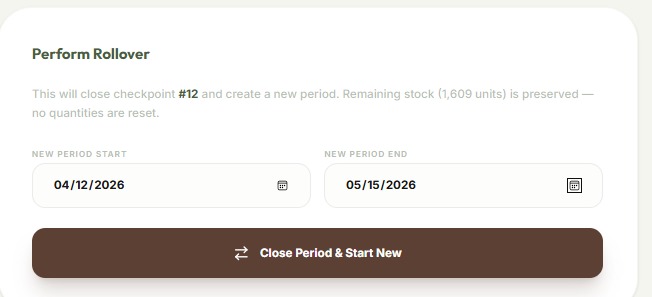
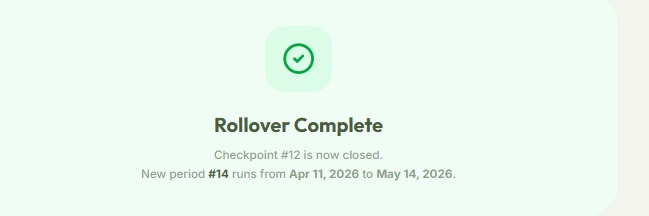
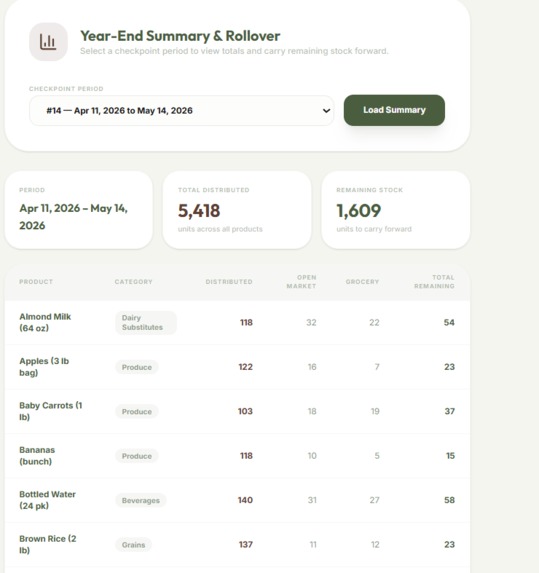
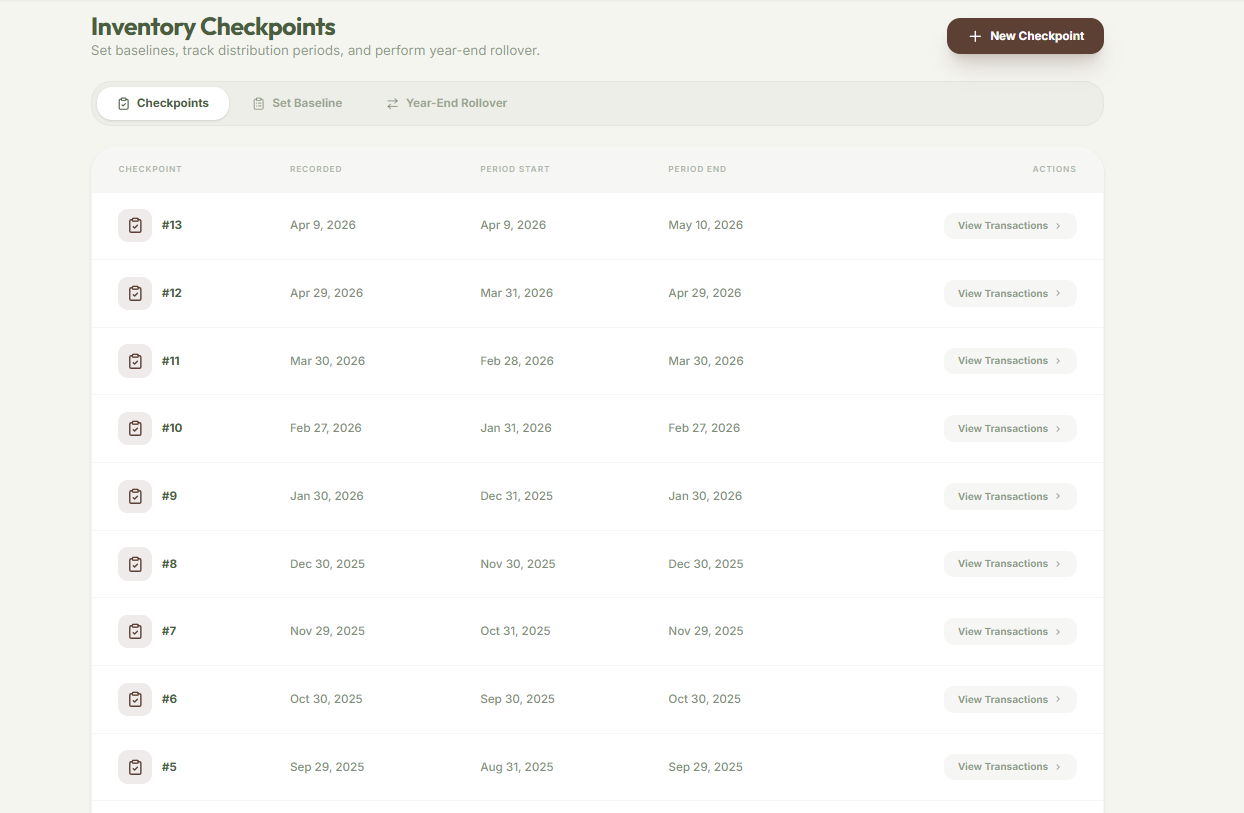
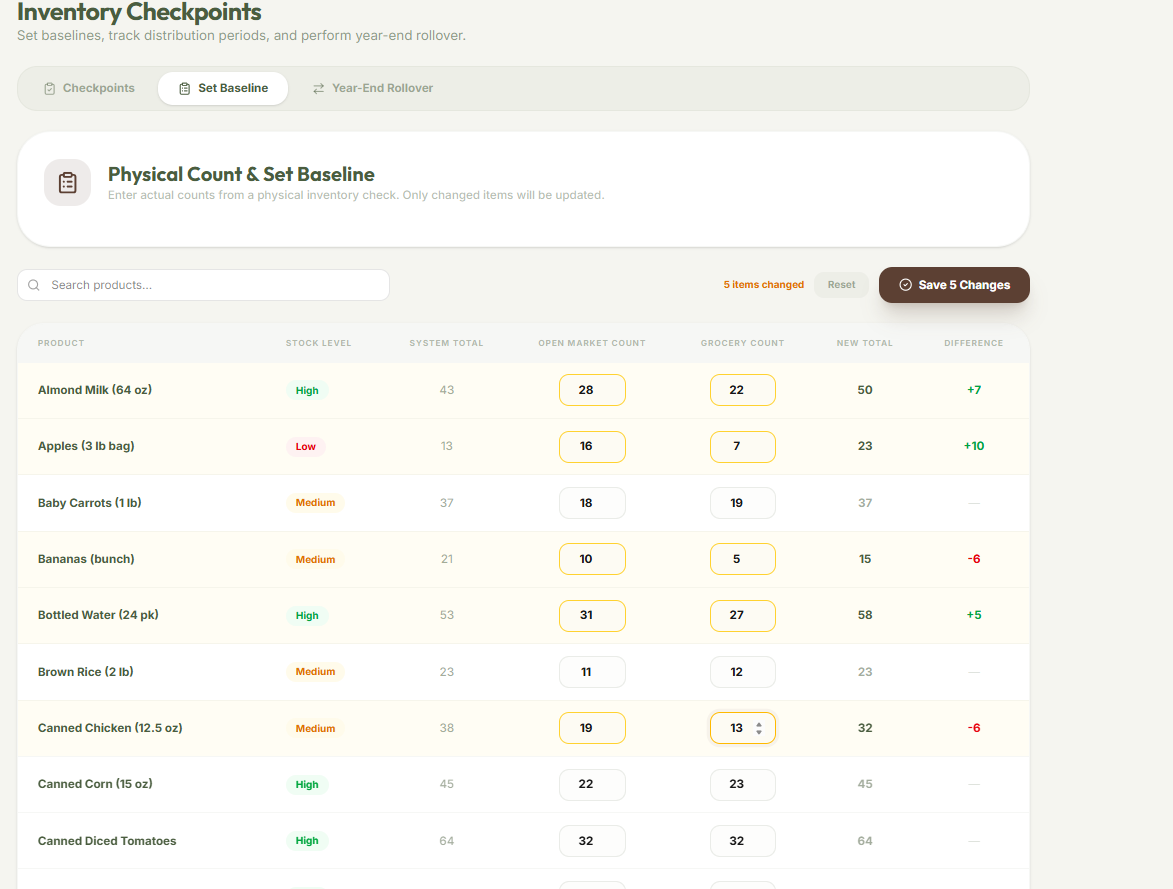
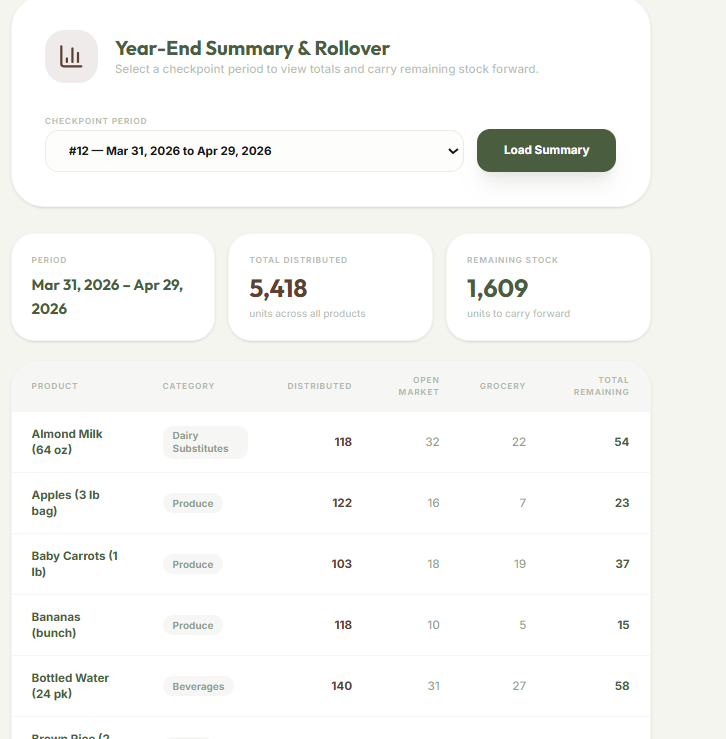
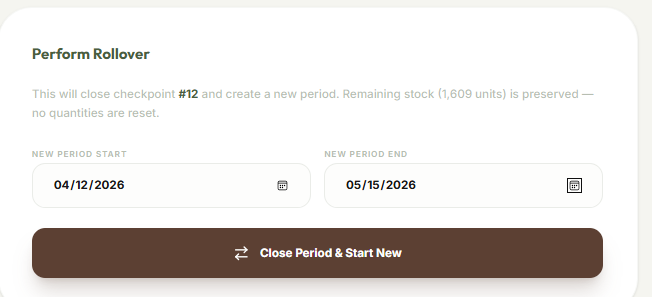
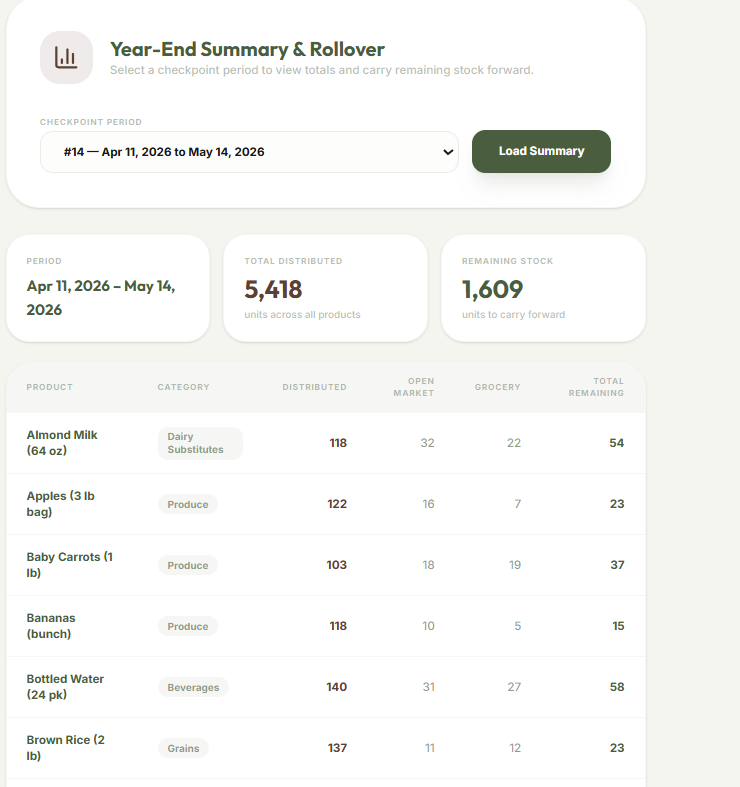
Inventory Checkpoints
-
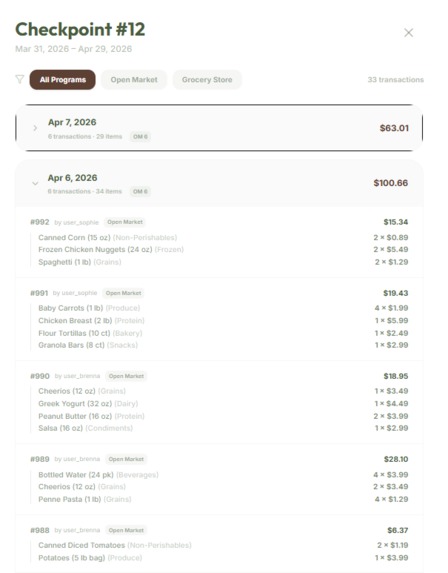
-
-
-

-
-
-
-
-
-
-
-
-
-
-
-
-


Inspiration
SimplyStocked was born from a conversation with Isabelle Largen at The Market at Virginia Tech, who described the pain of managing food access for hundreds of students using physical notebooks and manual Excel entry. She needed a simple system with all database entries in one place, a way to identify which items were popular across programs, and a faster, more reliable method for data entry. We wanted to build something that respects the dignity of those being served by ensuring shelves are always stocked while respecting the time of volunteers by automating the most tedious parts of their day.
What it does
SimplyStocked is a local-first inventory intelligence platform designed for the unique needs of food pantries and food banks.
- AI-Powered Ingestion: Uses a completely local ML model to transform heterogeneous vendor invoices (PDF or photo) into structured stock data in seconds, cutting manual entry time by 80%. None of the information ever leaves your local device, ensuring private information remains private.
- Dual-Program Tracking: Synchronizes inventory across independent distribution models (e.g., Open Market and Grocery Store), with a one-click transfer system to keep programs in sync.
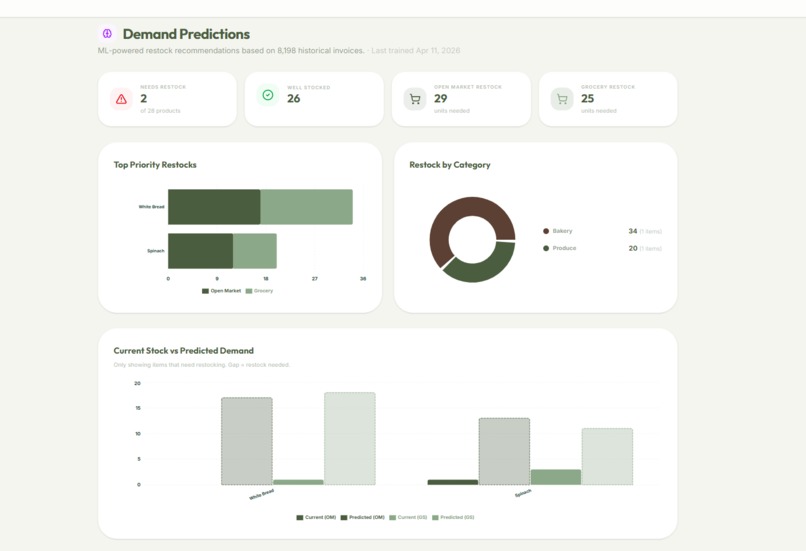
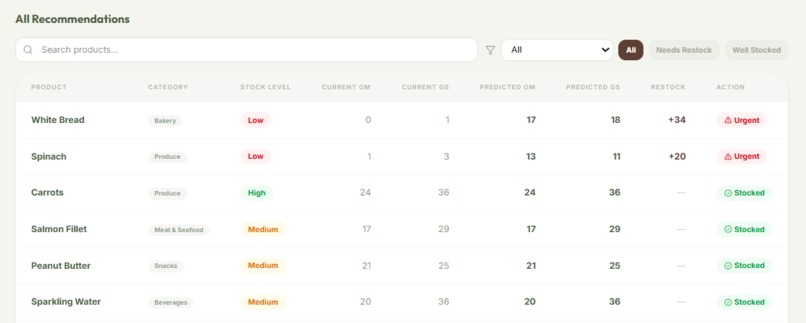
- Demand Forecasting: Analyzes up to a full year of historical distribution data via a custom machine learning model we created and trained to surface restock recommendations, so high-demand items never run out.
- Cost Analysis: Tracks unit pricing across vendors to surface savings opportunities and ensure pantries are always getting the best subsidized rates.
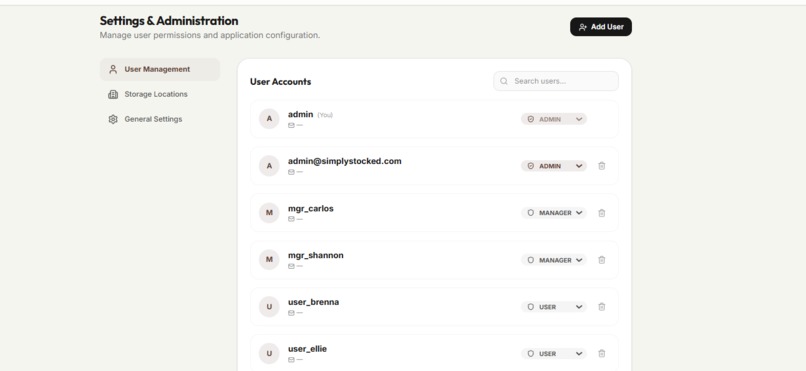
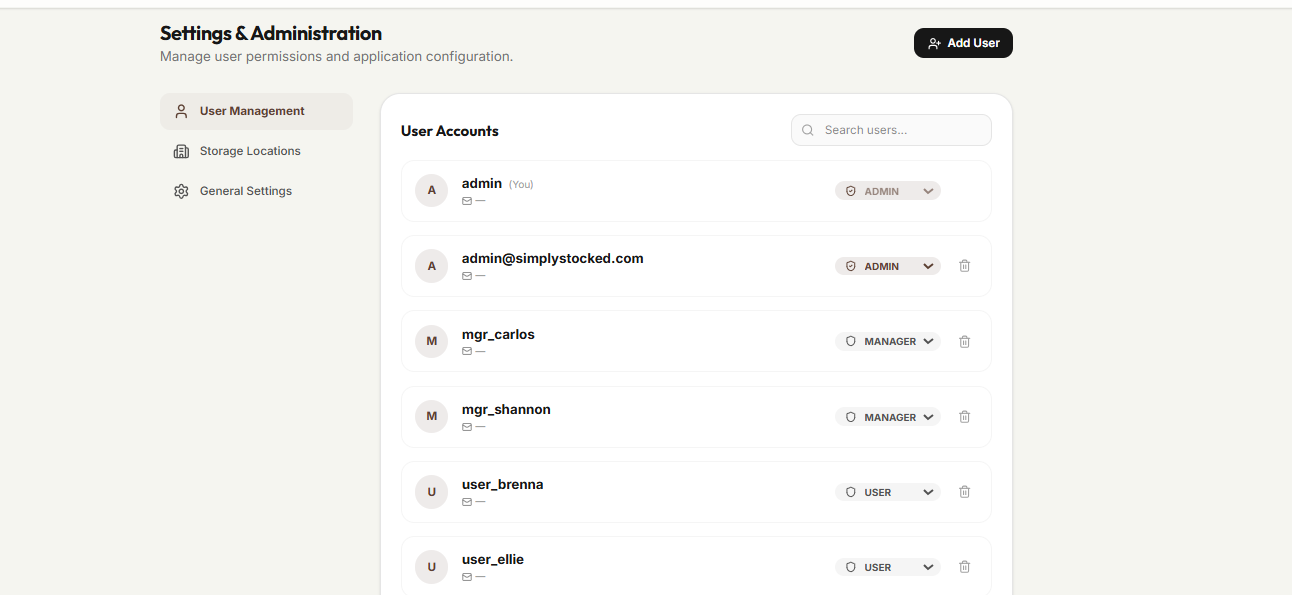
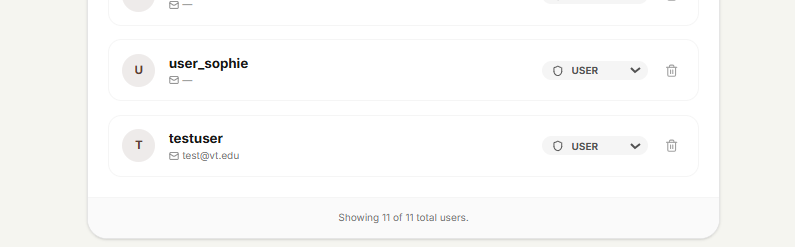
- Secure Role Management: RBAC ensures volunteers, managers, and admins each see exactly what they need and nothing more.
- Volunteer-Optimized UI: A clean, premium interface built with Framer Motion that guides non-technical users through a simple Scan → Review → Commit workflow.
How we built it
We chose a modern, scalable Google-centric stack:
- Frontend: React and Vite for a fast, responsive UI, with Framer Motion for premium micro-animations and accessibility.
- Backend: FastAPI (Python) providing a high-performance RESTful API with strict RBAC, custom MySQL database, and JWT session management.
- Infrastructure: Google Cloud Run for containerized server deployment using Google Cloud Run and Google Cloud SQL (MySQL) for database implementation.
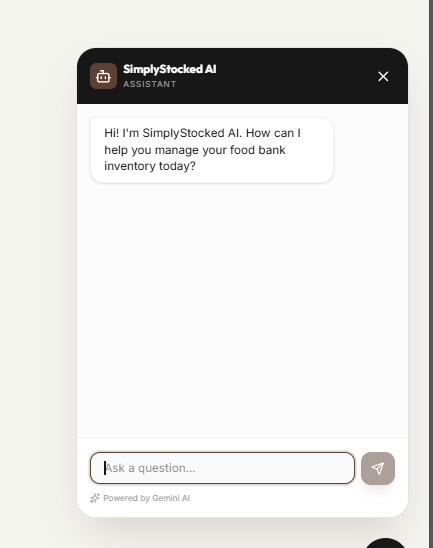
- Intelligence: Ollama’s qwen2.5vl:3b as the multimodal engine for OCR invoice extraction, a custom full-trained XGBoost regression machine learning model for demand forecasting over historical inventory data, and Gemini Flash for an in-app AI assistant.
- Identity: Google OAuth 2.0 for secure, low-friction administrative access, with Bcrypt for enterprise-grade password hashing.
- Privacy: Edge-based invoice redaction that strips sensitive vendor information before any data reaches cloud storage.
Challenges we ran into
One of the biggest challenges was balancing performance with feature complexity. We had ambitious goals for SimplyStocked — real-time inventory syncing, AI-powered invoice ingestion, demand forecasting, cost analysis, and secure role-based access — all running in a lightweight, volunteer-friendly system. As we added more intelligence and functionality, we constantly had to optimize for speed and usability so the system wouldn’t feel slow or overwhelming for non-technical users in a fast-paced pantry environment.
Another major obstacle was limited and inconsistent training data for our machine learning models. Food pantry inventory systems rarely have clean, structured historical datasets. Most records were incomplete, manually entered, or inconsistent across programs. This made it difficult to train reliable forecasting models, forcing us to iterate heavily on preprocessing, feature engineering, and fallback heuristics to stabilize predictions.
We also faced significant difficulty with invoice ingestion and OCR reliability. The invoices we received from food banks and vendors were extremely heterogeneous — every supplier used a different format, layout, and level of scan quality. Some were clean digital PDFs, while others were blurry photos or multi-column spreadsheets converted into images. This made traditional OCR pipelines brittle, which is why we ultimately shifted toward a multimodal approach using a local model to interpret invoices more contextually rather than relying on rigid templates.
A closely related challenge was extracting structured meaning from unstandardized data. Even when OCR worked, mapping extracted text into a consistent schema (items, quantities, units, pricing, and vendor info) required careful normalization logic. Units varied wildly (cases vs. individual items vs. pounds), and the same product often appeared under slightly different names across vendors, which complicated stock reconciliation.
We also struggled with uncertainty around what analytics actually mattered most to food pantries. At the beginning, we assumed forecasting and cost tracking would be the primary value drivers, but conversations with pantry staff revealed a broader set of needs — including simplicity of data entry, visibility across distribution programs, and the ability to quickly identify high-demand items. This forced us to repeatedly re-evaluate our priorities and redesign parts of the system around real operational workflows instead of purely technical metrics.
Another challenge was designing a machine learning system without overengineering it. We had to strike a balance between a custom-built forecasting model and practical reliability. With limited historical data and seasonal variability in donations and demand, we had to carefully tune our XGBoost model to avoid overfitting while still producing meaningful restock recommendations.
Finally, we encountered system design complexity around privacy and local-first constraints. Ensuring that sensitive vendor and operational data never left the local environment added architectural constraints to both the OCR pipeline and the AI components. We had to redesign parts of the ingestion flow to include edge-based redaction and carefully decide what could be processed locally versus what could be safely sent to cloud services like Gemini for assistance.
Accomplishments that we're proud of
- 80% reduction in manual data entry time. What once took 10+ minutes now takes under 2 minutes per shipment.
- 98% matching accuracy between AI-extracted invoice data and existing warehouse stock records.
- A volunteer-first design that feels like a polished consumer app rather than a legacy back-office tool, which directly encourages consistent adoption.
- A generalizable architecture ready to deploy across multiple food banks, including the Blacksburg Interfaith Food Pantry, with minimal code changes required.
What we learned
We learned that in social-good technology, the volunteer experience is just as important as the feature set. If a tool is intimidating, it won't be used. Staff feedback consistently pushed us toward simplicity over sophistication. Most importantly, we learned to build with our users: every major feature (RBAC, the one-click transfer system, cost analysis, etc) came directly from a real conversation with the food pantry staff.
What's next for SimplyStocked
- Multi-Pantry Coordination: Scale the architecture so organizations like the Blacksburg Interfaith Food Pantry can share anonymized demand signals while maintaining fully independent inventories.
- Deeper Demand Forecasting: Expand the Gemini predictions engine to incorporate seasonal trends (like spikes in canned goods around the holidays) using a rolling year of checkpoint history. We would use the information our fully-custom trained machine learning model provides alongside other EOY information.
- Automated Price Auditing: Cross-reference vendor invoices over time to flag price creep and ensure pantries are always receiving the best subsidized unit rates.
- Implement Ollama model on the deployed application and not just when you run it locally.
Demo login
Username: admin Password: testpass123
Built With
- antigravity
- cloudrun
- cloudsql
- cors
- docker
- fastapi
- gemini
- google-cloud
- google-oauth
- machine-learning
- mysql
- ocr
- ollama
- python
- react
- typescript

Log in or sign up for Devpost to join the conversation.