-
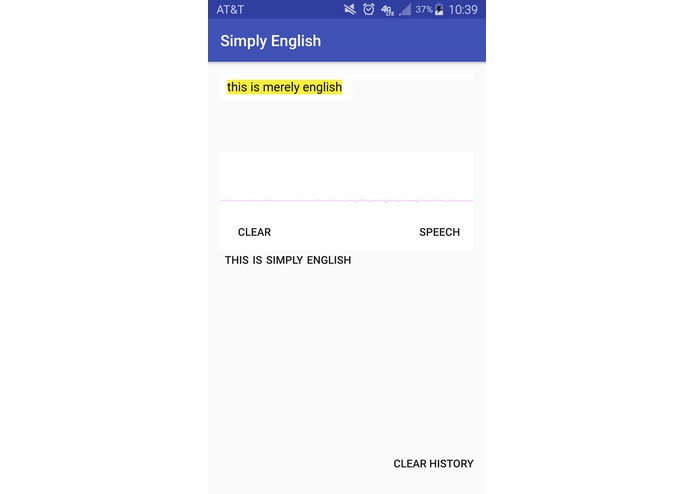
Speech Mode
-
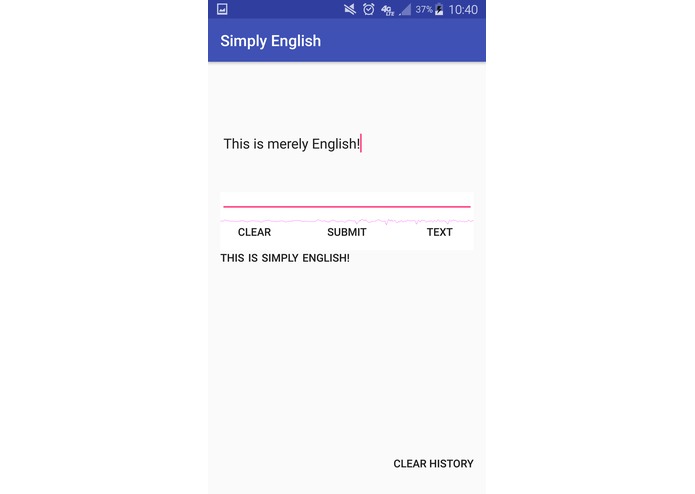
Text Mode
Just Imagine...
You are an aspiring foreign academic, come to the United States to participate in a prestigious academic conference. But alas! You speak English as a second language, and despite being highly intelligent, it's hard to keep up with the technical jargon used at every turn. Fortunately, now you have the app...
Simply English
An educational app that simplifies English, building personalized translations for you. Once you train the app by having it translate small blocks of text and specifying the translations that fit you, it then remembers your preferences for its real time speech-to-text functionality!
Motivation
From our three person team, one of us was an ESL student early in his education. Furthermore, each of us has many friends that aren't very comfortable with English. So we understand how difficult years of speaking with awkward French and Chinese accents, pretending to understand half of the conversations, and missing the important parts of movies can be. To alleviate some of those difficulties, we built Simply English.
How we built it
Simply English pulls from Merriam-Webster intermediate thesaurus to provide easy translation suggestions. We save the translation options you choose into the application's shared preferences (with our own data structure), making it quick and seamless to pull those synonyms back out. Finally, the voice recognition software first trains itself by running over a large set of "generic" English language (basically a recording of a conversation), and performing basic language parsing by matching sets of phones against its dictionary.
Challenges we ran into
Voice recognition is a problem that companies devote entire divisions to, and it's hard to replicate the accuracy of server-based speech recognizer's like Siri, especially in the limited time frame of a Hackathon. Furthermore, more natural language processing is needed to properly leverage the thesaurus in our application; for example, "hires" can be substituted by either "employs" or "employees".
Accomplishments that we're proud of
Despite the difficulty of the voice recognition algorithm, the fact that we could get it to work with any reliable degree of accuracy on a device with both limited storage and computational power was cause for celebration. Furthermore, we're quite proud of how smooth both the dynamic saving and loading of the user's suggested translations are.
What we learned
Throughout the project we delved into the algorithms behind voice recognition, and both designed and implemented our own primitive machine learning algorithms.
What's next for Simply English
More languages! Simply English is designed in such a manner that all English-specific pieces are loaded as assets, meaning they can be switched out with ease. Furthermore, the voice recognition only gets better with more sample data and more computational power; given more time, the optimizations and extra recordings we could make would bump our accuracy rate from ~60% to maybe somewhere around ~80%.
Built With
- android-studio
- c#
- java
- merriam-webster-dictionary
- pocketsphinx

Log in or sign up for Devpost to join the conversation.