-
-
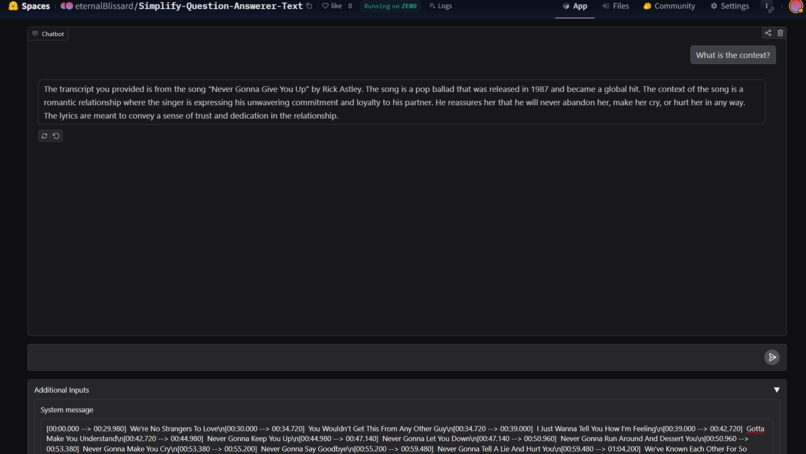
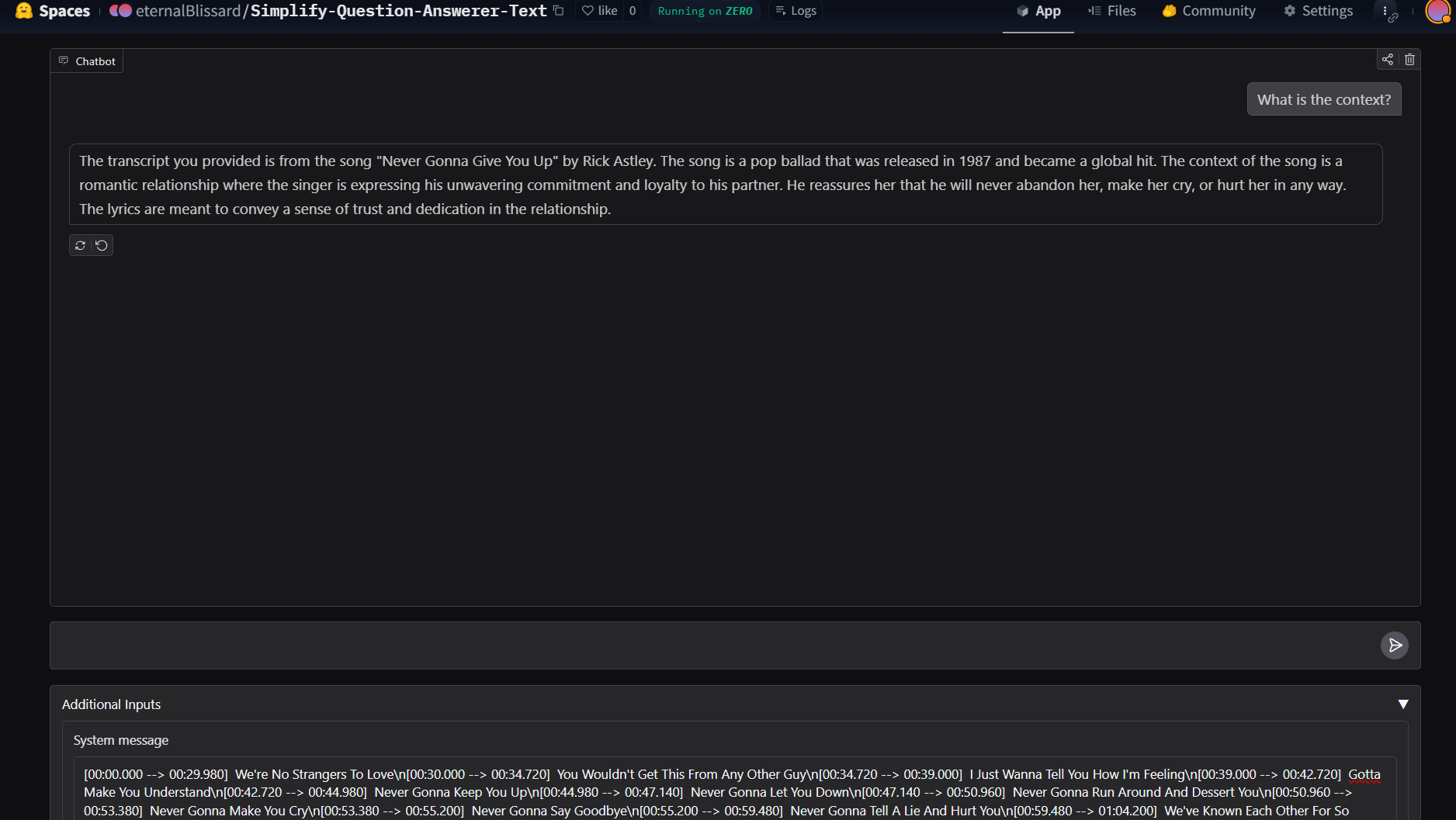
Chat Bot
-
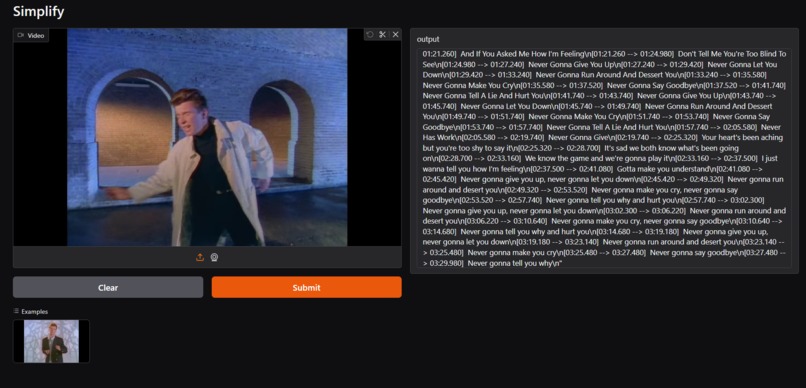
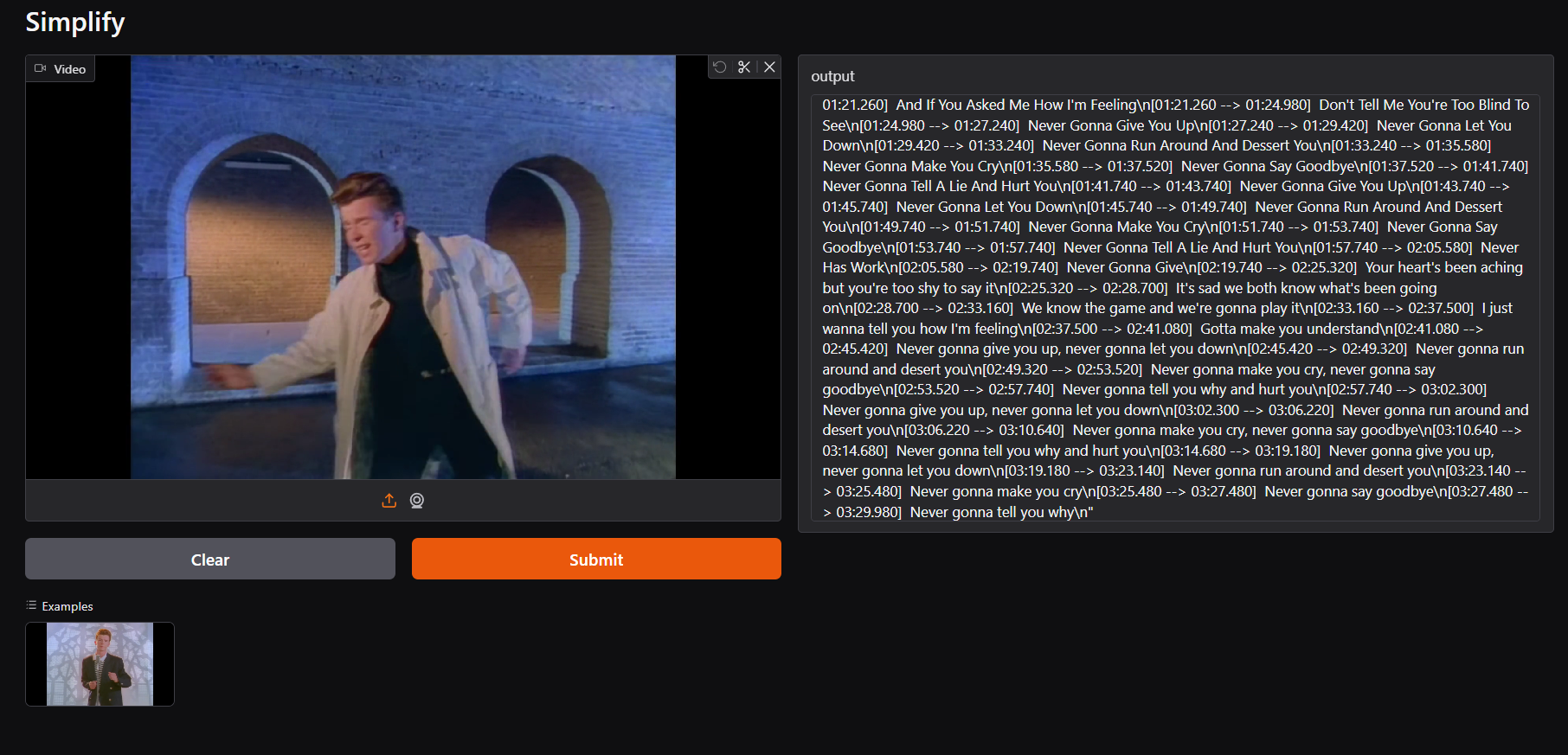
Transcriber Model
Inspiration
A "traditional chocolate scouffe" in Switzerland, which prompted me to look for its recipe online only to find none are there in english, mainly in german and none had subtitles as well. Rendering me helpless. Prompted me an idea to create a transcription model which requires someone 0 coding knowledge to use it.
What it does
It's a 3 model combo:
First Model takes in an video file, identifies the audio language, generates a transcript for that same language with time stamps. Ideal for content creators to get reach.
Second Model, powered by an LLM, takes in a video file and we can query regarding the video contents. Ideal, if a person doesn't wanna copy paste.
Third Model, takes in the transcript, it's much faster since 0 time taken for transcript generation and answers question on the go, ideal for improving understanding for a topic.
How we built it
I took a decent amount of time to figure out the problem to do. Tried various speech to text models from Deep Speech to Speech Recognition by google. Finally, settled with Whisper by OpenAI which is an open source model.
Need was to find a way to extract audio from video, this is taking place using ffmpeg, there are alternatives too like moviepy but they require a great deal of setup which a service like gradio on hugging face don't permit.
Choosing a chatbot with appropriate parameters for fast and accurate inferences. I chose the qwen2.5-72B model which is an open source model.
Then, it just down to putting everything together and bug smashing the new errors.
File Tracking was done through Hugging Faces Github has the Final Files and the Read Me is for Guidance of 'How to DO IT'!
Challenges we ran into
Ffmpeg and gradio pose issues together
Accomplishments that we're proud of
A free for all system
Accurate Results
What we learned
About use of speech-to-text
Video and Audio Processing
Gradio
What's next for Simplify
Scalibility: Since, the resources are limited, hence usage limited to some people at a time
Speed: Adding more resources to fasten the process
More Features: like overlaying text on video, adding language choice in transcription maker with an optimised API method
Built With
- huggingface
- python
- qwen
- torch

Log in or sign up for Devpost to join the conversation.