-

Logo
-

Homepage of the App!
-

Highlight text and we will do the rest for you!
-

Let us know how we can help you better!




💡 Inspiration
The objective of our application is to devise an effective and efficient written transmission optimization scheme, by converting esoteric text into an exoteric format.
If you read the above sentence more than once and the word ‘huh?’ came to mind, then you got my point. Jargon causes a problem when you are talking to someone who doesn't understand it. Yet, we face obscure, vague texts every day - from 'text speak' to T&C agreements.
The most notoriously difficult to understand texts are legal documents, such as contracts or deeds. However, making legal language more straightforward would help people understand their rights better, be less susceptible to being punished or not being able to benefit from their entitled rights.
Introducing simpl.ai - A website application that uses NLP and Artificial Intelligence to recognize difficult to understand text and rephrase them with easy-to-understand language!
🔍 What it does
simpl.ai intelligently simplifies difficult text for faster comprehension. Users can send a PDF file of the document they are struggling to understand. They can select the exact sentences that are hard to read, and our NLP-model recognizes what elements make it tough. You'll love simpl.ai's clear, straightforward restatements - they change to match the original word or phrase's part of speech/verb tense/form, so they make sense!
⚙️ Our Tech Stack
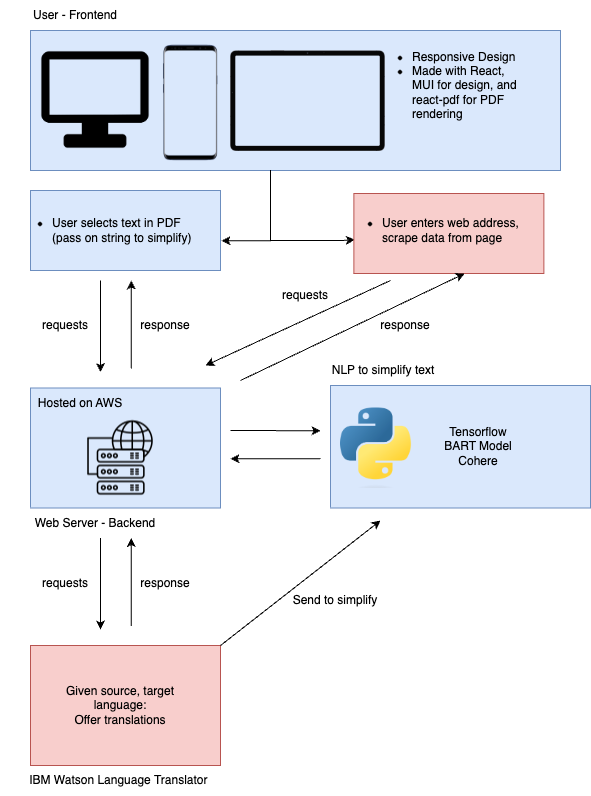
Frontend: We created the client side of our web app using React.js and JSX based on a high-fidelity prototype we created using Figma. Our components are styled using MaterialUI Library, and Intelllex's react-pdf package for rendering PDF documents within the app.
Backend: Python! The magic behind the scenes is powered by a combination of fastAPI, TensorFlow (TF), Torch and Cohere. Although we are newbies to the world of AI (NLP), we used a BART model and TF to create a working model that detects difficult-to-understand text! We used the following dataset from Stanford University to train our model- It's based on several interviews conducted with non-native English speakers, where they were tasked to identify difficult words and simpler synonyms for them. Finally, we used Cohere to rephrase the sentence and ensure it makes sense!
🚧 Challenges we ran into
This hackathon was filled with many challenges - but here are some of the most notable ones:
- We purposely choose an AI area where we didn't know too much in (NLP, TensorFlow, CohereAPI), which was a challenging and humbling experience. We faced several compatibility issues with TensorFlow when trying to deploy the server. We decided to go with AWS Platform after a couple of hours of trying to figure out Kubernetes 😅
- Finding a dataset that suited our needs! If there were no time constraints, we would have loved to develop a dataset that is more focused on addressing tacky legal and technical language. Since that was not the case, we made do with a database that enabled us to produce a proof-of-concept.
✔️ Accomplishments that we're proud of
- Creating a fully-functioning app with bi-directional communication between the AI server and the client.
- Working with NLP, despite having no prior experience or knowledge. The learning curve was immense!
- Able to come together as a team and move forward, despite all the challenges we faced together!
📚 What we learned
We learned so much in terms of the technical areas; using machine learning and having to pivot from one software to the other, state management and PDF rendering in React.
🔭 What's next for simpl.ai!
1. Support Multilingual Documents. The ability to translate documents and provide a simplified version in their desired language. We would use IBM Watson's Language Translator API
2. URL Parameter Currently, we are able to simplify text from a PDF, but we would like to be able to do the same for websites.
- Simplify legal jargon in T&C agreements to better understand what permissions and rights they are giving an application!
- We hope to extend this service as a Chrome Extension for easier access to the users.
3. Relevant Datasets We would like to expand our current model's capabilities to better understand legal jargon, technical documentation etc. by feeding it keywords in these areas.
Built With
- amazon-web-services
- bart
- cohere
- fastapi
- figma
- javascript
- materialui
- python
- react
- react-pdf
- tensorflow
- torch







Log in or sign up for Devpost to join the conversation.