-
-
Figma: Clean, mobile‑first design mockup for low‑literacy users on slow connections.
-
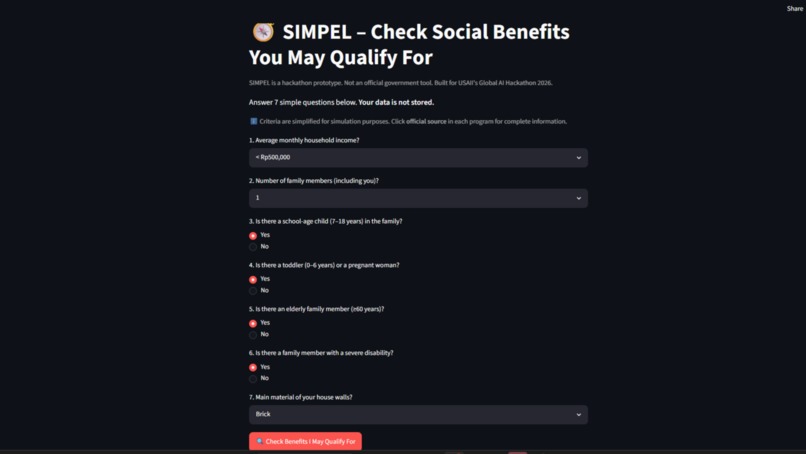
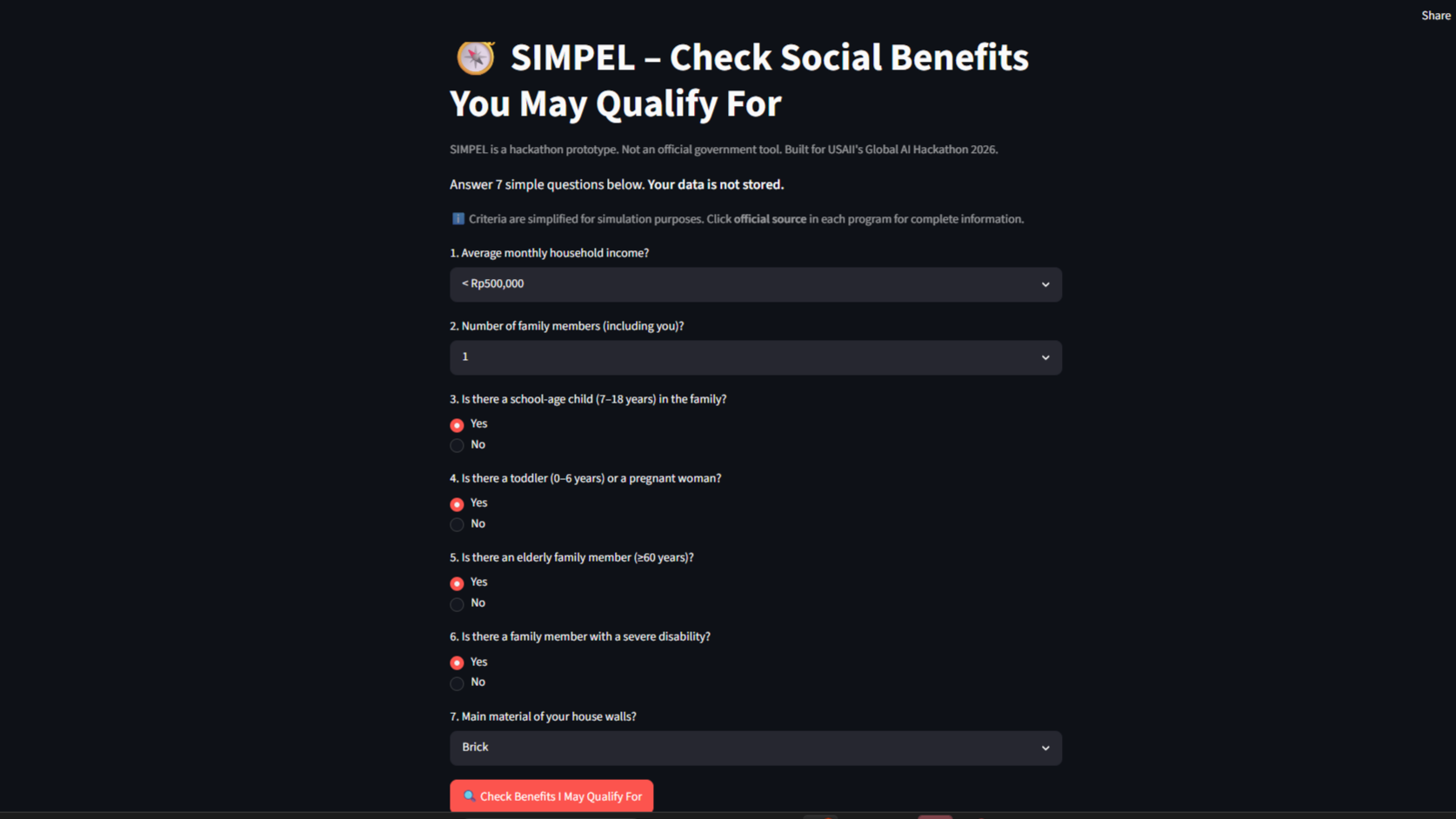
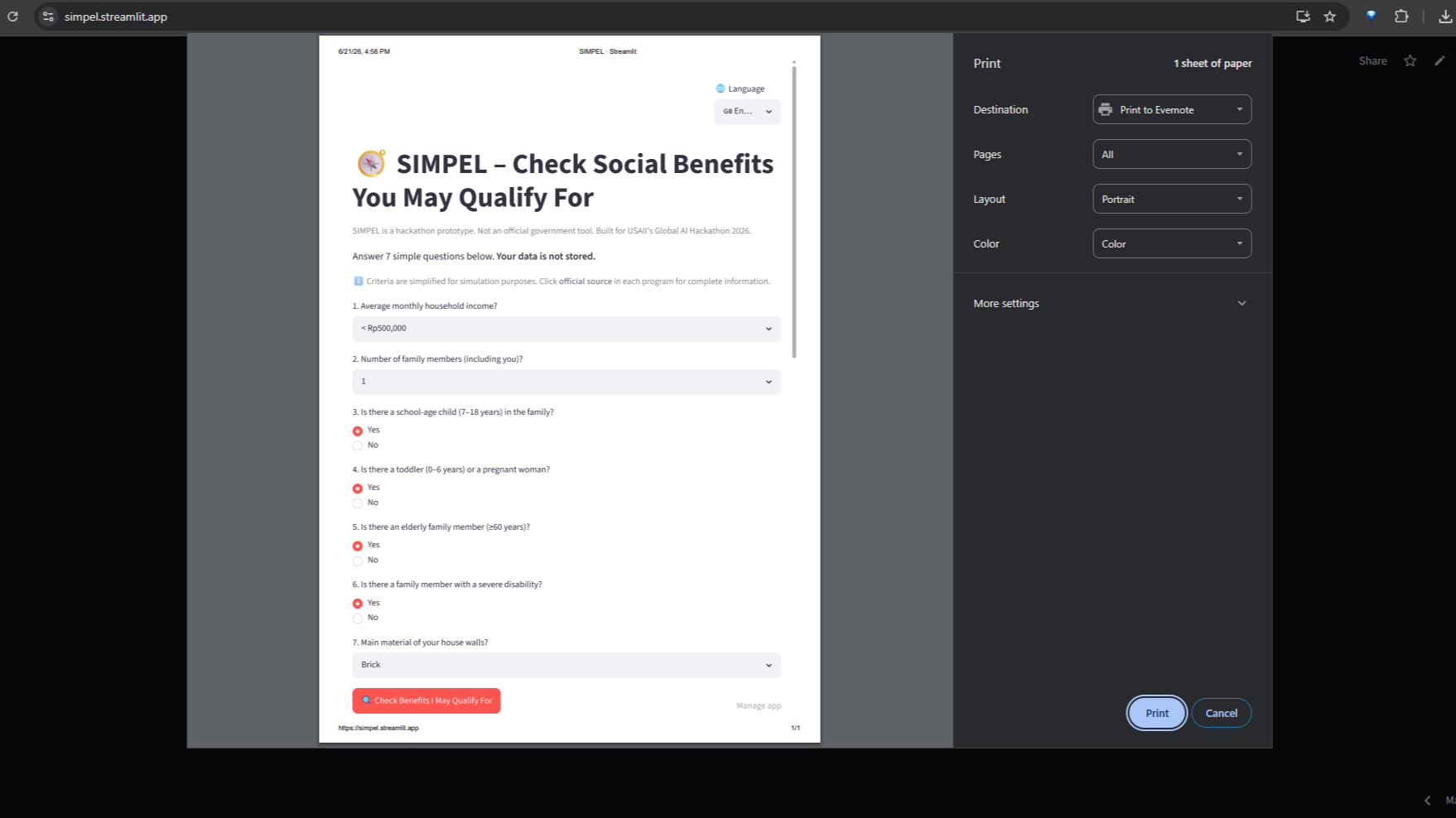
Streamlit: 7‑question intake form in Bahasa Indonesia/English – dropdowns and radio buttons, no typing.
-
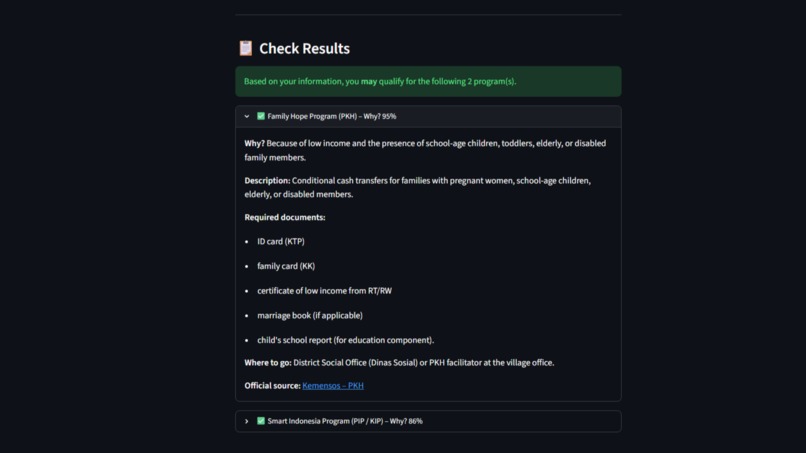
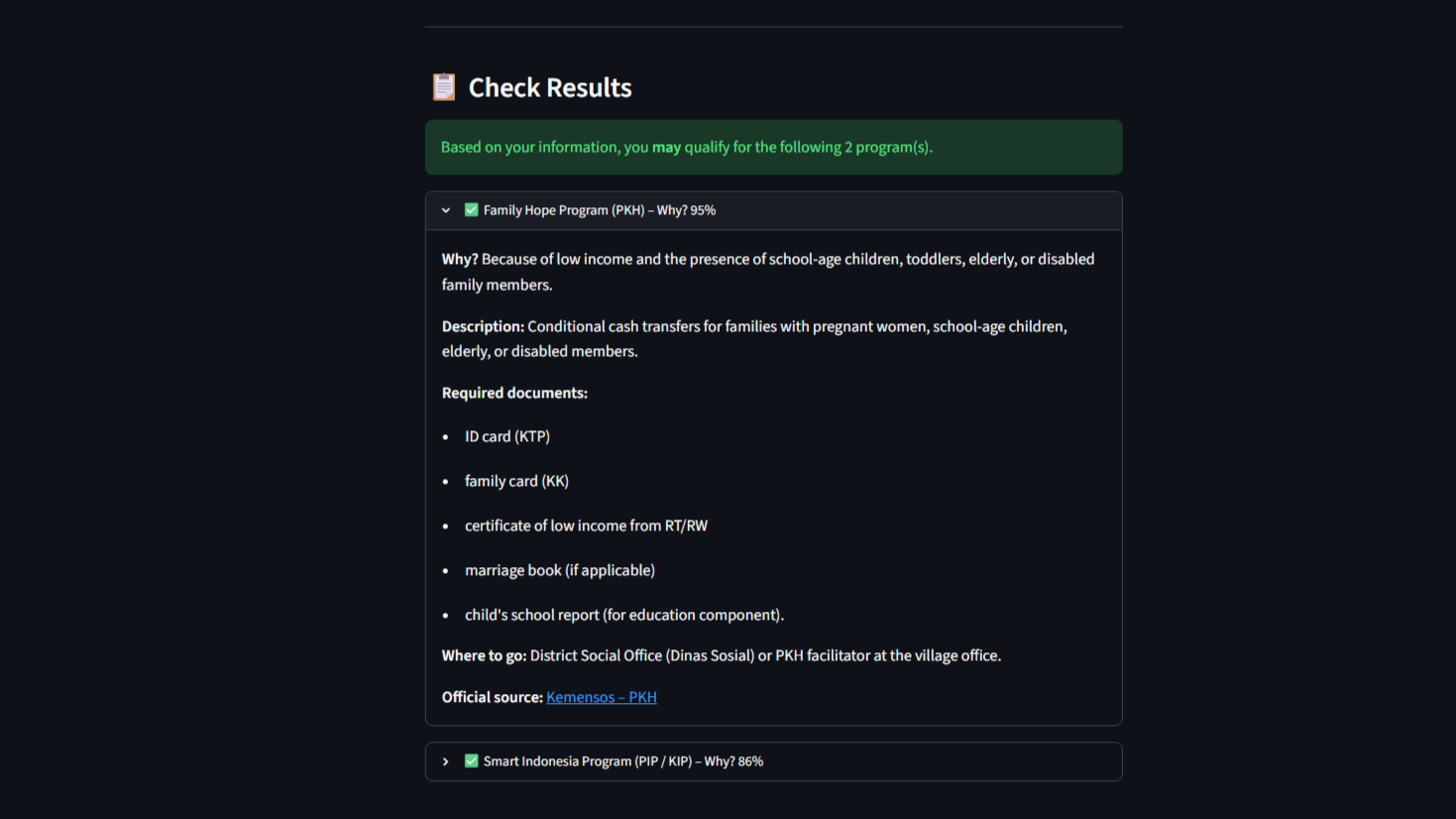
Streamlit: Expanded card: program name, confidence score, reason, description, required documents, and office location.
-
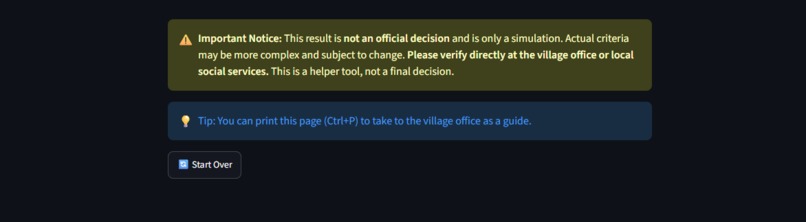
Streamlit: Yellow disclaimer, print tip, and reset button – AI suggests, never decides.
-
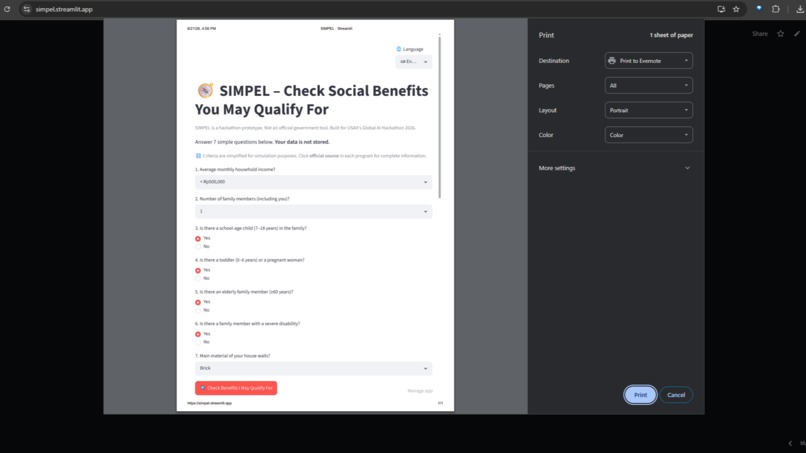
Streamlit: Print‑friendly result page (Ctrl+P) to bring a physical checklist to the village office.
Inspiration
Over eight million poor households in Indonesia miss out on welfare help every year—not because they are ineligible, but because tangled systems make access nearly impossible. Take Ibu Sari: a woman raising two kids alone, earning day by day in a village near Bogor, facing layers of official jargon scattered across several online platforms just to check if she qualifies for money, meals, education subsidies, or medical care. Under stress, with minimal reading skills and a sluggish 2G connection, she eventually stops trying.
SIMPEL—Sistem Informasi Mudah Pahami Eligibility Layanan (Simple Information System for Understanding Benefit Eligibility)—was built to answer one question: What makes things easier when life feels overwhelming? Every design choice flows from watching real people struggle with forms they barely understand.
What it does
SIMPEL asks seven plain‑language questions about income, family size, children, elderly, disability, and housing. No typing, no chatbot—just dropdowns and yes‑or‑no choices that work on a 2G connection.
A multi‑label Random Forest classifier instantly predicts which of Indonesia’s four largest national social programs the family may qualify for: PKH (cash transfers), BPNT (food assistance), PIP (school aid), and PBI‑JKN (free healthcare). One family can be flagged for multiple programs at once. Each recommendation comes with:
- A confidence score, deliberately capped at 95% — never “100% certain”
- A plain‑language explanation:
- Mengapa?— a simple reason in Bahasa Indonesia, e.g., “Karena pendapatan rendah dan terdapat anak usia sekolah.”
- Tentang— a jargon‑free description of the program
- Dokumen— a checklist of required documents (KTP, KK, SKTM, etc.)
- Langkah— the exact office to visit (Dinas Sosial, kelurahan, school, or BPJS branch)
- A direct link to the official program source:
A note on sources: Official portals for PKH and BPNT were intermittently unreachable during our submission window—a real‑world reminder of the infrastructure challenges our users face daily. The rules were verified against official Kemensos documentation before training and simplified into the seven‑question flow. In production, we plan to integrate directly with the DTKS database so program rules remain current regardless of website availability.
A persistent yellow disclaimer reminds users that this is not an official decision and must be verified at the kelurahan. The app stores nothing—a page refresh or tab close wipes all session data.
The page is print‑friendly (Ctrl+P), and a one‑click download button provides a text copy for reliable offline printing — ensuring the checklist reaches the urban village even when browser print fails.
How we built it
The entire application is a single‑file Python web app built with Streamlit, deployed on Streamlit Cloud’s free tier. No separate backend, no database, no paid APIs. This simplicity was a deliberate choice: keeping everything in one place means the tool can be cloned, adapted, and run by community workers with zero budget.
Under the hood, the AI engine works like this:
- Model: Multi‑label Random Forest (scikit‑learn, 100 trees, max‑depth=5) for interpretability and fast inference. We chose Random Forest over a neural network or an LLM because it is interpretable—feature importance shows exactly why a recommendation was made—and its deterministic output lets us guarantee the system will never tell a user they “definitely qualify,” something we cannot control with a generative model.
- Training data: 5,000 synthetic households generated programmatically; 2,773 qualified under simplified official rules. To teach the model when not to recommend aid, we added 1,500 negative samples (wealthy families, brick houses, no dependants), yielding 4,273 final rows.
- Features (7): income bracket, family size, school‑age child, toddler/pregnancy, elderly, disability, wall material. No personal identifiers.
- Labels (4): PKH, BPNT, PIP, PBI_JKN—output simultaneously.
- Training pipeline: Jupyter Notebook handles generation, train/test split, confusion matrices, classification reports, and feature importance. We manually tested edge cases (wealthy families, elderly alone, childless households).
- Artifacts: Model + encoder serialized with joblib, under 3 MB. Cached once in memory; inference <10 ms, no external API calls.
Responsible AI: Every safeguard—confidence capping, "maybe" phrasing, persistent disclaimer, ephemeral state, human‑in‑the‑loop—was designed into the architecture from day one, not pasted on later.
Design: Mobile‑first Figma prototype. Structured questionnaire over chatbot because predefined steps work better with limited literacy and unstable internet.
Deployment: Streamlit Cloud free tier, pulling from a public GitHub repo containing all model files
Challenges we ran into
False‑positive bias. Our first model gave an 80% PKH confidence to a wealthy family with no qualifying traits—found through manual edge‑case testing, not aggregate metrics. Cause: PKH appeared in 85% of training data. Fix: added 1,500 negative samples and reduced PKH label noise from 5% to 0.5%. The model now suppresses false positives while keeping high recall for eligible families.
Environment configuration. Windows PATH issues blocked streamlit and jupyter. Solved with python -m and moved training to Google Colab to eliminate local friction.
Simplicity vs. expectations. We skipped chatbots, LLMs, and databases. Would a single‑file app with “just” Random Forest feel substantial? We anchored every choice—max‑depth, confidence capping, ephemeral state—in documented rationale,turning simplicity into rigor.
Accomplishments that we're proud of
- Fairness debugged before deployment. Caught and fixed a real bias (the 80% PKH false positive) through manual testing.
- 100% truthful demo. Every feature in the pitch exists in the live app—no fabricated screens.
- Responsible AI baked in. Confidence limits, “mungkin” phrasing, persistent disclaimer, ephemeral state, and human‑in‑the‑loop were foundational decisions.
- Zero‑cost, replicable pipeline. Free tiers only—any community worker can clone and adapt it.
- Speed of execution. From idea to working AI live app in two days; the rest spent on testing, refinement, and documentation.
- Scalable potential. If adopted by even 1% of Indonesia’s 70,000 village facilitators (kader), SIMPEL could help screen eligibility for over 2 million families annually—reducing the administrative time per family from hours to under three minutes.
What we learned
- Manual edge‑case testing is irreplaceable. The bug was invisible in the F1‑score; extreme scenarios exposed it.
- Simplicity is a feature. Seven predefined questions beat a chatbot for stressed users on bad connections.
- Responsible AI must be upfront. Guardrails like confidence capping belong in the architecture from day one.
What's next for SIMPEL – AI Benefits Navigator for Indonesian Families
- 🗣️ Voice input — speech‑to‑text for illiterate users.
- 🌐 Multi‑language support — Javanese, Sundanese, and other regional languages.
- 📱 WhatsApp & SMS integration — results delivered directly in chat apps, no browser needed.
- 📴 100% offline execution — compile the model to pure JavaScript via m2cgen so it runs on basic mobile browsers without internet.
- 🏛️ DTKS database integration — real‑time eligibility verification.
- 💬 Guardrailed supplementary chatbot — answers only follow‑up questions about programs, documents, and procedures; sandboxed to prevent prompt injection or off‑topic use. It explains, never decides.
Built With
- deepseek
- figma
- github
- google-colab
- joblib
- jupyter-notebook
- matplotlib
- numpy
- pandas
- python
- scikit-learn
- streamlit
- streamlit-cloud



Log in or sign up for Devpost to join the conversation.