-
-
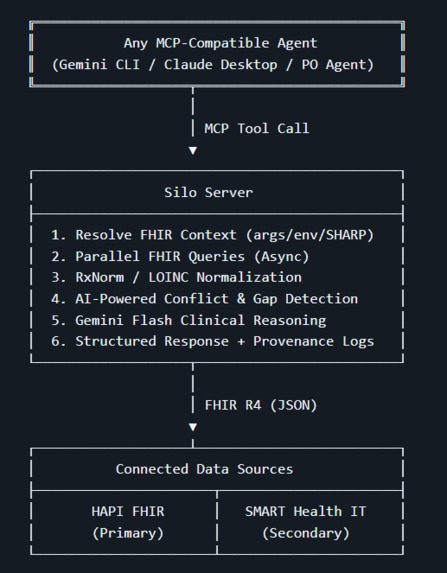
Silo Architecture: Seamlessly connecting the overarching AI Agent to siloed HAPI and SMART FHIR databases in real-time.
Inspiration
Every clinician has experienced it. You are treating a patient and you know their full medical history is somewhere — spread across the hospital system, the pharmacy, the specialist they saw two years ago, the lab that emailed results as a PDF. You make your decision with whatever fragment you can access in the time you have.
This is not a technology problem that nobody is working on. FHIR exists precisely to solve it. But knowing that a standard exists and having tools that actually bridge the gap for AI agents are two different things.
When i read the hackathon brief, one phrase stood out: interoperability. Not as a buzzword — as a clinical safety problem. Medication reconciliation failures at care transitions are among the most preventable causes of patient harm. They happen not because clinicians are careless but because the data they need exists in a system they cannot see from where they are standing.
That is what Silo was built to solve.
What it does
Silo is a Model Context Protocol server that acts as a universal FHIR R4 interoperability layer for AI agents. Any MCP-compatible agent — running on Prompt Opinion, Gemini CLI, Claude Desktop, or any other platform — can call five clinical tools that collectively break down the data silo:
- DetectMedicationConflicts — finds the dosage discrepancies that happen when a prescription is updated in one system but not another
- UnifyPatientRecords — resolves patient identity across disconnected FHIR silos and produces a single auditable Master Patient Record
- IdentifyCareGaps — identifies the overdue screenings and unaddressed risk factors that fall through the cracks of siloed records
- SmartClinicalQuery — answers natural language clinical questions against live FHIR data without hallucinating findings not in the record
- ExplainDataProvenance — produces a complete audit trail of every data source used, so every clinical claim is traceable to its origin
What makes each tool more than a FHIR wrapper is the GenAI reasoning layer. A rule engine can flag that a patient has two active Metformin entries at different doses. Only a clinical AI can explain that this pattern is consistent with a dose titration updated in the pharmacy but not the EHR, identify it as a reconciliation failure at a high-risk transition point, and recommend a specific next action for the clinician.
How I Built It
The stack is Python 3.11, FastAPI, and FastMCP for the MCP protocol layer. Google Gemini Flash handles all LLM reasoning calls. FHIR data comes from HAPI FHIR R4 as the primary silo and SMART Health IT as the secondary silo for patient record unification.
The architecture has three layers:
Collection — parallel async FHIR queries using asyncio.gather
so multiple resource types are fetched simultaneously rather than
sequentially. Every query is bounded with _count=50 and cached
with TTL so repeated calls within a session return instantly.
Normalization — a cascaded four-level RxNorm strategy for every medication: exact string match → normalized match (strips salt modifiers) → approximate match → LLM fallback. Conflict detection groups by active ingredient, not RxNorm ID, which is the critical distinction that catches brand-generic equivalences like Metformin and Glucophage being flagged as the same drug regardless of how each system names it.
Reasoning — each tool constructs a minimal prompt containing only the fields the LLM needs for clinical reasoning, calls Gemini Flash with a structured JSON output schema, caches the result by SHA-256 prompt hash, and wraps the call with a timeout that degrades gracefully to structured data rather than timing out the agent.
A three-priority FHIR context resolution system (resolve_fhir_context)
makes the server fully source-agnostic:
- Tool arguments → any agent, explicit parameters
- .env defaults → local development and testing
- SHARP headers → Prompt Opinion platform, injected automatically This design means the exact same server works identically whether called from the PO platform, Gemini CLI, or a test script — with no code changes and no platform dependency hardcoded anywhere.
Challenges I ran into
The ContextVar trap — The original session log implementation
used Python ContextVar to track FHIR requests for provenance
auditing. This worked perfectly in testing. In production,
stateless_http mode on FastMCP creates a new asyncio task per
request — and ContextVar is task-scoped. Logs written by
DetectMedicationConflicts in task N were invisible to
ExplainDataProvenance in task N+1. The fix was replacing
ContextVar with a module-level dict keyed by patient ID,
giving cross-request persistence while maintaining per-patient
isolation and bounding memory with a MAX_LOG_ENTRIES_PER_PATIENT
cap.
Normalization is harder than it looks — The RxNorm API has three match modes and none of them reliably handles all the ways a medication can be named in a real FHIR record. "METOPROLOL SUCCINATE 200MG TAB", "metoprolol", "Lopressor", and "metoprolol tartrate" are all the same drug but require different normalization strategies. Building the cascaded pipeline with preprocessing (stripping salt modifiers, expanding abbreviations) and an LLM fallback for brand names was the piece that made conflict detection clinically meaningful rather than just technically functional.
Timeout management — Each tool makes parallel FHIR queries
plus one LLM call. On cold cache with a public FHIR sandbox,
the total can hit 8-12 seconds — well above agent timeout
thresholds. The solution was not to remove the LLM call (that
kills the AI Factor) but to minimize prompt size to only
clinically relevant fields, replace the Phase 1 LLM call in
SmartClinicalQuery with a deterministic keyword router
(saving 2-4 seconds), and wrap every LLM call with
asyncio.wait_for so tools always return structured data
within the timeout window even if the narrative is a fallback.
Dual-mode architecture — Tools built exclusively for PO's SHARP header injection break immediately when called from any other agent. Building the three-priority context resolution system from the beginning — rather than trying to retrofit it later — was the design decision that made the server genuinely reusable and allowed testing with Gemini CLI throughout development without any PO dependency.
Accomplishments That I'm Proud Of
A server that works with any agent, not just one platform The three-priority FHIR context resolution system — tool arguments first, environment defaults second, SHARP headers third — means Silo works identically from Gemini CLI, Claude Desktop, a test script, and the Prompt Opinion platform without a single line of code changing between them. Building platform independence into the architecture from day one rather than bolting it on later is the decision i'm most proud of technically.
Cascaded RxNorm normalization that actually works Most FHIR integrations do a single API call for drug name normalization and accept whatever comes back. Our four-level cascaded pipeline — exact match, normalized match, approximate match, LLM fallback — with active ingredient grouping for brand-generic detection handles the real-world messiness of how medications are named across systems. The difference between grouping by RxNorm ID and grouping by active ingredient is the difference between missing a Metformin-Glucophage duplicate and catching it. That distinction matters clinically.
GenAI reasoning that explains, not just detects Every tool in the project produces output that a deterministic algorithm cannot. I am proud that the LLM reasoning step in each tool is not decorative — it is the clinically meaningful part. The conflict classification, severity scoring, and recommended action are all rule-based. The explanation of what the conflict means for this specific patient, why it happened, and exactly what the clinician should do next is what Gemini Flash contributes. That division of responsibility between deterministic logic and generative reasoning is the architecture i'm most proud of from a clinical AI design perspective.
Solving the ContextVar cross-request isolation bug Discovering that Python ContextVar is task-scoped in stateless HTTP mode — and that this silently caused ExplainDataProvenance to always return empty results because logs written in one request were invisible in the next — was one of the hardest bugs in the project. It looked like a data bug, behaved like a concurrency bug, and was actually an asyncio task isolation problem. Replacing ContextVar with a module-level dict keyed by patient ID, with per-patient memory bounds and deduplication, solved it completely. I'm proud I found it and fixed it rather than working around it.
Five tools that tell a single coherent clinical story Each tool is independently useful. Together they answer the question a clinician actually needs answered before a patient encounter: who is this patient across all systems, what are they taking and does it conflict, what care are they missing, what do their records show, and where did all of this data come from. That narrative arc — unify, detect, identify, query, audit — was deliberate from the first design session and i'm proud that the final submission delivers it end to end.
Timeout resilience without sacrificing the AI Factor Every tool calls a live LLM. On cold cache with a public FHIR sandbox, that is 8-12 seconds of execution time. I'm proud that I solved the timeout problem without the easy answer — removing the LLM call. The combination of Gemini Flash, minimal prompt construction, deterministic query routing for SmartClinicalQuery, and graceful timeout fallback means every tool always responds within the agent threshold while still producing genuine GenAI clinical reasoning on every successful call.
A production-grade submission, not a demo The gap between a hackathon demo and something a hospital integration engineer could build on is large. I'm proud that Silo closes most of that gap: proper async architecture, TTL caching at both the FHIR and LLM layers, structured logging without PHI, Pydantic v2 response validation, tenacity retry with exponential backoff, source provenance on every response field, and a confidence score derived from actual data completeness rather than hardcoded values. A real clinician asking where a recommendation came from gets a real answer.
What I Learned
FHIR is a solved protocol. The hard problem is not speaking FHIR — it is knowing which fields to trust, how to compare data across systems that use the same standard differently, and how to surface conflicts in a way that is clinically meaningful rather than technically correct but practically useless.
The AI Factor in healthcare is not about replacing clinical judgment. It is about giving clinicians the complete picture — the unified, reconciled, gap-analyzed view of a patient that no single system currently provides — so that the judgment they apply is informed by everything that is known, not just everything that happens to be visible from where they are standing.
What's Next for Silo
The next step is connecting Silo to real EHR systems via SMART on FHIR authorization — the same protocol, real hospital endpoints. The architecture is already built for it: swap the sandbox URLs for production FHIR endpoints with OAuth tokens, and every tool works without modification.
The longer-term vision is a Rounds Agent — an A2A-enabled agent that calls Silo before every clinical encounter, automatically surfacing the medication conflicts, care gaps, and data discrepancies a clinician needs to know before they walk into the room.

Log in or sign up for Devpost to join the conversation.