-
-
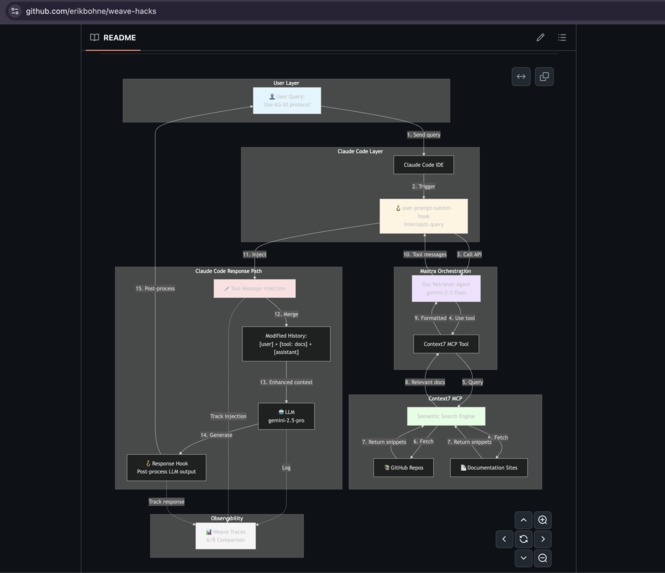
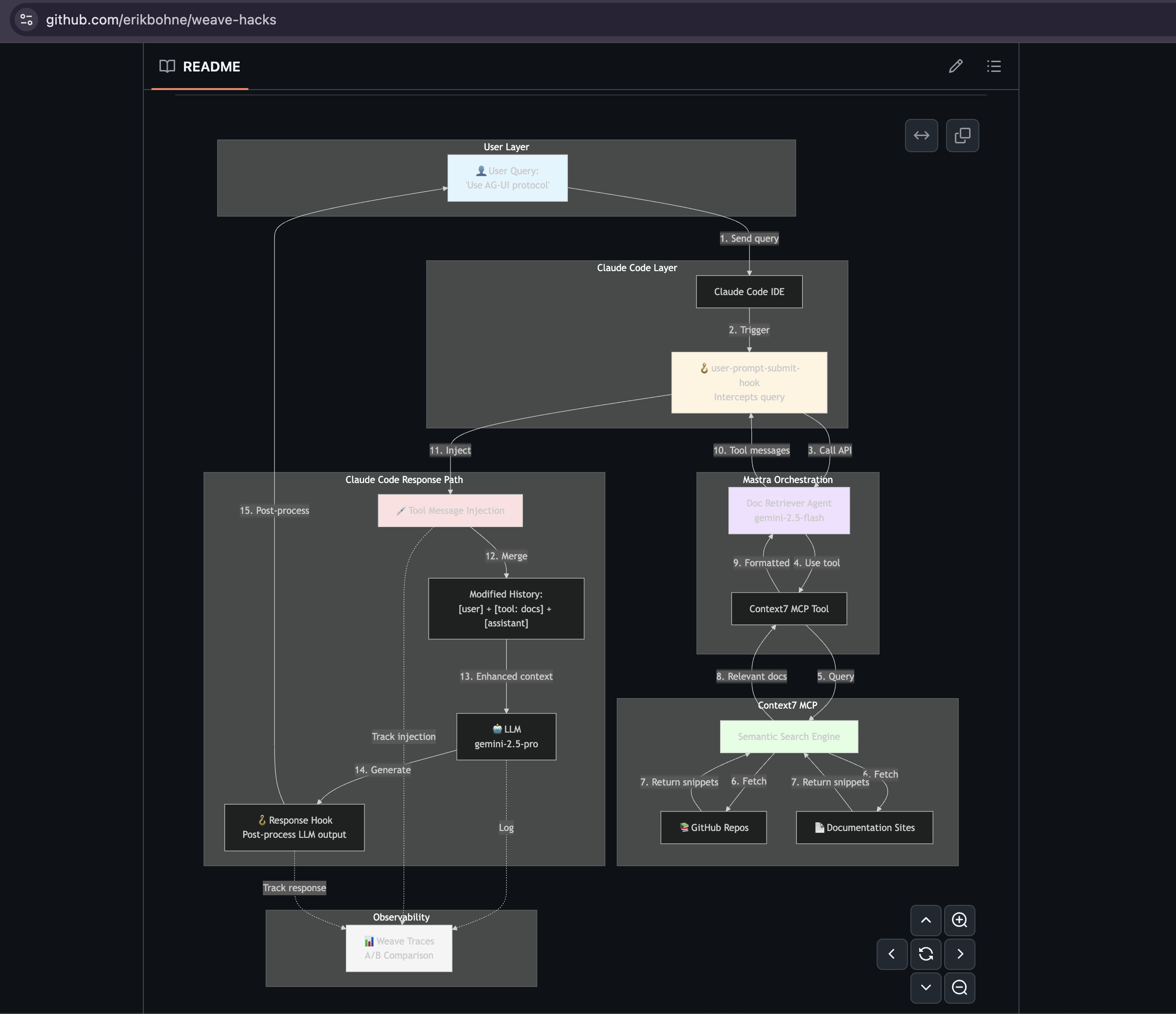
Project architecture
Silicon Valhalla — The Documentation Injection Agent
Inspiration
When using Claude Code, one major reason people hesitate to full send it with code generation is the knowledge cutoff.
Knowledge cutoffs limit us from using code agents with the latest versions of libraries like Pydantic, FastAPI, and LangChain, because updates are shipping at record speed — and it’s too expensive to constantly retrain frontier models just because Pydantic deprecated .json() for model_dump_json().
But do we really need to fine-tune LLMs every time docs change?
Is there a more efficient way?
Or is it enough to simply tell them they don’t know what they don’t know — and just prompt-inject the relevant documentation?
What It Does
The Documentation Agent automatically injects live documentation into Claude Code sessions whenever the user references a package (Python / Node / C++) that has had a major update since the model’s knowledge cutoff (February 2025).
So either:
- When a user prompts something like “How do we stream from sub-agents using LangGraph?”, or
- When Claude Code makes a change involving, say, Pydantic — which we know it doesn’t have updated info on —
we inject the latest documentation from “Context 7.” (MCP/ API for up-to-date markdown documentation)
How We Built It
We created a custom hook in Claude Code that calls a Mastra Agent running open-source models via Weights & Biases (wandb).
The hook triggers the Mastra Agent when relevant to fetch the latest documentation.
All agent calls are traced, and Claude Code sessions are sent to an evaluation pipeline in wandb.ai for performance review.
The evaluation pipeline checks if Claude Code actually used the injected documentation.
If not, the Mastra Agent tweaks its own system prompt — adding few-shot examples when needed — to improve future injections automatically.
Challenges We Ran Into
The hardest part? Keeping up.
Coming from Norway, we sometimes feel a bit behind on what’s new (that’s partly why we’re here!).
We had never used Mastra, Weave, BrowserBase, or Daytona — so naturally, we tried them all.
The challenge was to scope it down and nail two of them: Mastra and Weave.
Other than that — we’re pretty good at GenAI stuff, so we managed.
Accomplishments We’re Proud Of
We’re most proud of building something that’s deployable and scalable within the Weave ecosystem.
From never having used the service, we’re now ready to deploy the system so all Claude Code users can attach the hook and start documentation-injecting their sessions.
It actually works great — and it’s super fast!
What We Learned
We learned how to use Weave for:
- Building datasets ready for fine-tuning (Serverless RL),
- Tracing and evaluation pipelines, and
- Creating and deploying Mastra Agents, which turned out to be both powerful and surprisingly easy (at least locally for now).
What’s Next for Silicon Valhalla
Instead of only doing prompt-level fine-tuning, we want to fine-tune the models running under the hood of the get-docs-inject agent — using our evaluation dataset.
As Alex from Weave said: “You need data before you can fine-tune.”
So for now, it’s not mature — but we see massive potential.
Our next step is to use the saved Claude Code sessions from the evaluation pipeline to fine-tune, say, a 120B GPT-OSS model, to help Claude understand how to be documentation-injected even better.
Made with ❤️ from Norway
Team Silicon Valhalla


Log in or sign up for Devpost to join the conversation.