-
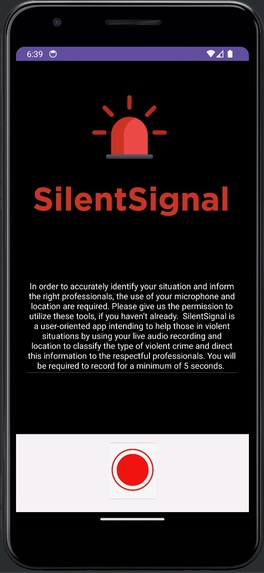
This is the home screen where users are prompted for their permission to use the mic, with a short summary of getting started with the app.
-
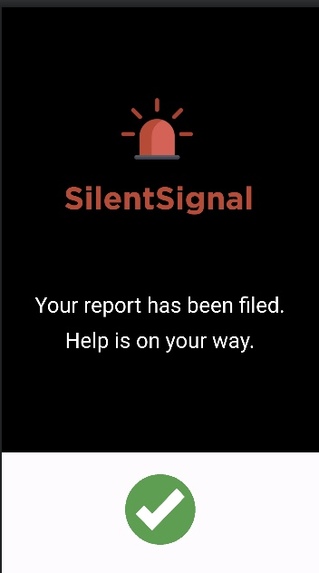
This is the final screen after the appropriate emergency responders have been contacted.
-
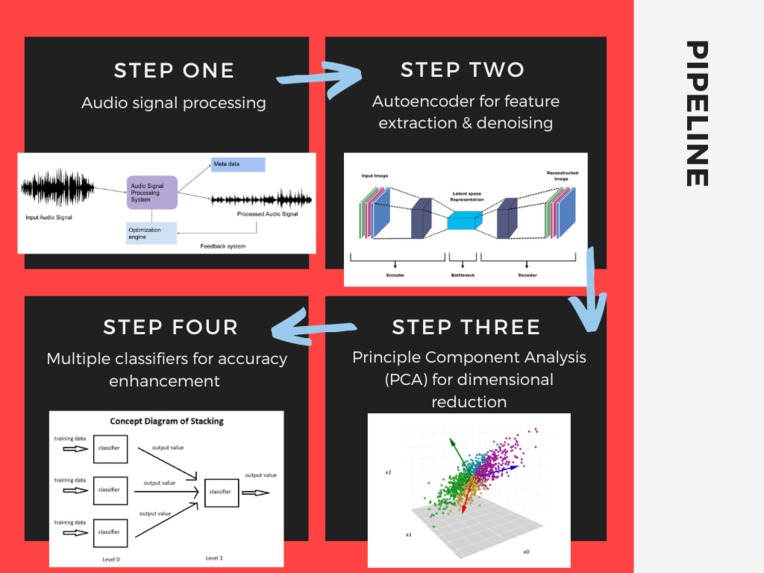
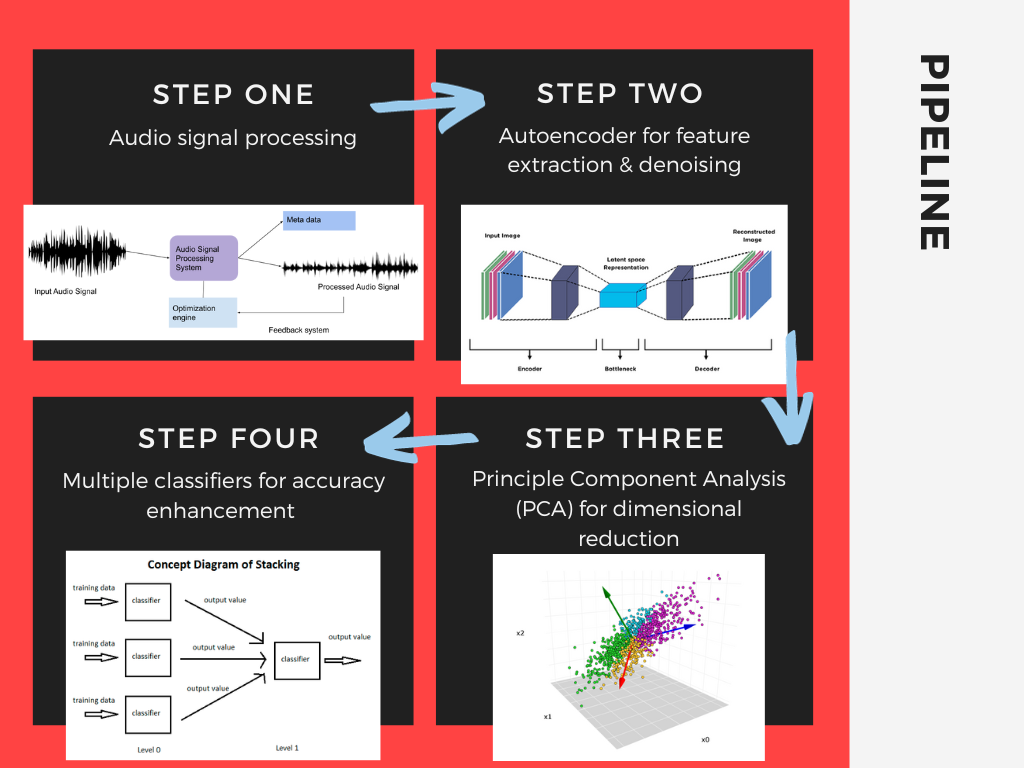
Our pipeline involved transferring audio data to multiple classifiers.
Inspiration
Approximately half of the United States’ annual violent crimes are reported each year. Much of this discrepancy can be attributed to a widespread fear of calling 911. To provide a safeguarding mechanism for situations precluding conventional means of communication, our project undertakes the development of a sophisticated real-time monitoring and alerting system.
Identifying the difficulty of talking aloud in many situations showed us the immense potential that an audiocentric emergency reporting app has to reduce this statistic. This system is predicated upon intricate audio data analysis for the explicit purpose of crime detection and the facilitation of swift emergency response.
What it does
At the heart of this convenient app lies a high-level architectural framework for audiocentric crime detection. The crux of our technical infrastructure is the application of advanced deep learning paradigms, notably the integration of stacking classifiers, which consists of multiple classifiers such as RandomForestClassifier, SGDClassifier, Support Vector Classifier, etc.
Augmenting this neural architecture is the strategic deployment of integration of classification models as well as data transformation and dimension reduction, thereby optimizing the intricate classification of audio clips based on the nature of the crime they encapsulate.
How we built it
The backend of the pipeline was written in Python, using Flask and Django as the backbone. The backend is supported by a pipeline of stacking classification models that determines the type of crimes the users ran into by collecting the surrounding ambient sounds that could signal a dangerous environment.
For the frontend, we utilized Android Studio to create the interactive user interface of the project, which will enhance the user experience when using the application. The minimalist design for the frontend ensures that the users can spend the least amount of time interacting with our product as it is designed for emergency use, thus requiring minimum initiation steps. The integration of the interactive frontend with a convolutional, yet efficient backend are the characteristics of our product.
Challenges we ran into
ML Model: We struggled to find the right parameters for the classification model that resulted in a notable amount of time spent on adjusting minor values to maximize accuracy.
Android Studio: It was difficult to create a minimal user interface that would recognize a finger holding the record button in loops of 5 seconds. There was some unexpected difficulty in using the “Audio Recorder” constructor of Android Studio that provides live feedback as the audio is being fed in.
Accomplishments that we're proud of
The foundation of our app depends on the pipeline developed to classify types of violent crimes. Though the accuracy of the model could be improved on in the future, it was a fundamental step towards knowing that we could bring safety many steps closer to individuals in such dangerous situations.
What we learned
Among others, we learned that it’s important to achieve the overall goal first - regardless of how well it was reached. We struggled to maximize our accuracy with the pipeline - having switched from CNN to our original method largely due to a lack of computation power - but had to realize that it is better to walk away with something over nothing.
What's next for SilentSignal
Shorter timeframe & location In the future, it would be greatly beneficial to be able to shorten the required timeframe of 5 seconds so that we can identify and report situations where even that is too long. Additionally, it is crucial to know where the user is located as we will be contacting local officials, so this is also an area of interest.

Log in or sign up for Devpost to join the conversation.