-
-
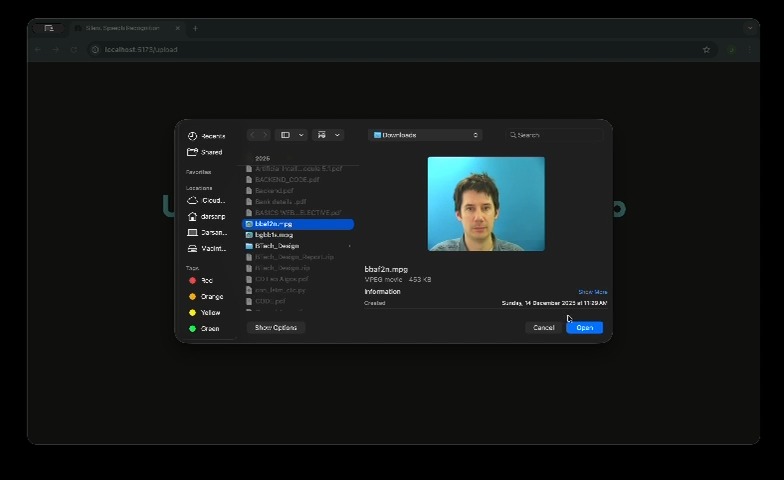
Grid model test data results
-
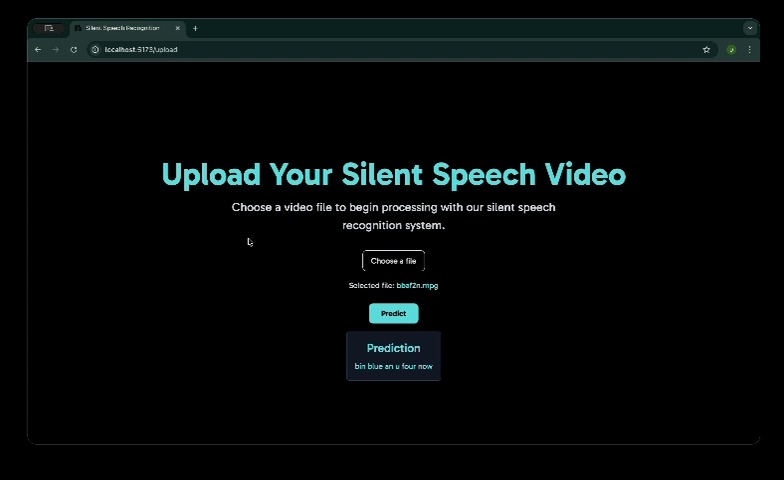
Grid model test data results
-
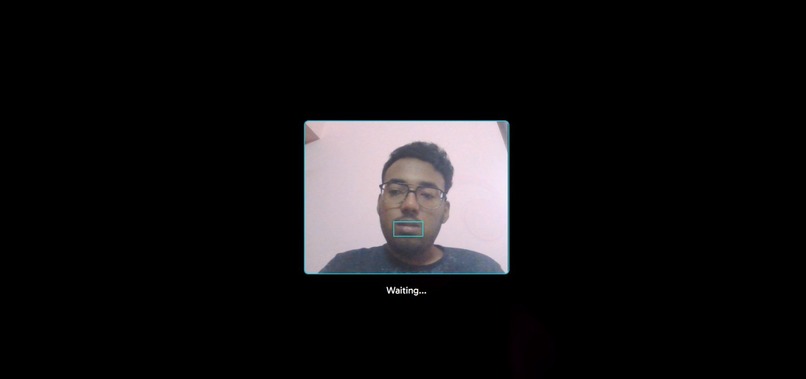
Grid model real-time results
-
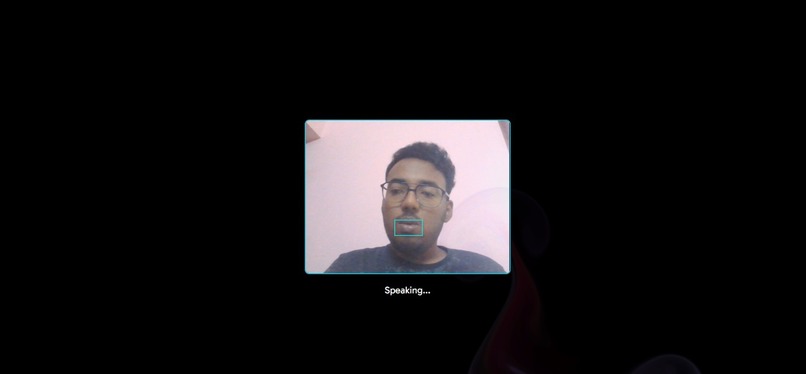
Grid model real-time results
-
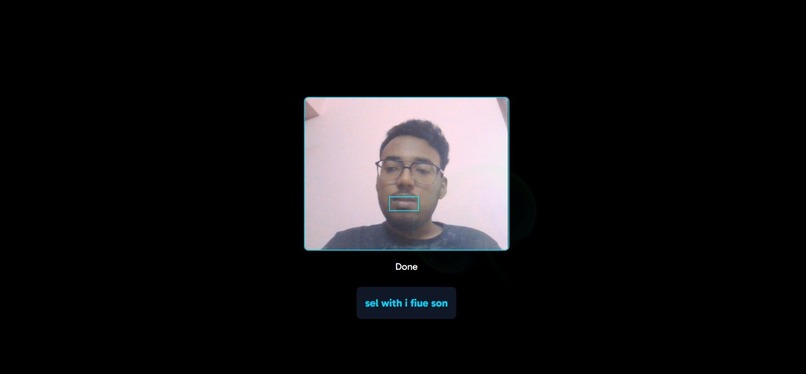
Grid model real-time results
-

custom model test data results
-
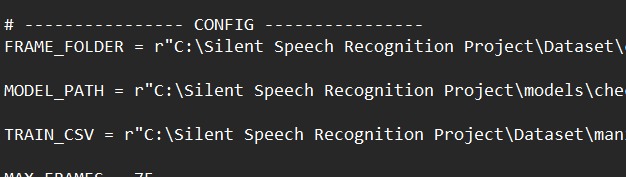
Custom model test data results
-
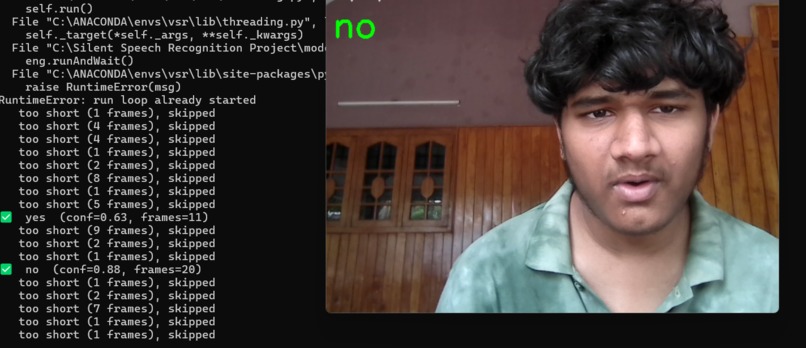
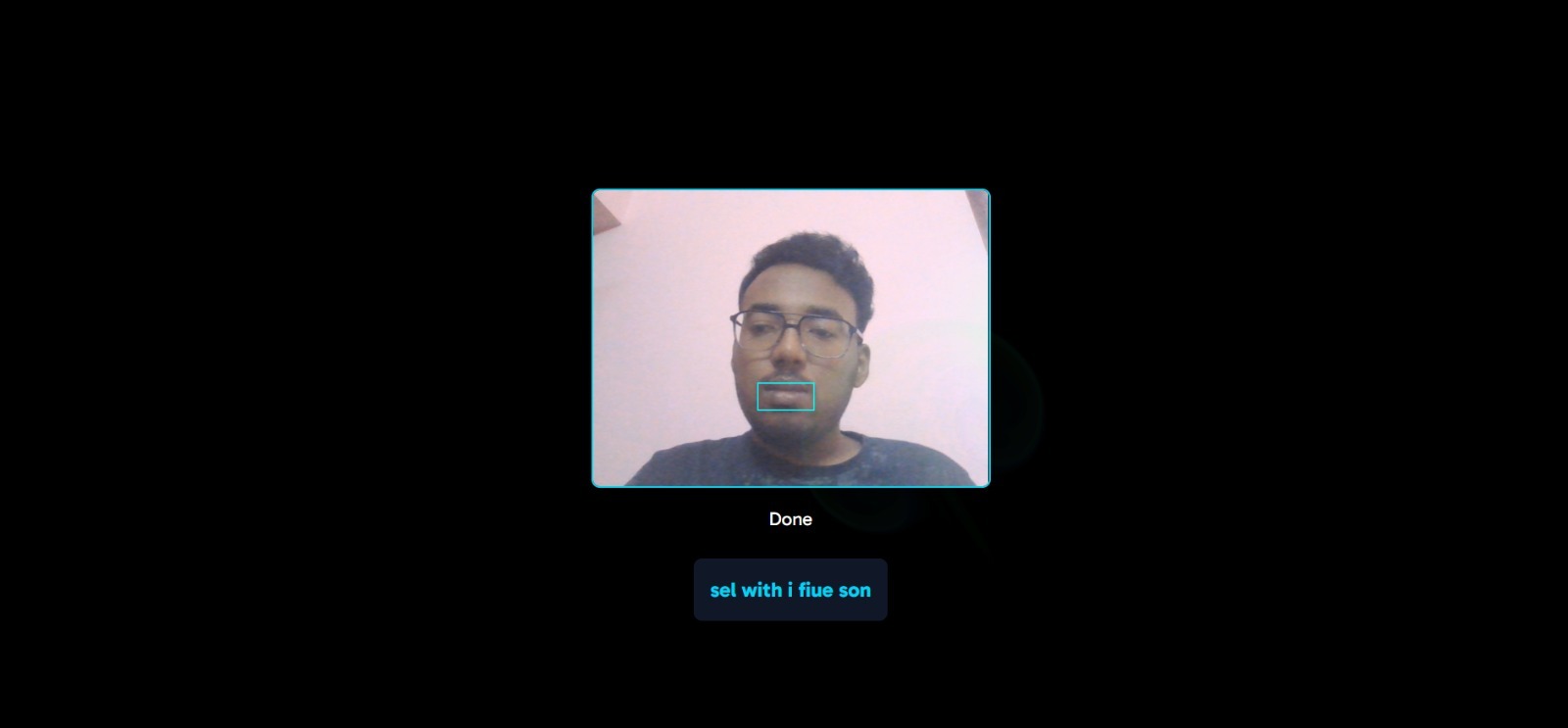
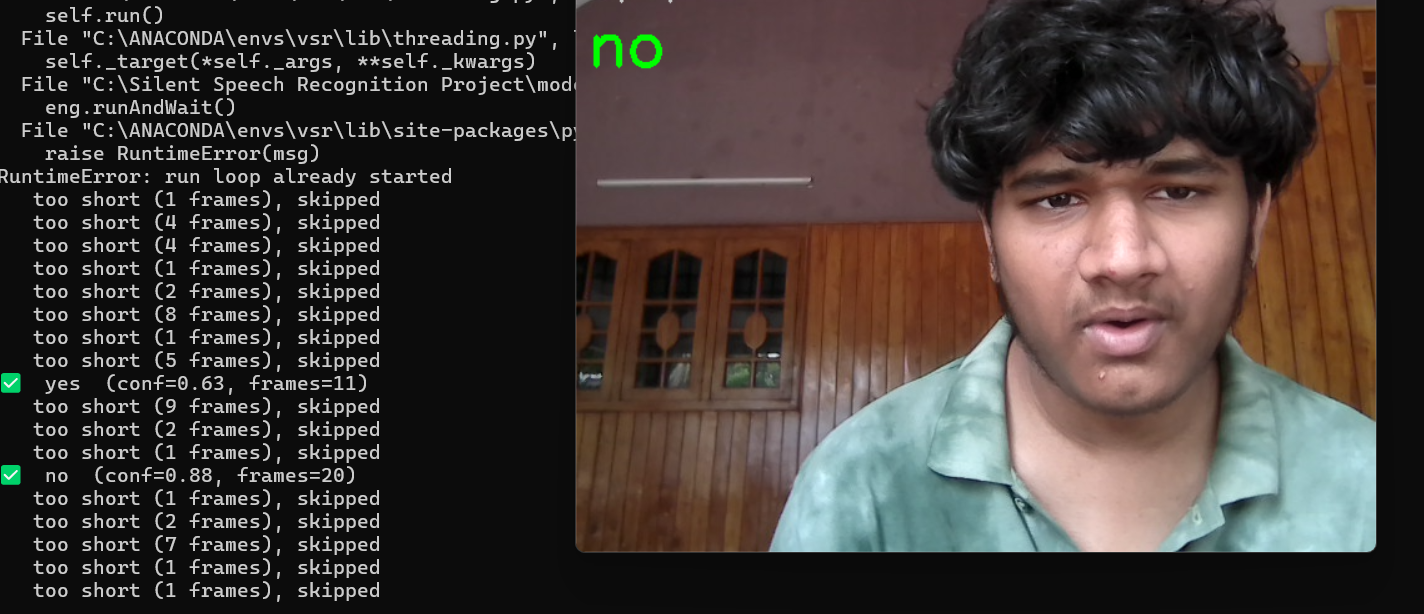
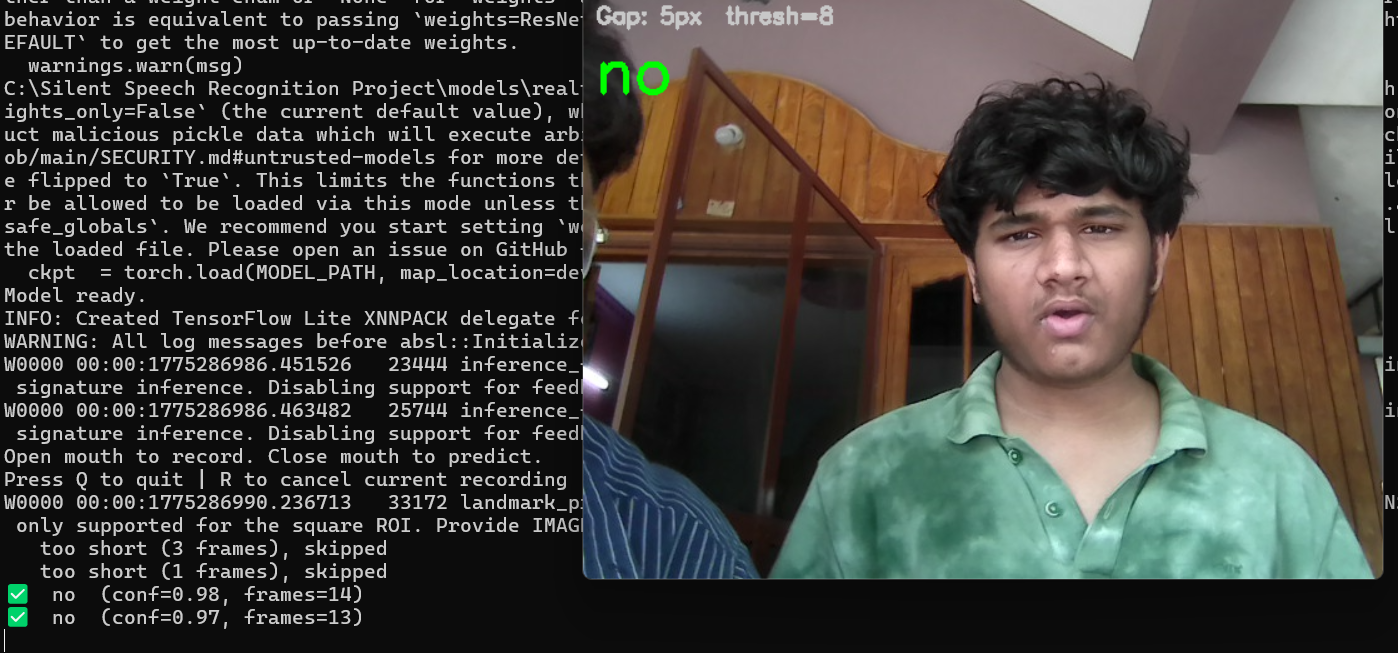
custom model real-time results
-
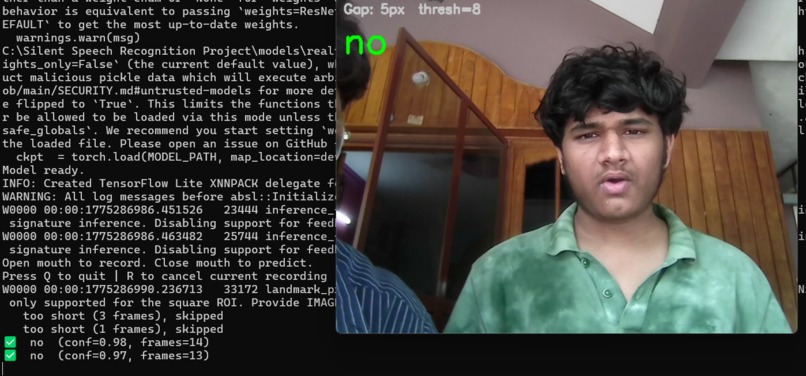
Custom model real-time results

Inspiration
The project was inspired by the need to help people who are unable to speak, especially individuals affected by conditions like ALS (Amyotrophic Lateral Sclerosis), communicate more effectively. We wanted to build something meaningful using AI that could convert silent lip movements into text and speech.
The idea also aligns with the growing focus on AI-driven solutions supported by government initiatives aimed at improving accessibility and assistive technologies.
What it does
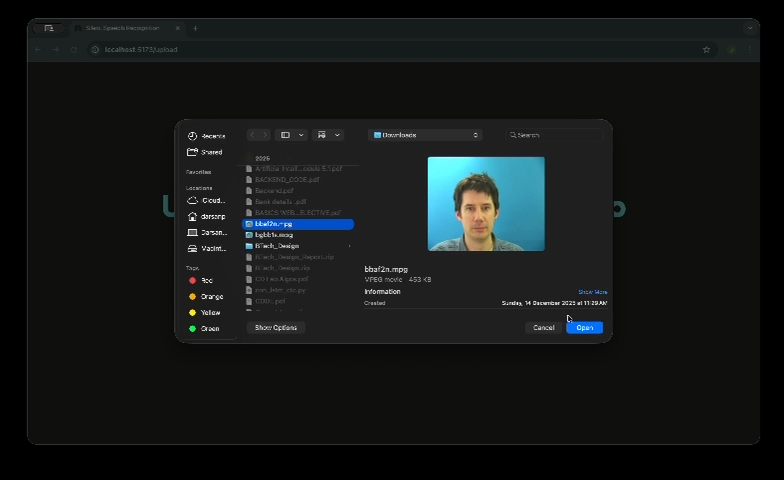
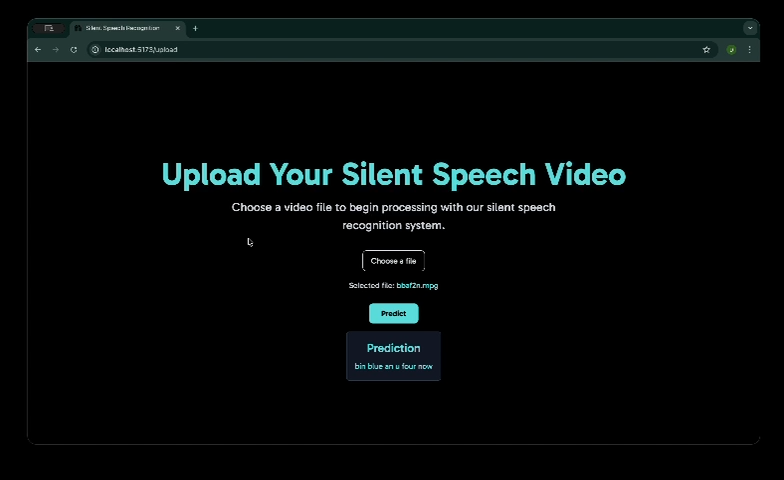
The system recognizes lip movements from video or real-time webcam input and converts them into text. It supports both sentence-level prediction using the GRID dataset and word-level prediction using a custom dataset.
The custom model also includes text-to-speech, allowing the predicted words to be spoken out loud, making it useful for real-time assistive communication.
How we built it
We built the system using a CNN–BiLSTM architecture. The CNN extracts spatial features from lip frames, while the BiLSTM captures temporal patterns across sequences.
For preprocessing, we used MediaPipe FaceMesh to detect facial landmarks and extract the lip region. Frames are resized to (64 \times 64), converted to RGB, and normalized using:
[ x' = \frac{x - 0.5}{0.5} ]
We implemented two models:
- A CTC-based model for sentence prediction on the GRID dataset
- A softmax-based classifier for word prediction on a custom dataset
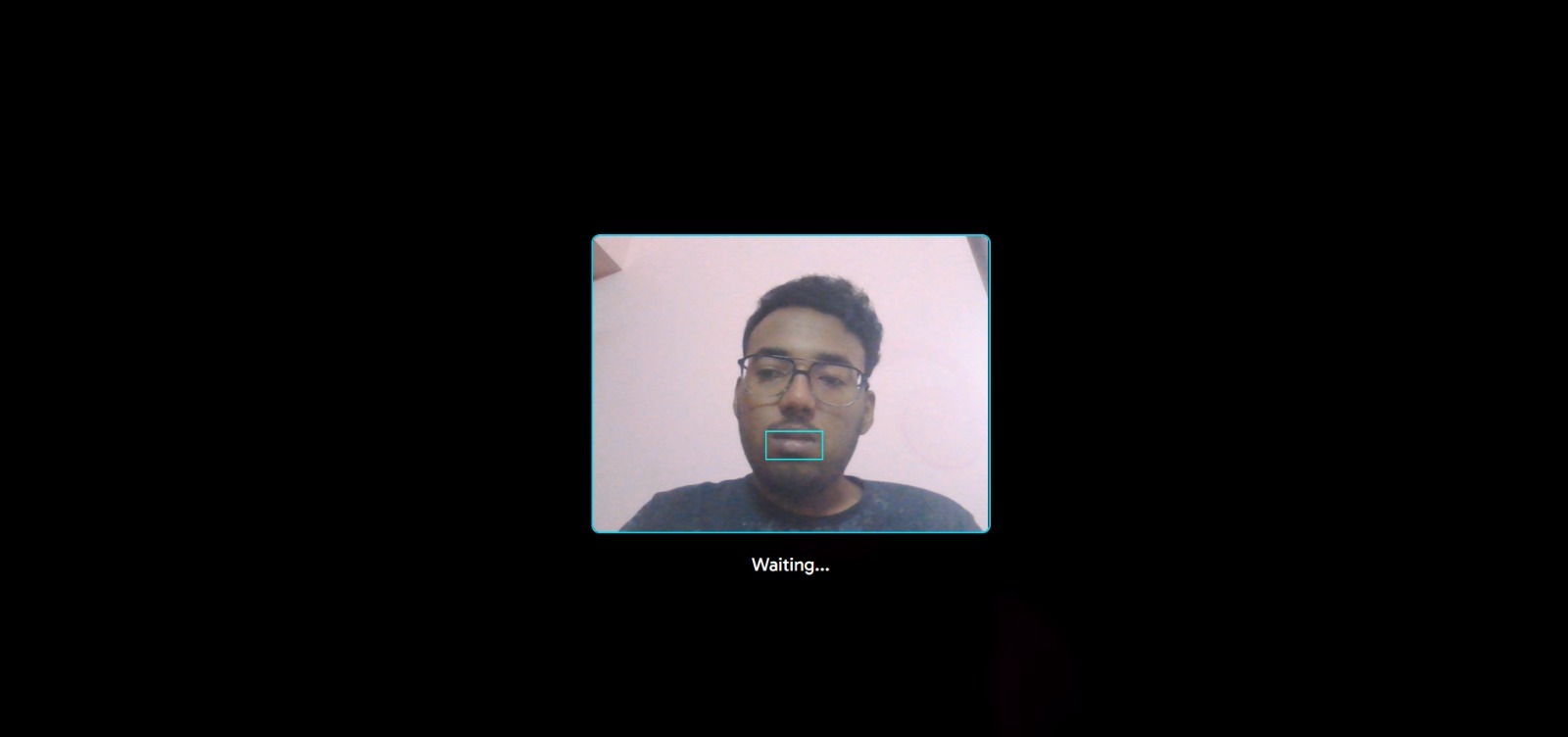
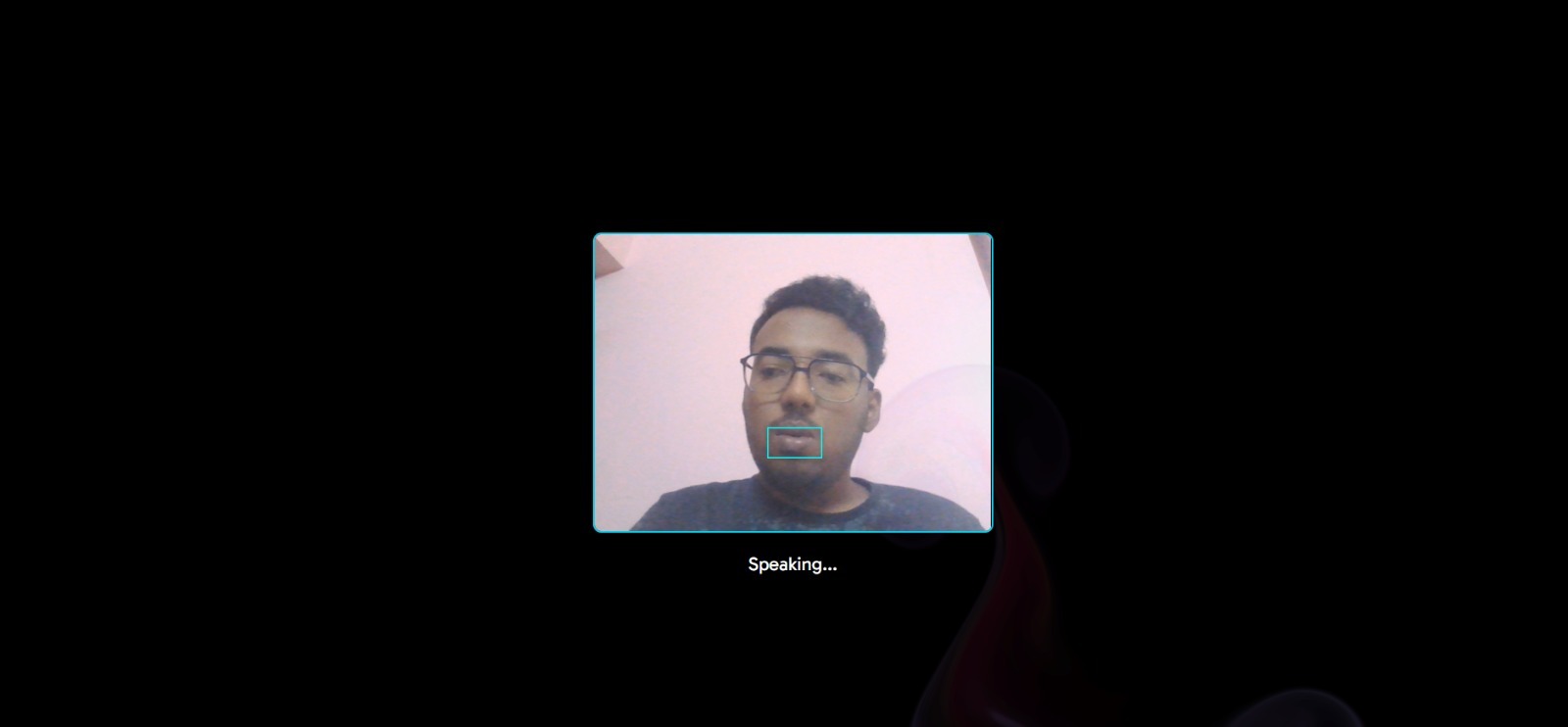
A real-time pipeline was also developed using webcam input, buffering, and smoothing techniques. Text-to-speech was integrated to convert predictions into audio output.
Challenges we ran into
One of the main challenges was achieving stable performance in real-time conditions. Variations in lighting, camera quality, and user movement caused inconsistent predictions.
Another challenge was the limited size of the custom dataset, which affected generalization. We also faced issues with noisy predictions, which required techniques like smoothing and confidence thresholds.
Accomplishments that we're proud of
We successfully developed a working silent speech recognition system capable of converting lip movements into text in both offline and real-time modes. The integration of text-to-speech made the system more practical for assistive communication.
A major milestone for our team was securing ₹1,00,000 in funding support, which reflects the potential and real-world impact of our project. This recognition encouraged us to further improve and expand the system.
We are also proud that this project aligns with AI-driven initiatives focused on accessibility and assistive technologies.
What we learned
We gained hands-on experience with computer vision, deep learning, and sequence modeling. We understood how CNNs and LSTMs work together, and how CTC enables sequence prediction without explicit alignment.
We also learned how to design real-time systems, optimize performance, and handle practical challenges such as noise, lighting variations, and unstable predictions.
What's next for Silent Speech Recognition for the Voiceless
Future improvements include expanding the vocabulary, improving real-time accuracy, and making the system more robust to different lighting and user conditions.
We also plan to explore transformer-based models and deploy the system on mobile or web platforms to make it more accessible and practical for real-world use.

Log in or sign up for Devpost to join the conversation.