-
-
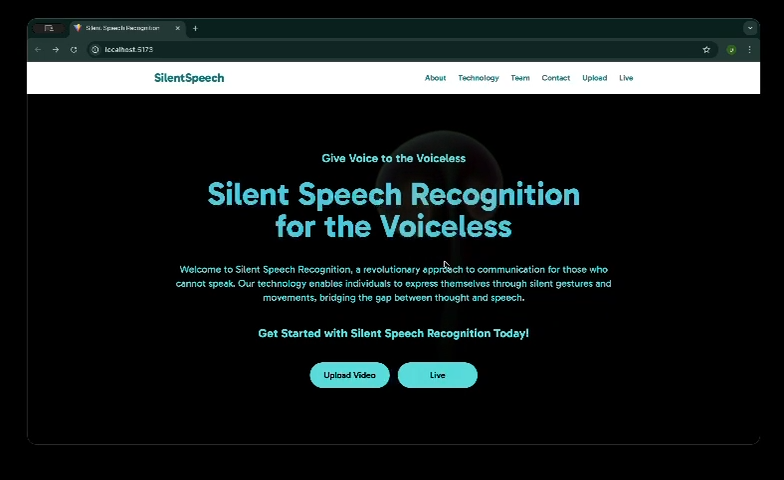
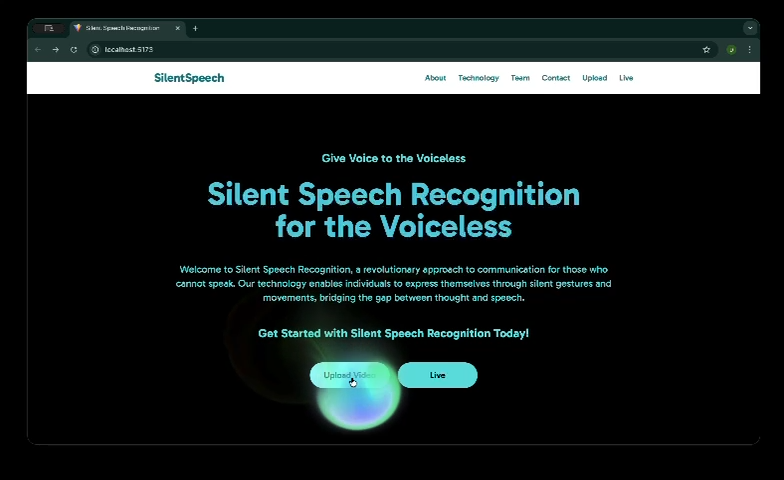
Hero Section
-
-
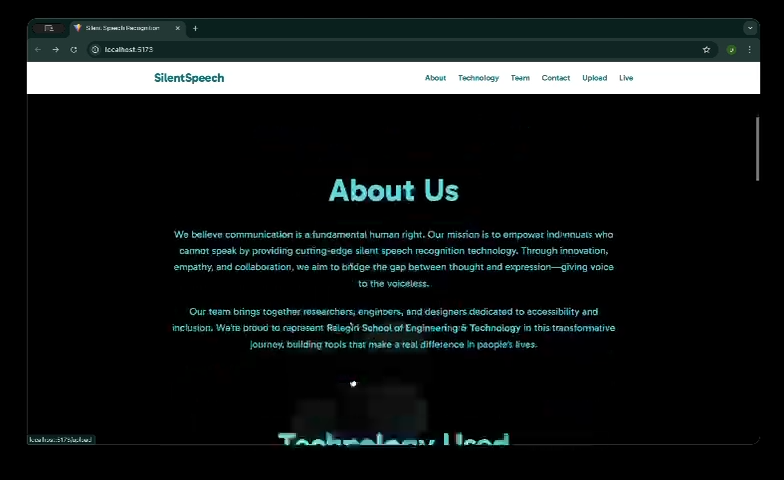
About Us Section
-
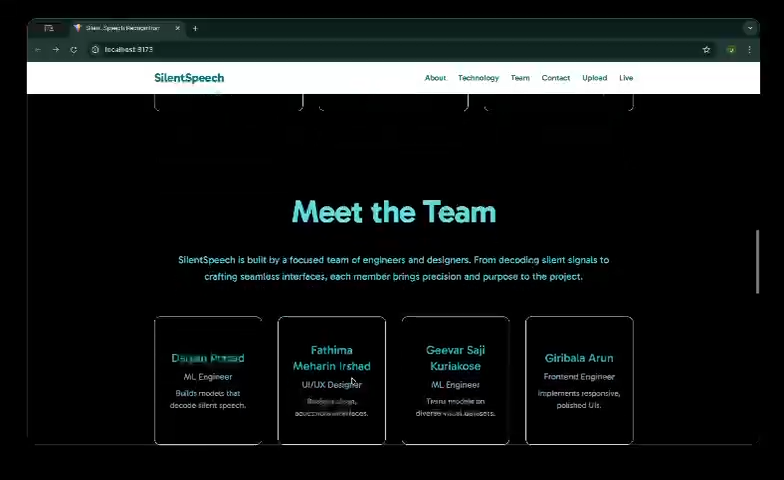
Developers
-
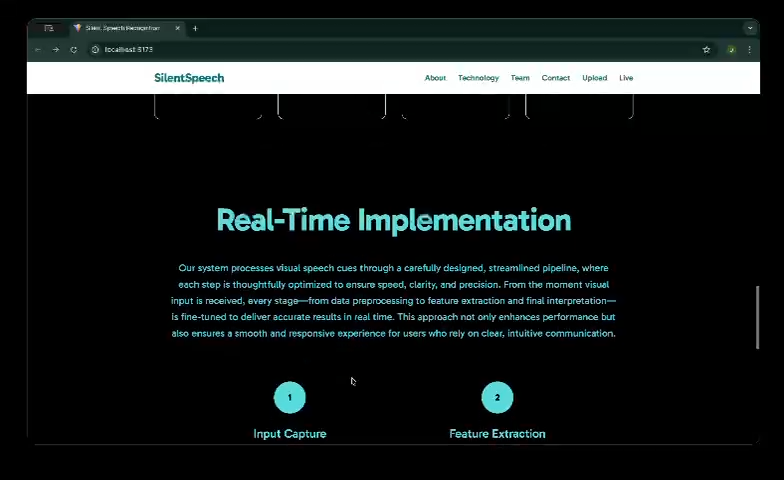
Implementation Section
-
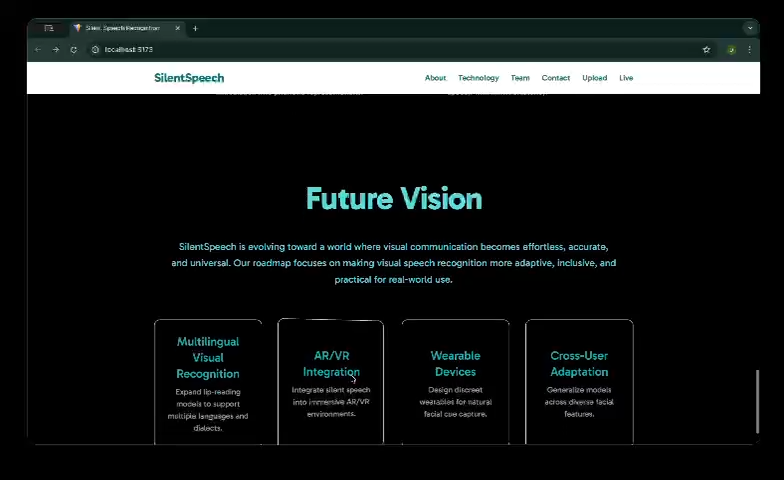
Future Vision Section
-
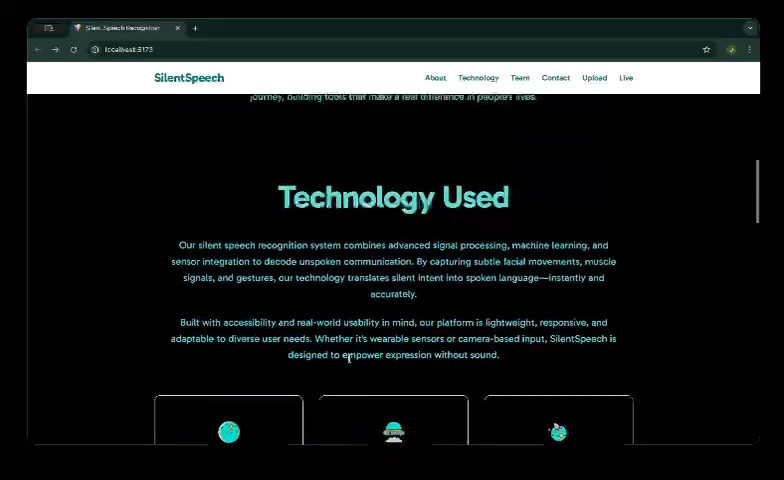
Technology Used Section
-
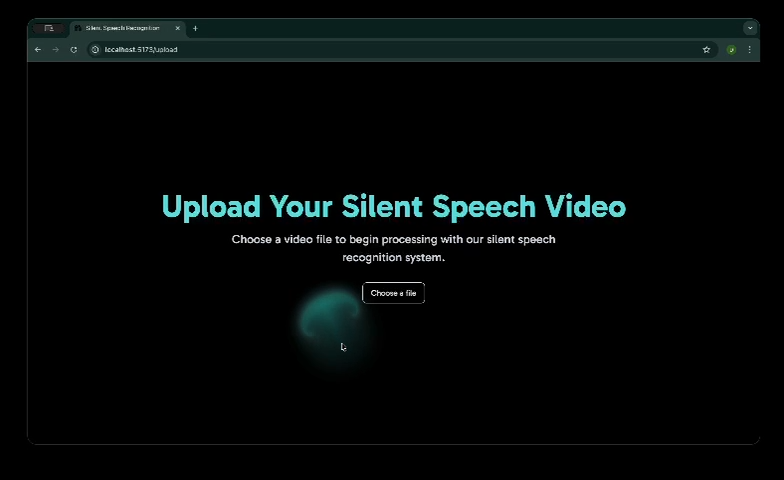
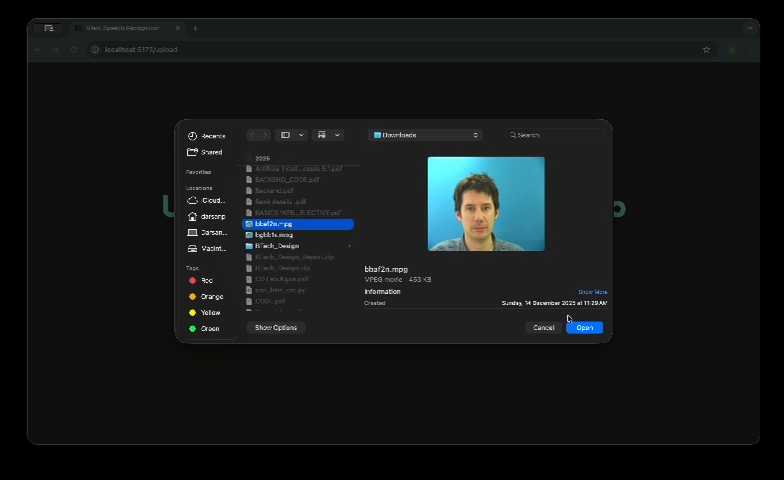
Uploading (Offline Vers) - 1
-
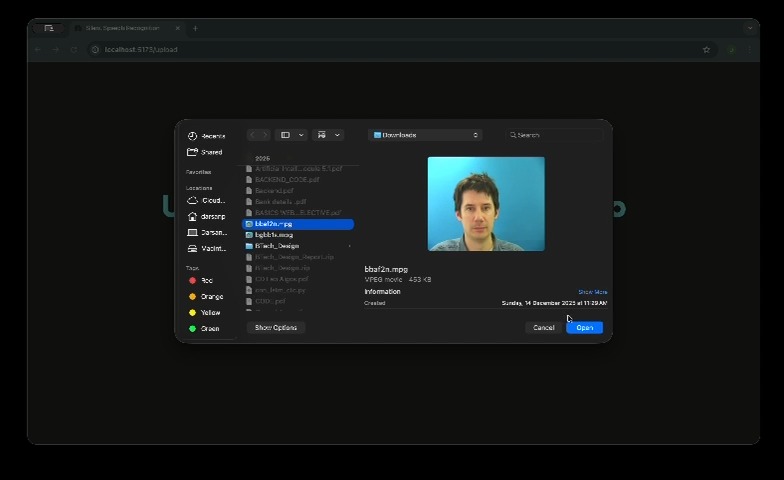
Uploading (Offline Vers) - 2
-
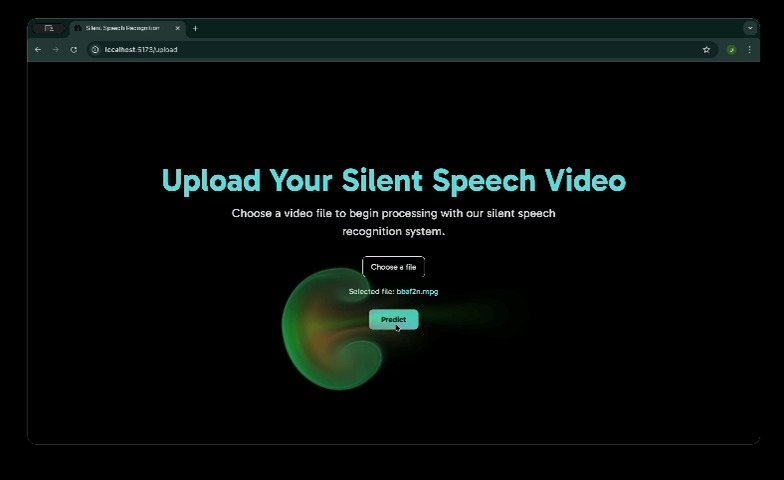
Uploading (Offline Vers) - 3
-
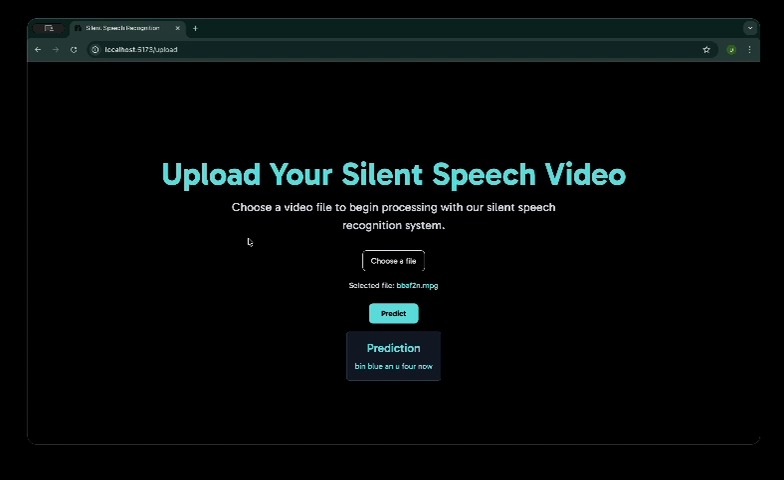
Uploading (Offline Vers) - 4
1. Inspiration
Silent speech recognition is a challenging problem with strong relevance for assistive communication, especially for individuals who are unable to speak audibly due to conditions such as ALS or vocal cord paralysis. Even without sound, many speech-impaired users naturally articulate words through lip movements.
This project was inspired by a simple question:
Can visual information alone be used to decode speech and convert it into readable text using deep learning?
We were motivated by the idea of building a silent, non-invasive communication system that works in real time while preserving user privacy.
2. What It Does
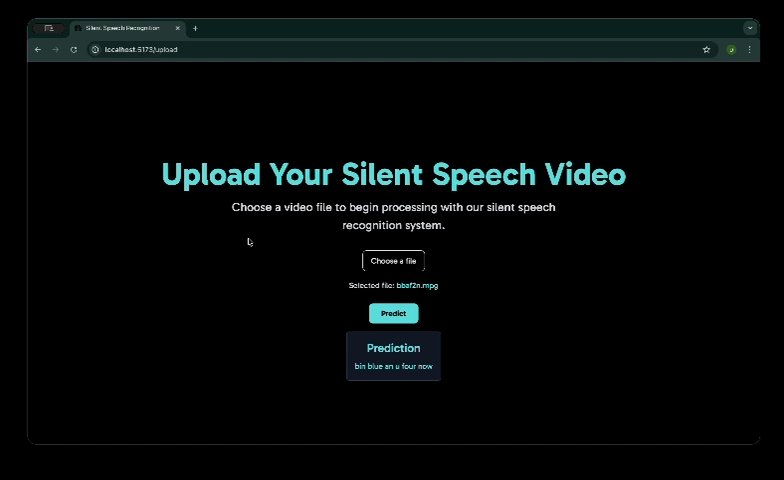
This project presents a real-time silent speech recognition system that translates lip movements from video directly into text using only visual input.
The system supports:
- Pre-recorded video input
- Live camera input
The output is a sequence of readable text corresponding to the silently articulated speech, with optional text-to-speech playback.
3. How We Built It
The system processes video input frame by frame and extracts the lip region using MediaPipe FaceMesh to ensure consistent region-of-interest localization. The cropped lip frames are resized, normalized, and grouped into temporal sequences.
A ResNet-18 Convolutional Neural Network (CNN) extracts spatial features from individual lip frames. These features are then passed to a Bidirectional Long Short-Term Memory (BiLSTM) network to model temporal dependencies across frames.
Training is performed using Connectionist Temporal Classification (CTC) loss, which allows sequence-to-text learning without explicit frame-level alignment:
[ \mathcal{L}{CTC} = - \log \sum{\pi \in \mathcal{B}^{-1}(y)} P(\pi \mid x) ]
During inference, both greedy decoding and beam search decoding are used to generate the final text output. The model is trained and evaluated using the GRID audiovisual dataset.
4. Challenges We Ran Into
- Generalizing to unseen speakers
- Sensitivity to lighting conditions and head pose variations
- Handling variable-length video sequences
- Maintaining low latency while preserving recognition accuracy for real-time use
5. Accomplishments We’re Proud Of
- Built a fully visual-only speech recognition system
- Achieved real-time inference using live video input
- Integrated lip detection, deep learning, and decoding into an end-to-end pipeline
- Trained and evaluated the model on a standard benchmark dataset (GRID)
6. What We Learned
Through this project, we gained hands-on experience in:
- Visual speech recognition and sequence modeling
- CNN–RNN architectures for temporal data
- Training with CTC loss for unaligned sequences
- Building real-time deep learning inference pipelines
We also developed a deeper understanding of the practical challenges of deploying vision-based models in real-world conditions.
7. What’s Next
Future work includes:
- Training on larger and more diverse datasets
- Improving robustness to lighting, pose, and camera variations
- Exploring transformer-based temporal models
- Deploying the system as a practical assistive communication tool





Log in or sign up for Devpost to join the conversation.