SignVu
Real-time AI-powered sign language translation that works both ways.
The Problem
466 million people worldwide have disabling hearing loss. For the 70+ million who use sign language daily, every interaction with the hearing world becomes a negotiation—writing notes, relying on interpreters, or simply going without.
Professional interpreters cost $50-150/hour and require advance booking. Real-time communication? Nearly impossible without one.
We asked: What if Gemini 3 could be that interpreter?
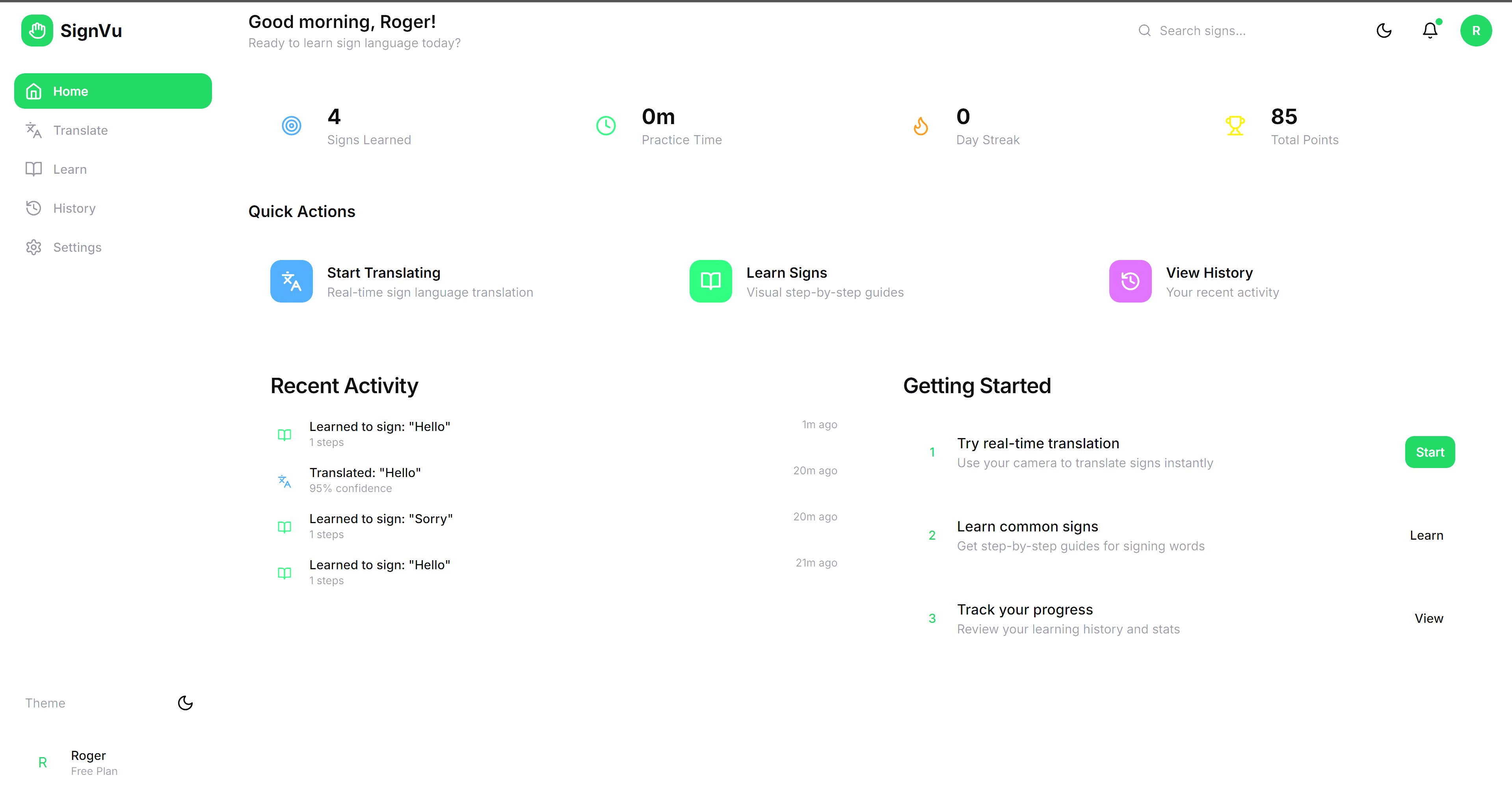
What SignVu Does
SignVu creates a two-way bridge between sign language and spoken language:
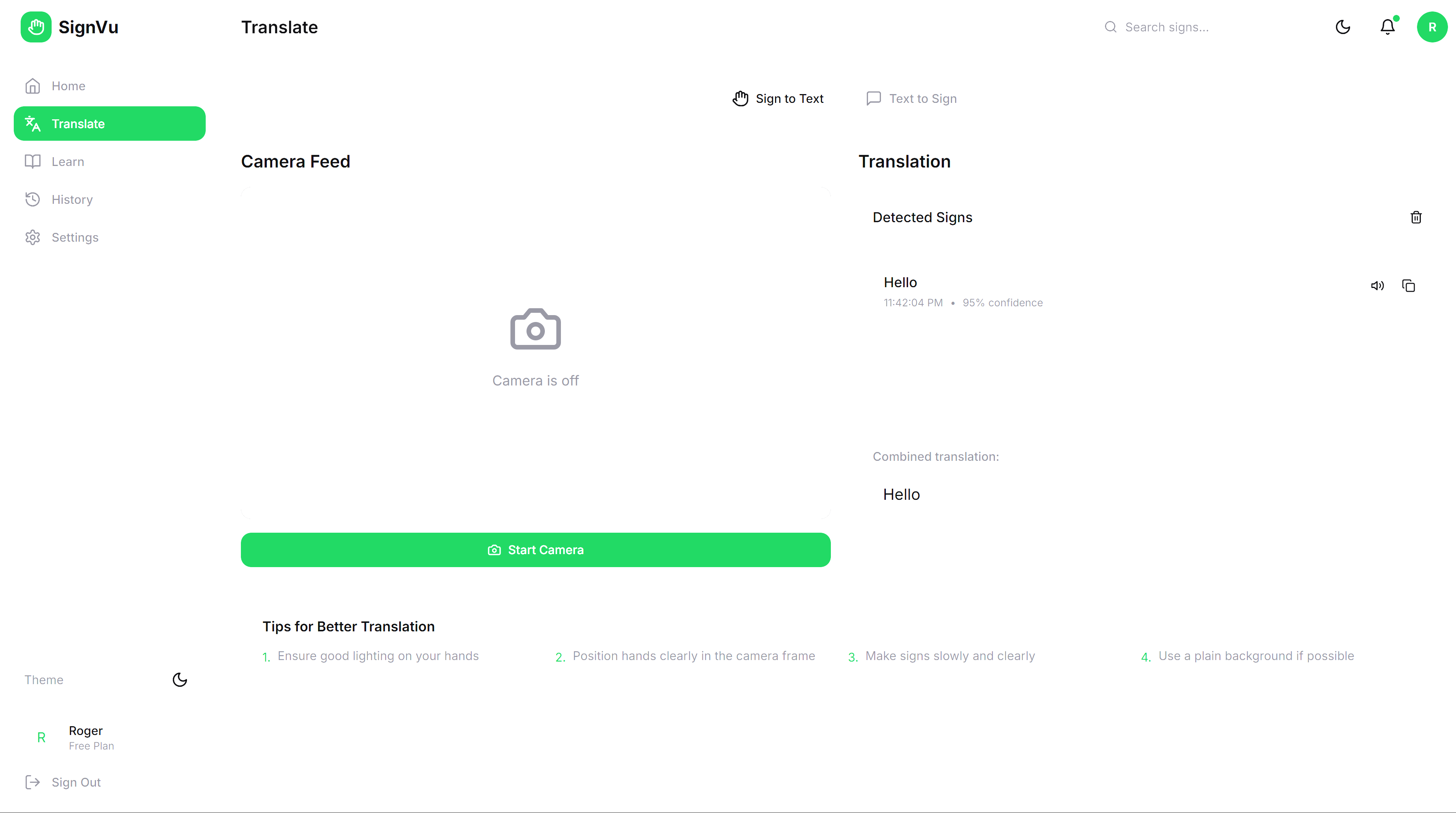
Translate: Point your webcam at someone signing ASL. SignVu interprets their gestures in real-time and displays the translation with confidence scoring.
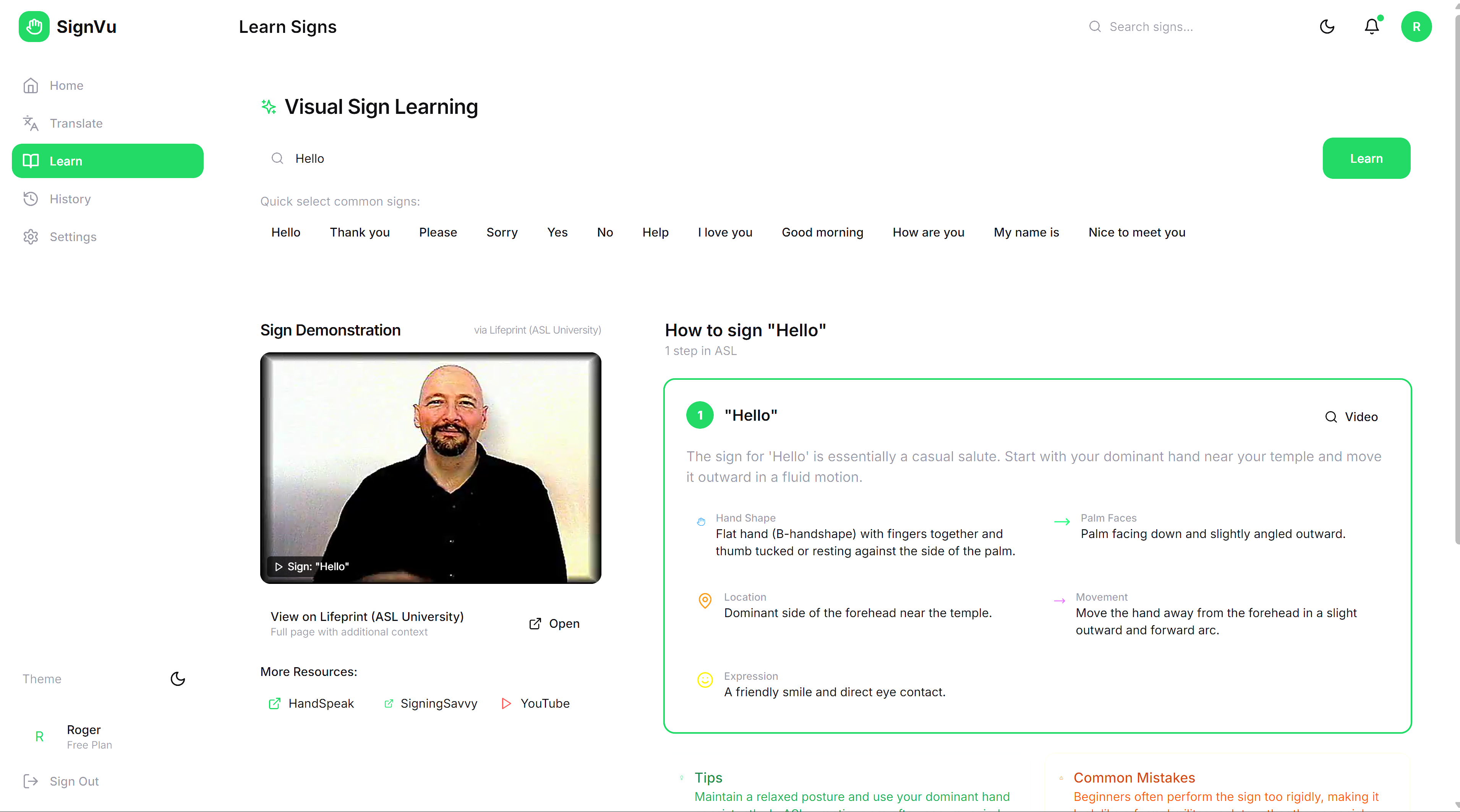
Learn: Type any word. Get step-by-step visual instructions for signing it—hand shapes, palm orientation, movement patterns, facial expressions—plus curated video demonstrations.
Visualize: Interactive 3D hand models show exactly how each sign should look, generated dynamically by Gemini.
Real Video Demonstration We query real video demonstrations from the American Sign Language (ASL) University.
No accounts. No data stored. Just communication.
How Gemini 3 Powers SignVu
We use Gemini 3's multimodal capabilities in three distinct ways:
Vision Understanding for Translation
When a user signs in front of their webcam, we capture frames and send them directly to Gemini 3's vision model:
response = model.generate_content([
"""Analyze this ASL gesture. Consider:
- Hand shape and finger positions
- Palm orientation relative to camera
- Location (face, chest, neutral space)
- Any visible movement blur
- Facial expression if visible
Return the most likely sign and confidence.""",
preprocessed_image
])
Gemini interprets the visual information and returns structured data—no custom ML models, no training datasets, just multimodal intelligence.
Instructional Content Generation
For the learning side, we prompt Gemini to generate pedagogically-sound signing instructions:
response = model.generate_content(f"""
Create signing instructions for: "{word}"
Structure as steps with:
- Dominant hand shape (flat, fist, point, etc.)
- Non-dominant hand role if applicable
- Starting and ending positions
- Movement trajectory
- Required facial grammar
- Common mistakes to avoid
""")
This transforms any word into learnable, actionable guidance.
3D Pose Data Generation
For our Three.js hand visualization, Gemini generates precise joint positions:
response = model.generate_content(f"""
Generate hand pose data for the sign: "{sign}"
Output finger curl values (0.0=extended, 1.0=closed)
and spread angles for 3D rendering.
""")
The result: dynamic 3D hands that show exactly how each sign should look.
Gemini 3 Features Utilized:
- Multimodal image analysis (vision + language)
- Zero-shot visual recognition
- Structured JSON generation
- Context-aware instruction synthesis
Technical Architecture
┌─────────────────────────────────────────────────────────────┐
│ Frontend │
│ Next.js 14 · TypeScript · Three.js · Tailwind · Zustand │
└──────────────────────────┬──────────────────────────────────┘
│ REST / WebSocket
┌──────────────────────────▼──────────────────────────────────┐
│ Backend │
│ FastAPI · MediaPipe · OpenCV · Pillow · Python 3.11 │
└──────────────────────────┬──────────────────────────────────┘
│
┌──────────────────────────▼──────────────────────────────────┐
│ Gemini 3 API │
│ gemini-3-flash-preview · Multimodal Processing │
└─────────────────────────────────────────────────────────────┘
Frontend Stack:
- Next.js 14 with App Router for server components
- React Three Fiber for 3D hand visualization
- Zustand for persistent state (progress tracking, preferences)
- React Query for efficient API caching
- Canvas API for real-time frame capture
Backend Stack:
- FastAPI with async endpoints for low-latency responses
- MediaPipe for hand landmark detection (preprocessing)
- OpenCV/Pillow for image optimization before Gemini
- WebSocket support for continuous translation streams
Infrastructure:
- CloudFront CDN (global edge delivery)
- Docker containerization
Challenges & Solutions
Challenge: Sign language isn't just hands—facial expressions carry grammatical meaning in ASL.
Solution: We engineered prompts that explicitly instruct Gemini to analyze facial features when visible, and our learning module teaches facial grammar alongside hand movements.
Challenge: Gemini occasionally returns malformed JSON, breaking the UI.
Solution: Multi-layer parsing with regex fallbacks extracts usable data even from imperfect responses. The app degrades gracefully, never crashes.
Challenge: Latency kills real-time translation.
Solution: Image preprocessing (resize to 1280px max, 85% JPEG compression), 1-second capture intervals, and async processing keep translations feeling instant.
Impact
Accessibility: A deaf person can hold their phone up during a conversation and get real-time text of what someone is signing—no interpreter needed.
Education: Hearing people can learn to sign without expensive classes. Type a phrase, see exactly how to sign it, practice with 3D visualization.
Privacy: Unlike cloud-based alternatives, SignVu stores nothing. Every frame is processed and discarded. Your conversations stay yours.
Cost: Free and open source vs. $50-150/hour for human interpreters.
What's Next
- More Sign Languages — BSL, LSF, JSL, and others have different grammar and vocabulary
- Sentence-Level Understanding — Move from isolated signs to continuous signing
- Mobile Native Apps — iOS and Android for true portability
- AR Glasses Integration — Overlay translations in real-world view
- Offline Mode — Edge-deployed models for areas without connectivity
Built With
Gemini 3 Next.js FastAPI TypeScript Python Three.js MediaPipe OpenCV Tailwind CSS Docker
SignVu — Because communication is a right, not a privilege.
Built With
- gemini
- gemini-3-flash-preview

Log in or sign up for Devpost to join the conversation.