-
ui
-
ui
-
letter reconigization
-
gemini to generate proper text
-
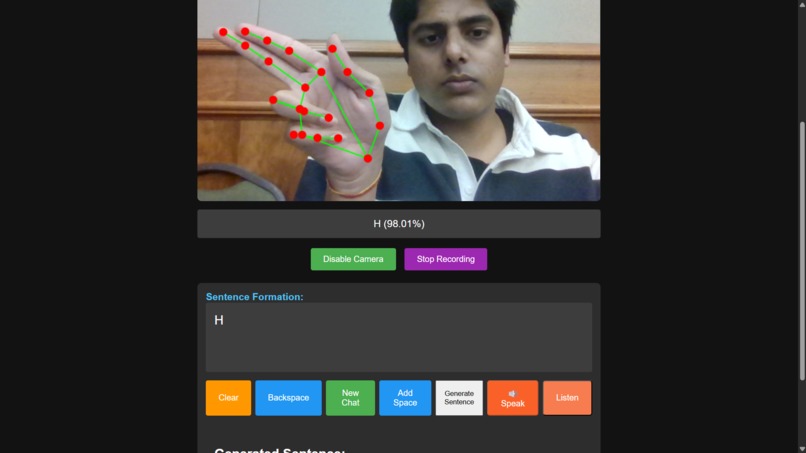
letter reconigization
-
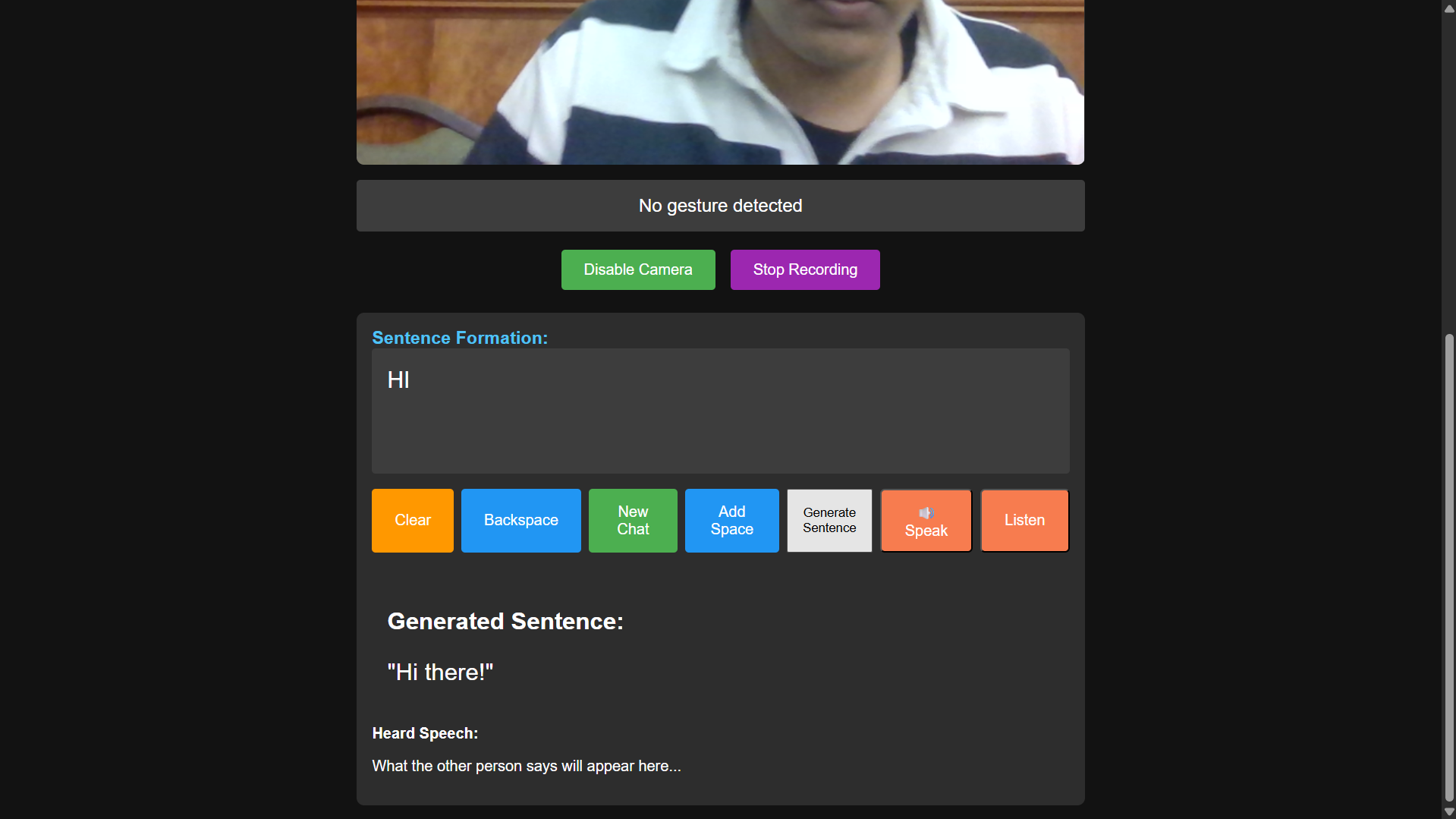
lister to other person for text
Inspiration
We were inspired by the gap in current accessibility tools. Lots of apps can translate to sign language, but few can do the reverse in a way that feels like a real conversation. We didn't want to build just a dictionary; we wanted to build a real-time, two-way communication bridge that could be used in a real-world scenario, like at a coffee shop or asking for directions.
What it does
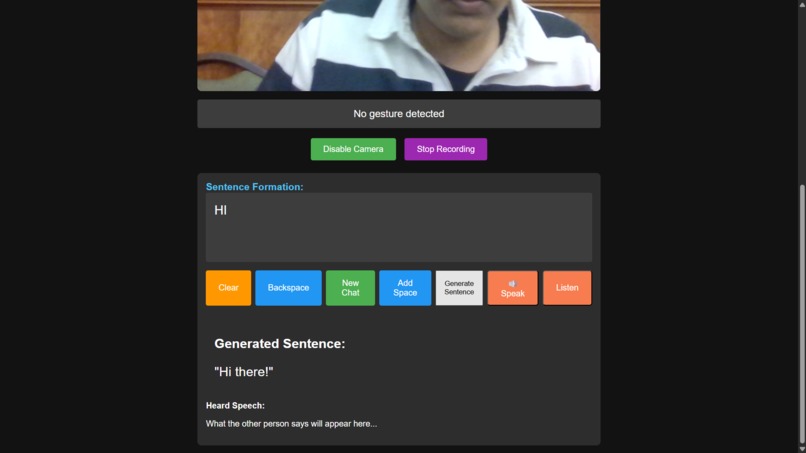
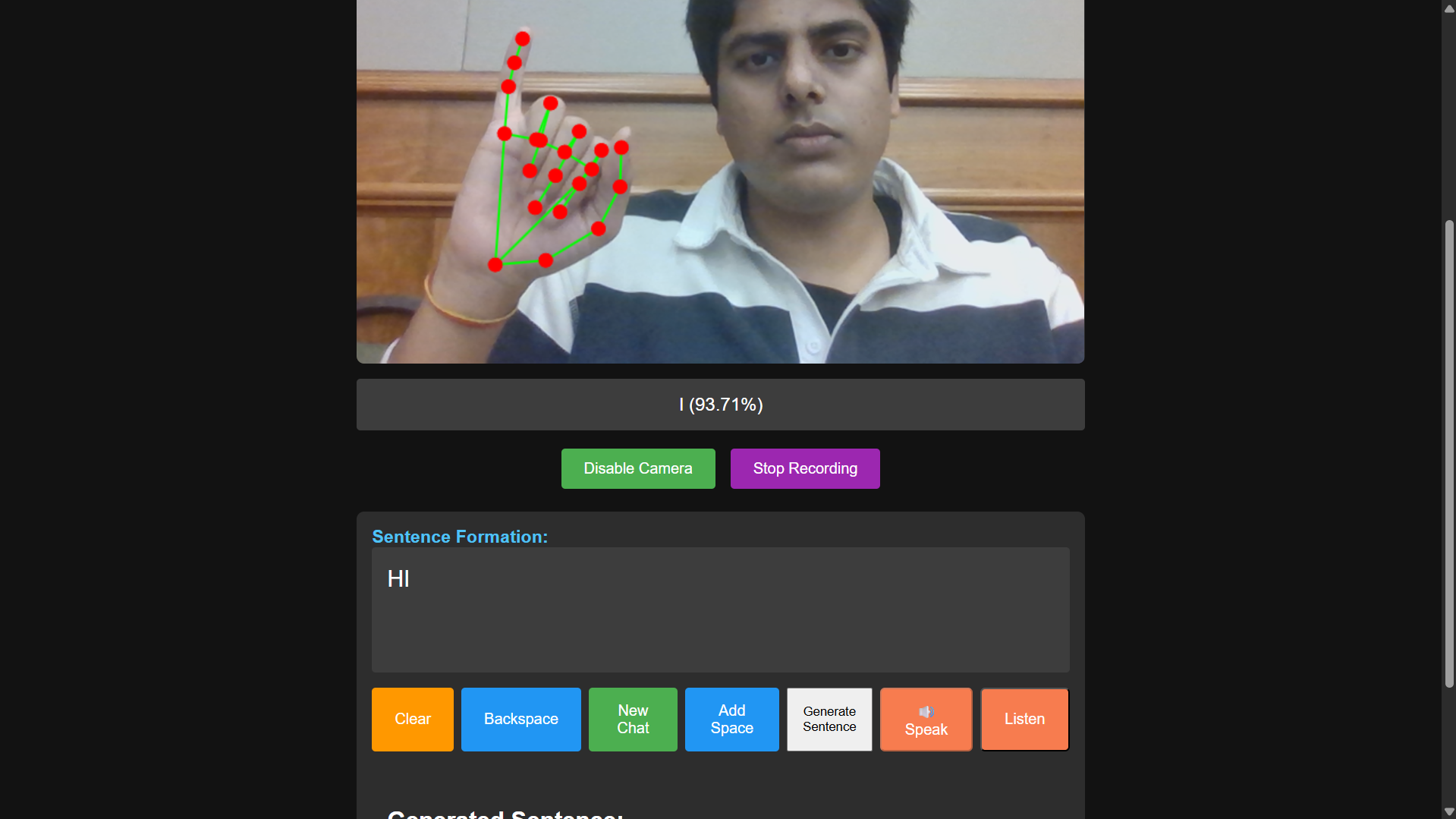
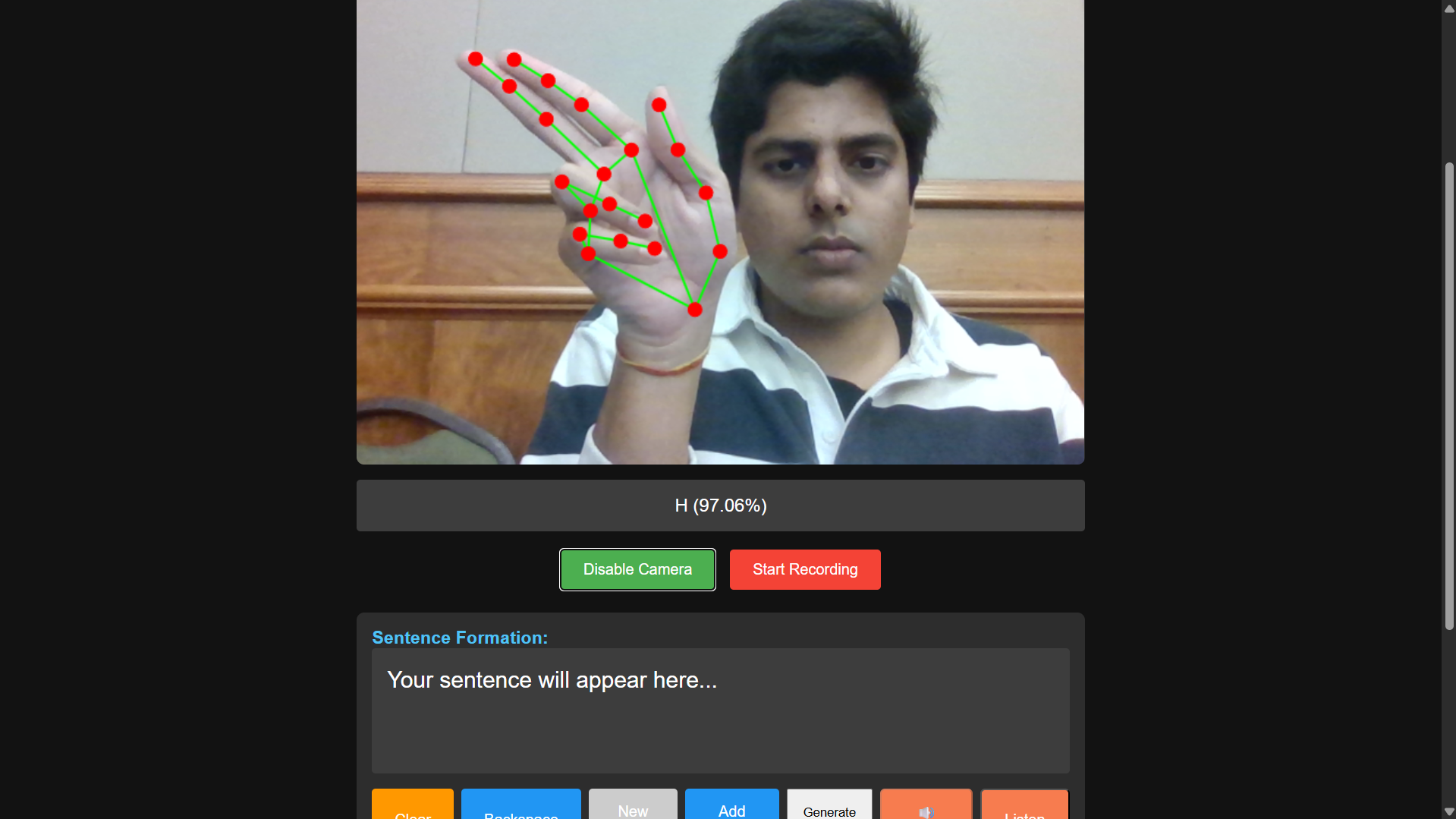
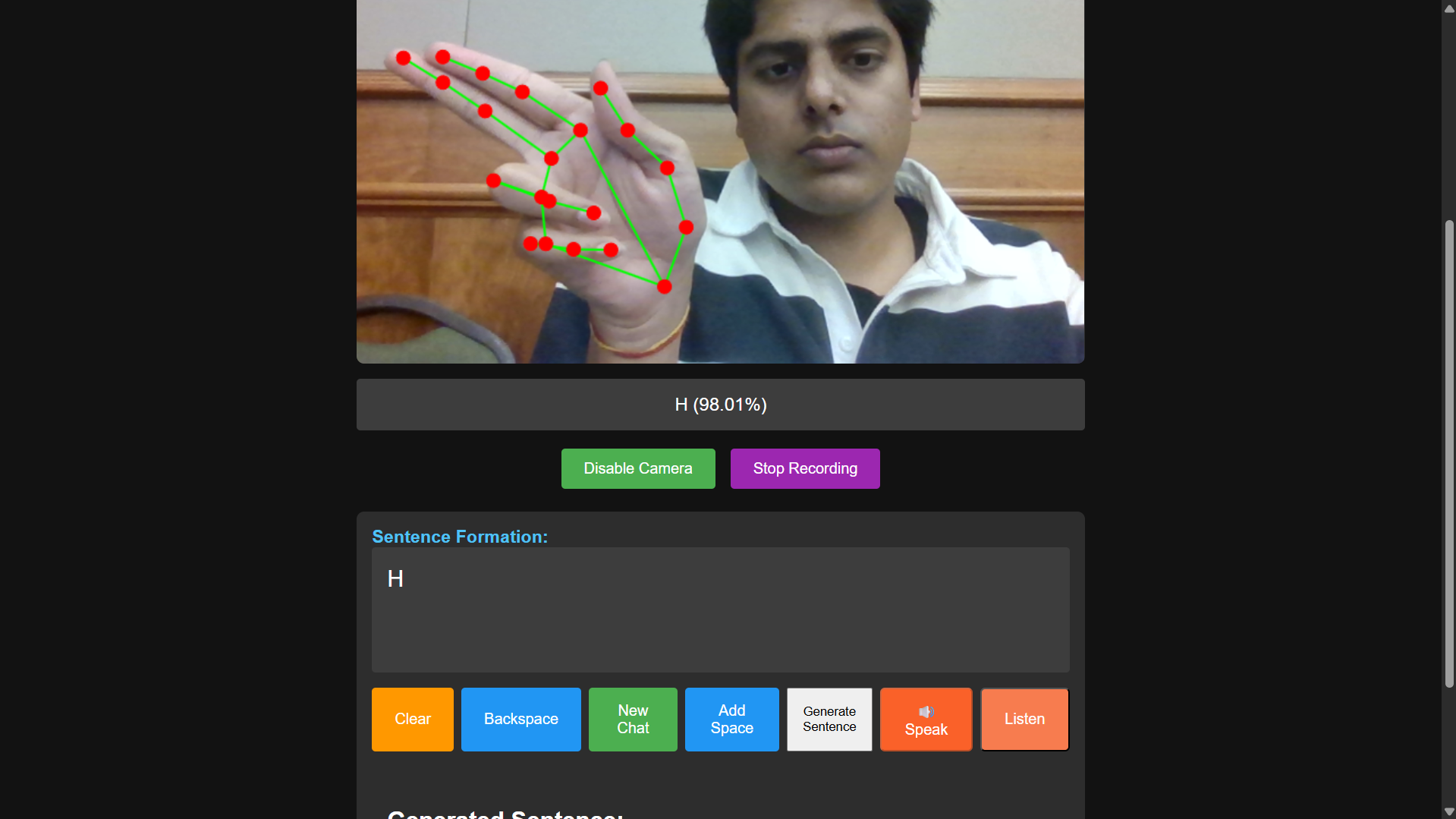
SignSync is a web app that turns your webcam into a real-time ASL interpreter.
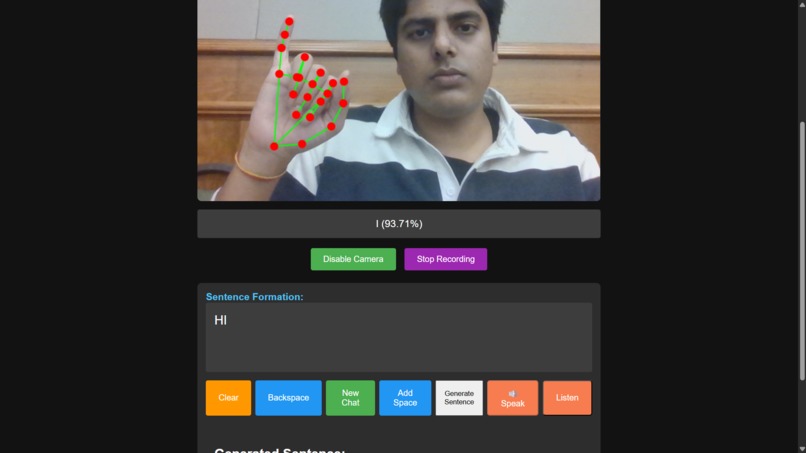
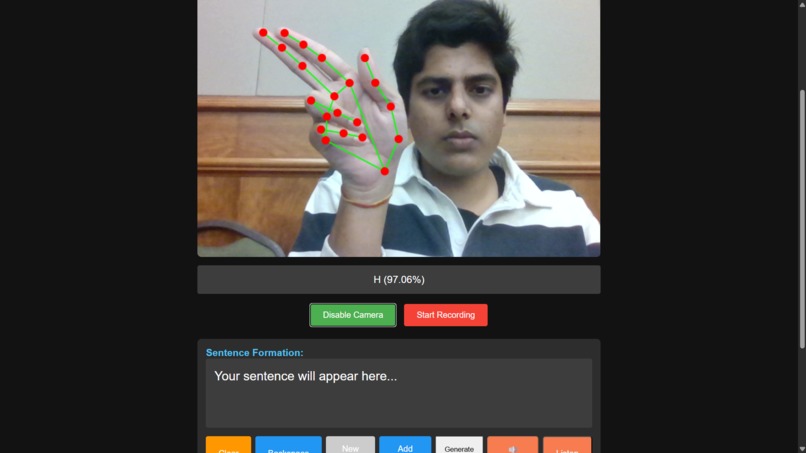
You sign: The app uses your webcam to read your ASL fingerspelling (like "H-E-L-L-O").
It translates: Our custom-trained model recognizes the letters and builds them into words.
AI makes it natural: When you're ready, you hit "Generate." The app sends your raw words (e.g., "BATHROOM WHERE") to a secure backend, which uses the Gemini API to expand it into a full, polite sentence ("Could you please tell me where the bathroom is?").
It speaks: The app speaks the full sentence out loud for the other person to hear.
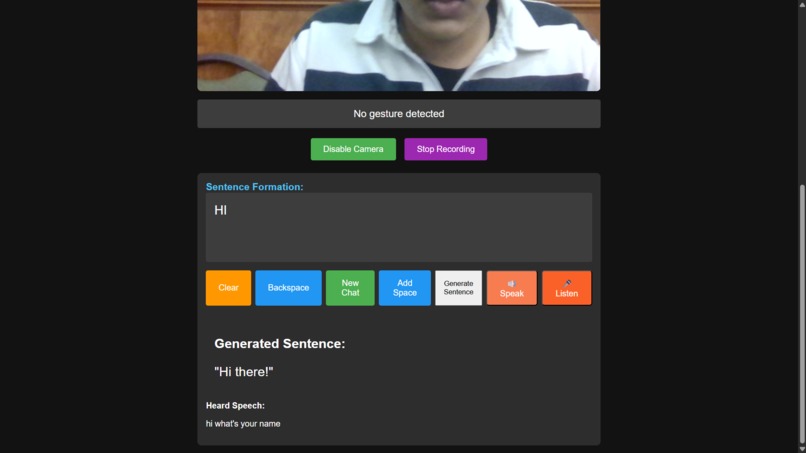
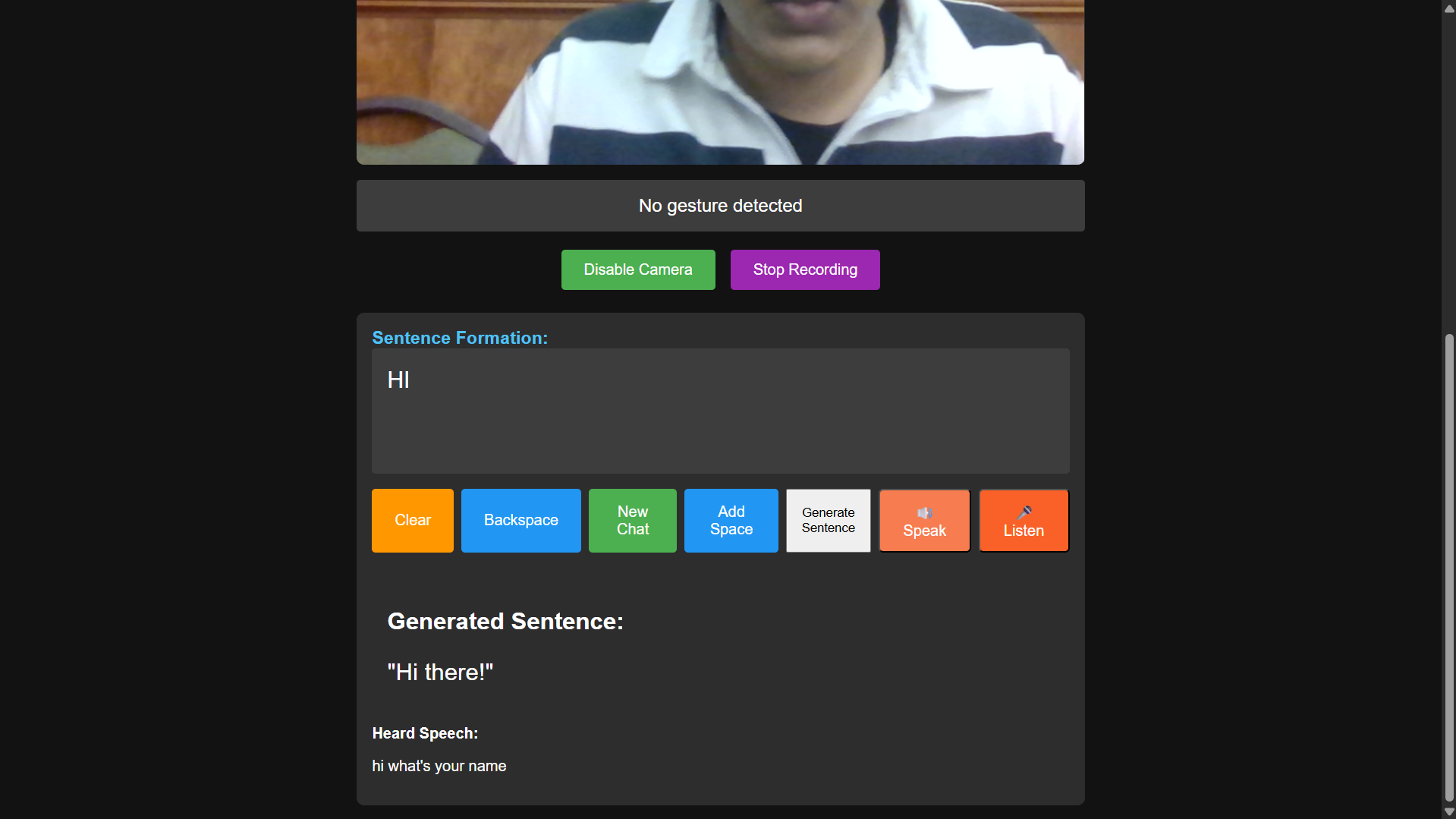
It listens: You can then click "Listen," and the app will use the microphone to capture the other person's spoken reply.
Full Conversation: The app saves both sides of the chat, giving the AI context for a continuous, natural conversation.
How we built it
This is a full-stack application, built to be secure and scalable.
Frontend: Built in TypeScript, HTML, and CSS. We used the MediaPipe GestureRecognizer to get the live hand landmark data from the webcam. The frontend also uses the browser's built-in Web Speech API for both SpeechRecognition (listening) and SpeechSynthesis (speaking).
Backend: A Node.js/Express server, also in TypeScript. This was critical for security. The backend holds our Google Gemini API key and our database password so they are never exposed to the public.
Database: We used MongoDB Atlas with Mongoose to store the conversation. When a user clicks "New Chat," the backend creates a new document in the database. As the conversation happens, every signed sentence and spoken reply is pushed to that chat's history array.
Challenges we ran into
We hit a ton of challenges. Our biggest one was model accuracy. Our model was terrible at recognizing 'M', 'N', and 'R' because their landmarks are almost identical. We had to write custom logic to lower the confidence threshold just for those specific, "hard" letters.
Another huge bug was conversation context. Our "Listen" feature was showing the spoken text on the screen, but we forgot to add it to the conversationHistory array! This meant the AI had no idea what the other person said, and the conversation made no sense. We had to debug our logic to make sure both sides of the chat were being pushed to the history.
Finally, just setting up a secure, full-stack TypeScript project was a challenge. Getting the Node.js ESM-style imports to work with nodenext in our tsconfig.json and fixing MongoDB ENOTFOUND connection errors took a lot of debugging.
Accomplishments that we're proud of
We are incredibly proud that we built a full-loop, two-way system. It's not just a tech demo. A user can sign, the app speaks, the app listens, and the AI understands the entire context for the next signed sentence.
Building a secure backend from scratch that properly handles API keys and manages chat state in a database was a massive win for us. Seeing the AI understand why the user was signing "THANKS" (because of the spoken reply it had just heard) was the "Aha!" moment.
What we learned
A Backend is Non-Negotiable: You cannot build a serious AI app without a backend. Hiding your API keys is rule #1.
Prompt Engineering is Everything: Just sending text to Gemini wasn't enough. We had to give it "few-shot" examples and include a "hint" in the prompt to help it understand that "SWAY" was a name, not the verb "to sway."
Hardware is Hard: Browser APIs for microphones (SpeechRecognition) and cameras (getUserMedia) are finicky and have major differences (like only working in Chrome).
What's next for SignSync
This is just the beginning. The next, most obvious step is to move beyond letters. Our current model only recognizes the ASL alphabet (fingerspelling). The dream is to train a new, much larger model that can recognize full word-signs (like the single gestures for "help," "please," or "mother"). This would make the app exponentially faster and more practical for fluent signers.
Built With
- gemini
- mongodb
- mongoose
- tenserflow
- typescript

Log in or sign up for Devpost to join the conversation.