-
-
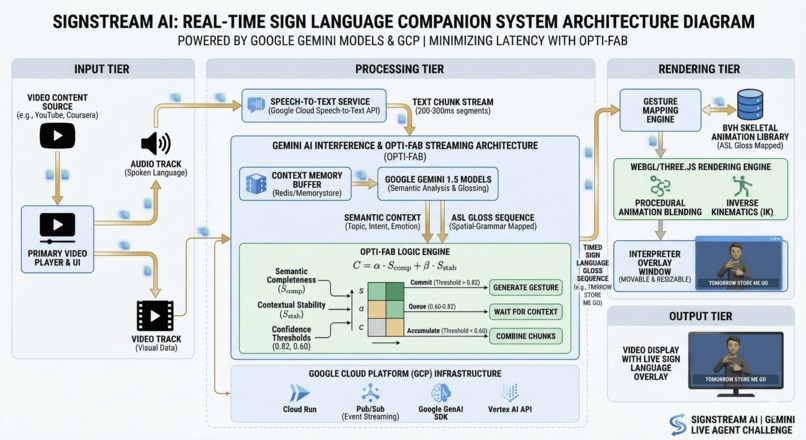
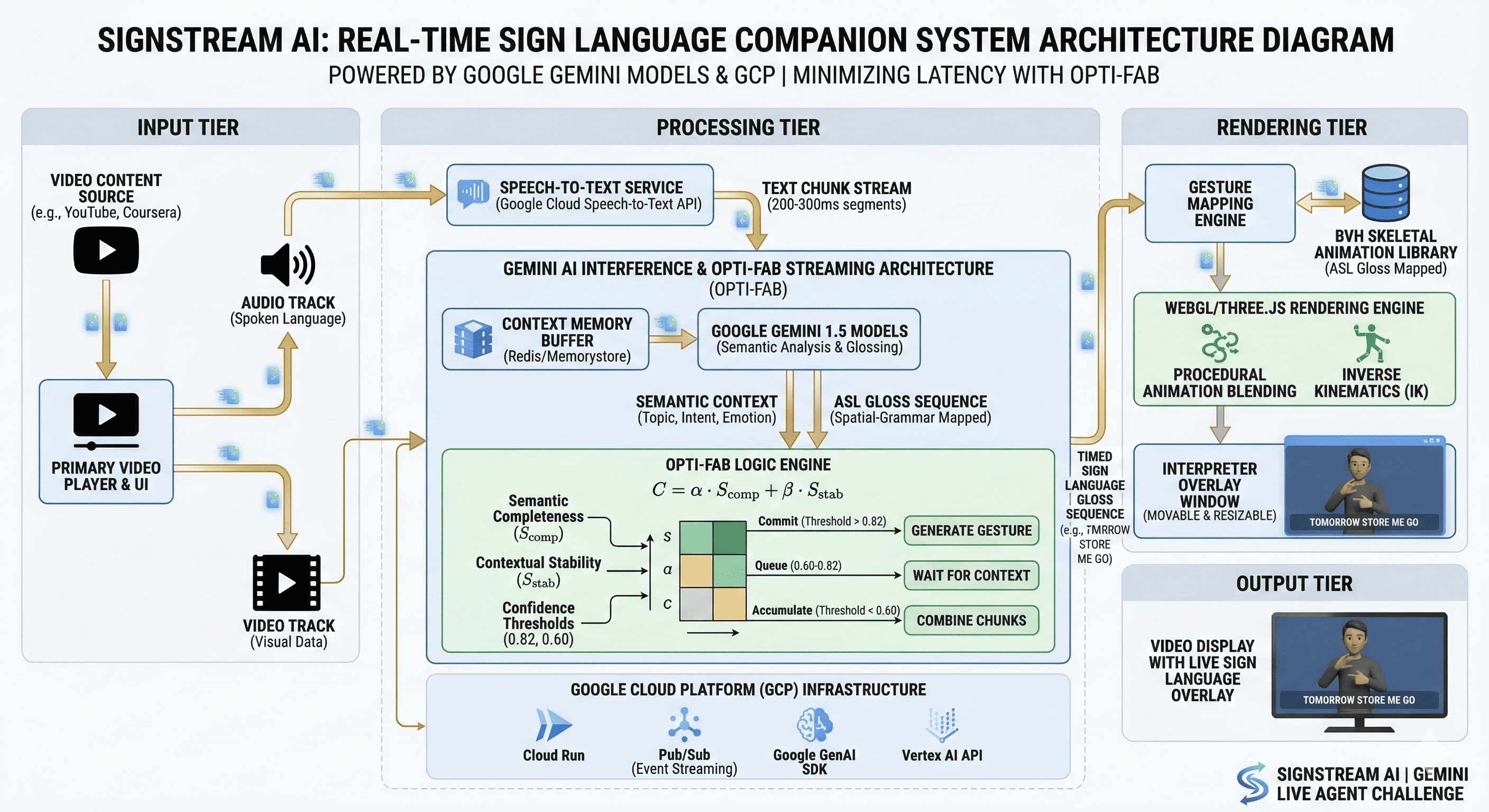
SignStream AI architecture for real-time speech-to-sign language interpretation using Gemini and Google Cloud
Inspiration
According to the WHO, over 430 million people worldwide experience disabling hearing loss. While digital video content is exploding, accessibility is lagging. We realized that the industry's default solution—closed captions—is fundamentally flawed for native sign language users.
American Sign Language (ASL) is not just "English on the hands"; it is a distinct spatial language with its own morphology and syntax (like Time-Topic-Comment structures). Forcing a pre-lingually deaf user to read fast-paced English captions is forcing them to rapidly translate a second language in their head, resulting in high cognitive load and a loss of emotional nuance. We were inspired to build a true, multimodal accessibility tool: a system that "listens" to spoken audio and translates it natively into visual-spatial sign language, just like a human interpreter.
What it does
SignStream AI is a real-time, multimodal AI agent designed to bridge the auditory-visual gap. It operates as an interactive overlay on any video player.
As the video plays, the agent actively listens to the audio stream, processes the spoken language to understand semantic meaning and context, and instantly renders a 3D avatar performing the corresponding sign language gestures. It doesn't just do a rigid, word-for-word translation; it translates the intent and meaning of the speaker, including idioms and grammatical correct ASL glossing, enabling native visual communication for the deaf and hard-of-hearing community.
How we built it
We built the system around a decoupled microservices architecture heavily leveraging the Google ecosystem:
- Audio Ingestion: We capture browser audio and stream it via WebSockets to the Google Cloud Speech-to-Text API for low-latency transcription.
- The Brain (Gemini AI): We route the text stream to Google Gemini via the GenAI SDK. Using few-shot system prompting, we instruct Gemini to act as an expert ASL linguist, converting English sentences into "ASL Gloss" (the written representation of signs and spatial grammar) while extracting semantic intent.
- OPTI-FAB Streaming Architecture: To eliminate the 2-4 second delay of traditional AI translation, we engineered OPTI-FAB (Optimized Partial-stream Inference for Fluid Avatar Behavior). Instead of waiting for a full sentence, the system calculates a dynamic confidence score using $C = \alpha \cdot S_{comp} + \beta \cdot S_{stab}$ (where $S_{comp}$ is semantic completeness and $S_{stab}$ is contextual stability). If the score surpasses a threshold, it triggers the avatar immediately, before the speaker finishes their sentence.
- Rendering Layer: We use WebGL/Three.js to render a 3D skeletal rig. We map the Gemini gloss outputs to a database of BVH animation files.
Challenges we ran into
- The Latency Bottleneck: Traditional seq2seq NLP models suffer from "exposure bias" and need a full sentence to work. Overcoming this to achieve real-time rendering was incredibly difficult and led to the creation of our OPTI-FAB sliding-window approach.
- Linguistic Dissonance: Preventing the AI from doing literal translations (e.g., translating "raining cats and dogs" into the signs for actual animals). We had to heavily refine our Gemini prompts to ensure it mapped idioms to correct conceptual signs.
- Robotic Coarticulation: Humans don't put their hands down between every sign. Blending separate animation files together looked jittery. We had to implement an Animation State Machine with procedural blending and inverse kinematics (IK) to ensure the avatar smoothly transitioned from one gesture to the next.
Accomplishments that we're proud of
- Sub-Second Latency: Through our OPTI-FAB architecture, we managed to bring the translation latency down from the industry standard of ~3 seconds to 300–600 milliseconds, matching the responsiveness of a professional human sign interpreter.
- True Multimodal Transformation: We successfully moved beyond a standard "chat-box" AI. We built an agent that takes unstructured temporal audio data and transforms it natively into structured, spatial-visual 3D outputs.
- Semantic Glossing: Successfully getting an LLM to reliably output grammatically accurate ASL gloss rather than broken English syntax.
What we learned
- The Depth of ASL Linguistics: We gained a profound appreciation for the complexity of sign languages and why standard translation APIs fail so spectacularly at addressing deaf accessibility.
- Streaming Inference: We learned how to balance AI confidence with speed, mastering the art of partial-stream processing and continuous data ingestion.
- Advanced Prompt Engineering: We discovered how powerful Gemini's contextual window is when tasked with translating abstract concepts and emotional intent rather than just raw text.
What's next for Signstream
- Non-Manual Markers (NMM): In ASL, meaning is heavily dictated by facial expressions (e.g., raised eyebrows for a question). Next, we will use Gemini's sentiment analysis to drive facial blendshapes on our 3D avatar.
- Browser Extension Integration: Packaging the entire frontend into a Chrome Extension so users can natively toggle the interpreter on platforms like YouTube, Twitch, and Coursera.
- Bi-Directional Communication: Integrating computer vision so the user can sign back at their webcam, translating their signs into text/speech for hearing participants on video calls (like Zoom or Google Meet).
- Global Expansion: Scaling our animation database to support British Sign Language (BSL), Auslan, and Indian Sign Language (ISL).
Built With
- ai-tools
- and
- and-cloud-infrastructure.-the-system-uses-python-for-backend-development-and-javascript
- and-css-for-the-frontend-interface.-google-gemini-ai-models-were-integrated-using-the-google-genai-sdk-to-process-and-understand-spoken-language.-the-backend-services-are-deployed-on-google-cloud-platform
- be
- can
- cloud
- containerization
- docker
- for
- handled
- html
- specifically-using-google-cloud-run-for-scalable-server-deployment.-the-application-utilizes-fastapi-for-building-the-api-layer-and-web-audio-api-for-capturing-and-processing-audio-streams.-for-real-time-communication-between-the-frontend-and-backend
- this-project-was-built-using-a-combination-of-modern-web-technologies
- using
- websocket-technology-is-used.-visual-rendering-of-the-interpreter-interface-can-be-implemented-using-three.js-and-standard-web-technologies.-development-and-version-control-were-managed-using-github


Log in or sign up for Devpost to join the conversation.