-

Front page
-
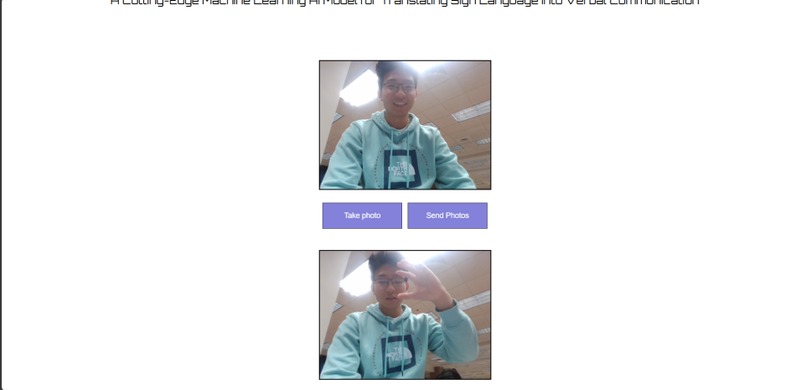
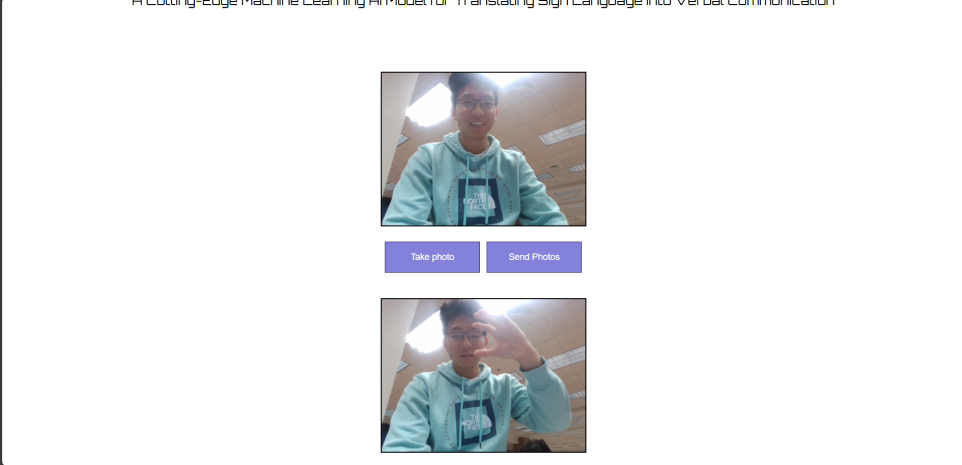
ASL to speech pipeline interface

Inspiration
Sign language is a beautiful and essential form of communication, yet it often goes unrecognized in digital spaces. We noticed this and wanted to create a tool that bridges the gap between sign language and spoken language, empowering both deaf and hearing individuals to communicate more effectively. Our inspiration came from the desire to enhance accessibility and promote inclusion for the deaf community.
What it does
SignSpeak is a web app that can take pictures of American Sign Language (ASL) and convert it to text and speech. After users capture their string of ASL through our frontend, our backend processes these images to provide real-time text translations and spoken output, making communication seamless and efficient.
How we built it
We used RoboFlow to create a custom ASL detection model using YoLOv8 (achieving over 95% mAP), then integrated it into a website with an HTML/CSS/JS frontend and Node.js/Express.js backend. We utilized Python and PyTorch to create a Recurrent Neural Network (RNN) with Long Short-Term Memory (LSTM) units to parse the raw character input from the YoLO model. Finally, we employed pyttsx3 (a Python text-to-speech conversion library) to generate audio from the detected signs and passed both the text and the audio back to the web app for user interaction.
Challenges we ran into
One big challenge we ran into right off the bat was that we originally planned on making it fully automatic, by having a webcam stream deposit the ASL info directly into the YoLO model. However, we found that Roboflow streams and inference sinks were challenging to work with, so we decided to make the ASL interface use images instead of a constant video stream. Furthermore, we originally planned on using David Lee's premade ASL library on RoboFlow, however, we found that this model was quite inaccurate when we tested it. We thus decided to create and train our own model. We also originally planned on utilizing FreeWilli to display the text and the audio. However, this turned out to be very challenging, so we ended up just passing it back to the website.
Accomplishments that we're proud of
We were able to successfully develop a functional prototype of SignSpeak that can recognize ASL signs from images and convert them to text and speech. This project consisted of a lot of "firsts" for all of us - our first fully-automatic YoLO pipeline, our first recurrent neural network, and our first website with a "real" backend, so we're really proud that our project has an output at all. Moreover, we were able to successfully integrate the various components of the application, creating a smooth user experience.
What we learned
Throughout the dev process, we learned valuable lessons about working through roadblocks. Furthermore, we also gained more experience with web development using Node.js and Express.js, as well as integrating front-end and back-end.
What's next for SignSpeak
Deploying it to the web! Although we have a fully functional front and backend, we decided not to deploy it online as none of us had experience in that area before. However, we believe that SignSpeak is currently at a functional state that can be deployed.

Log in or sign up for Devpost to join the conversation.