-
-
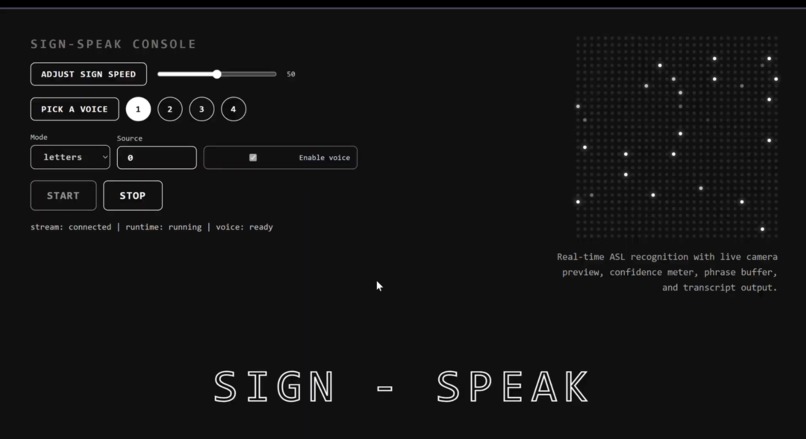
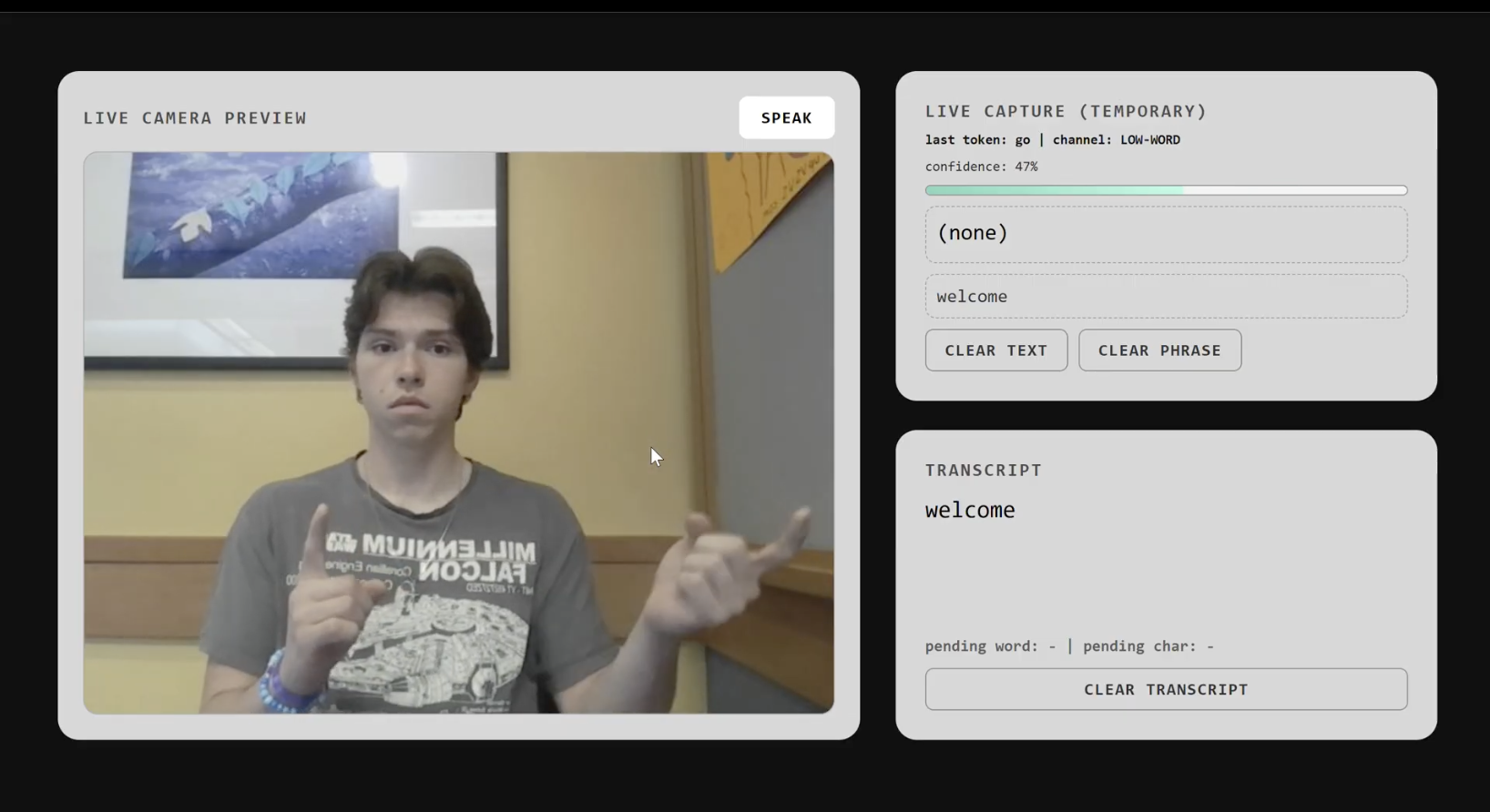
Upper home page (intro, adjustments and settings)
-
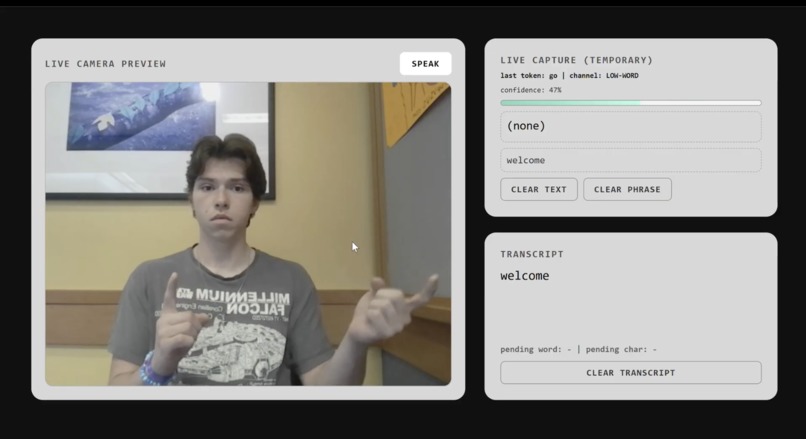
Lower home page (video feed and character processing)
-
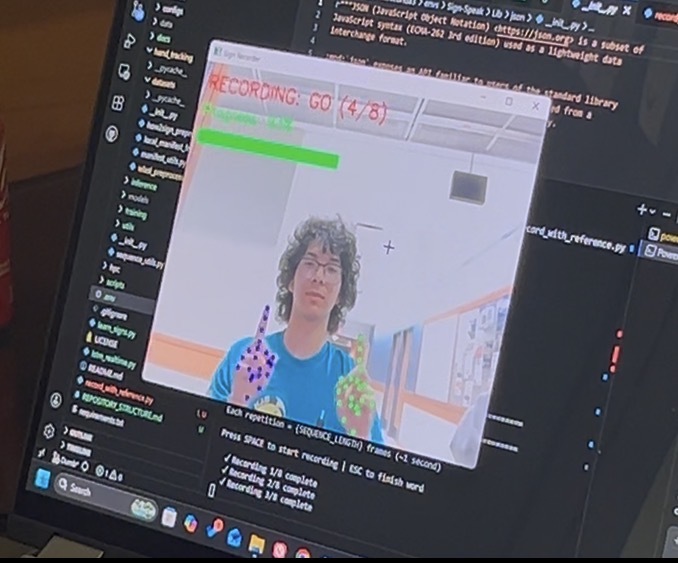
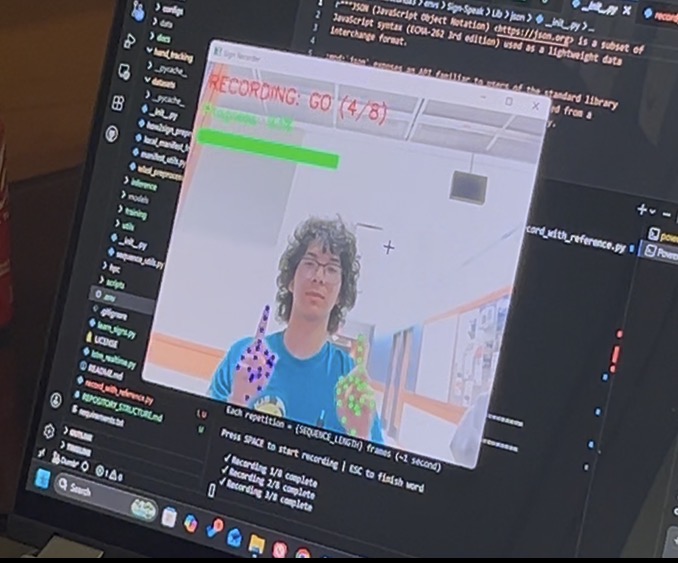
Training ASL words
Inspiration
There are over 70 million deaf people globally, yet the hearing world is largely "illiterate" in American Sign Language (ASL). This creates a massive, everyday communication wall. We didn't just want to build another static ASL dictionary we wanted to build a bridge. Our goal was to create a real time, vocal link between two worlds, giving ASL a natural spoken voice.
What it does
SignSpeak is an AI powered translation tool that gives a spoken voice to ASL. By converting visual signs from a live video feed into natural spoken audio, it bridges the communication gap between individuals who communicate with ASL and those who are unfamiliar with it.
How we built it (Below is our workflow)
Vision: We used OpenCV and MediaPipe to track 21 distinct hand landmarks in real time allowing the computer to analyze specific hand positions. Machine Learning: We trained a custom TensorFlow neural network on these hand positions, mapping coordinate data to corresponding ASL characters. Processing Characters: As characters are registered, we pass the raw strings to the Google Gemini API. Gemini reformats the text for clarity and grammar, and critically, detects the emotional tone of the sentence. Voice Generation: We then route that data to the ElevenLabs API to generate speech. By matching the voice to the tone provided by Gemini, we add genuine emotion and life to the translation. Frontend: Everything is tied together on a sleek and dark React UI built with Vite. The dashboard showcases the live video feed, real time character registration, and the final output strings before they are sent to the AI services.
Challenges we ran into
We learned the hard way that training a TensorFlow model on a standard laptop CPU is incredibly time consuming. We had to downsize our dataset to focus on the alphabet and a few core words to meet the hackathon deadline. Due to timing constraints, we left some stretch goal UI settings (like speed adjustment and user choice voices) in the backlog to dedicate more time to making sure the project worked.
Accomplishments that we're proud of
We successfully chained together a custom local ML model with two Gemini and ElevenLabs APIs without sacrificing speed. Additionally, we designed a modern and clean React dashboard that we are genuinely proud to demo. Also, despite our compute power constraints, we successfully trained the model to recognize the entire ASL alphabet and several full words.
What we learned
Never train a model on a basic laptop without expecting to wait hours! We learned a lot about dataset optimization out of pure necessity. Also, we gained massive experience managing state and routing data between Python backends, React frontends, and external APIs. Most importantly, we learned a lot of ASL during the testing phase and gained a much deeper appreciation for the complexity of sign language.
What's next for SignSpeak
Our immediate next step is securing better compute power to train the model on a massive vocabulary of whole words and fluid sentences. Beyond that, we envision packaging SignSpeak into a mobile app or a video call plugin to provide real time closed captioning and audio dubbing for ASL users anywhere they go.




Log in or sign up for Devpost to join the conversation.