-
-

-
Machine Learning
-

Sign Speech Glove


Inspiration
During a school-funded event for individuals with learning disabilities, we noticed a communication barrier due to students’ limited ability to understand sign language. The current solution of using camera recognition fails to be feasible since pulling out a phone during a conversation is impractical and the individual may not consent to being recorded at all. To effectively bridge this gap, we developed SignSpeak, a wearable real-time translator that uses flex sensors to instantly translate sign language gestures. This innovation promotes effective communication, fostering equality and inclusion for all.
What it does
SignSpeak is a real-time American Sign Language to Speech translation device, eliminating the need of a translator for the hearing impaired. We’ve built a device that consists of both hardware and software components. The hardware component includes flex sensors to detect ASL gestures, while the software component processes the captured data, stores it in a MongoDB database and uses our customized recurrent neural network to convert it into spoken language. This integration ensures a seamless user experience, allowing the hearing-impaired/deaf population to independently communicate, enhancing accessibility and inclusivity for individuals with disabilities.
How we built it
Our hardware, an Arduino Mega, facilitates flex sensor support, enabling the measurement of ten sensors for each finger. We quantified finger positions in volts, with a linear mapping of 5V to 1023 for precise sensitivity. The data includes a 2D array of voltage values and timestamps.
We labeled data using MongoDB through a Python serial API, efficiently logging and organizing sensor data. MongoDB's flexibility with unstructured data was key in adapting to the changing nature of data during various hand gestures.
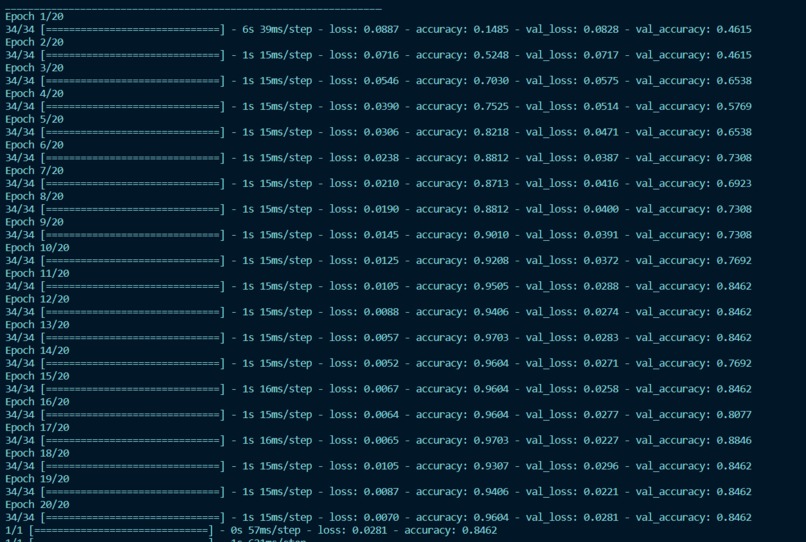
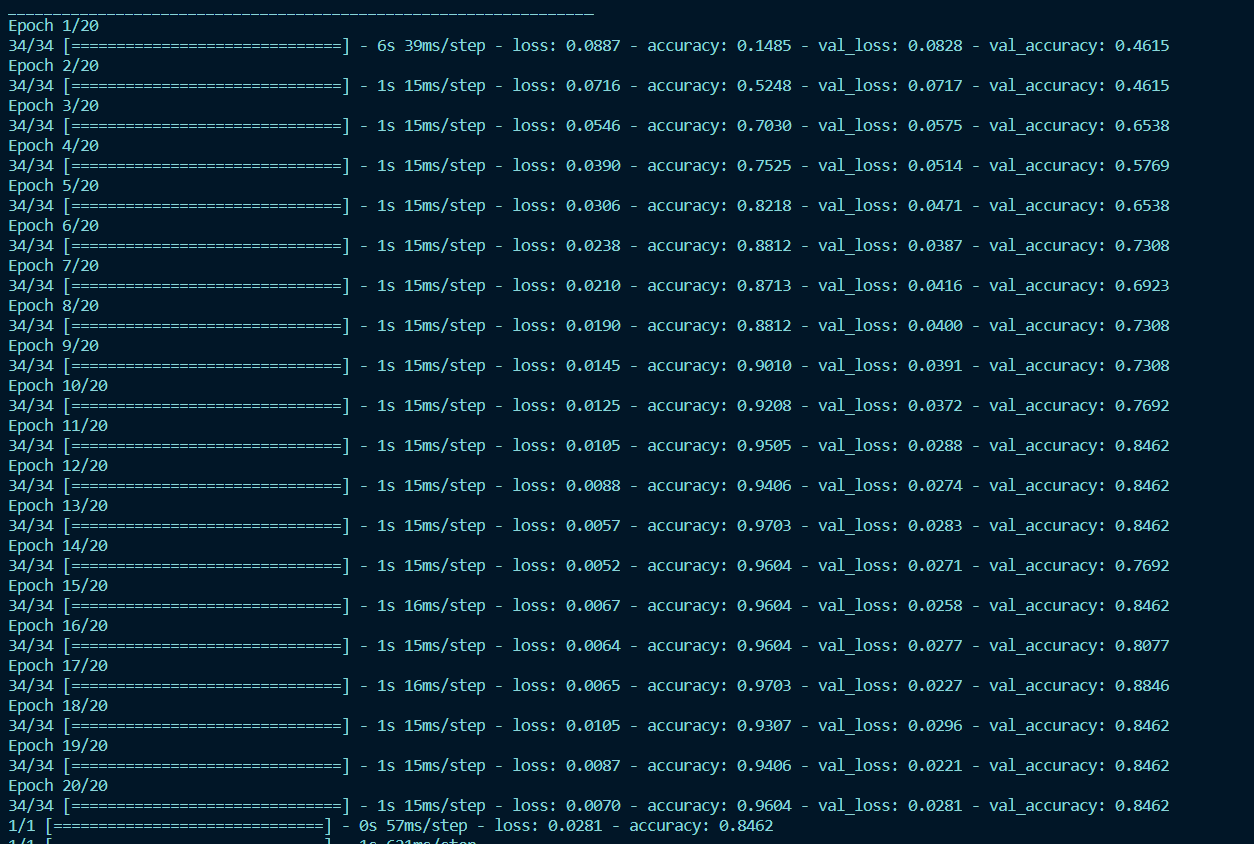
After reviewing research, we chose a node-based RNN algorithm. Using TensorFlow, we shaped and conformed data for accuracy. Training was done with 80% test and 20% validation, achieving 84% peak accuracy. Real-time input from COM5 is parsed through the RNN model for gesture sequence and voice translation using text-to-speech.
Challenges we ran into
A lot of our challenges stemmed from hardware and software problems related to our sensors. In relation to hardware, the sensors, over time adjusted to positions of flexion, resulting in uncalibrated sensors. Another prominent issue was the calibration of our 3D data from our sensors into a 2D array as an RNN input as each sign was a different length. Through constant debugging and speaking with mentors, we were able to pad the sequence and solve the issue.
Accomplishments that we're proud of
We’re most proud of being able to combine software with hardware, as our team mostly specialized in hardware before the event. It was especially rewarding to see 84% accuracy on our own custom trained dataset, proving the validity of our concept.
What's next for SignSpeak
SignSpeak aims to expand our database whilst impacting our hardware to PCBs in order to allow for larger and wider public translation.






Log in or sign up for Devpost to join the conversation.