-
-
Winner Winner Chicken DInner
-
Architecture Overview
-
Architecture-Live-Session
-
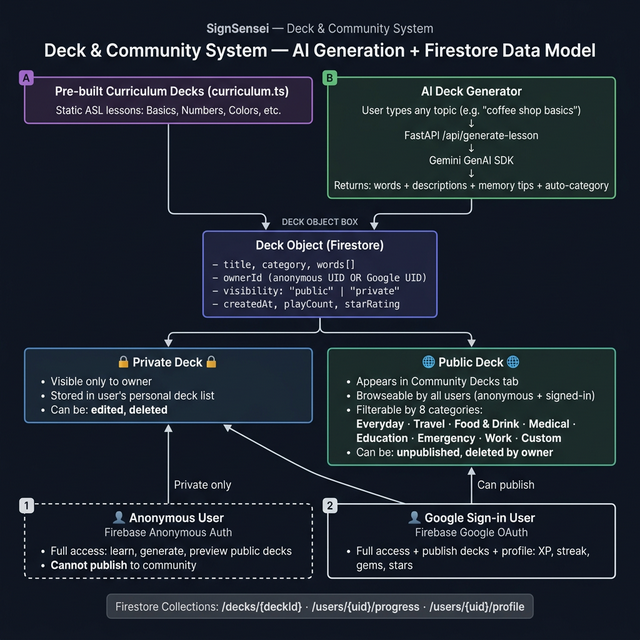
Architecture-Deck-Community
-
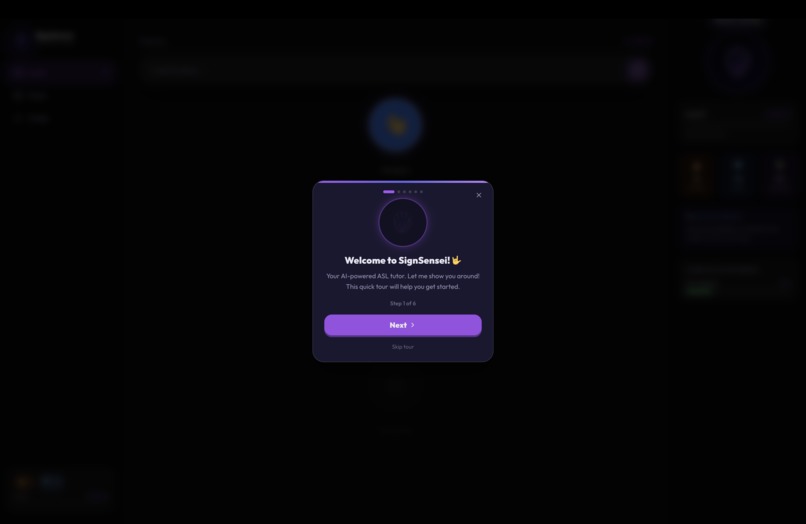
Tour Guide
-
-
-
-
Inspiration
American Sign Language (ASL) is used by over half a million people in the US alone, yet finding an accessible, patient, and affordable tutor is incredibly difficult. Traditional apps rely on multiple-choice quizzes or passive video playback — they can't actually see if you're performing the physical movements correctly.
We looked at the new Gemini Multimodal Live API — sub-second latency, native video understanding, and real-time audio — and saw something others hadn't built yet: a closed-loop physical skills tutor. An AI that doesn't just show you how to sign, but watches you do it and coaches you to mastery.
SignSensei was born from a simple belief: a patient, always-available ASL teacher should not be a luxury. It should be a URL.
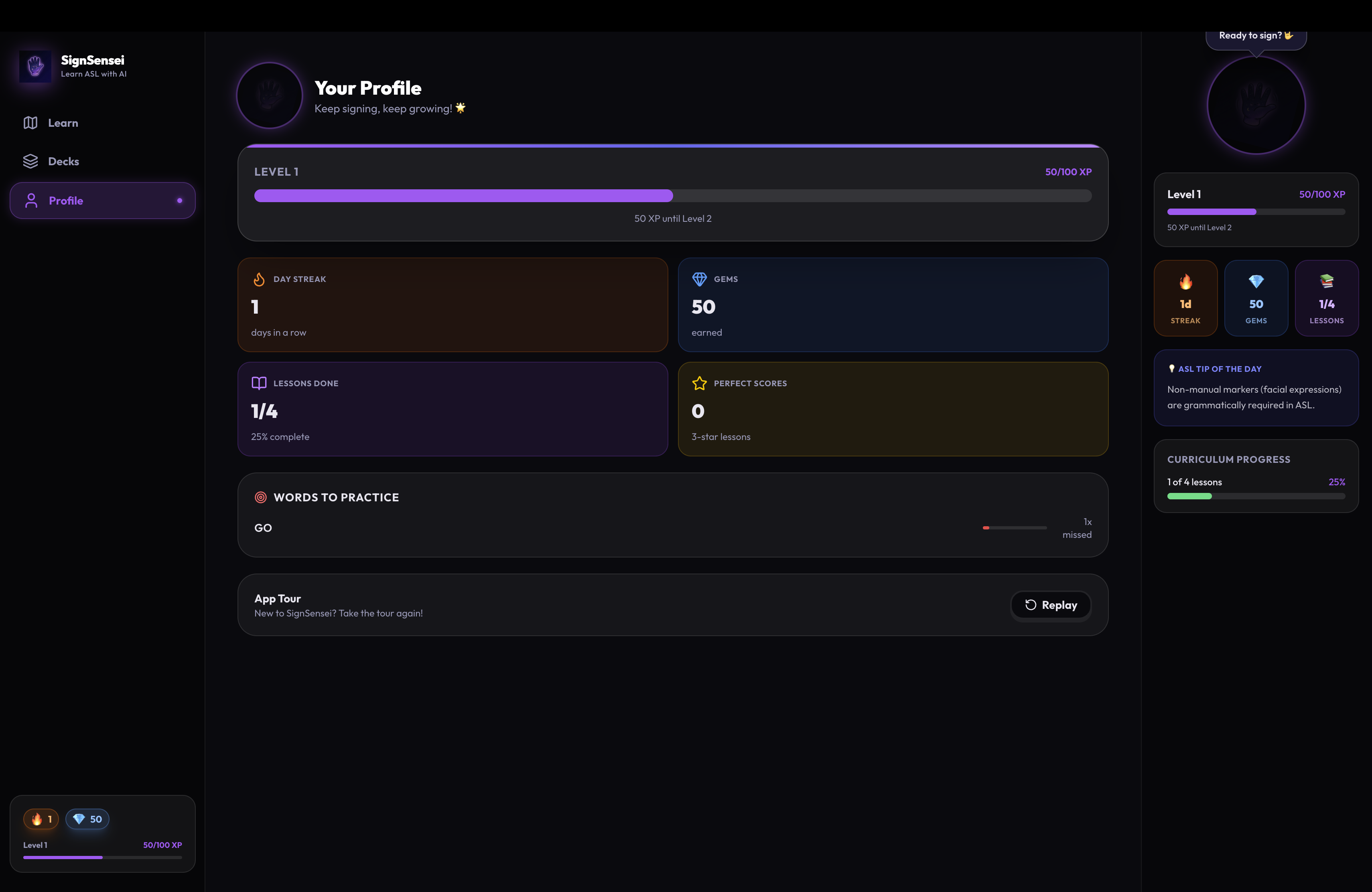
What it does
SignSensei is a real-time, interactive ASL learning platform. It's not a video dictionary. It's a live, bidirectional tutoring loop.
🚀 Try it instantly — no account needed: signsensei.web.app
Here's how a typical session works:
- The AI tutor introduces the sign — spoken instructions, visual reference video.
- You say "Ready" — the webcam activates for your signing window.
- You sign, then say "Done" — Gemini watches your hands and grades the attempt.
- If correct: The UI celebrates, awards XP, and advances the curriculum.
- If incorrect: Gemini explains exactly what went wrong (handshape, location, movement) and you retry — as many times as you need.
After mastering all words in a lesson, you face the Boss Stage — a full conversational sentence challenge graded as a complete performance.
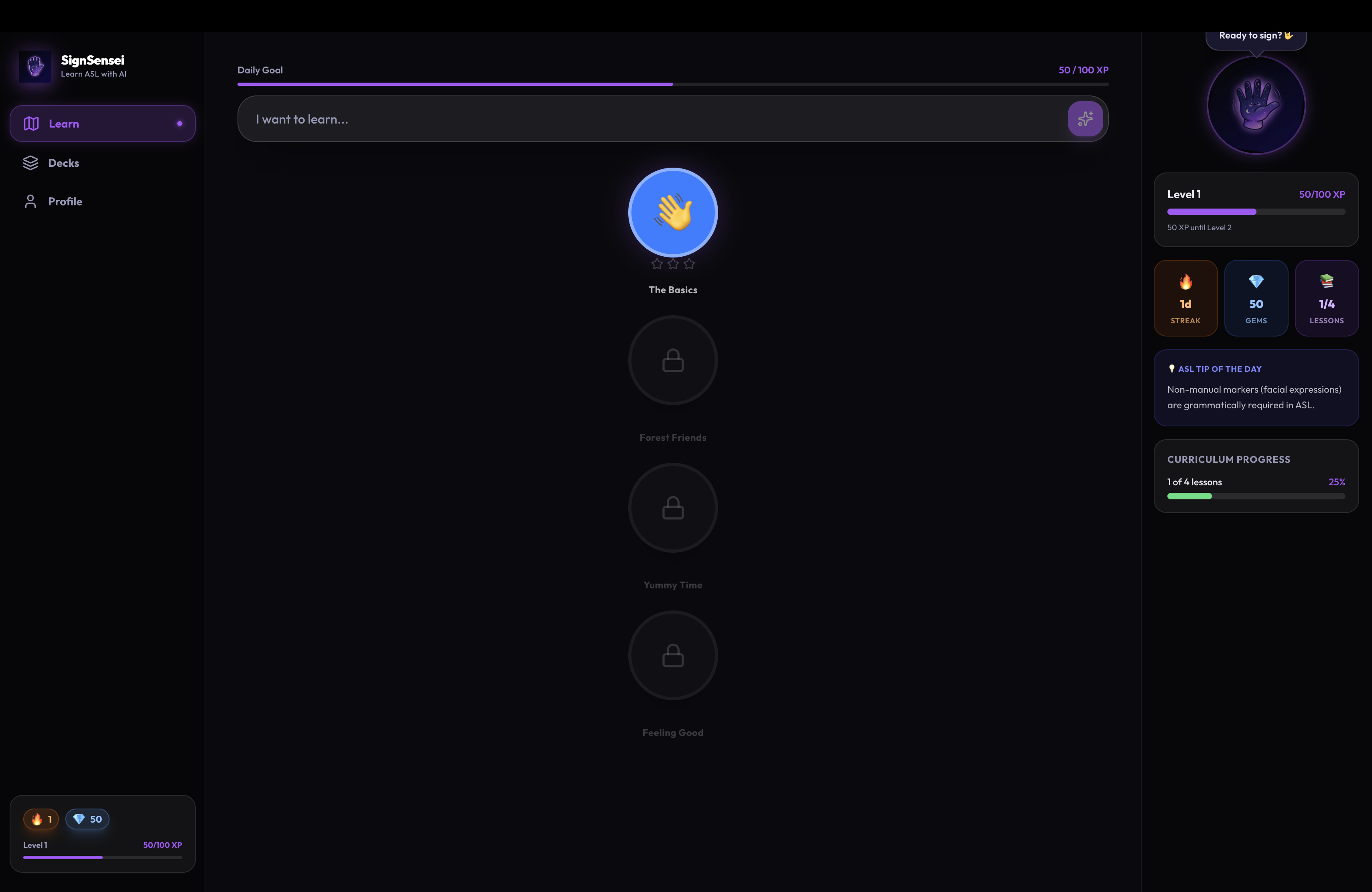
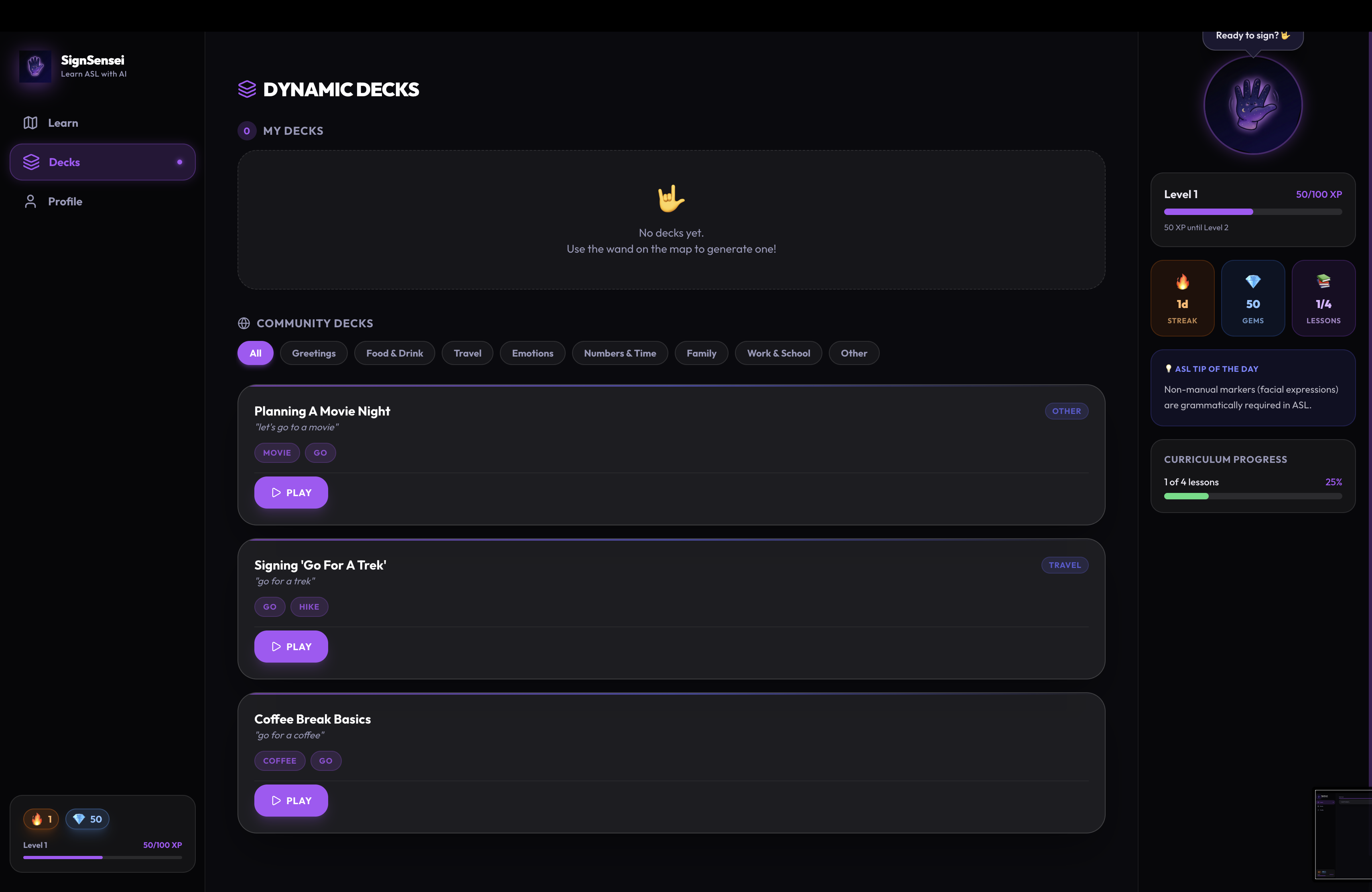
Key features:
- 🎥 Real-time vision grading via Gemini Live 2.5 Flash
- 🗣️ Voice-first UX — no typing, no clicking, just signing and speaking
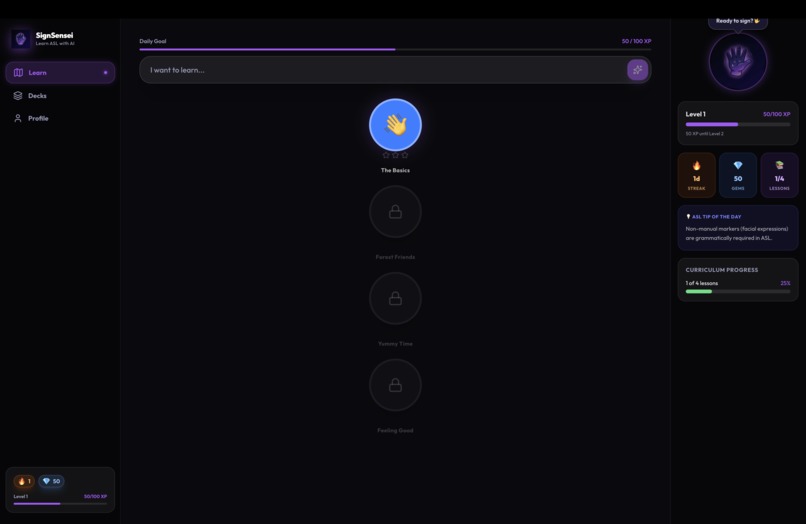
- 🗺️ Saga-map curriculum (Duolingo-style progression)
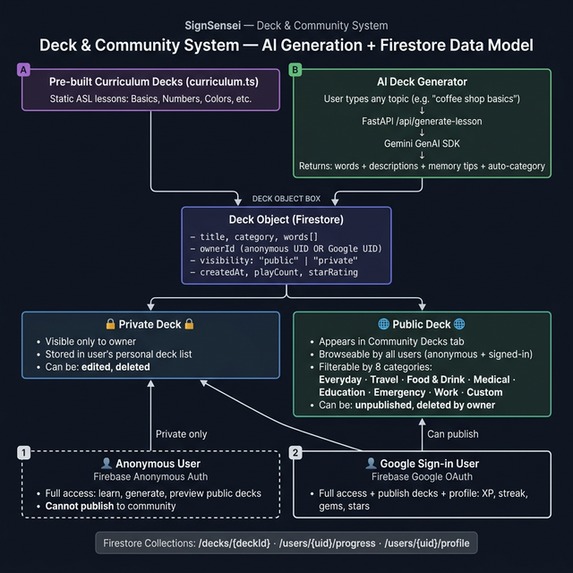
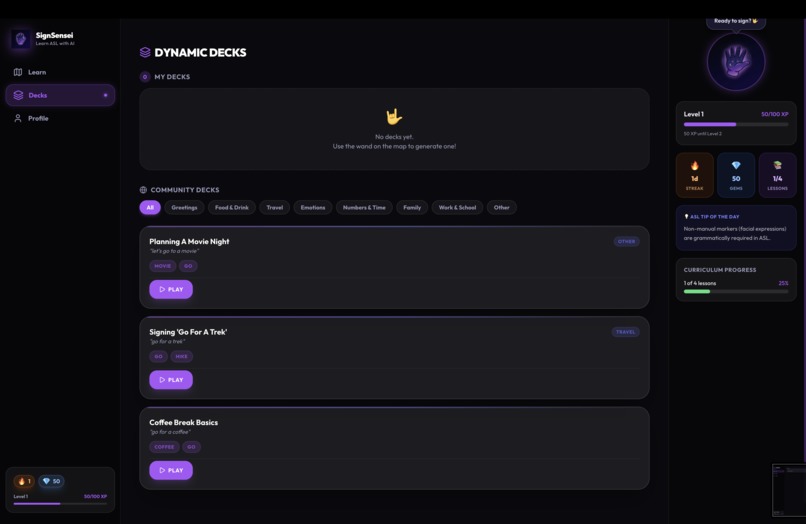
- 🤖 AI Deck Generator — type any topic, get a custom ASL lesson in seconds
- 🎭 Mascot emotion system — 7-state animated mascot reacts to your performance
- 📱 Full PWA — installable on iOS/Android, works offline
How we built it
Tech Stack
| Layer | Technology | Purpose |
|---|---|---|
| Frontend | React 19, Vite, TypeScript | SPA, PWA |
| Styling | Tailwind CSS, Framer Motion, GSAP | Dark glassmorphism UI, animations |
| State | Zustand + TanStack Query | Split-brain (client/server) state |
| AI (Live) | Gemini Live 2.5 Flash | Real-time vision + audio tutoring |
| AI (Decks) | Gemini 2.0 Flash Lite | Lesson deck generation |
| Backend | Python FastAPI | Ephemeral token service + deck API |
| Infra | Cloud Run, Firebase Hosting, Firestore | Hosting, database, auth |
| IaC | Terraform + GitHub Actions | Keyless CI/CD via Workload Identity |
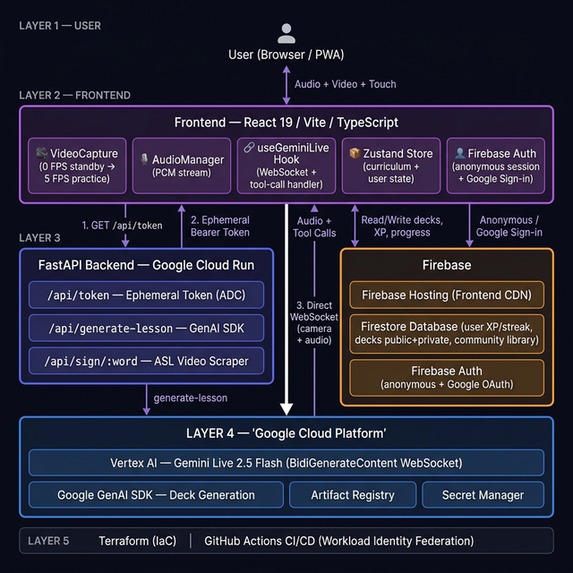
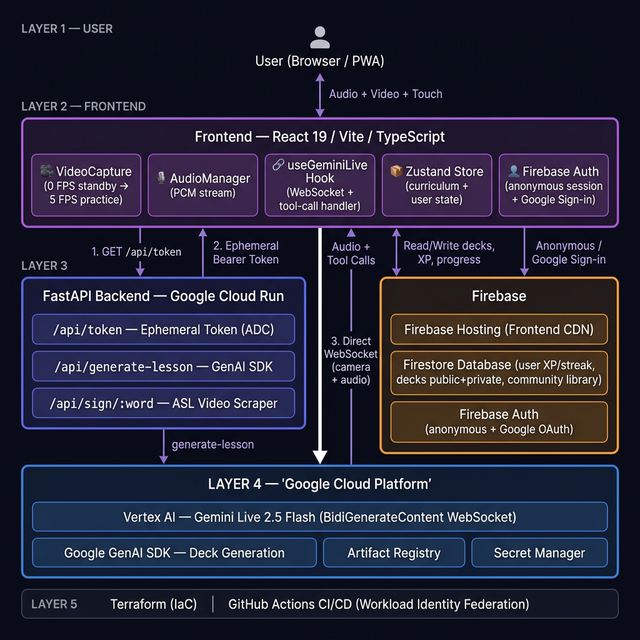
System Architecture
┌─────────────────────────────────────────────────────────────────┐
│ Browser (React SPA) │
│ │
│ ┌──────────────┐ ┌───────────────┐ ┌──────────────────┐ │
│ │ Webcam Feed │───▶│ useGeminiLive │───▶│ Zustand Store │ │
│ │ (5 FPS) │ │ Phase Guard │ │ (Curriculum │ │
│ └──────────────┘ │ Trojan Horse │ │ State Machine) │ │
│ │ Audio Gate │ └──────────────────┘ │
│ ┌──────────────┐ └──────┬────────┘ │
│ │ Microphone │───────────┘ │
│ │ (PCM Audio) │ │
│ └──────────────┘ │
└─────────────────────────┬───────────────────────────────────────┘
│ 1. GET /api/token
▼
┌─────────────────────────────────┐
│ FastAPI Backend (Cloud Run) │
│ ADC → Mint Ephemeral Token │
└─────────────────┬───────────────┘
│ 2. Return short-lived token
▼
┌─────────────────────────────────┐
│ Vertex AI (Gemini Live) │◀─── Direct WebSocket
│ wss://us-central1-aiplatform │ from Browser
│ .googleapis.com/... │
└─────────────────────────────────┘
Critical design decision: The Gemini WebSocket connects directly from the browser to Vertex AI using a short-lived ephemeral token minted by the backend. This eliminates transcoding latency that would occur if video/audio were proxied through Cloud Run, while keeping all GCP credentials server-side.
🧠 The Control Loop: Taming a General-Purpose LLM
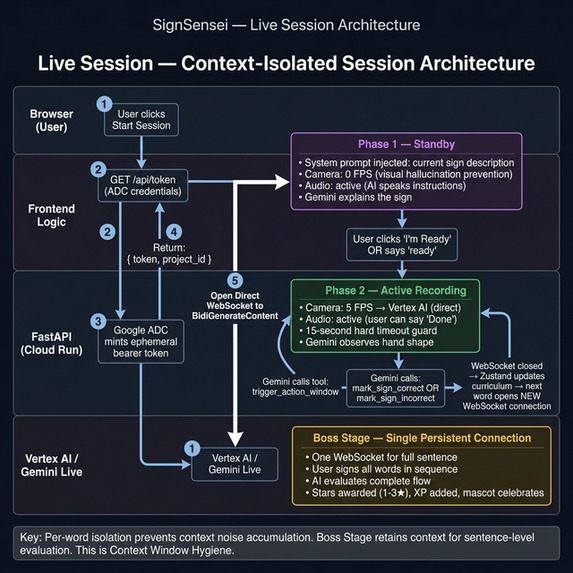
This was the core engineering challenge. Gemini is a conversationalist, not a teacher. Left unconstrained, it would grade signs too eagerly, skip phases, or hallucinate lesson advancement. We had to engineer a strict state machine on top of the live stream.
Phase System
[STANDBY / PHASE 1]
│
│ User says "Ready" → trigger_action_window
▼
[OBSERVATION / PHASE 2]
Gemini calls user_is_resting_or_calibrating in a loop
Camera runs at 5 FPS, watching for signing movement
│
│ User says "Done" → Trojan Horse injects override
▼
[GRADING / PHASE 3]
Gemini calls trigger_grading_window (ONE-SHOT TOKEN)
Then calls mark_sign_correct OR mark_sign_incorrect
│
▼
[RESULT] ──correct──▶ Advance curriculum (new WebSocket)
──incorrect──▶ Mind Wipe → back to PHASE 1
The "Trojan Horse" Override
When the user says "Done," instead of sending a direct Gemini API interrupt (which causes regressions), we inject a silent clientContent override into the next tool call response that Gemini is already waiting for. This transitions Gemini to grading mode mid-stream — without breaking the conversation flow.
The Phase Guard
A React-side interceptor that blocks tool calls arriving out of sequence. All tool calls are checked against the current phase state before being executed:
// Only allow trigger_grading_window if a one-shot token was granted
if (!isGradingWindowGrantedRef.current) {
// Reject — no UI changes, no speech triggered
return REJECT;
}
Client-Side PCM Audio Muting
Because Gemini bundles audio generation with tool calls in the stream, blocking a duplicate tool call server-side doesn't silence the already-sent audio. We built a client-side gate that drops raw PCM audio packets before they reach the browser's playback buffer:
// In the WebSocket onmessage handler:
if (part.inlineData?.mimeType.startsWith('audio/pcm')) {
if (!isAudioMutedRef.current && onAudioData) {
onAudioData(part.inlineData.data); // Only play if not muted
}
}
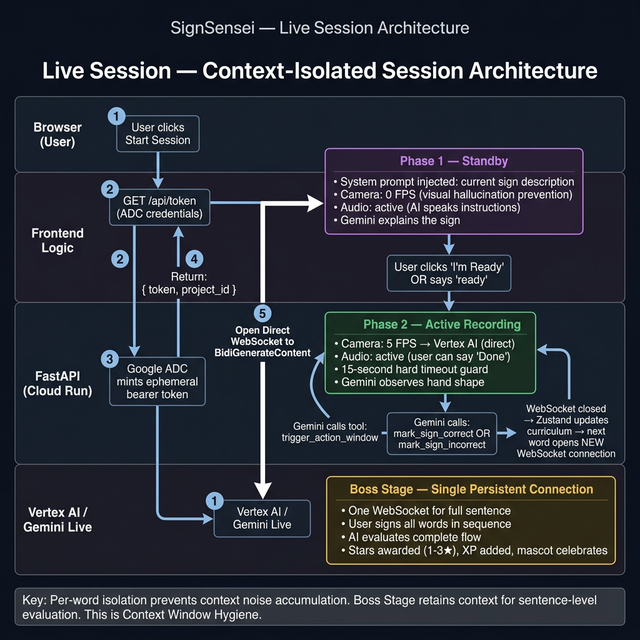
🗂️ Context-Isolated Session Architecture
Through empirical testing, we discovered Gemini's grading reliability degrades over multi-sign sessions due to accumulated context noise — the model confuses prior grading windows with the current evaluation.
| Session Type | Connection Strategy | Why |
|---|---|---|
| Individual word practice | Fresh WebSocket per word | Eliminates context bleed. Grading is deterministic from a clean state. |
| Retry after incorrect sign | Same connection kept alive | AI needs short-term memory of why the last attempt failed |
| Boss Stage sentence | Single persistent connection | Requires continuity to evaluate full sentence flow |
Key insight: Stateless context = predictable grading. This is not a workaround — it is a Context Window Hygiene pattern validated through real usage.
Challenges we ran into
1. The "Eager AI" Problem Gemini is fast — sometimes too fast. It would grade a sign mid-motion before the user finished. We built the entire Phase Guard system with a "Manual Done" protocol to enforce that grading only happens after explicit user confirmation.
2. Multimodal Hallucinations When streaming live video, the model would occasionally grade based on what it heard the user describe rather than what it saw them sign. We rewrote our tool schemas to force evaluations strictly on visual mechanics: handshape, location, movement.
3. The Double Speech Bug Duplicate tool calls arrived ~500ms apart due to Gemini Live's streaming batching. Blocking the second call server-side didn't silence its already-queued audio. Our client-side PCM audio muting layer solved this completely.
4. Context Contamination Gemini's long-term memory across signs caused it to apply grading criteria from one word to another. The context-isolated session architecture (fresh WebSocket per word) was the only reliable solution.
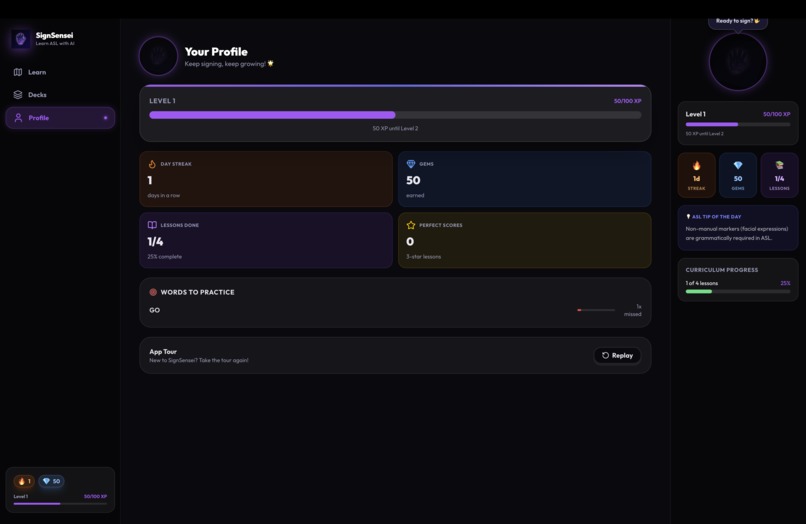
Accomplishments that we're proud of
- ✅ Forced deterministic grading out of a non-deterministic generative model
- ✅ Sub-second visual grading using just a standard laptop webcam
- ✅ Premium, production-quality UI — not a hackathon prototype aesthetic
- ✅ Zero-friction onboarding — anonymous sessions, learning in under 10 seconds
- ✅ Full IaC deployment via Terraform + keyless GitHub Actions CI/CD
- ✅ PWA — installable, offline-capable, landscape-mode for signing
What we learned
- Tool Calling is the best control flow primitive for LLM state machines. It's not just for external APIs — it's the cleanest way to synchronize an AI's internal reasoning with a deterministic frontend.
- Stateless context = predictable grading. Fresh WebSocket connections per word were more reliable than trying to "remind" a model of its current task mid-session.
- Multimodal physical education is genuinely viable today. Watching an AI evaluate hand movements in real-time and explain the error is not a demo trick — it works, repeatedly, on a consumer webcam.
What's next for SignSensei
This MVP proves the core mechanism works. Next steps:
- Facial Expression Teaching — ASL grammar depends heavily on facial expressions, not just hand movements. We want to expand grading beyond hands.
- Expanded Curricula — Medical ASL, emergency phrases, conversational ASL beyond vocabulary drilling.
- Native Mobile — Leveraging native camera APIs for smoother frame extraction and enabling learning anywhere.
Ultimately, we believe that for 70 million deaf people globally, the biggest barrier isn't the language itself — it's the lack of people who sign it.
We've proven that a universally accessible, real-time ASL tutor isn't a sci-fi concept for five years from now. It's a deployment away. It would be extraordinary to see structured skill-teaching capabilities — like SignSensei's Phase Guard and curriculum engine — built directly into the core Gemini platform one day. Until then, we've shown that the future of accessible language learning is already here.

Log in or sign up for Devpost to join the conversation.