-
-

Main page
-

Live camera feed + ASL typing
-
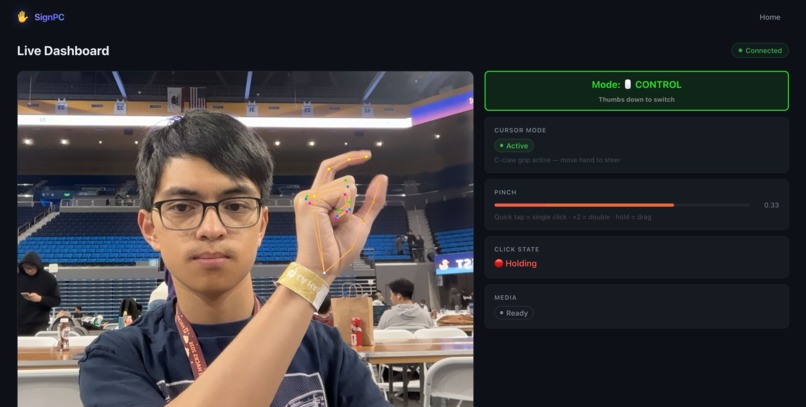
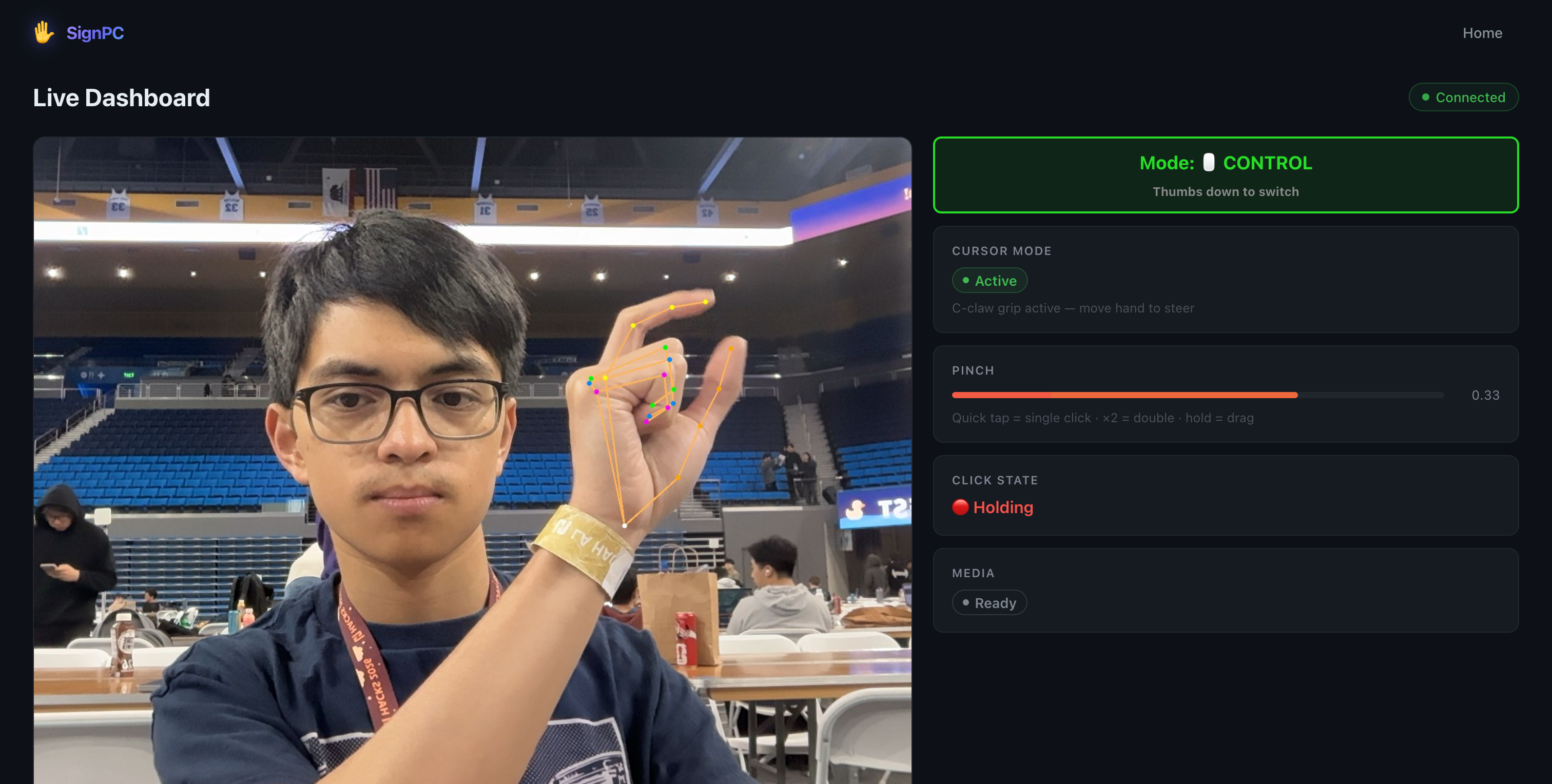
Live camera feed + cursor control


Inspiration
Traditional voice typing and commands allow you to type in conversationally intuitive ways and control your computer without a keyboard. But for people born with hearing loss who have trouble speaking, that accessibility isn't an option for them. But what if they could use their main language: American Sign Language in order to control their computer with the same ease? Enter SignPC.
What it does
SignPC is a real-time gesture interface that lets you control your entire computer using only your hand and a webcam. It runs in two modes you can switch between on the fly. In Control mode, a C-claw grip activates the cursor and your hand position steers the mouse (weighted 80% toward your thumb tip for stability). Pinching fires a click, a double pinch fires a double-click, and holding the pinch drags. An open palm held for half a second plays or pauses media. In Typing mode, SignPC recognizes ASL fingerspelling in real time using an ML classifier, committing each letter after you hold the shape steady for a quarter second. Once you've spelled out a word, a thumbs-up sends the accumulated letters to an on-device Gemma 3 model, which autocorrects recognition errors and completes the intended phrase. Everything runs 100% locally at 30 FPS. No cloud, no account, no lag.
How we built it
The backbone is MediaPipe's Hand Landmarker task, which gives us 21 3D landmarks per hand every frame. From there we built two separate feature pipelines in Python: Cursor control maps normalized thumb and index tip positions to screen coordinates with exponential smoothing, and uses pinch ratio thresholds for click detection. ASL typing normalizes the 21 landmarks relative to palm size and wrist orientation, then runs them through a 2-tier hierarchical ML classifier using scikit-learn (rule-based filtering for simple letters, KNN for the ambiguous ones)—12 classifiers in total. A FastAPI server ties it together, the camera loop runs in a background thread, writes gesture state to a shared dict, and broadcasts it at 30 FPS over a WebSocket. The React frontend connects to that socket and updates a live dashboard. The camera feed streams as MJPEG directly from the server. For AI autocorrect, we run Gemma 3-1B locally via Ollama in a separate daemon thread. When the thumbs-up gesture fires, it sends the typed letters to the model with a prompt tuned for ASL autocorrection, then streams the result back to the dashboard.
Challenges we ran into
Getting ASL recognition to feel reliable was the hardest part. Many letters look nearly identical from a single camera angle (like M versus N or U versus V), and the same hand at different distances or rotations produces very different raw landmark values. We spent significant time on normalization; scaling coordinates to palm size and rotating relative to the wrist before accuracy became usable. Gesture disambiguation was also tricky. The thumbs-up (Gemma trigger), thumbs-down (mode switch), and cursor activation gestures all live in similar hand-shape space. We added hold-duration requirements and cooldown windows to prevent false fires, but tuning those constants took a lot of trial and error. Latency was a challenge on the AI side. Our first attempt used a 9.6 GB model that took 10+ seconds per inference. Switching to Gemma 3 1B brought that down to under 2 seconds on an M4 Mac.
Accomplishments that we're proud of
The cursor control actually feels good to use. Getting the weighted thumb-anchor approach right where 80% of the cursor position comes from the stable thumb tip rather than the index made a noticeable difference in reducing jitter during pinch approach. We're also proud of having two fully functional modes that you switch between using nothing but a gesture. The full pipeline — webcam → landmark detection → gesture classification → OS-level cursor/keyboard action → live dashboard — all running under 33ms per frame.
What we learned
How to build concurrent Python programs that mix camera I/O, WebSocket broadcasting, and LLM inference without everything blocking each other. Threading discipline frame-level locks, daemon threads, skip-if-busy guards turned out to be as important as the gesture logic itself. We also learned that ASL recognition is a computer vision problem worth taking seriously. A naive approach with raw pixel landmarks gets you nowhere; careful normalization and a tiered classifier architecture made the difference between unusable and reliable.
What's next for SignPC
- Support for J and Z, which require motion tracking rather than static poses
- Two-hand detection so both hands can be active simultaneously
- Packaging as a standalone desktop app so setup is a single download
- Exploring word-level prediction rather than letter-by-letter correction type faster with fewer signs
Built With
- gemma
- mediapipe
- opencv
- python
- react
- scikit-learn



Log in or sign up for Devpost to join the conversation.