-
-
PathGuardian (Caretaker or User Option)
-

PathGuardian Login Page
-
Onboarding Page
-
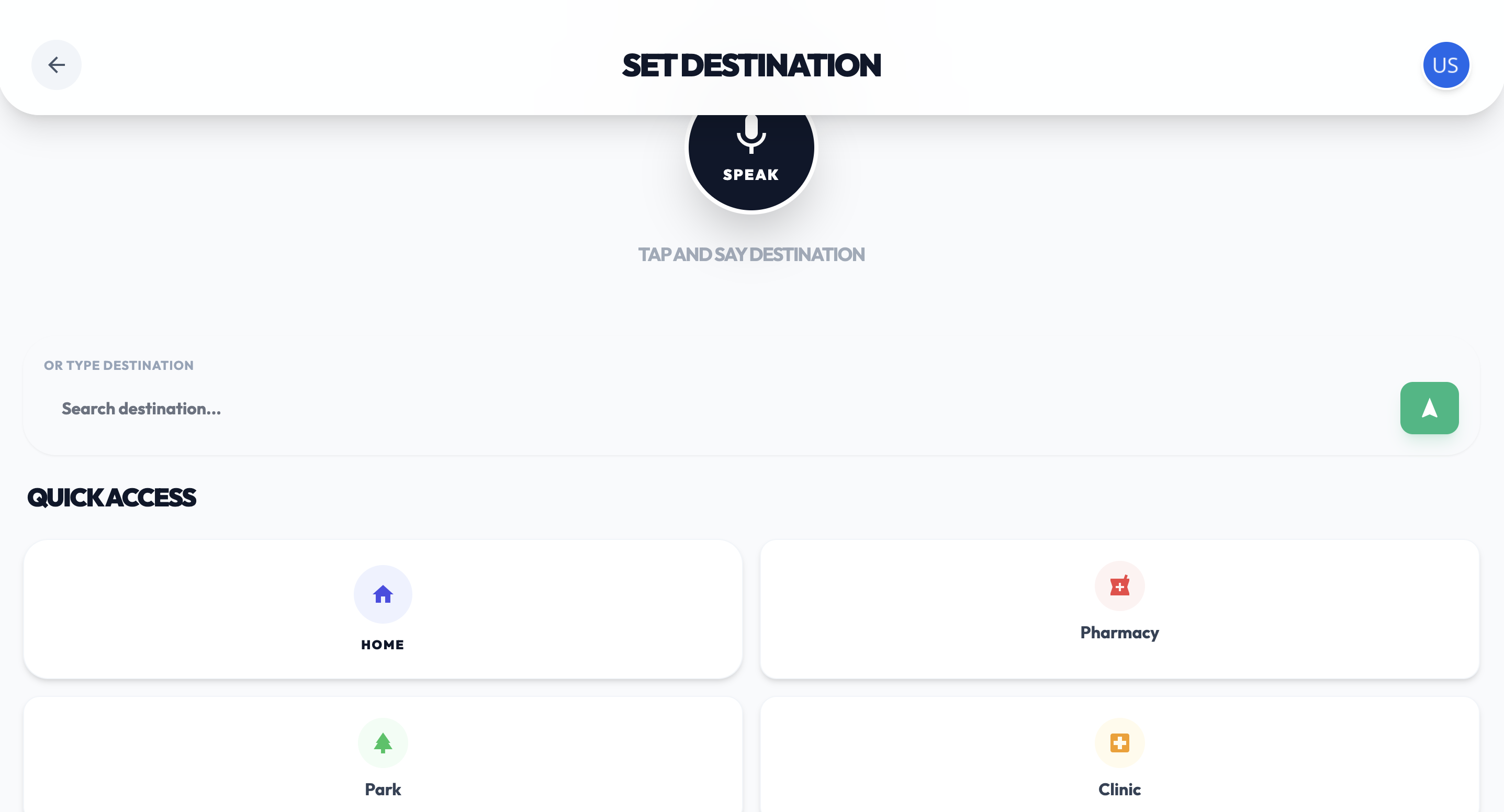
Location Setter - Speech-to-Text / Text Input
-
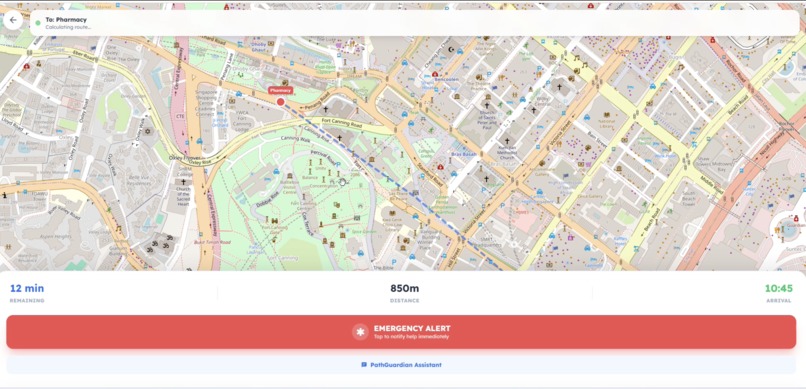
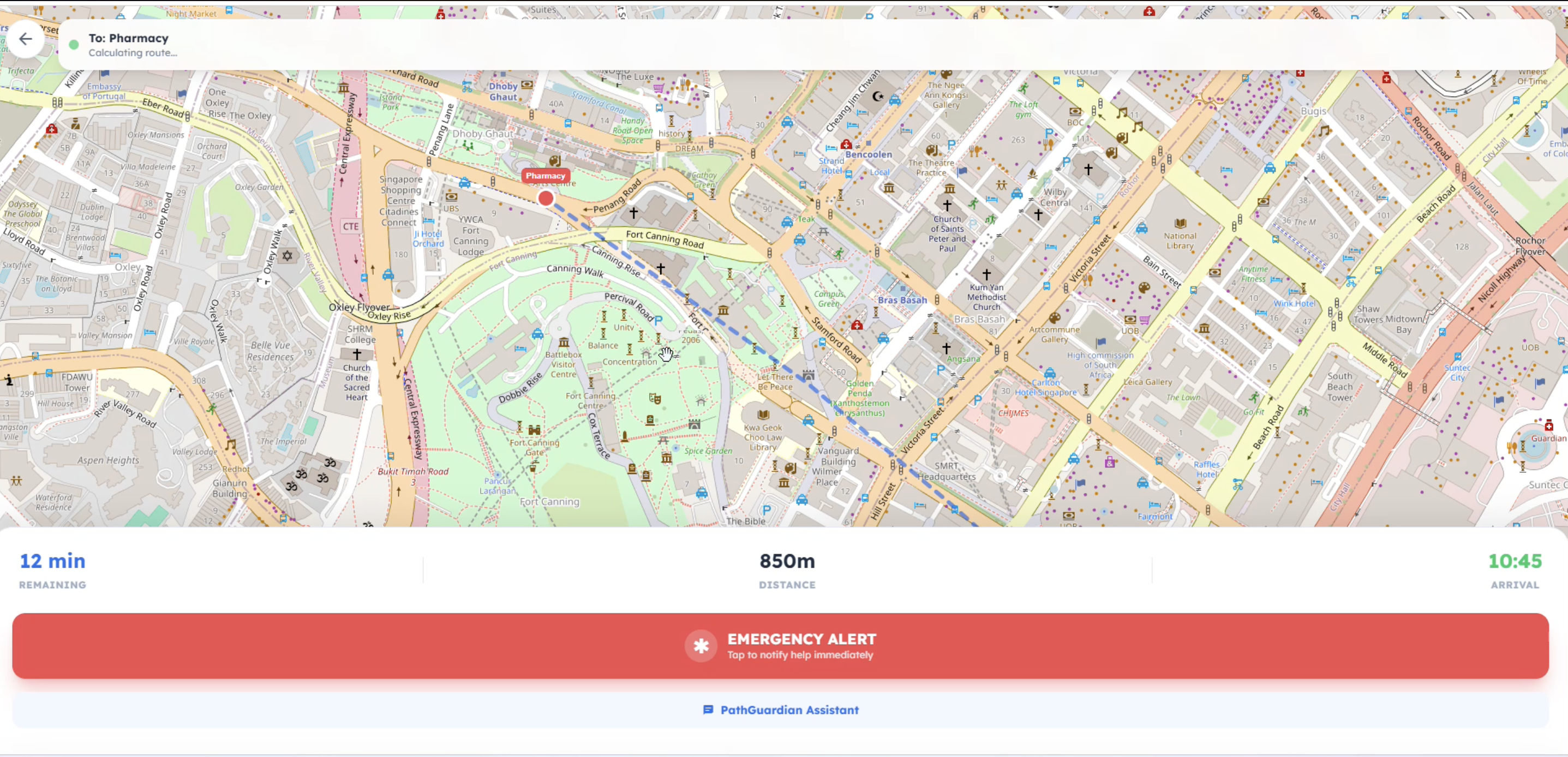
Location Tracker - Map
-
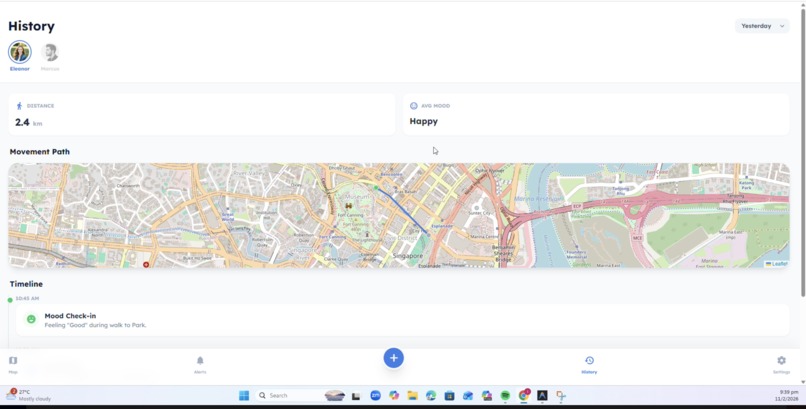
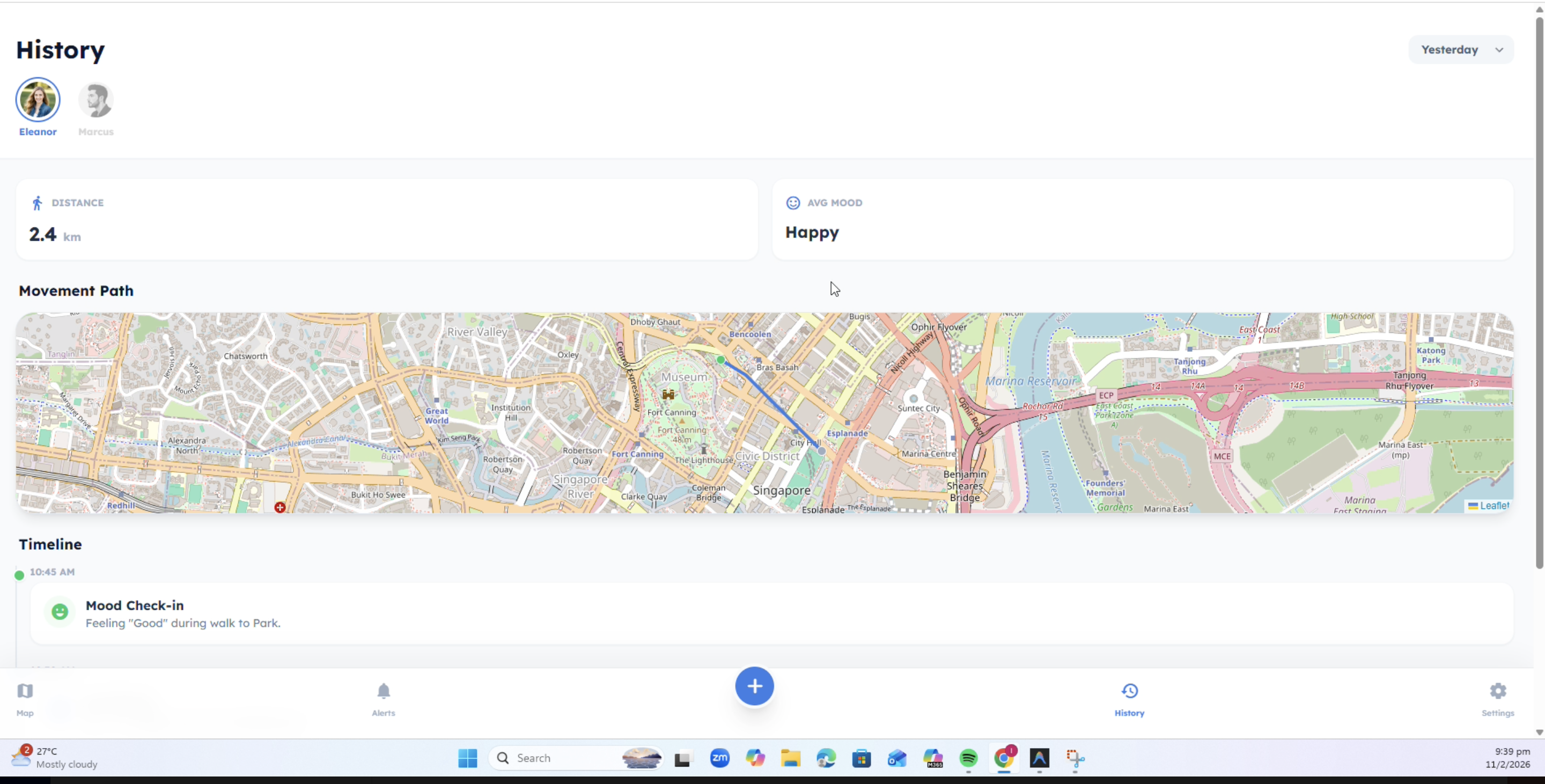
History Dashboard
-
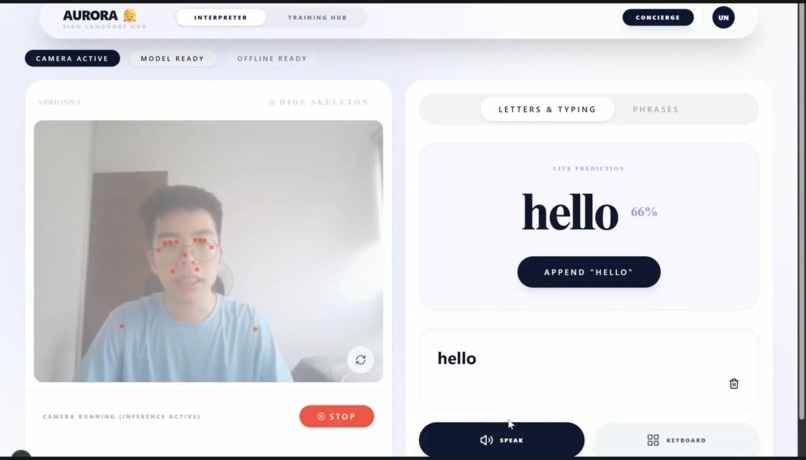
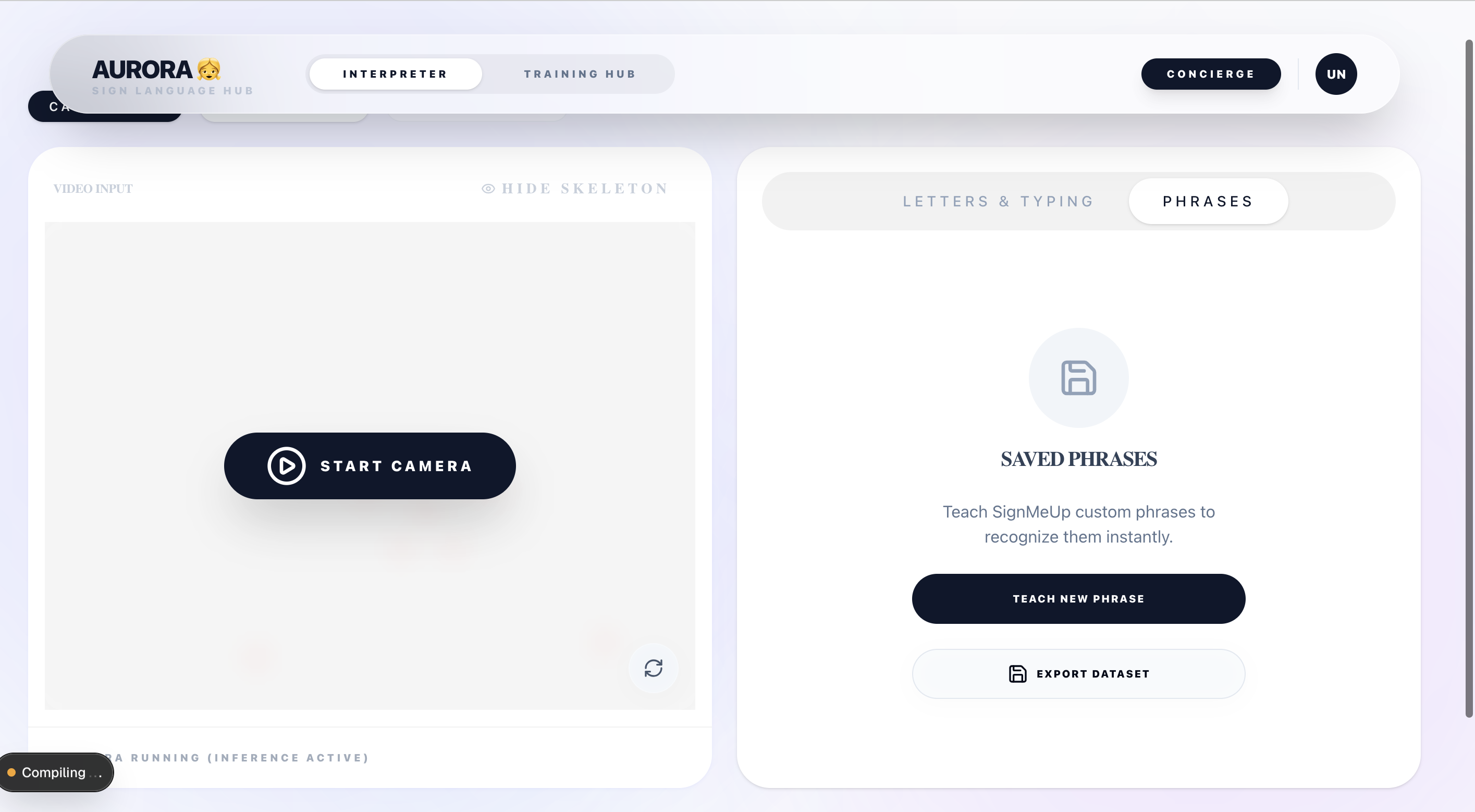
Sign Language Interpreter Dashboard
-
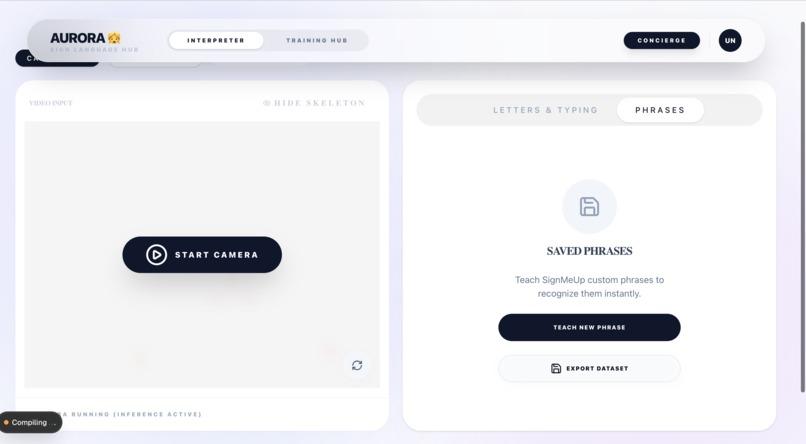
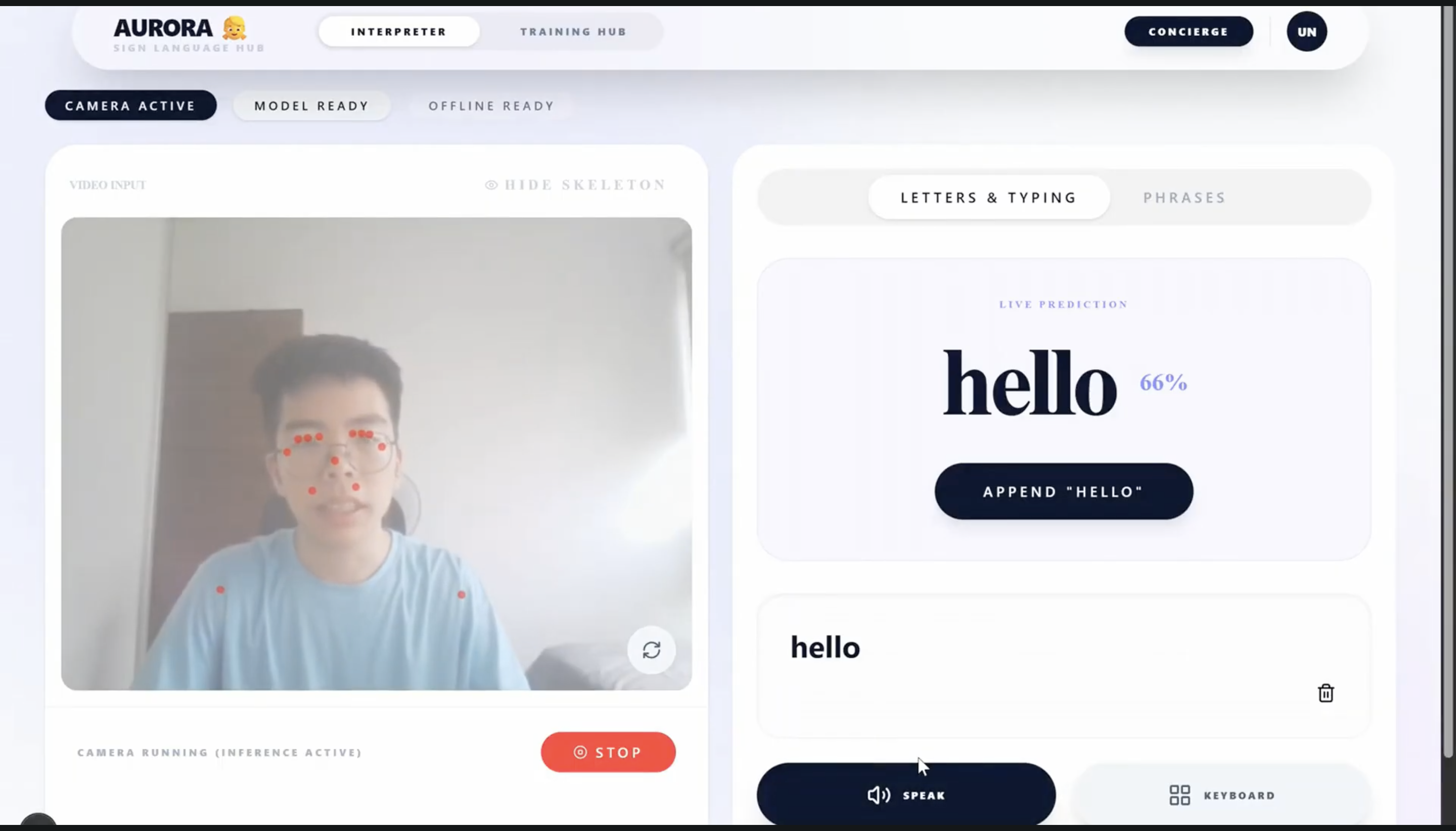
Sign Language Interpreter (Machine Learning Page)
-
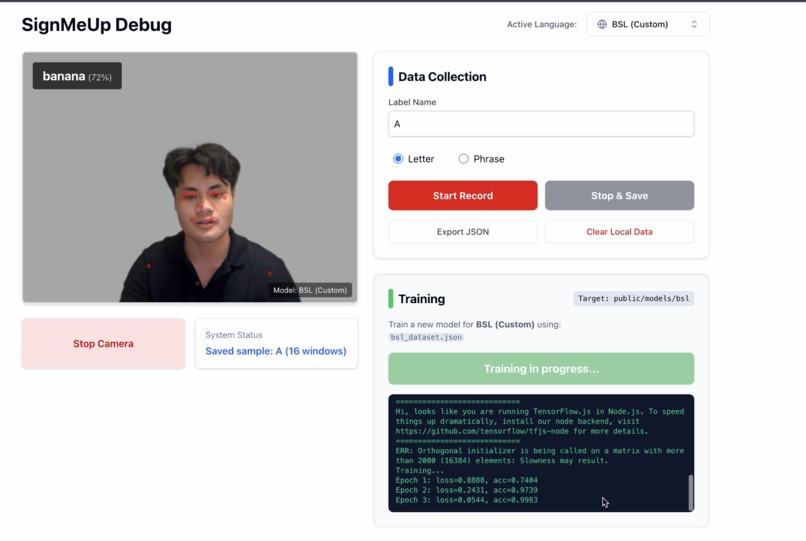
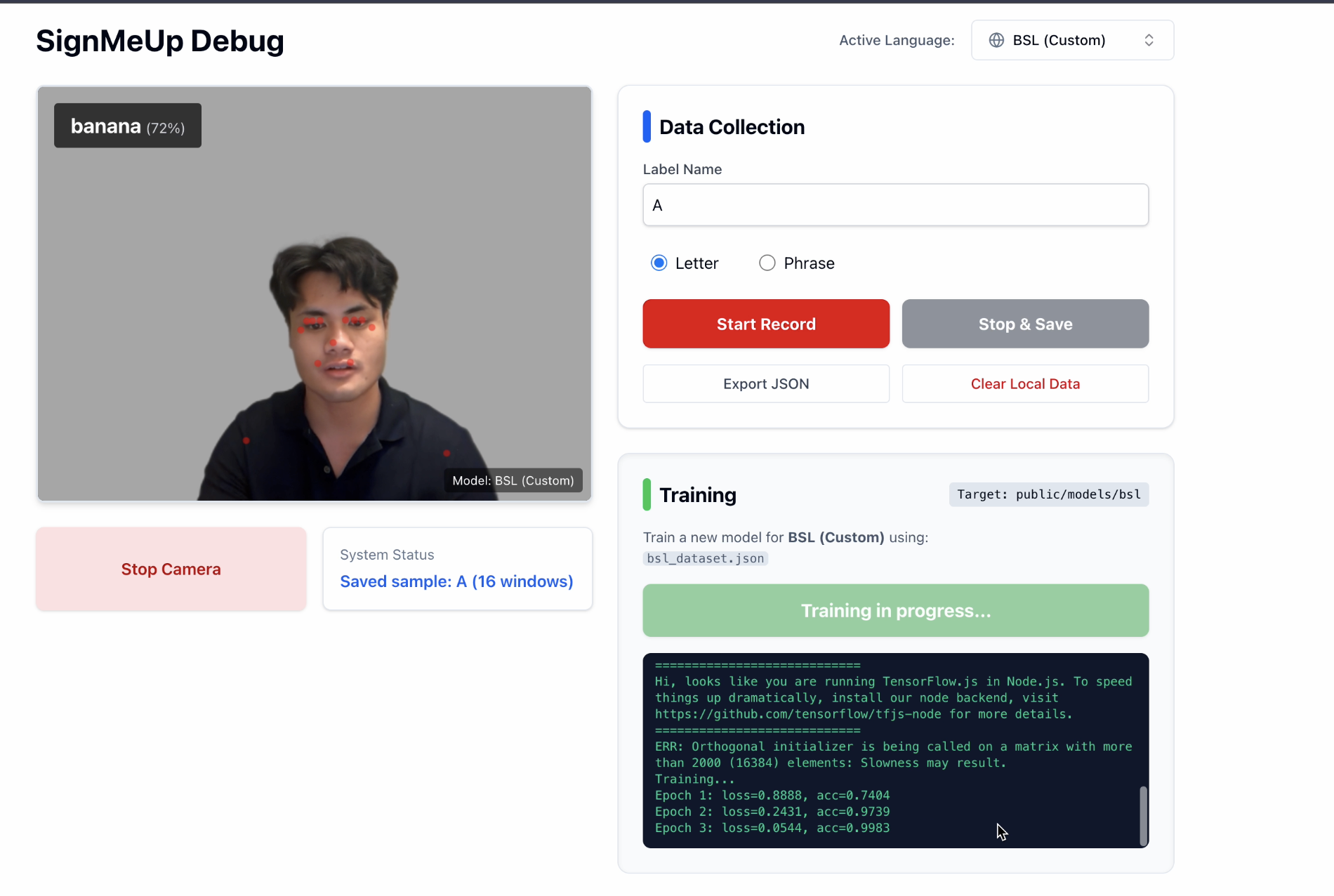
Sign Language Interpreter (Training Dataset)
-
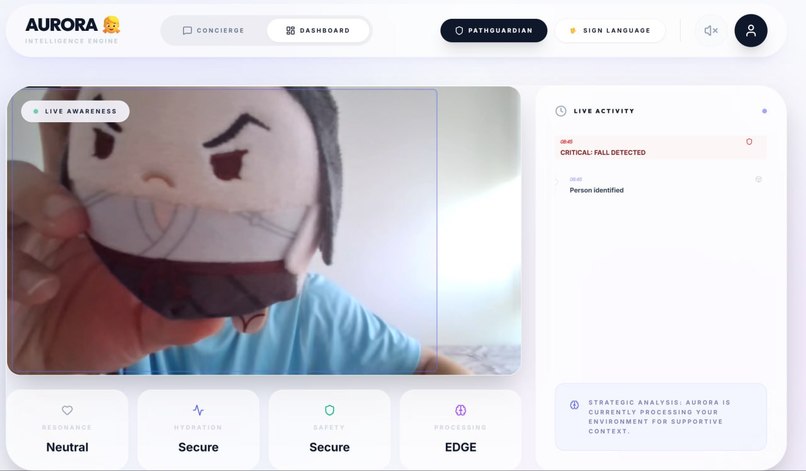
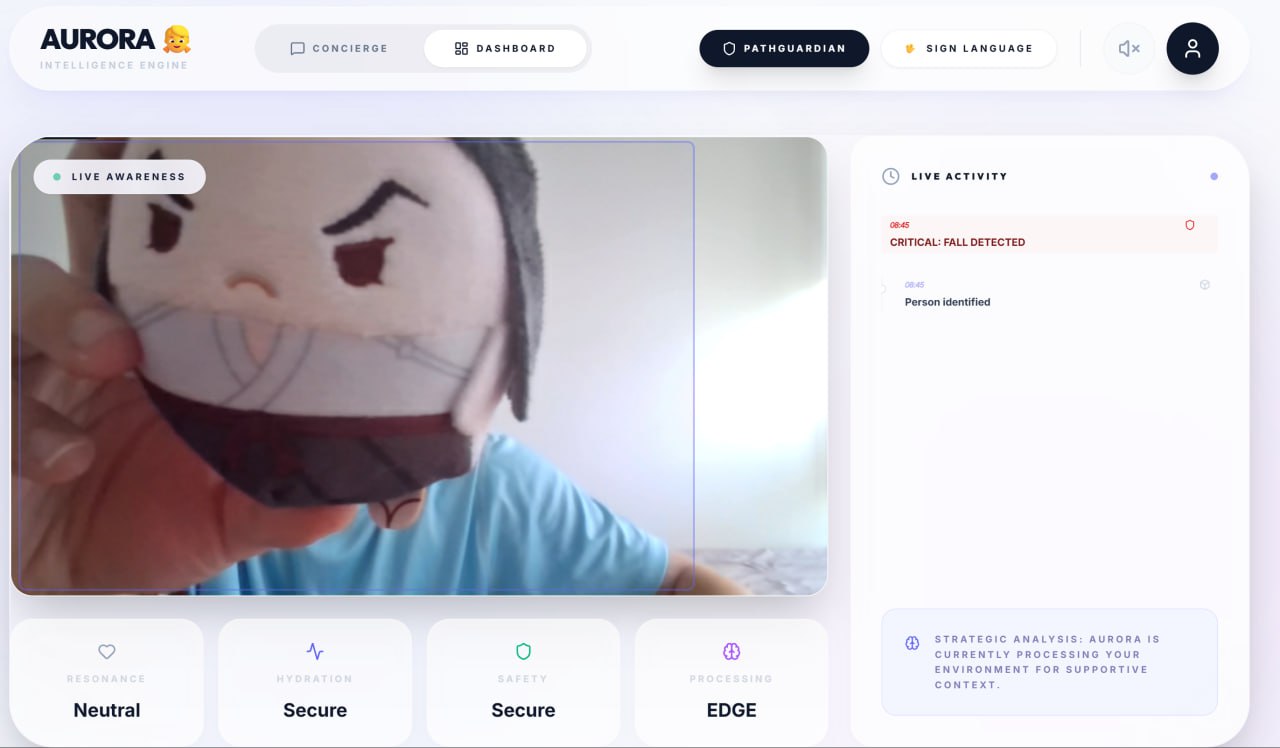
Aurora AI (Tasks and Mood Tracker)
-
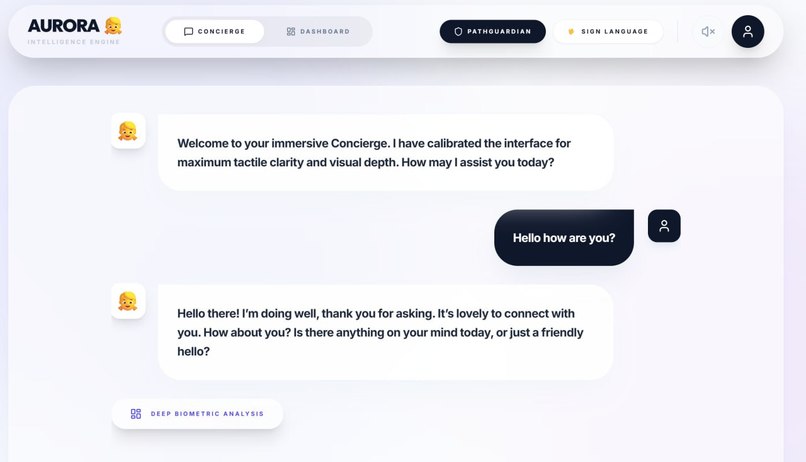
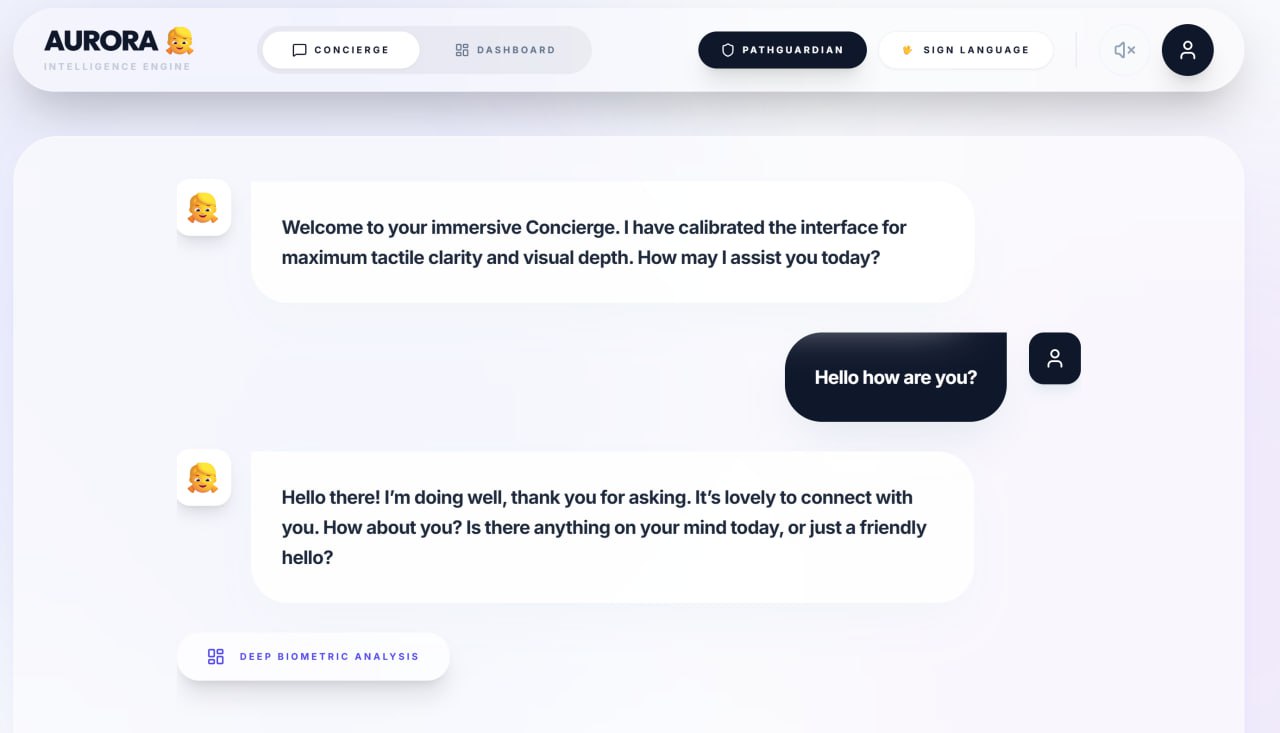
Aurora AI Chatbot Assistant (Text-to-Speech & Speech-to-Text)

Inspiration
The digital world is largely designed for the "average" user, which inherently marginalizes specially-abled individuals. While assistive technologies exist, they suffer from a fatal flaw: they are almost entirely single-modal. A screen reader assumes you can hear; a voice assistant assumes you can speak; a gesture tool assumes you have precise motor control. This creates a fragmented, isolating experience. Driven by the Changemaker League's prompt to rethink accessibility, we were inspired to build a system that adapts to the user's available modes of interaction, rather than forcing the user to adapt to the tech. We envisioned UnifierBBinary, a unified, privacy-first companion that seamlessly blends vision, voice, and gesture recognition to empower users with true independence.
What it does
UnifierBinary is an Advanced Wellness, Accessibility, and Safety Suite divided into three synchronized pillars:
- Aurora (AI Wellness Assistant): An empathetic, Gemini-powered companion that uses edge-vision to monitor safety and wellness.
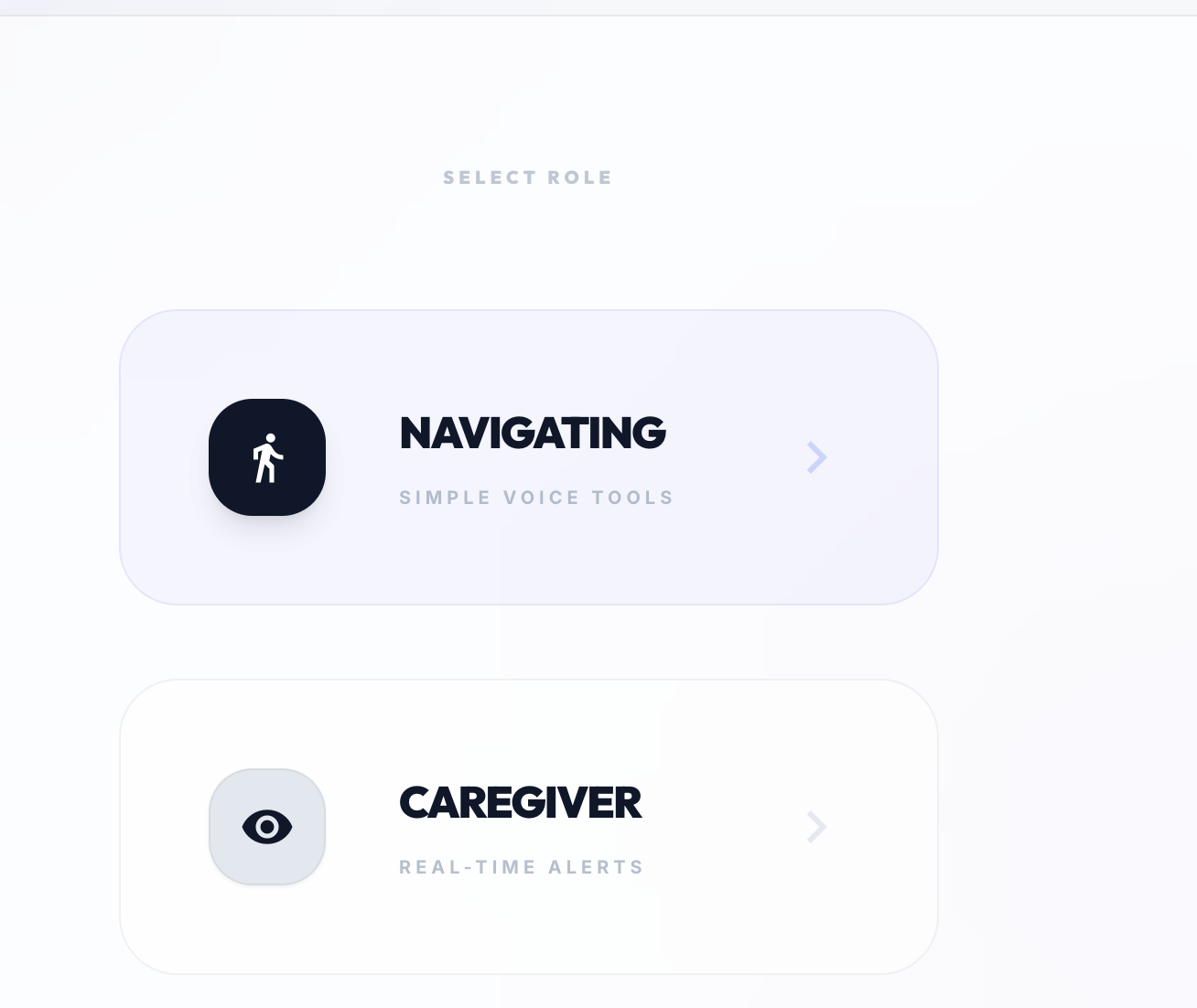
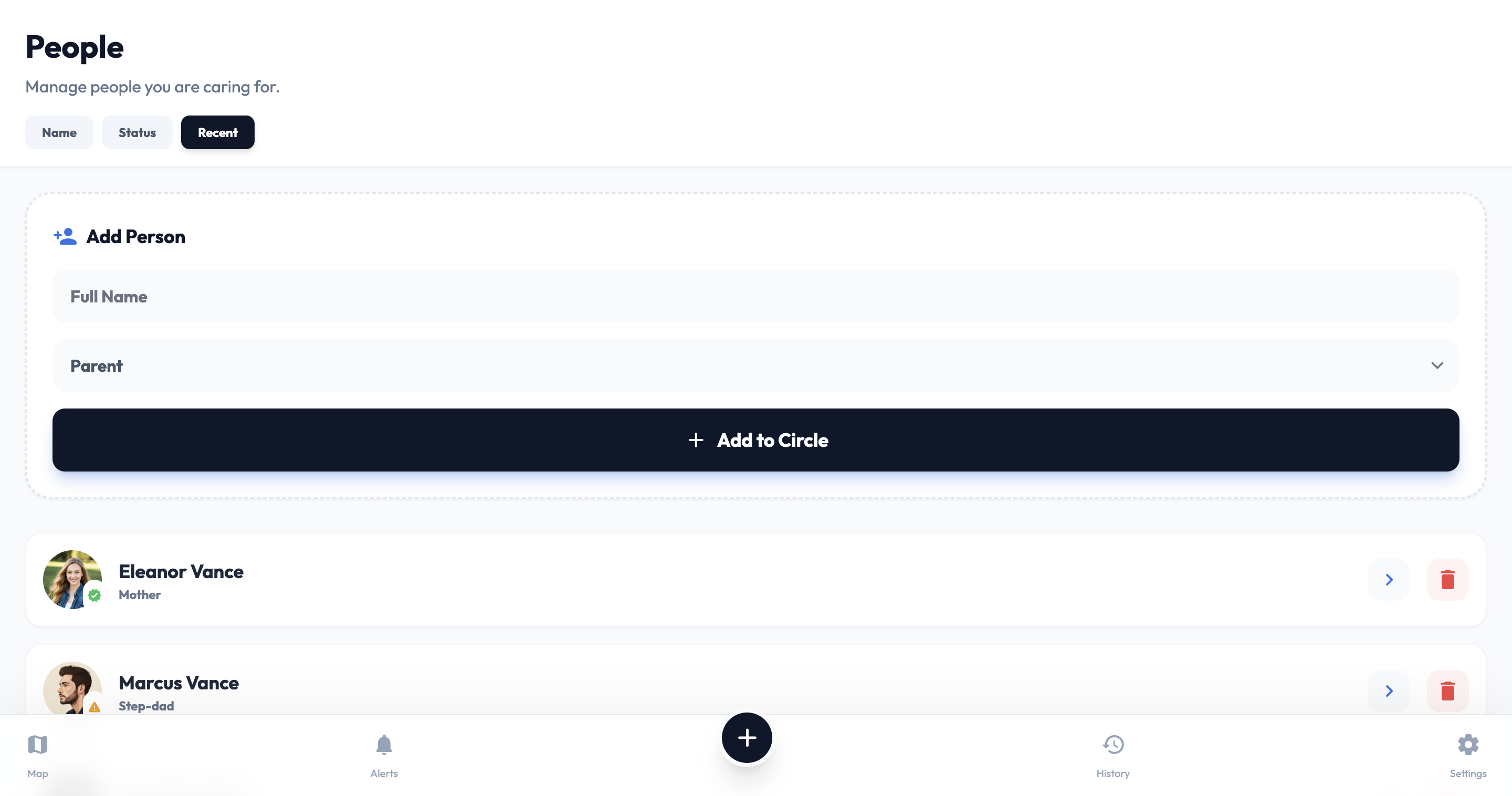
- PathGuardian 2.0 (Navigation): A voice-first navigation system that gives users independent mobility while providing caregivers with a live map.
- SignMeUp (Sign Language Interpreter): A local, privacy-centric gesture recognition engine where users can teach the system their own specific signs.
How we built it
Building a cohesive ecosystem out of three distinct interaction models required a robust, highly optimized stack, particularly because we prioritized running heavy ML workloads entirely on the edge (in-browser) to protect user privacy.
Frontend & User Interface
- We utilized React 19 and Vite 7 with TailwindCSS 4 to implement a high-contrast Glassmorphism design language. We strictly enforced accessibility standards, using a minimum touch target of 64px and integrating Lucide React icons.
The Multimodal AI Pipeline
- Conversational Engine: We utilized the Google Gemini (GenAI SDK) to give Aurora conversational memory.
- Computer Vision: We leveraged Google MediaPipe Tasks Vision and deployed TFLite running the EfficientDet Lite0 model.
- Gesture Recognition: We utilized ONNX Runtime Web and built a custom sequence-modeling engine using an LSTM network.
Orchestration & Infrastructure:
- To manage the monorepo, we built a custom manage.js script to coordinate the services concurrently.
Mathematical Modeling for Multimodal Fusion
- To prevent false positives, we engineered a dynamic Multimodal Confidence Scoring algorithm. The system calculates a weighted probability of a critical event E at time t by fusing the probability scores from Vision P(V), Audio P(A), and Gestures P(G).
- The event is triggered only if the sum exceeds a dynamic threshold:$$E(t) = \begin{cases} 1, & \text{if } \alpha \cdot P(V)_t + \beta \cdot P(A)_t + \gamma \cdot P(G)_t \geq \tau \ 0, & \text{otherwise} \end{cases}$$Because environmental reliability changes, our weights (alpha, beta, gamma) are dynamically adjusted in real-time.
Challenges we ran into
- Browser Memory Bottlenecks: Running MediaPipe, TFLite, and ONNX models simultaneously in the browser caused massive memory leaks. We solved this by implementing aggressive frame-dropping and memory-garbage-collection cycles.
- State Synchronization: Keeping the React frontend, Next.js backend, and Node routing perfectly in sync required complex state management across different ports.
Accomplishments that we're proud of
- 100% Local Inference for Vision: We successfully engineered the platform so that zero video data is ever sent to the cloud.
- True Multimodality: We broke the silo of single-mode assistive tech. A user can seamlessly start a command with their voice, confirm it with a gesture, and have the system monitor their safety visually.
- Custom Gesture Training: Giving users the ability to teach the AI their specific signs democratizes the technology.
What we learned
- We learned that building for accessibility is not about adding features to an existing app; it's an architectural mindset.
- We also learned that LLMs like Gemini become infinitely more powerful when you give them "eyes" through edge-vision data, transforming them from chatbots into proactive, context-aware companions.
What's next for UnifierBBinary
- Wearable Telemetry: Integrating smartwatch data (heart rate, gyroscope) into our Multimodal Fusion algorithm.
- Local LLM Deployment: Transitioning Aurora from cloud-based APIs to WebGPU-accelerated local models (like Gemma 4B) for full offline functionality.
- Pilot Testing: Partnering with local assisted-living facilities to field-test PathGuardian 2.0.
Built With
- asl
- bsl
- gemini
- google-web-speech-api
- googleaistudio
- googlegenai
- googlemediapipe
- html
- javascript
- leaflet.js
- lexend
- lucide-react
- next.js
- node.js
- numpy
- onnx
- opencv-python
- python
- radix
- react
- snitch-ui
- tailwindcss
- tensorflow
- tflite
- typescript
- vite
- wlasl300

Log in or sign up for Devpost to join the conversation.