-
-
Training/Testing Images
-
Training/Testing Images
-
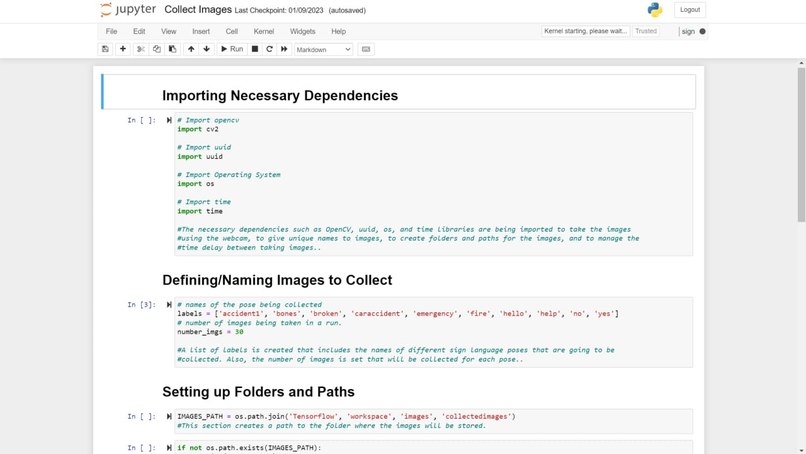
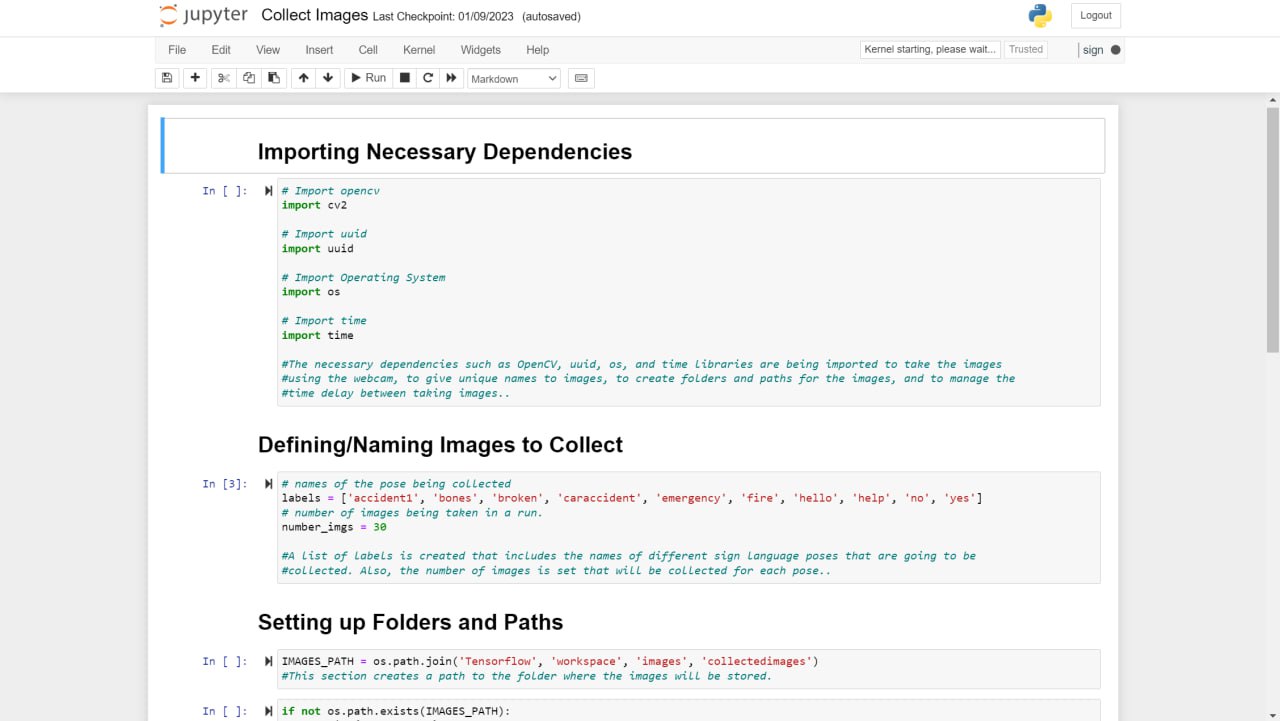
Jupyter Notebook Code
-
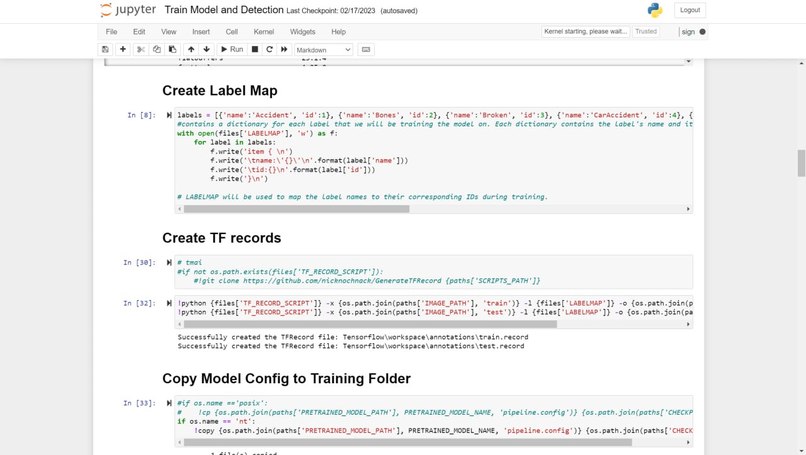
Jupyter Notebook Code
-
Jupyter Notebook Code
-
Jupyter Notebook Code
-
Jupyter Notebook Code
-
Jupyter Notebook Code

Inspiration
The inspiration behind this project was my grandparents. With their decline in health and loss of hearing, it has been harder to communicate with them about their needs. Consequently, I felt that there must be a system or software that would help combat this issue to aid those who use sign language to communicate to emergency services in cases of emergencies. It is one of my greatest fears that my grandparents cannot communicate their needs to emergency services and I want to help find a solution to combat this for all families and individuals who use sign language. Access to emergency services can affect an individual's sense of security. The inability to communicate effectively in emergencies is a harsh reality for the deaf and hard-of-hearing community. Access to sign language interpreters and communication accommodations for individuals who are deaf can vary depending on the location. In some places, emergency services may have trained staff who can communicate using sign language. However, "even within countries, access and experiences [regarding emergency services] differ across regions" (Foltz), and these resources may be limited or not available, particularly in lesser-developed areas. Deaf members have substantially lower accessibility to emergency services than the general population, with 77% of deaf patients reporting difficulties communicating with staff and 30% of these patients avoiding seeing their family doctor because of miscommunication (Foltz). The inaccessibility and hesitance to receive help from medical professionals lower feelings of security and standard of living. Clear communication is necessary to ensure the correct treatment or services are timely. Without access to sign language interpreters or communication accommodations, individuals who are deaf may not be able to understand instructions or communicate their needs, which can lead to delayed or inadequate medical attention, resulting in serious health consequences and even death.
What it does
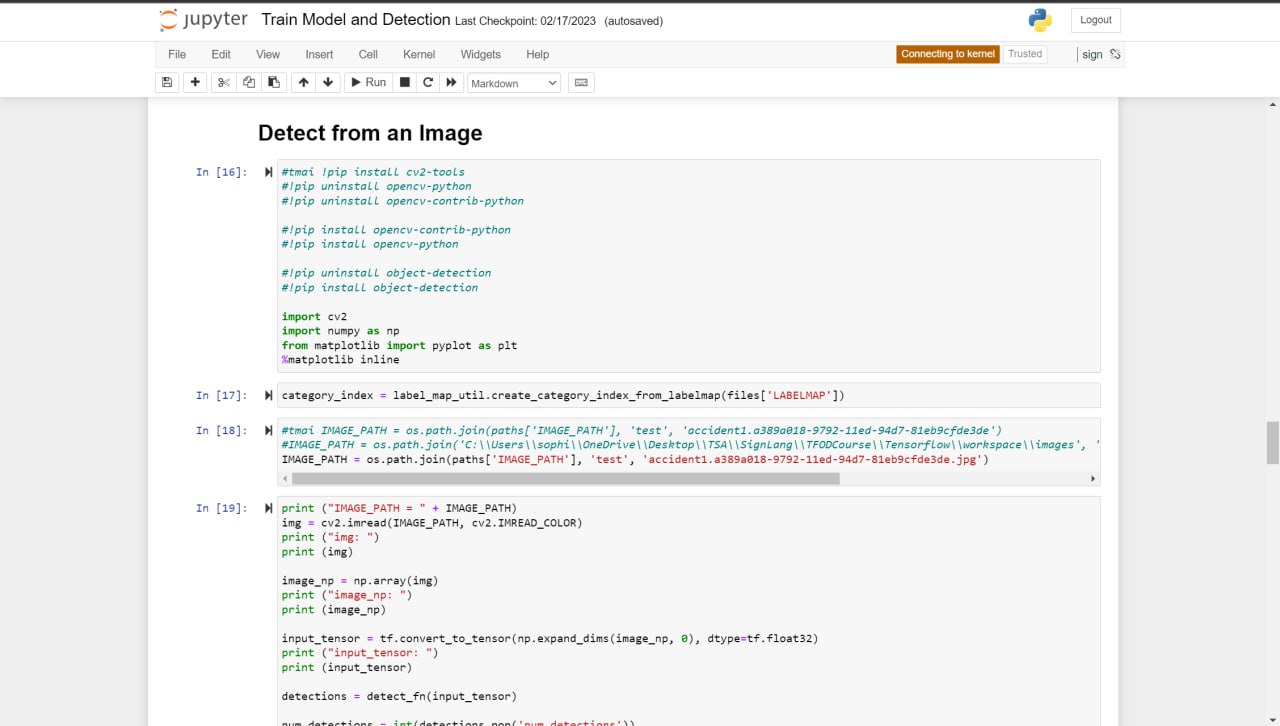
My software consists of some of the most common signs that would need to be used in emergencies. I created a sign language detection model that utilizes machine learning and computer vision using TensorFlow, an open-source software library for machine learning and artificial intelligence, Jupyter Notebook, an open-source web application that allows people to integrate live code and be used for visualizations of data, Protocol Buffers, a free and open-source cross-platform data format used to serialize structured data, Anaconda, a distribution of Python used to organize data, machine learning applications, and large-scale data processing, and LabelImg, an image annotation tool that allows the creation of bounding boxes around objects in each image and automatically saves the XML files of labeled images.
How we built it
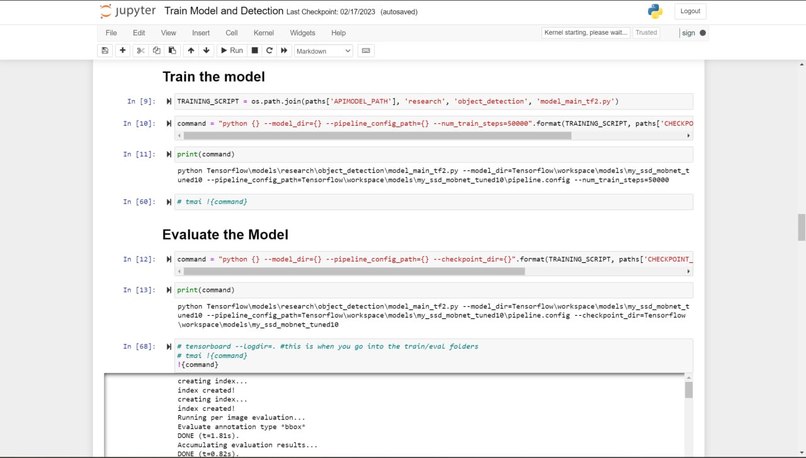
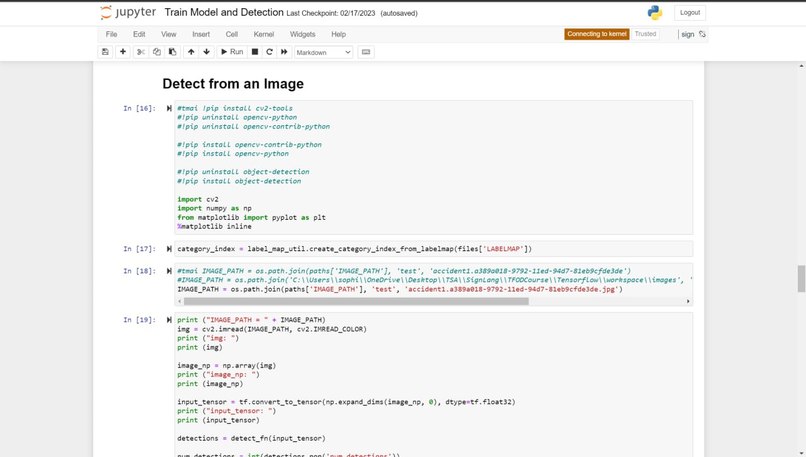
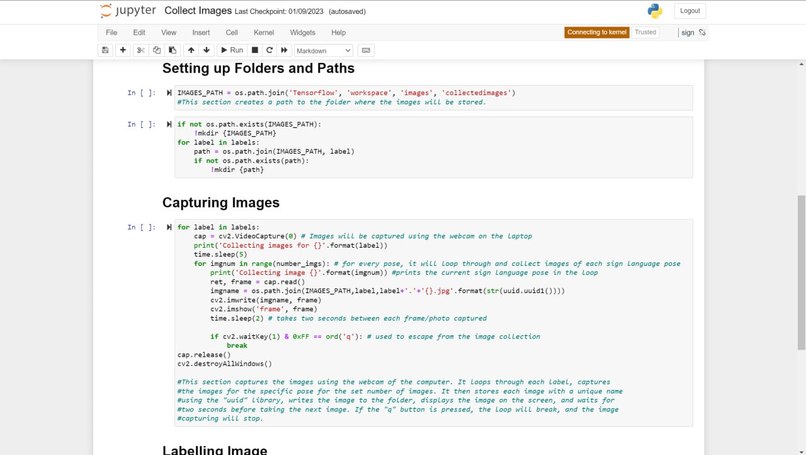
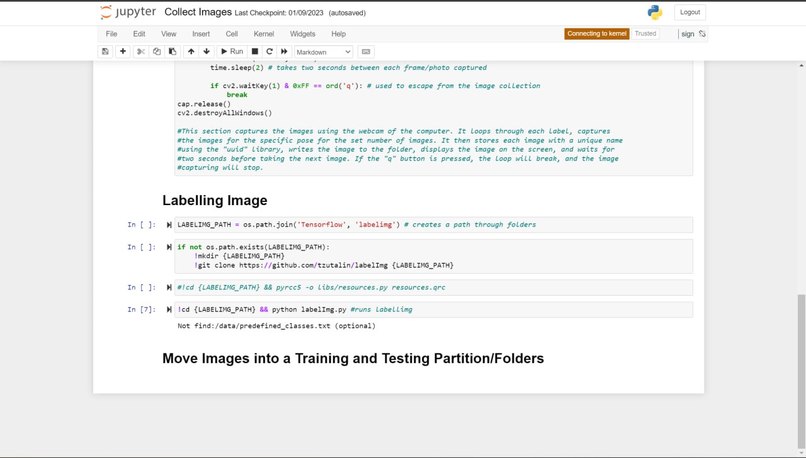
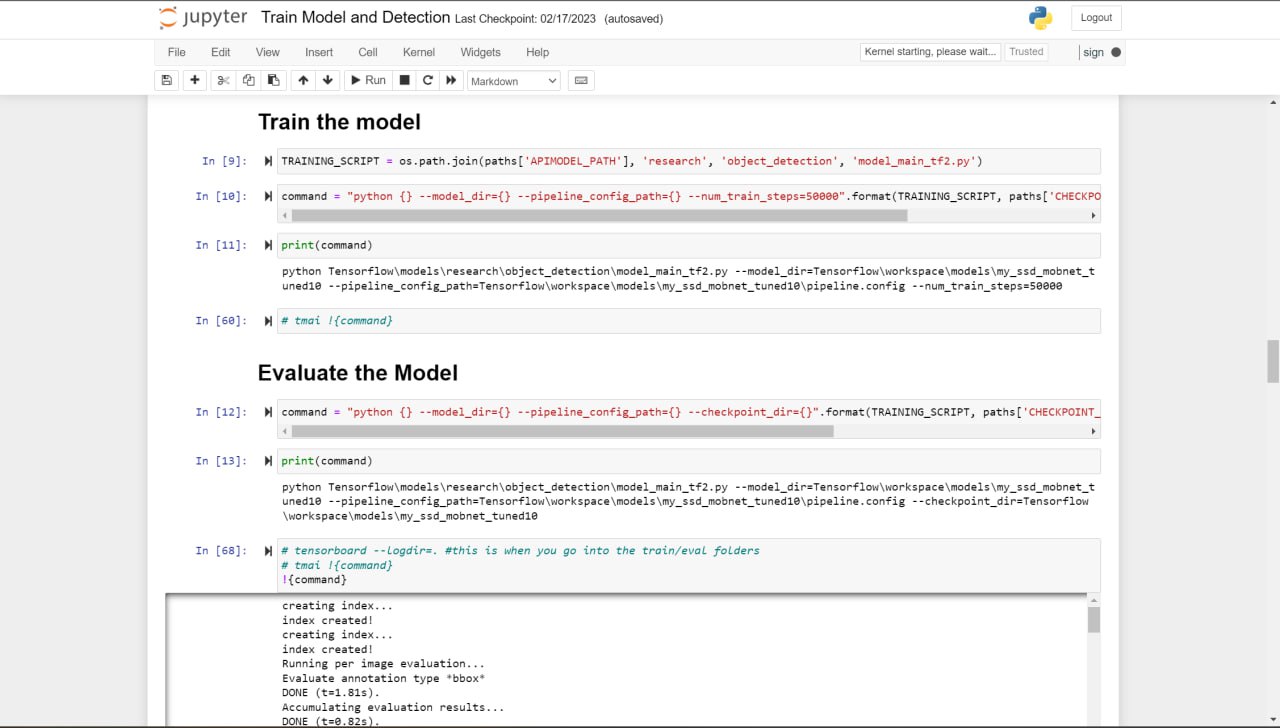
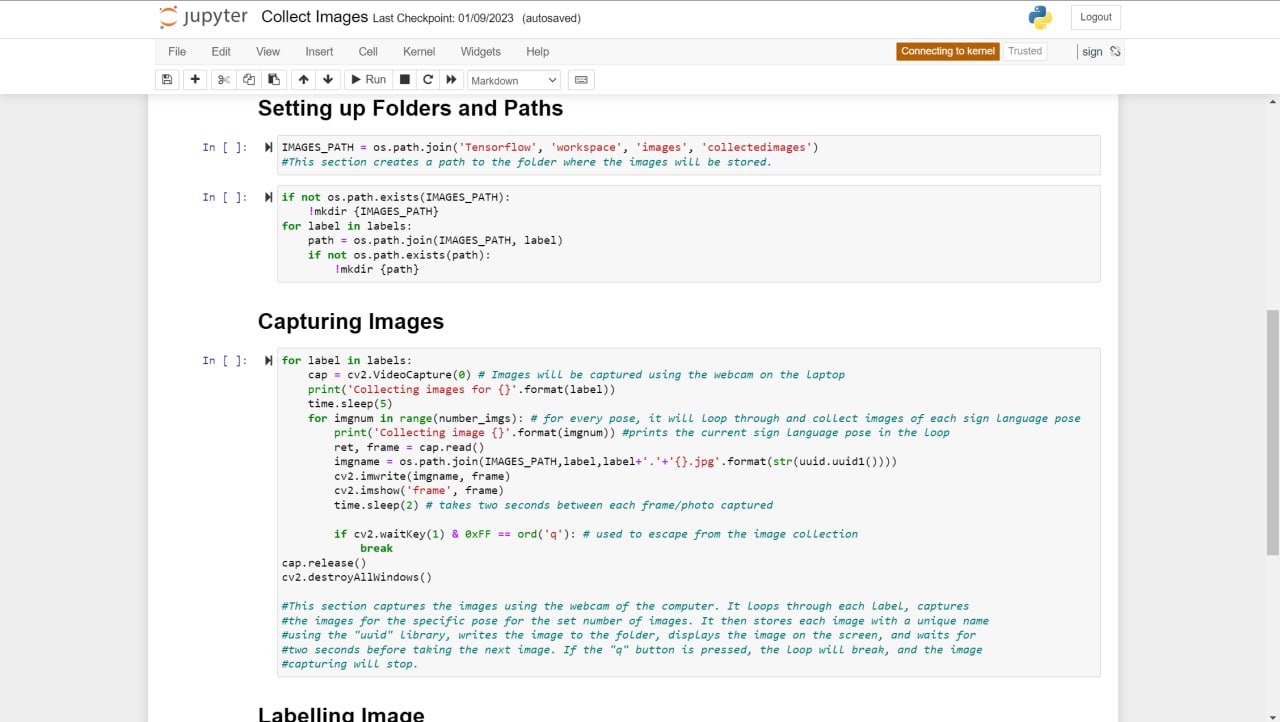
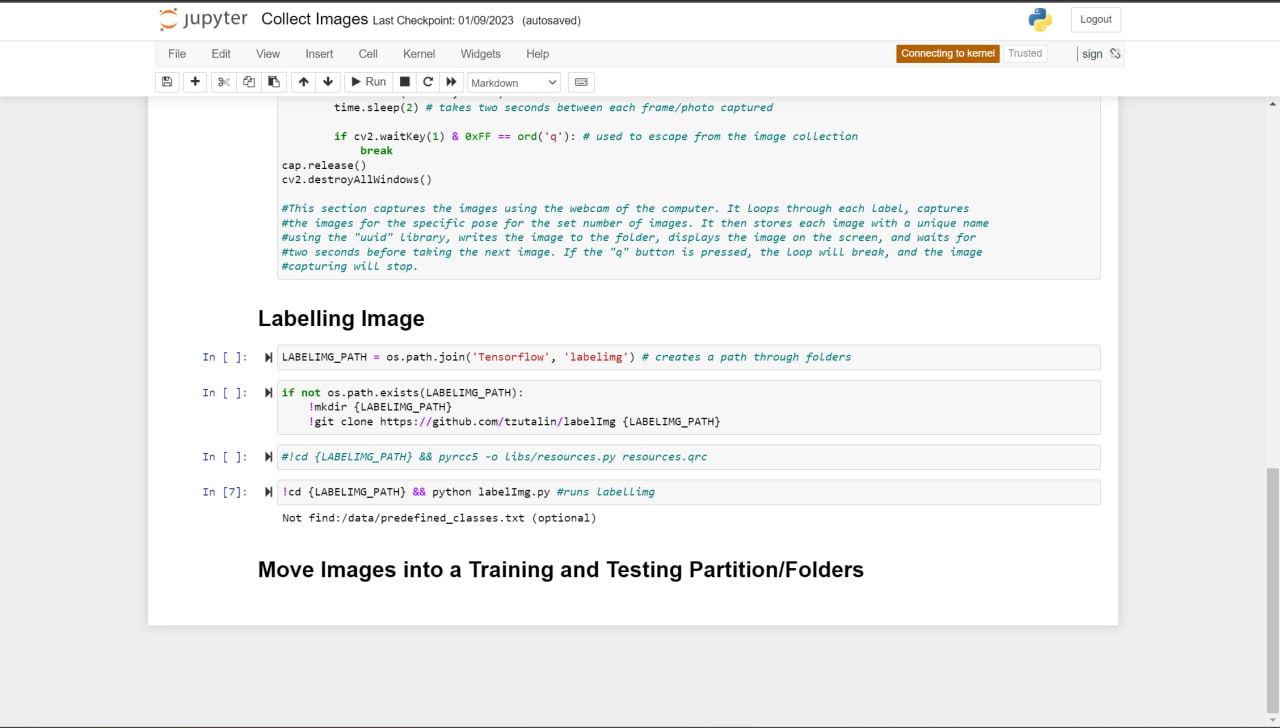
The current system and design for the sign language detection software utilize a web camera. Inputs from the camera and use of the trained sign language model will detect a sign from Accident, Bones, Broken, CarAccident, Emergency, Fire, Hello, Help, No, and Yes. Outputs and detections are shown on the webcam display. The training of the sign language detection model began with importing and downloading necessary dependencies, such as Jupyter Notebook (an open-source web application that allows people to integrate live code and be used for visualizations of data), Protocol Buffers (data serializing protocol which helped with the creation of an XML file and metadata such as the bounding boxes of poses on images), Tensorflow (open-source software library for machine learning and artificial intelligence), Tensorboard (providing the visualizations and graphs for machine learning), and Anaconda (a distribution of Python used to organize data, machine learning applications, and large scale data processing). Using a Jupyter Notebook, a list of labels is created and includes the names of different sign language poses that are collected. Paths to the folder and storage of images are made. Images are collected using the webcam and images are stored with a unique identifier using the "uuid" library. Images are then labeled using LabelImg (an image annotation tool that allows the creation of bounding boxes around objects in each image and automatically saves the XML files of labeled images). Once images and corresponding annotations were created, the images and annotations were placed in training and testing partitions with the majority of the images going into training folders (75-80% of images) and the remaining images toward testing. Training and detection of models began with setting paths. A label map (label_map.pbtxt which is a simple text file that links labels given to each sign language pose to an integer value) is then created and is used by the TensorFlow Object Detection API for training and detection. A model architecture is then chosen from the Tensorflow Model Zoo. Depending on the model, the pre-trained models differ in their accuracy and speed of detection. Certain models may prioritize accuracy over the speed of object detection. The pre-trained model used for the sign language detection uses SSD MobileNet V2 FPNLite 320x320. The speed for detection is faster than many of the models but less accurate. The pre-trained model is then copied into the training folder. The training script and command are then processed into the command prompt. Training a machine learning model involves finding the right balance between underfitting and overfitting. Overfitting occurs when the model is trained for too many steps, causing it to become too specialized to the training data and not generalize well to new data. On the other hand, underfitting occurs when the model is not trained enough, resulting in poor performance on both the training and new data. In the case of not training the model for enough steps, the model will not have enough time to learn the underlying patterns and relationships in the data. This can result in poor performance, such as inaccurate predictions. To find the right balance, it is often necessary to monitor the performance of the model on a validation set during the training process. This can help determine whether the model is overfitting or underfitting and whether more training is necessary. Additionally, techniques such as early stopping can be used to prevent the model from being trained for too many steps and overfitting the data. The model is then tested using Tensorflow and object detection.
Challenges we ran into
Getting the packages to work together was a struggle. Some aspects of my code required newer packages while some were depreciated, and because some packages were updated, other packages had older files that were no longer compatible with the newer packages. This was by far the most challenging part of creating the machine learning model because so many packages were needed and as a result, I needed to find a version of each package that would not result in any errors or conflicts with each other. Creating virtual environments in the Command Prompt was something I discovered later on which would allow me to tweak the package versions without damaging the current packages that are installed on my computer.
Accomplishments that we're proud of
One of the significant accomplishments of this project is the development of a sign language detection model using machine learning and computer vision. Creating a machine learning model that can detect and interpret sign language poses is a complex task that requires a deep understanding of both the underlying technology and the sign language itself. By successfully building and training the model, the team has made significant progress toward bridging the communication gap between emergency services and individuals who use sign language. This accomplishment has the potential to improve the safety and well-being of the deaf and hard-of-hearing community during emergencies.
What we learned
Throughout the project, I gained valuable insights and knowledge in several areas. Firstly, I learned about the challenges and barriers faced by individuals who use sign language to communicate, particularly in emergency situations. This understanding helped guide the development process and shape the goals and objectives of the project.
I also gained expertise in machine learning and computer vision techniques. Building and training a sign language detection model required a deep understanding of these technologies, including the use of TensorFlow, image annotation tools like LabelImg, and the process of training and evaluating machine learning models. This experience in machine learning will likely prove beneficial in future projects and applications.
What's next for SignLink
What's next is getting the machine learning project to detect all signs and getting a type of translation from English to sign language. ASL (American Sign Language) is the “primary language for deaf and hard of hearing people to communicate” with their family, teachers, and friends (Arena). Though most deaf and hard-hearing people know ASL, not many people outside of the disability sector are familiar with this language creating a gap in communication with many people, through the development of a sign language model, there would be a significant step made towards addressing the communication gap between first responders and the deaf and hard-of-hearing community during emergencies. A machine learning model that utilizes computer vision can be used to detect sign language, improve response times, and ensure that those who communicate primarily through sign language have equal access to emergency services. By providing real-time text translations of emergency signs, first responders can quickly understand and respond to the situation, reducing the risk of miscommunication and delay that would have been faced. By gathering diverse sign language data and training an AI model on them, it could be possible to extend sign language detection to other sign language families worldwide, such as British or French Sign Language. Consequently, it will enable people to recognize and comprehend different sign languages at a global level. Translation services that cover both spoken and written languages can expand the reach of translation services beyond sign language, enabling translation between any sign language group and any spoken or written language, such as French Sign Language to Vietnamese. Additionally, through the implementation of a customizable interface, those with visual impairments or other disabilities can be accommodated. Features like adjustable font sizes, customizable user interfaces, or compatibility with assistive technologies can further the scope of this technology to support all sign language users. The model also has the potential to facilitate communication in other settings, such as medical appointments or public safety announcements, further improving accessibility for the deaf and hard-of-hearing community. The development of this sign language model is a significant step towards addressing the communication gap between first responders and the deaf and hard-of-hearing community during emergencies.
Built With
- anaconda
- jupyter
- jupyternotebook
- protoc
- tensorflow


Log in or sign up for Devpost to join the conversation.