-
-

Landing Page
-

Waiting Room Page
-

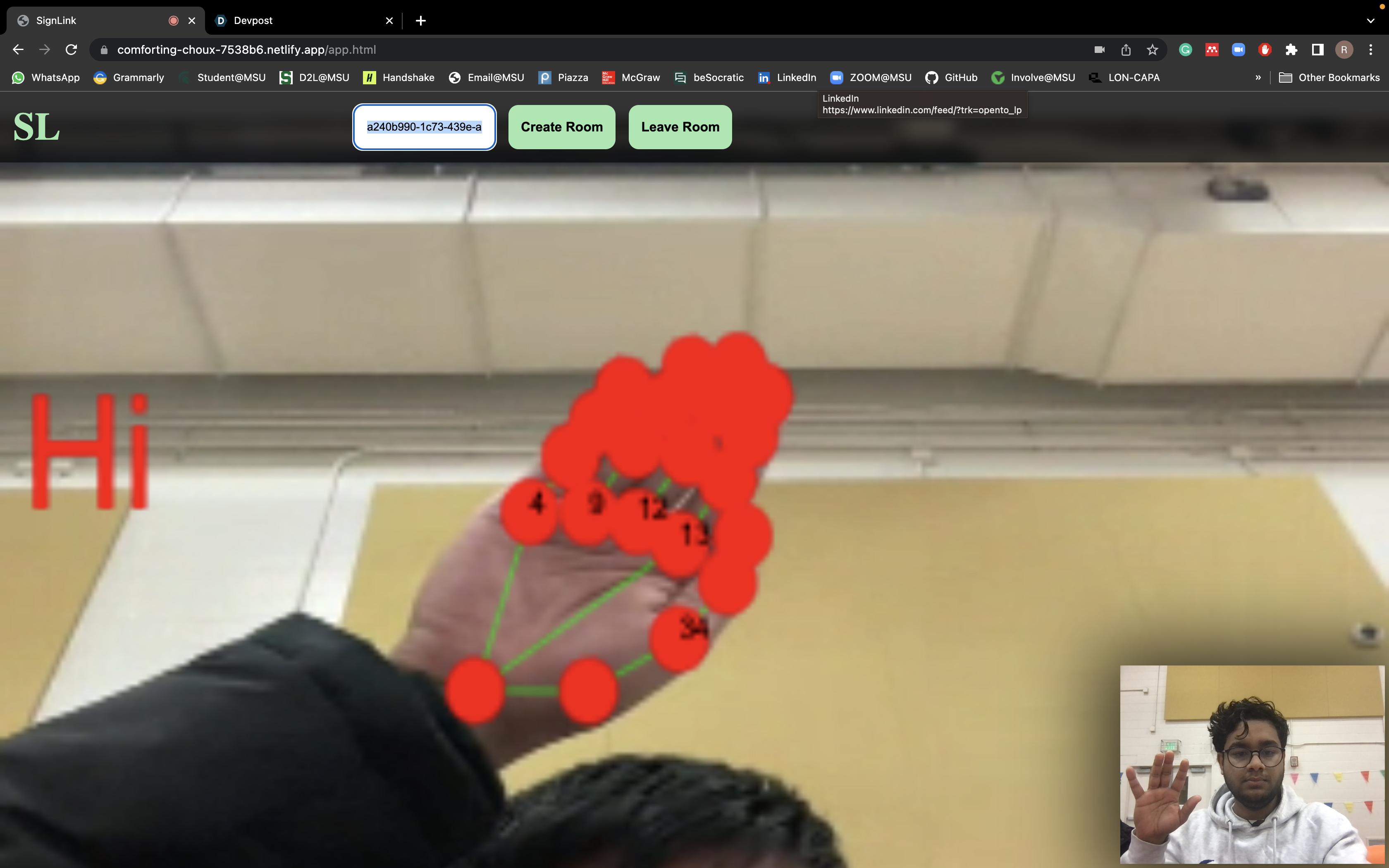
Connected on call and active ASL translation


Inspiration
We were inspired by the lack of accessibility features for the deaf/heard of hearing community to communicate with a hearing person who doesn't know ASL without an interpreter. We have a passion for technology which combines accessibility, so I decided to build this project as a way to challenge myself and expand my knowledge.
What it does
As the world becomes more diverse and inclusive, the need for effective communication with individuals who are deaf or hard of hearing is becoming increasingly important. Recognising this need, we developed our in-house video conferencing app that includes a feature to help bridge the communication gap: an American Sign Language (ASL) to text translator.
Currently, our app uses a pre-defined dictionary to translate ASL signs into text in real-time. While this feature is useful, we understand that machine learning can provide a more accurate and efficient solution. That's why we are actively researching and developing a machine learning-based ASL to text translator, which will improve the accuracy and speed of the translation process.
Our app also includes other features such as high-quality video and audio, and the ability to connect with different devices, making it perfect for everyday use.
In conclusion, our in-house video conferencing app is a powerful tool that promotes effective communication, inclusion, and accessibility for individuals who are deaf or hard of hearing. Its current ASL to text translator feature is a step towards a more accurate and efficient solution in the future, making it more inclusive and convenient for all users.
How we built it
We built our in-house video conferencing application using a combination of HTML, JavaScript, WebRTC, and CSS for the front-end and OpenCV, MediaPipes for the ASL-text feature.
To create the video conferencing platform, we used HTML and PeerJS to handle the real-time communication between users, and WebRTC for the video and audio streaming. We also used CSS to create a visually appealing and user-friendly interface.
For the ASL to text feature, we used OpenCV to capture and process the video, and MediaPipes to analyse the movement of the hand. We then used vector algebra and trigonometry to find the relative angles of all the joints, and created a database of all the ASL letters to reference in real-time.
To recognise the ASL letters, we hardcoded a language processing model using 20 nodes placed at strategic points on the hand. This allowed us to accurately recognise the ASL letters in real-time and display them on the screen for hearing users to understand.
The whole process was done in real-time to ensure seamless communication between users. Overall, the combination of these technologies allowed us to create a powerful and efficient in-house video conferencing application that promotes communication, inclusion and accessibility for individuals who are deaf or hard of hearing.
Challenges we ran into
Our initial goal for this project was to build an AI-based American Sign Language (ASL) to text converter using Tensorflow. However, we encountered several challenges that hindered our progress.
One of the major challenges was poorly documented tutorials that led to many dead ends. We spent countless hours trying to navigate through the use of various libraries, only to find that some of them were poorly coded or not compatible with our setup. To further complicate matters, one of the required modules needed a windows C++ standalone builder, which proved to be a roadblock as it was broken even through the Microsoft store. Despite our persistence, we were unable to get the AI-based converter to work, and had to abandon the idea of using Tensorflow altogether.
Another challenge we faced was the lack of support for our desired feature set in the available libraries for building a standalone video conference application. We had planned to use the Zoom SDK to create a full-blown video conference application that would output the video of the meeting participants and also broadcast the text generated by the converting application. Unfortunately, none of the libraries offered online could support this feature set, which forced us to rethink our approach and pivot the entire base of our project.
In the end, we were able to overcome these challenges by changing our approach and adopting new technologies. While it was disappointing to have to abandon our original plans, it ultimately led us to create a more innovative and effective solution.
Accomplishments that we're proud of
Developing a video conferencing app that can convert American Sign Language to English captions is no small feat, and the fact that some of the signs were successfully translated is a great indication of the hard work and dedication put in by our team. The use of technology to bridge the communication gap between individuals who use American Sign Language and those who don't is an important step towards inclusivity and accessibility. Our team was able to make this leap, especially given the complexity of hand angles recognition and translation, it's a big step forward. We are proud of what we accomplished in such a short time!
What we learned
We have acquired knowledge and skills in utilising various technologies and tools to develop a video conferencing solution that incorporates gesture recognition functionality. Specifically, We have gained proficiency in utilising PeerJs for establishing video conferencing connections, utilising MediaPipes and OpenCV for real-time editing of remote video, and utilising TensorFlow for the training and implementation of a machine learning model for gesture recognition. Furthermore, We have gained insight into the challenges that may arise during the training and implementation of machine learning models.
What's next for SignLink
Potential future developments for this concept could include the creation of a mobile application to enhance accessibility and improve the accuracy of sign language translation. The current implementation utilizes letter-to-letter translation, however, incorporating advanced machine learning techniques would allow for recognition of compounded expressions, movement, and sign language, resulting in a more effective and holistic form of communication. The inclusion of live captioning and transcription functionality would also be beneficial. Furthermore, implementing support for multiple languages would promote inclusivity and cater to a diverse range of users.



Log in or sign up for Devpost to join the conversation.