-
-
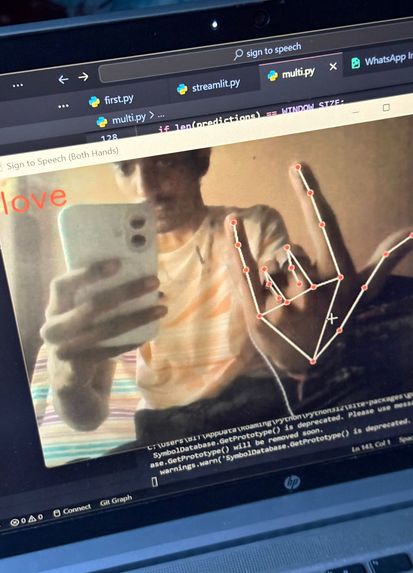
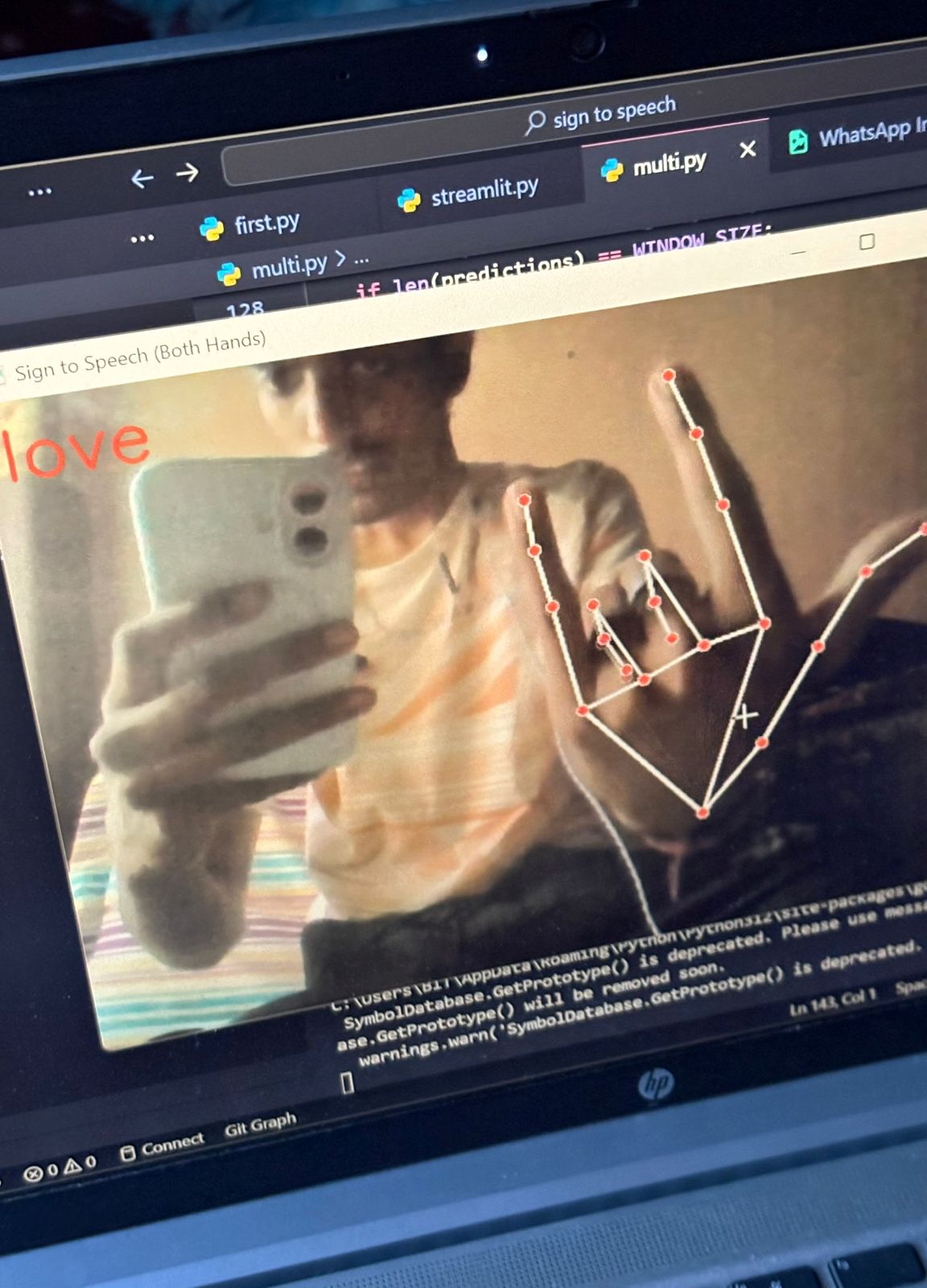
love
-
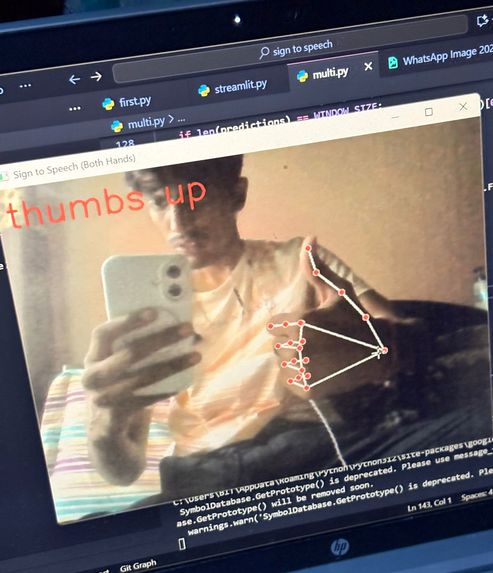
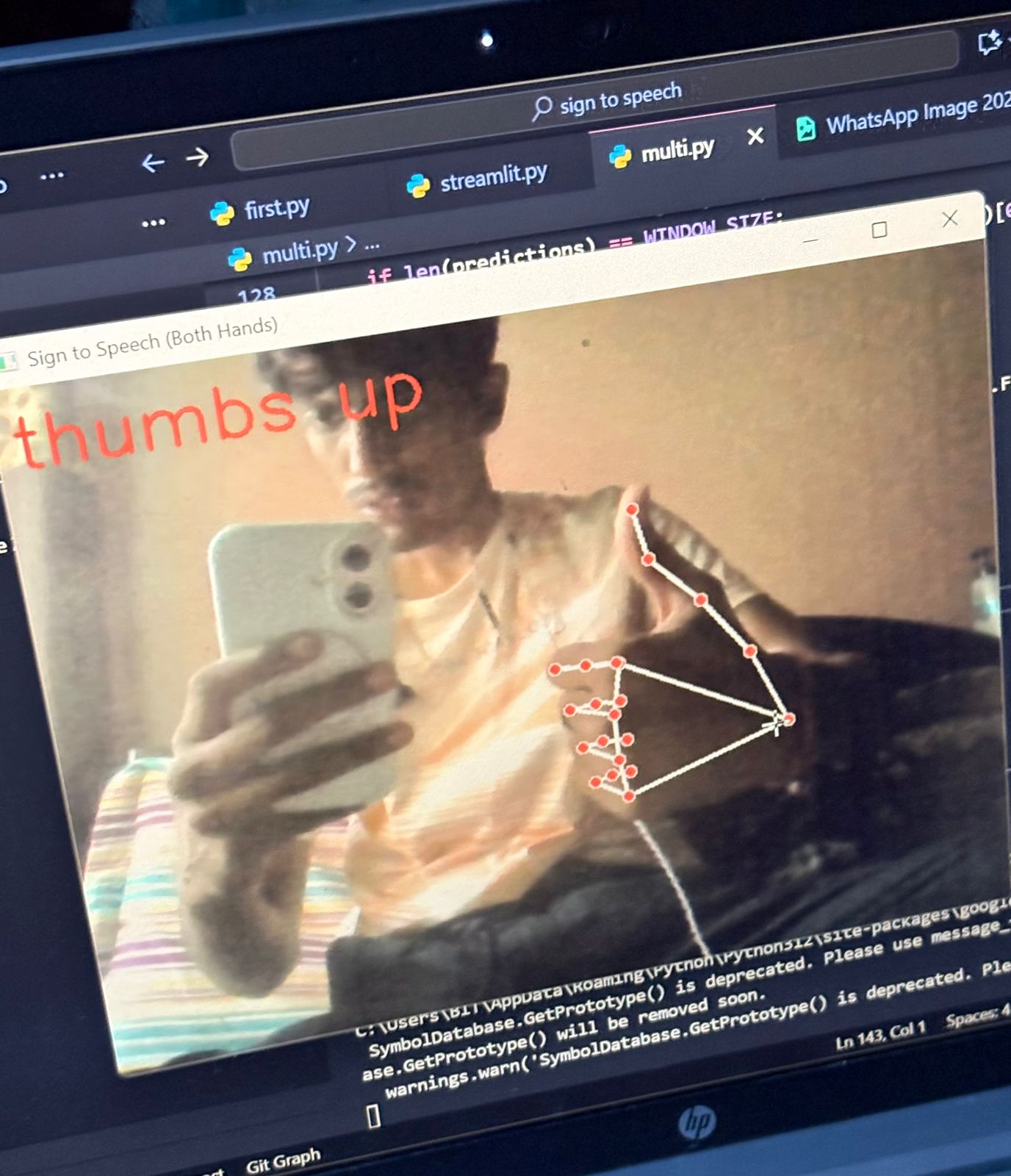
thumbs up
-
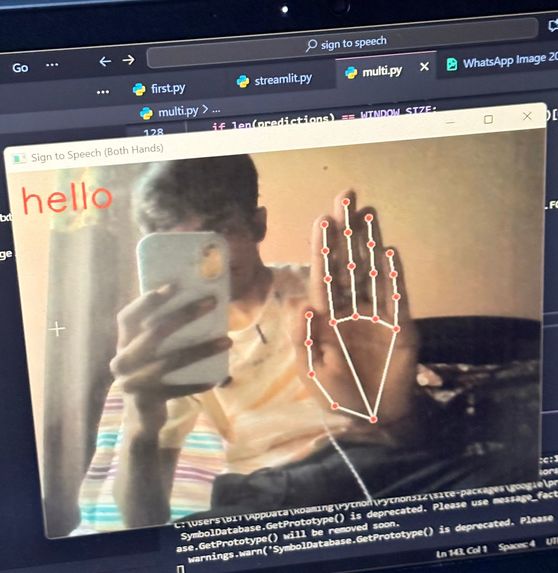
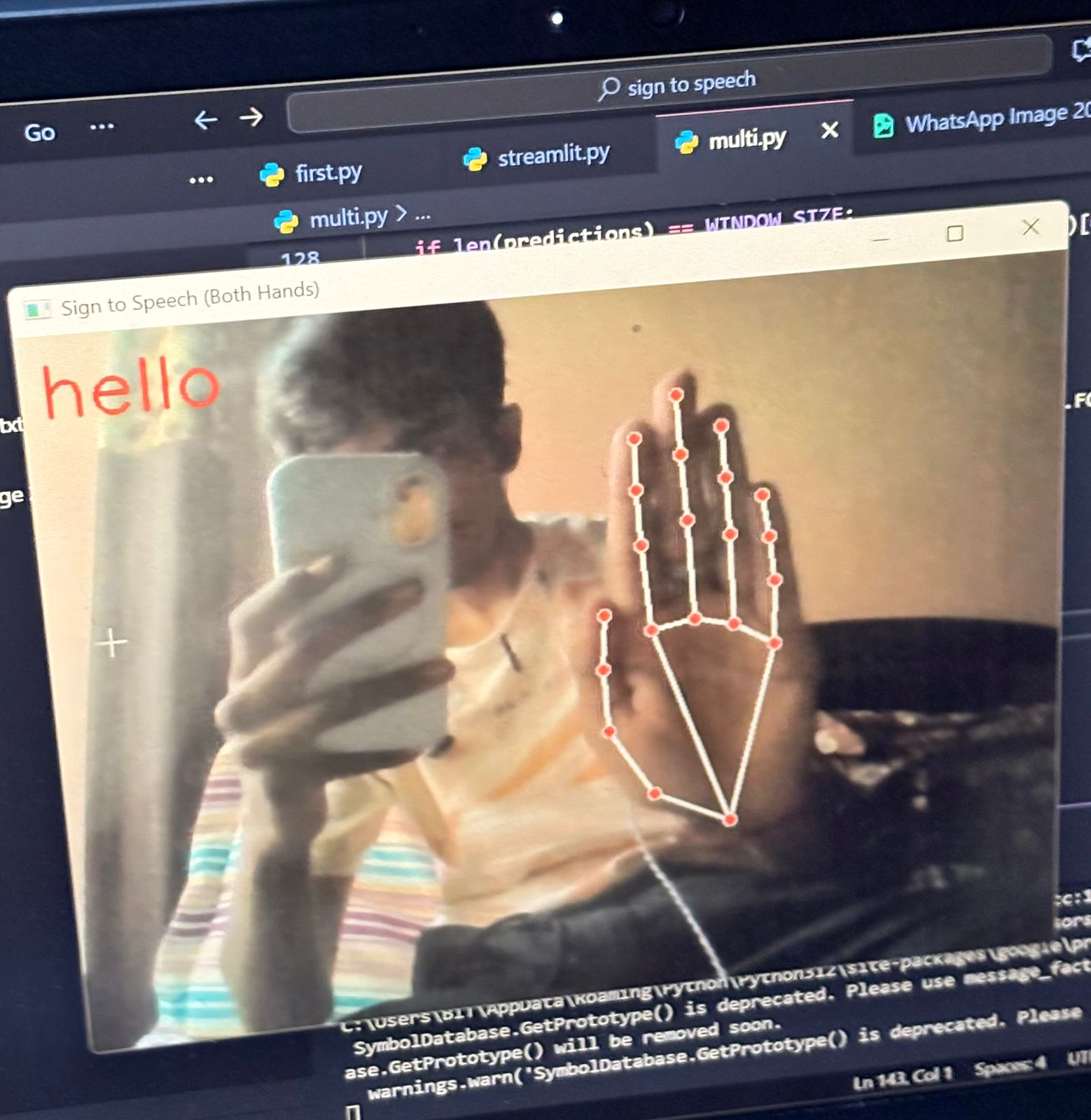
hello
-
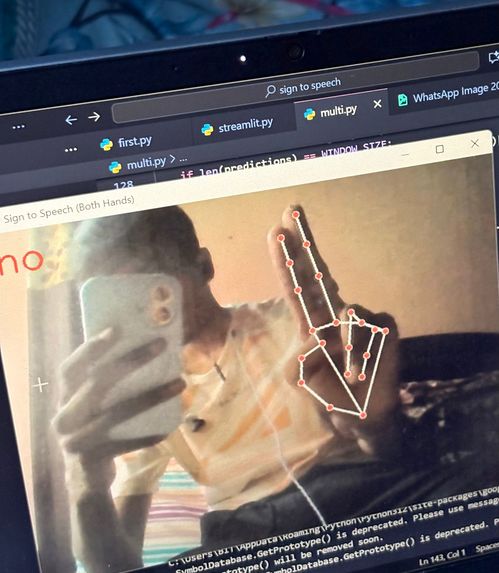
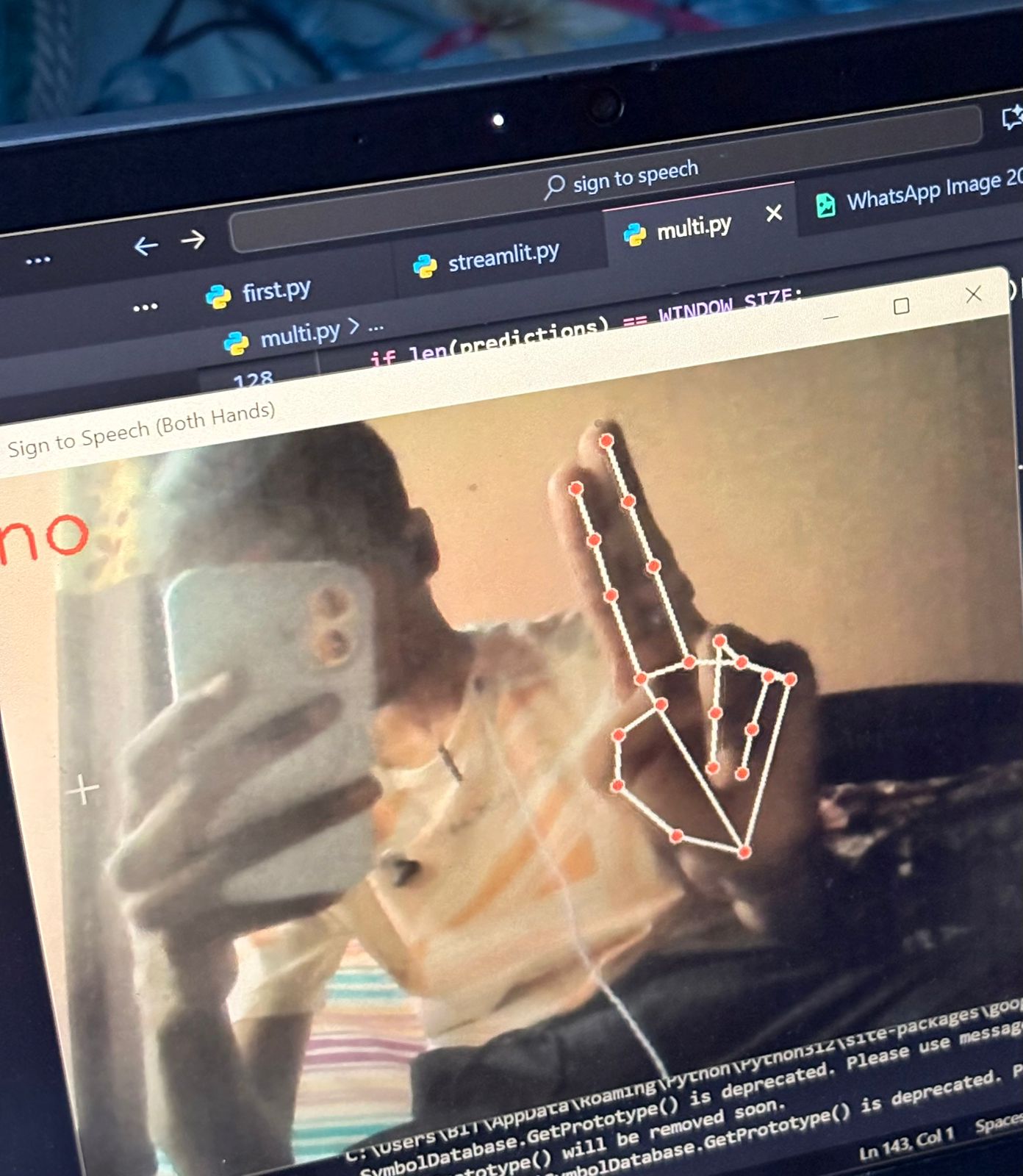
no
Inspiration
Communication is a fundamental human need, yet millions of people around the world with speech or hearing impairments face daily barriers in expressing themselves. Sign language is a powerful tool for these communities, but unfortunately, most people outside of these groups do not understand it, limiting interactions. We wanted to bridge this gap. "Signify" was inspired by the idea of making communication seamless and inclusive by using technology to translate hand signs into spoken language in real time.
What it does
Signify is an AI-powered application that recognizes hand signs and converts them into speech. Using computer vision and machine learning, the system captures hand gestures through a camera, interprets the signs using a trained model, and instantly outputs the corresponding spoken words or phrases. This allows individuals using sign language to communicate more effectively with people who do not understand sign language, making daily interactions more accessible and natural.
How we built it
We built Signify using a combination of machine learning, computer vision, and text-to-speech (TTS) technologies:
Data Collection: We used publicly available datasets of sign language images and videos, and augmented them with custom hand gestures to improve accuracy.
Model Training: A Convolutional Neural Network (CNN) was trained to classify static hand signs. We used TensorFlow/Keras for model building.
Real-time Detection: OpenCV was integrated for real-time hand gesture recognition through webcam input.
Text-to-Speech: We used libraries like pyttsx3 or Google Text-to-Speech (gTTS) to convert the predicted sign into spoken language.
User Interface: A simple, intuitive UI was built with Python (Tkinter/Streamlit) to allow users to interact with the system.
Challenges we ran into
Data Limitations: Finding high-quality, labeled datasets for various sign languages was difficult. We had to clean and augment data significantly.
Gesture Similarity: Some hand signs look very similar, leading to misclassification, especially in poor lighting or different hand orientations.
Real-time Performance: Ensuring low latency while maintaining high accuracy was a balancing act, especially on lower-spec hardware.
Generalization: Getting the model to perform well across different users with varying hand sizes, skin tones, and signing styles was a challenge.
Accomplishments that we're proud of
Successfully built a working prototype that translates hand signs into speech in real time.
Trained a custom model that can recognize a set of frequently used signs with good accuracy.
Made communication more accessible for people who rely on sign language.
Created a simple yet effective UI that can be used by individuals without technical backgrounds.
What we learned
Hands-on experience with computer vision, CNNs, and real-time model deployment.
Importance of data quality and preprocessing in machine learning projects.
Challenges of accessibility and the potential of AI to solve real-world communication problems.
Learned how to balance model complexity and performance for real-time applications.
What's next for Signify
Expand Vocabulary: Train the model on a wider set of dynamic and static signs, possibly incorporating full American Sign Language (ASL) or other regional variants.
Dynamic Gestures: Implement models that can recognize motion-based (dynamic) gestures using video sequences and LSTM/CNN hybrids.
Multilingual Support: Enable speech output in multiple languages for global accessibility.
Mobile App: Develop a mobile version for Android/iOS to make Signify accessible anywhere.
Community Input: Collaborate with the deaf and hard-of-hearing community to improve and refine the system based on real feedback.












Log in or sign up for Devpost to join the conversation.