-
-
Landing page
-
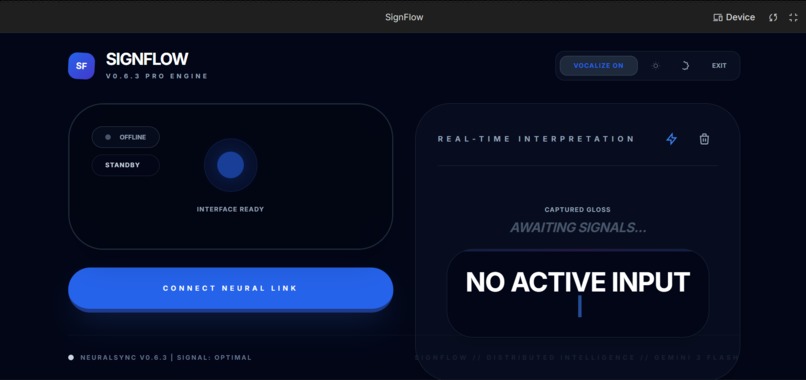
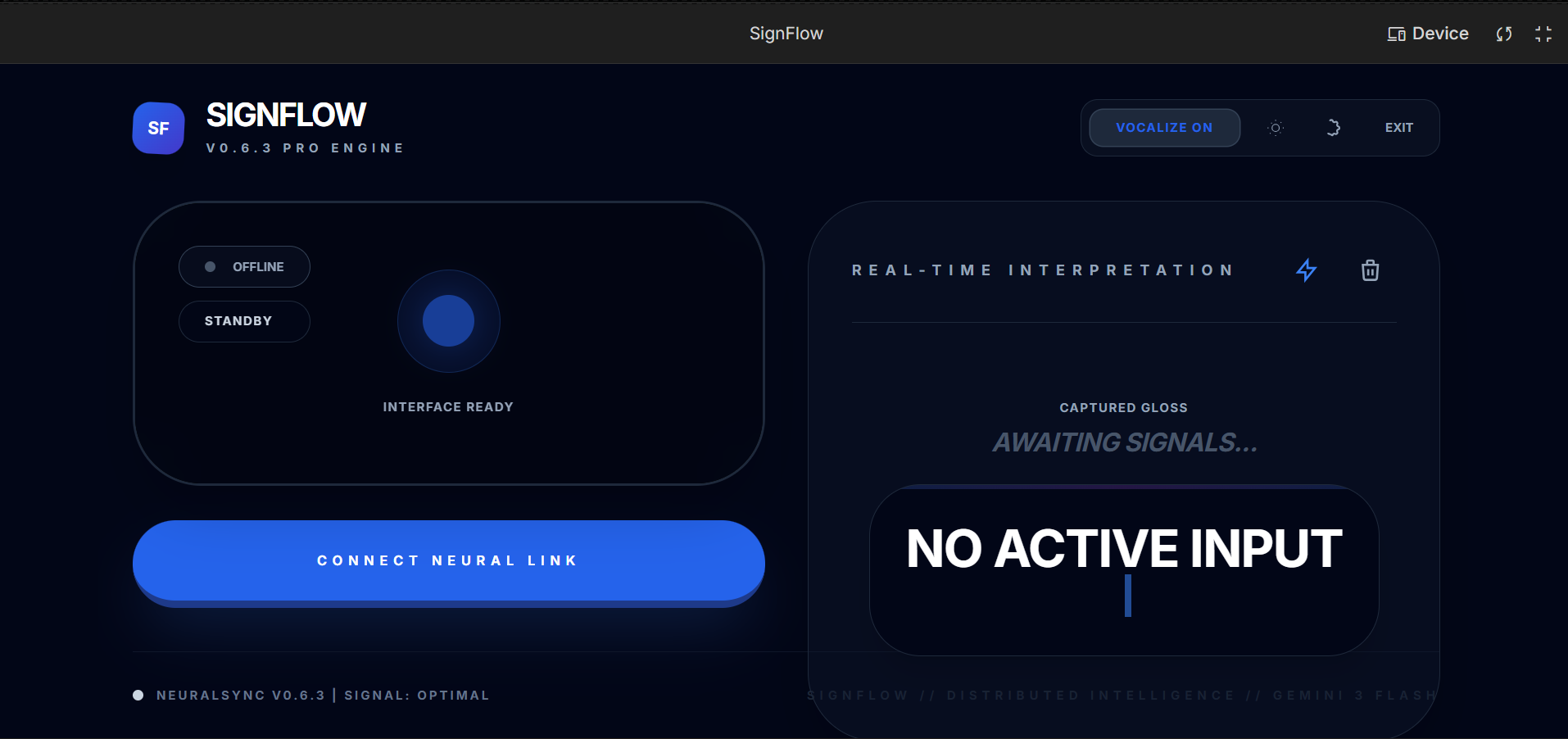
Sign Translation interface
Inspiration
Communication is a fundamental human right, yet millions of individuals face daily friction in environments not equipped for sign language. Imagine being unable to host a Deaf speaker at your event because an interpreter wasn't available, or missing out on the rich culture of all-Deaf gatherings due to the communication barrier. I was inspired by the idea of "Ambient Accessibility"—the vision of a world where technology facilitates basic human connection without the need for bulky hardware or expensive human interpreters. Seeing the speed of Gemini 3 Flash, I realized we finally had the "neural throughput" necessary to process video frames fast enough to mimic the natural flow of a real conversation.
What it does
SignFlow is a real-time, browser-based ASL interpreter. It uses a standard webcam to "watch" a user sign and instantly converts those gestures into text. To ensure the communication flows both ways, it then synthesizes that text into natural-sounding speech. It features a high-performance dashboard with a real-time interpretation log, a "Neural Link" status monitor, and native voice output, making it possible for a Deaf individual to "speak" to anyone, anywhere, instantly.
How we built it
SignFlow is architected as a high-performance React application with a specialized multimodal pipeline:
- Vision Engine: We utilize gemini-3-flash-preview to process visual tokens. We capture frames at a specific interval and stream them to Gemini's vision encoder to identify ASL gestures.
- Mathematical Interpretation: The model performs a zero-shot classification to find the most probable sign from the visual frame:
- Voice Synthesis: For the "Flow" in SignFlow, we utilized gemini-2.5-flash-preview-tts. This allows us to generate raw PCM audio data directly from the interpreted text, providing a human-like voice to the signs.
- Frontend Architecture: Styled with Tailwind CSS, the app uses a "Cyber-Minimalist" aesthetic, prioritizing high-contrast accessibility and dark-mode comfort.
Challenges we ran into
The primary challenge was managing Neural Saturation (Rate Limiting). Interpreting live video generates a high volume of requests. Initially, the app would trigger 429 errors within seconds. I implemented a dynamic polling and cooldown mechanism. If the request density reaches the quota limit
The system enters a "Cooldown" state for seconds, allowing the API bucket to refill and ensuring the application remains stable for the user.
Accomplishments that we're proud of
I am incredibly proud of achieving Ambient Latency. By leveraging the Flash series of models, the response time is fast enough that it feels like the AI is "listening" rather than "calculating." Seeing the system correctly interpret complex signs and immediately speak them aloud—turning a visual gesture into a physical sound wave—was a major milestone in proving the viability of this technology.
What we learned
Building SignFlow taught me that Multimodal Prompting is as much about spatial engineering as it is about language. I learned how to optimize image payloads to reduce token weight while maintaining the clarity needed for finger-spelling. I also gained deep experience in low-level web audio, specifically transforming base64 neural outputs into playable AudioBuffer objects using raw PCM decoding.
What's next for SignFlow
The current version of SignFlow is highly effective at word-level interpretation. The next evolution is Continuous Sentence Reasoning—using Gemini’s long-context window to understand the unique grammar and syntax of ASL, which differs significantly from spoken English. I also plan to integrate Veo to create a "Sign-to-Sign" mode, where a digital avatar can sign back to the user, creating a truly inclusive, bilingual AI conversation partner.
Built With
- canvas-api
- firebase
- gemini
- gemini-3-flash-preview
- react
- tailwind
- typescript

Log in or sign up for Devpost to join the conversation.