-
-
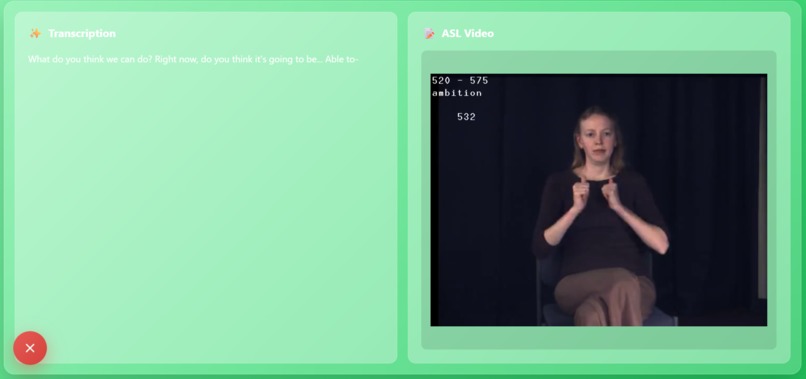
Frontend interface
-
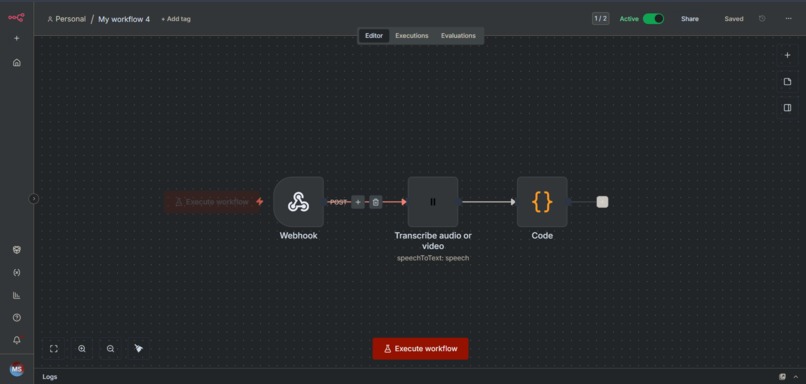
n8n Voice Transcription Workflow
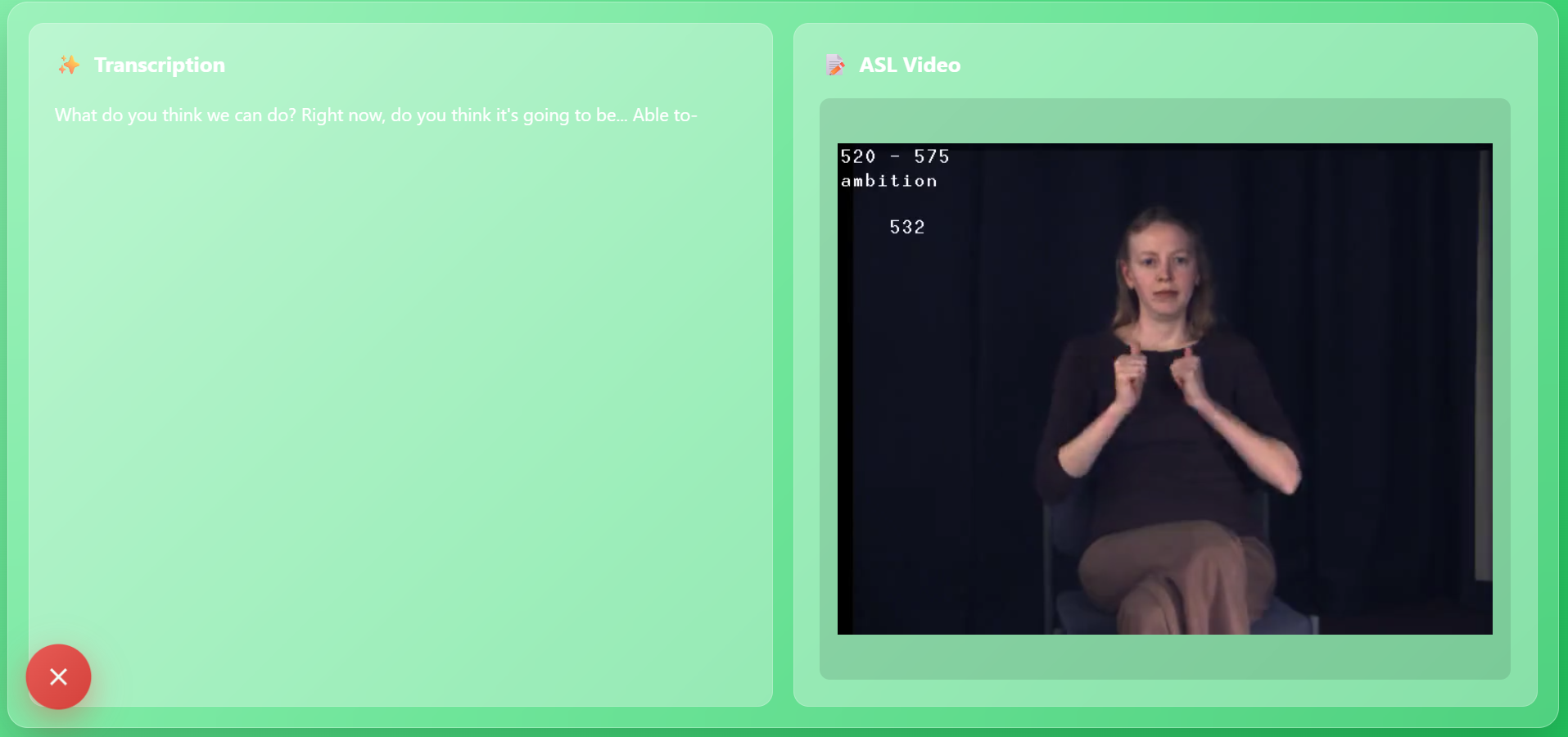
Inspiration
We built SignFlow because we realized that many deaf people still struggle to understand spoken communication in public places. Announcements at airports, instructions on public transport, and speeches at events are often not accessible to them. This inspired us to create a tool that helps deaf people instantly understand what someone is saying through ASL. We wanted to support better inclusion, improve access to information, and help deaf individuals feel more confident and independent in daily activities.
What it does
SignFlow is a real-time speech-to-ASL translation system built on Vercel. The user clicks a microphone button on the website to start recording. The audio is immediately sent to an n8n webhook, which uses the ElevenLabs transcription API to convert the voice into text within split seconds.
The text appears on the left side of the webpage, while the ASL animation video appears on the right side. Both update in real time so that deaf users can read the text and watch the ASL output at the same time.
How we built it
We built the frontend using plain html . The microphone records audio and sends small chunks to n8n. Inside n8n, we set up a webhook that receives the audio and passes it to the ElevenLabs transcription service via the ElevenLabs API.
The backend first prepares the dataset by downloading individual ASL videos for each word along with their gloss. Each gloss is labeled and stored in MongoDB with its corresponding video ID. When text is transcribed, Groq is used to infer the gloss, which is then queried against MongoDB to retrieve the correct set of video IDs. Finally, Python merges these videos in the proper sequence to generate the complete ASL video.
The transcription result is returned to the website and displayed instantly.
Challenges we ran into
The biggest challenge was generating ASL videos. There is currently no simple API that can create full ASL avatar videos with correct hand movements and facial expressions. ASL depends heavily on facial expressions, so using normal avatar tools was not enough.
We also found a dataset with more than thirteen thousand ASL videos, but downloading and preparing them took a lot of time. Another challenge was connecting all parts of the system, such as real-time audio recording, the webhook, fast ElevenLabs transcription, and displaying the results on the webpage simultaneously without delays.
Time is also a big challenge as we couldn't figure out a way to connect the python backend to the html frontend in time.
Accomplishments that we are proud of
We are happy that we built a working system that captures voice, transcribes it in real time, and shows both text and ASL output together. Even though the ASL video is not perfect, we are proud that the idea works and can already help demonstrate how real-time ASL translation can look.
We also succeeded in building a clean and simple interface. This project helped us show something meaningful that can support accessibility.
What we learned
I personally learned how the frontend and backend communicate with each other and how audio moves through the system. I also learned how to use React, Vite, and how real-time transcription works. My teammate and I shared many ideas and taught each other new skills. We also learned from other hackers during the event.
This project helped us understand more about accessibility technology, teamwork, and how to build a functional prototype under hackathon pressure.
What is next for SignFlow
Our next step is to improve the ASL video generation so that the avatar can show clear hand movements and correct facial expressions.
We also want to make the system faster and more accurate. In the future, we hope to turn SignFlow into a service that can be used by airports, train stations, events, schools, hospitals, TV stations, customer service centers, and many other places. Our goal is to help deaf people access spoken information more easily in as many environments as possible.



Log in or sign up for Devpost to join the conversation.