Inspiration
1 in 5 ASL users report miscommunication with healthcare providers. In a hospital, that's not just frustrating; it can be life-threatening. A patient who can't communicate "I'm in pain" or "I'm allergic to this" faces real risk. Professional interpreters are expensive, unavailable at short notice, and simply absent from most clinical interactions.
We built SignBridge to change that. A patient signs. The doctor hears them speak. No interpreter needed.
What it does
SignBridge uses a standard webcam to recognise American Sign Language in real time and convert it into spoken English, with a specific focus on healthcare communication.
The pipeline:
- MediaPipe detects 21 hand landmarks per frame via webcam in real time
- Static signs (ASL alphabet A–Z) → MLP Neural Network classifier
- Dynamic signs (words and phrases) → LSTM sequence model trained on 30-frame gesture windows
- Recognised signs buffered into a gloss sequence → Groq LLaMA → natural medical sentence
- Sentence spoken aloud via gTTS text-to-speech
Healthcare-specific gestures supported: hurt, help, doctor, emergency, water, eat, sorry, please, thank you, stop, sit, sleep, restroom, and more - exactly the signs most needed in a clinical setting.
A spell correction mode handles fingerspelling for names and medical terms - a patient can spell out a medication name letter by letter and SignBridge reconstructs the full word.
How we built it
We recorded our own custom dataset from scratch during the hackathon:
- 1,450 static landmark samples across 29 classes (full ASL alphabet + YES, NO, I LOVE YOU)
- 33,600 motion frames across 28 gesture classes
Instead of storing raw images, we used MediaPipe to extract 21 hand landmark (x, y, z) coordinates per frame - making the system signer-agnostic and independent of lighting, skin tone, and background.
Two separate models:
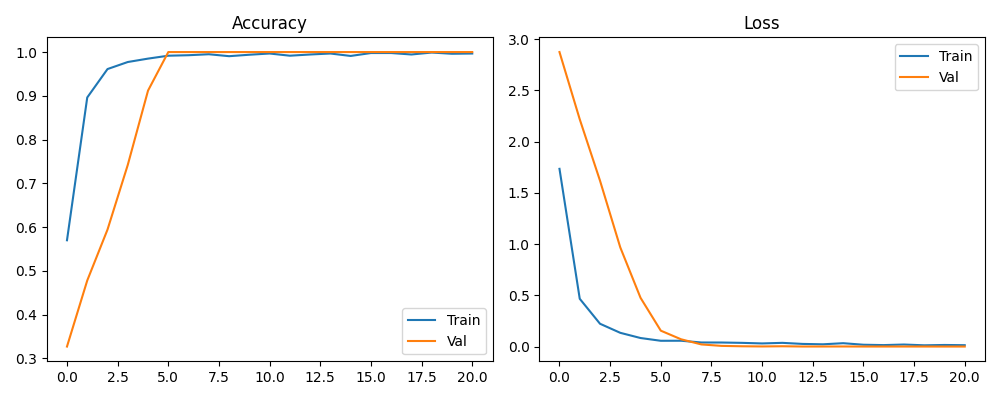
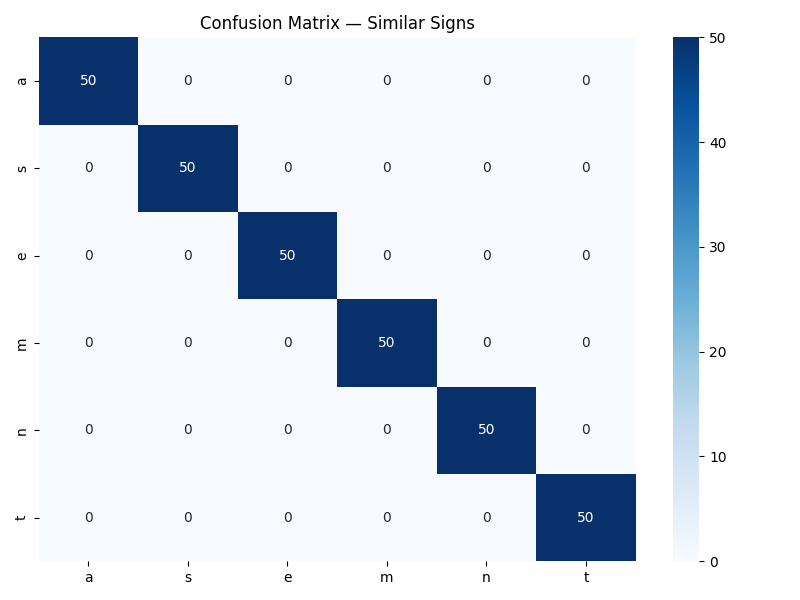
| Model | Input | Architecture | Test Accuracy |
|---|---|---|---|
| Static classifier | 63 values (single frame) | MLP: Dense(256)→Dense(128)→Dense(64) | 100% |
| Motion classifier | 126 values × 30 frames | LSTM(128)→LSTM(64)→Dense | 95.54% |
A movement detection layer routes to the correct model in real time - static model fires when the hand is still, LSTM fires when motion is detected. This prevents the two models from interfering with each other.
The LLM layer uses Groq (LLaMA) for ultra-low latency inference - critical for a real-time clinical tool. A healthcare-specific system prompt converts raw sign glosses into natural, contextually appropriate medical sentences.
Stack: Python · MediaPipe · TensorFlow · Keras · LSTM · Scikit-learn · Groq · LLaMA · Streamlit · OpenCV · gTTS
Challenges we ran into
Running static and motion models simultaneously caused constant interference - each model would override the other mid-signing. We solved this with a movement detection layer that measures frame-to-frame landmark displacement and exclusively routes to one model at a time.
We also hit Python 3.14 incompatibility with TensorFlow (required downgrade to 3.11), and had to navigate the MediaPipe 0.10.x API migration which removed the entire solutions namespace.
Accomplishments that we're proud of
- Built and labelled our own dataset entirely within the 24-hour hackathon
- First system combining static + dynamic ASL recognition in a single real-time pipeline with a routing layer
- 95.54% test accuracy on the motion model - trained on CPU in under 20 minutes
- Healthcare-focused LLM prompt engineering producing clinically relevant output
- Full pipeline: webcam → ASL → spoken English, running on a standard laptop with no GPU
What we learned
Data quality beats model complexity every time. MediaPipe landmark coordinates are so clean that a simple MLP outperforms many CNN approaches on static signs. We also learned that combining two models in a real-time pipeline is an architectural problem as much as a machine learning one - the routing logic matters more than the models themselves.
What's next for SignBridge
- Expand to Indian Sign Language (ISL) - millions of signers, almost no existing tools
- Add facial expression recognition for ASL grammatical cues
- Deploy as a tablet app for clinical waiting rooms
- Partner with hospitals to fine-tune the medical vocabulary
- Support BSL (British Sign Language) and other regional variants
Dataset Note: The full training dataset (1,450 static samples + 33,600 motion frames) is not included in the GitHub repository due to file size limitations. Collection scripts (
collect_static.pyandcollect_motion.py) are provided so anyone can record their own dataset and retrain the models.
Built With
- github
- groq
- gtts
- keras
- llama
- lstm
- mediapipe
- opencv
- python
- scikit-learn
- streamlit
- tensorflow
- visual-studio

Log in or sign up for Devpost to join the conversation.