-
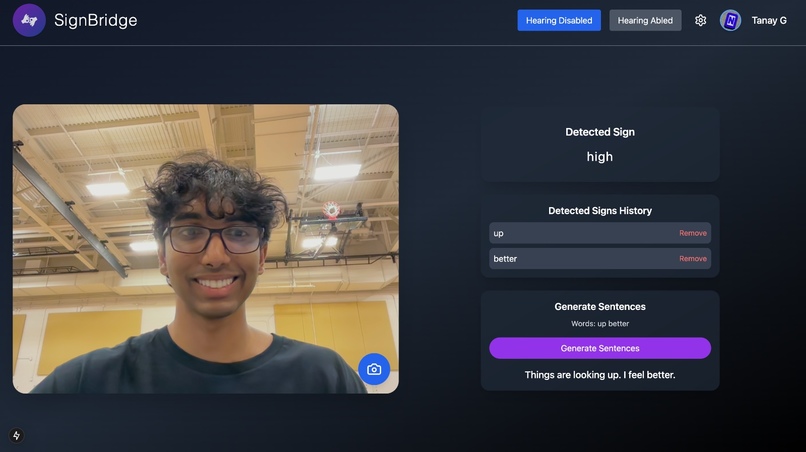
ASL to Speech with lip-sync audio
-
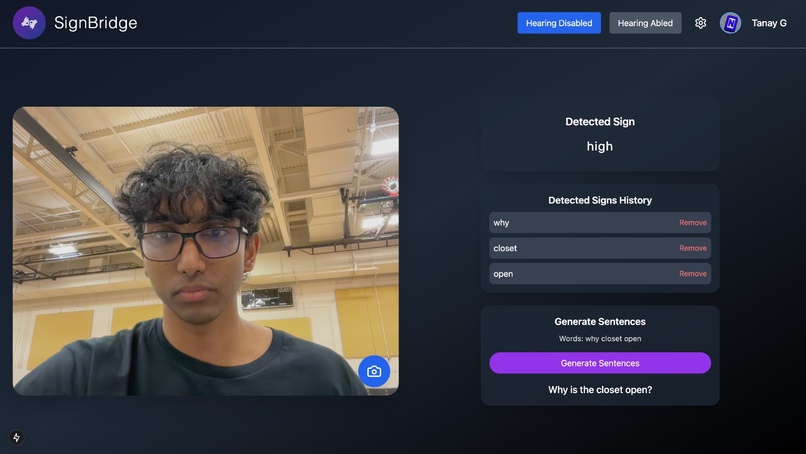
ASL to Speech with lip-sync audio
-
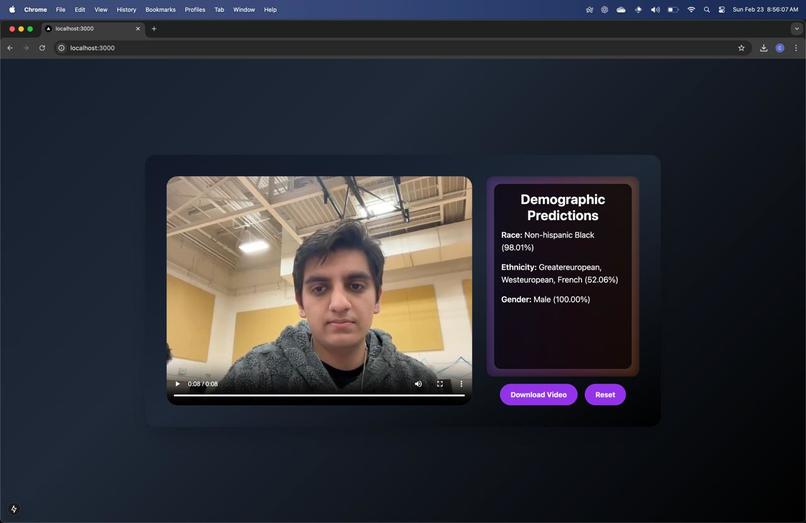
Sync API
-

Allowing SYNC to work is magic ;)
-

Hour 101
-

I am just a Cool guy.
-

Please help us add a caption.
-

We even got some cool merch!
-
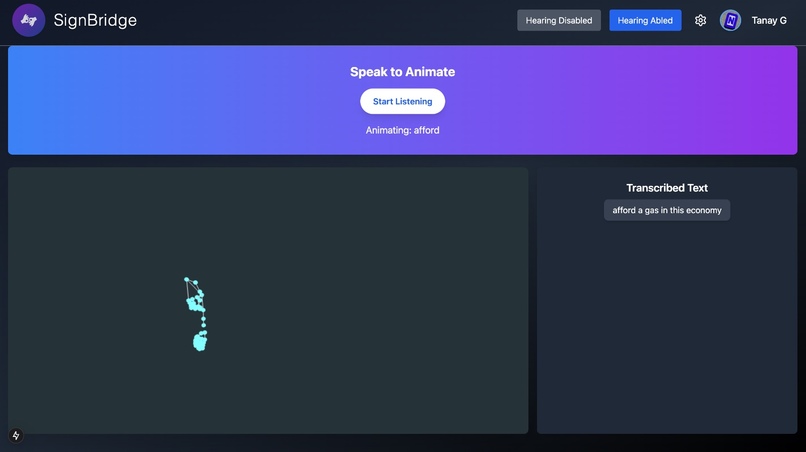
Afford gas in this economy





Inspiration
Imagine sitting in a job interview. You’re the perfect candidate - your resume is impressive, the interviewers seem excited, and you know exactly what to say.
But when you try to speak, nothing comes out.
You gesture, trying to explain, but they don’t understand. The opportunity slips away - not because you aren’t qualified, but because the world cannot hear you.
Now, imagine a world where that barrier doesn’t exist. Where your thoughts and ideas are heard, no matter how you express them. That’s the future we’re building.
What it does
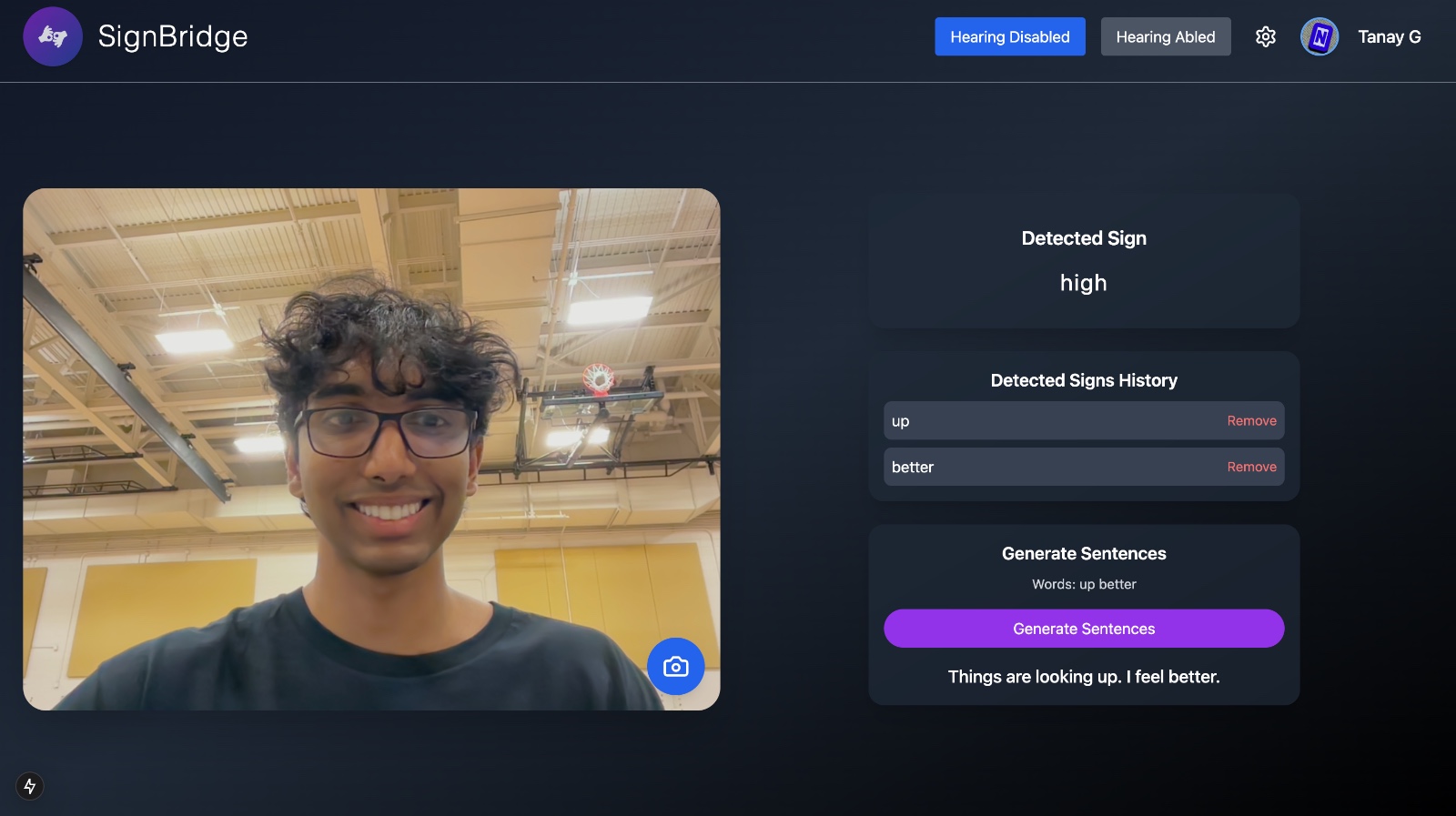
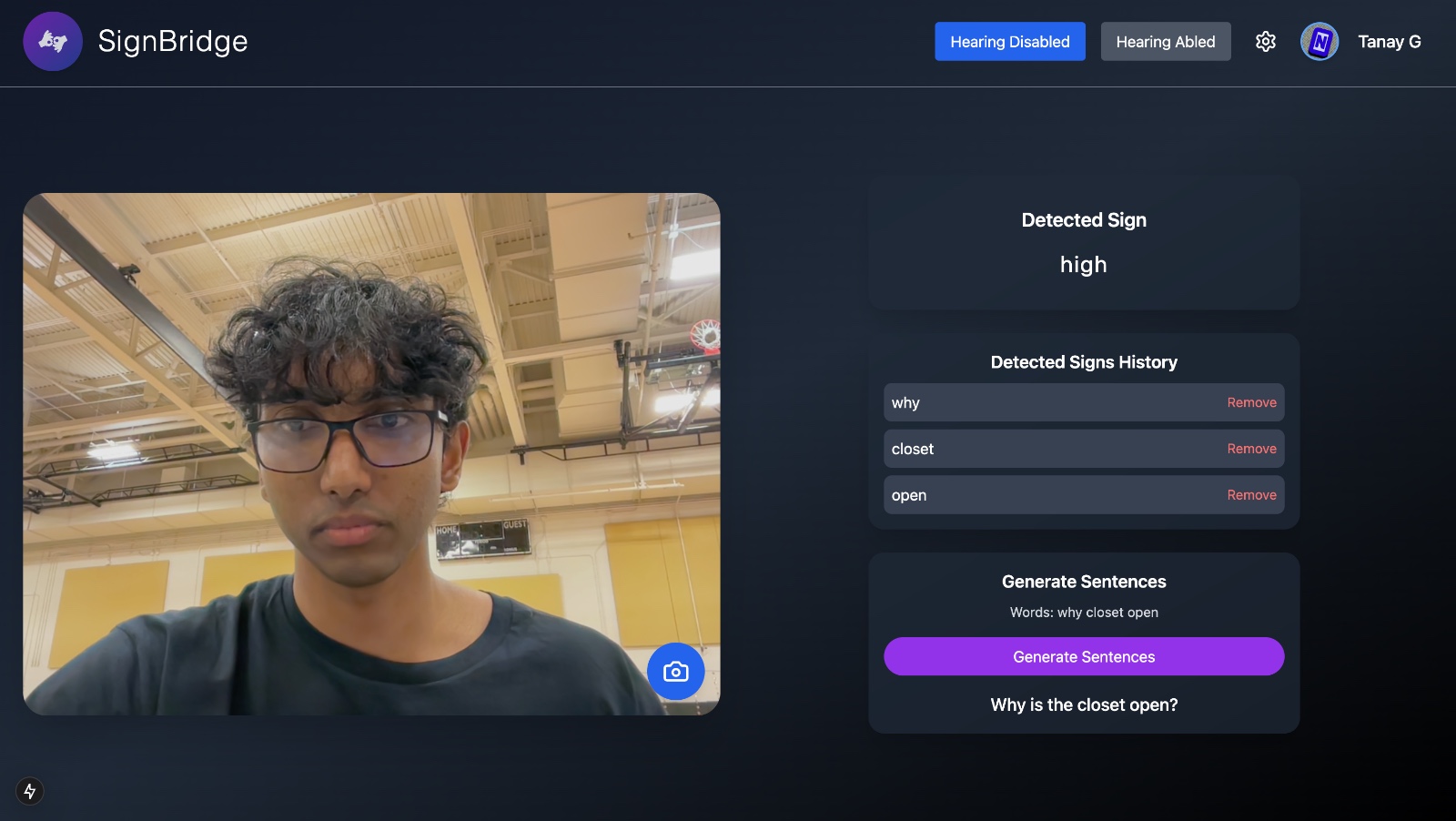
SignBridge is an AI-powered tool that translates American Sign Language (ASL) into both text and speech in real time, breaking down communication barriers for the deaf and non-verbal community.
Using computer vision, SignBridge captures hand gestures and movements, processes them through a Convolutional Neural Network (CNN), and converts them into readable text. Then, to make interactions more natural, we go a step further—syncing the generated speech with a video of the person signing, making it appear as though they are actually speaking.
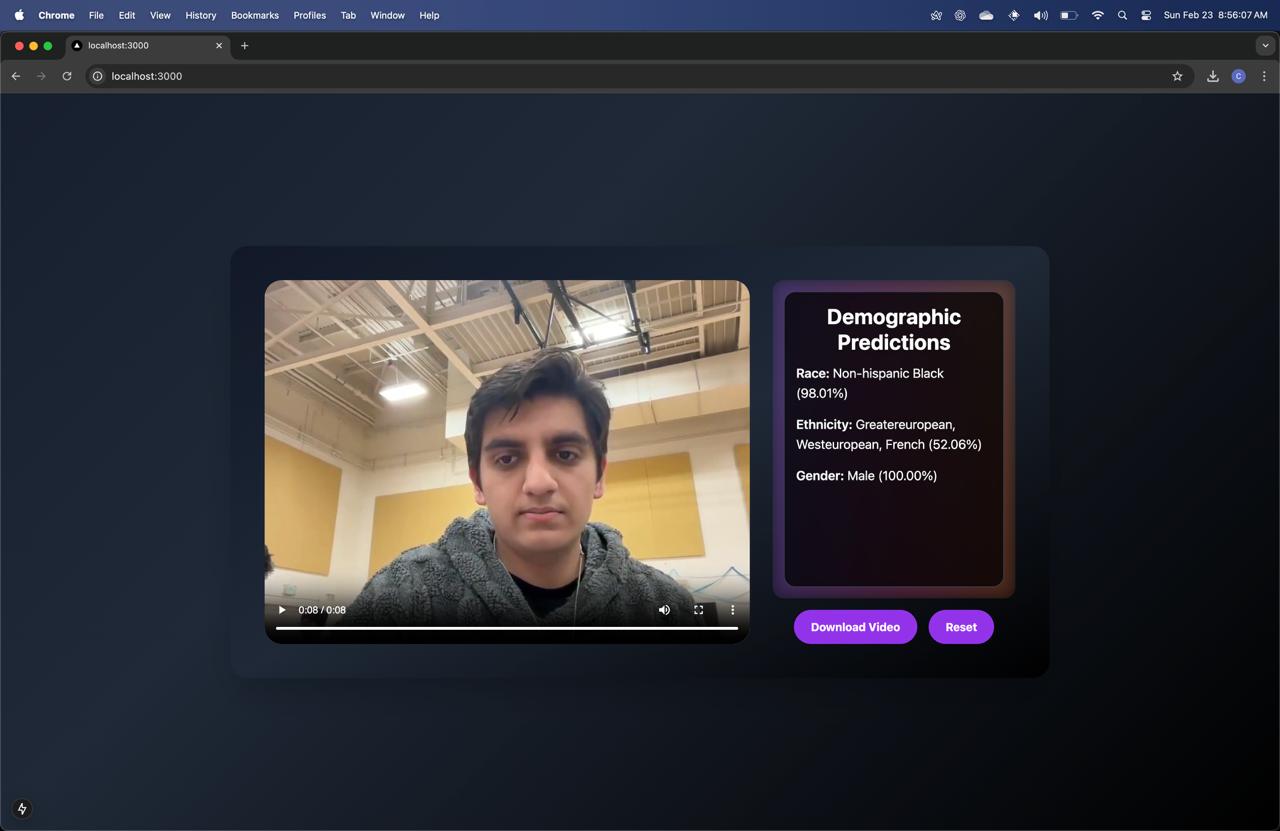
This is achieved using Sync, an AI-powered lip-syncing tool that animates the signer’s lips to match the spoken output. Additionally, SignBridge considers the signer’s gender and race to generate an appropriate AI voice, ensuring a more authentic and personalized communication experience.
With its ability to provide instant translation and realistic speech synchronization, SignBridge can be used in everyday conversations, workplaces, educational settings, and beyond—helping to create a world where communication is truly inclusive.
How we built it
SignBridge: Technical Overview
1) ASL to Speech
Our system leverages a Transformer-based Neural Network to recognize hand gestures made by the user and translate them into spoken language. The model is trained on a dataset of American Sign Language (ASL) gestures and is implemented using MediaPipe for real-time hand tracking and gesture recognition. The trained model processes ASL inputs efficiently, ensuring accurate and seamless translation to speech.
2) User Authentication with Auth0
We integrate Auth0 for secure user authentication. This is crucial as our system utilizes facial recognition and lip-syncing techniques to enhance the accuracy and personalization of speech generation from ASL gestures. By mapping users' facial movements and lip sync patterns, we create a more natural and context-aware speech output, making interactions more lifelike and engaging.
3) Lip-Sync Audio Generation
To ensure that the generated speech is synchronized with realistic lip movements, our system makes API calls to specialized lip-syncing services. This feature improves the visual realism and inclusivity of our ASL-to-speech conversion by mapping audio to corresponding lip movements.
4) Generative AI for Word Prediction
A Generative AI model is employed to enhance word prediction and context interpretation. By analyzing sequential ASL inputs, the AI model can predict probable next words, improving the fluency and coherence of the generated speech.
5) Ethnicity and Gender Prediction Using BERT
We integrate BERT (Bidirectional Encoder Representations from Transformers) to infer the ethnicity and gender of the user based on their name. This information helps tailor the speech synthesis to better match cultural and linguistic nuances, contributing to a more personalized and contextually aware translation.
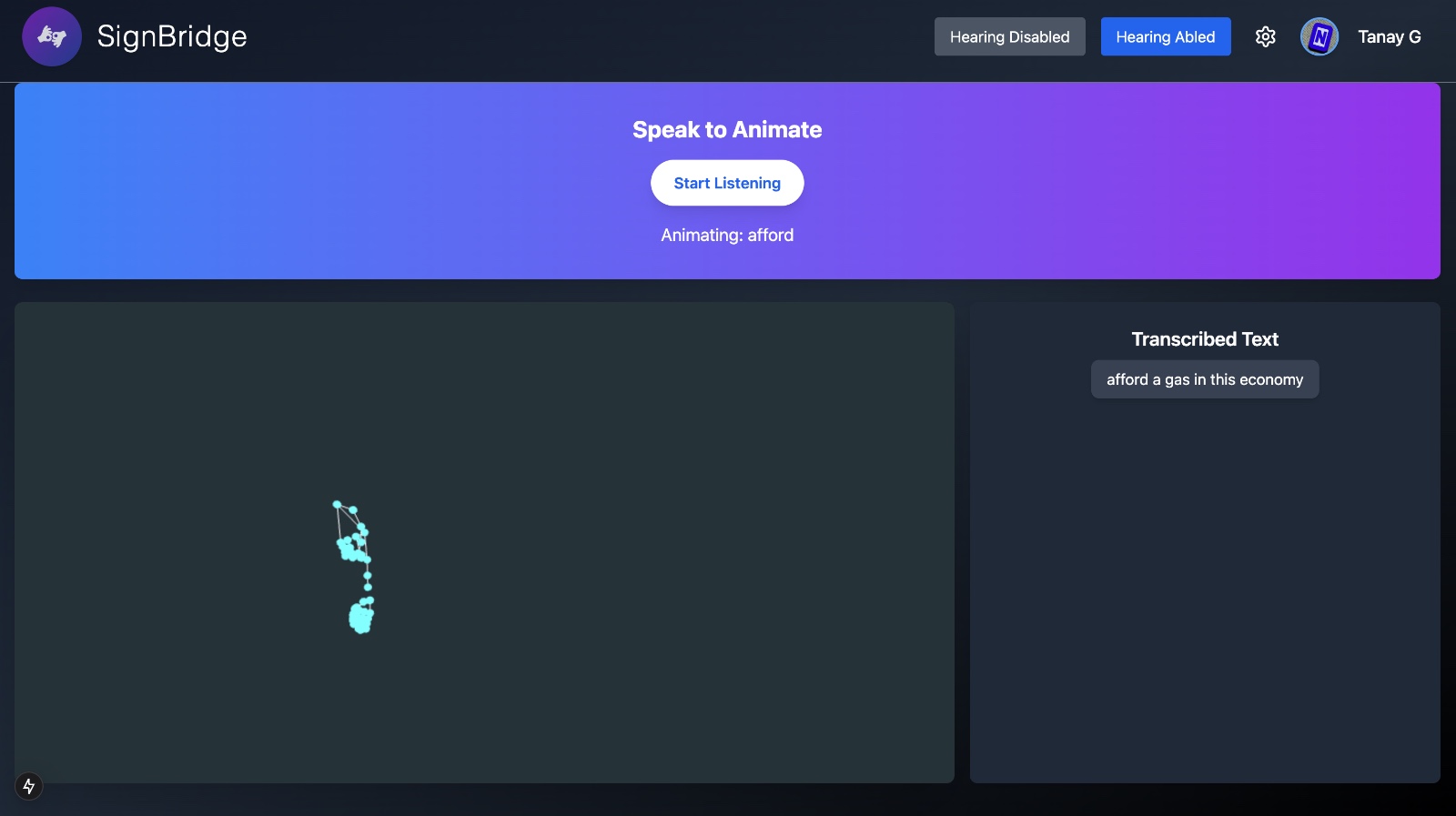
6) Speech to ASL
The Speech-to-ASL module follows these steps:
Speech Collection in the Frontend:
- The system records speech input from users directly within the web application.
- The system records speech input from users directly within the web application.
Mapping Speech to Hand Motions:
- To convert speech into ASL gestures, we require a comprehensive dataset of sign language videos that correspond to spoken words.
- These videos are web-scraped from reliable ASL datasets and repositories, ensuring a diverse and accurate representation of gestures.
- The processed video segments are then mapped to hand motion sequences and dynamically displayed on the frontend to provide users with an ASL visualization of the spoken input.
- To convert speech into ASL gestures, we require a comprehensive dataset of sign language videos that correspond to spoken words.
By combining machine learning, natural language processing, and computer vision, SignBridge creates an efficient and accessible communication bridge between ASL and spoken language. 🚀
Challenges We Encountered
Throughout the development of SignBridge, we faced several technical challenges that required iterative problem-solving and optimization. Below is a breakdown of the key issues and how we addressed them:
Step 1: Gesture Recognition Accuracy & Word Buffering
- One of the primary challenges in ASL-to-speech translation was buffer misclassification—when users repeated a gesture, the model sometimes predicted incorrect words due to lingering buffer data.
- To resolve this, we implemented a buffer filtering mechanism that dynamically removes incorrect predictions and stabilizes the output, ensuring accuracy in translation.
- Additionally, our dataset was limited to 249 recognized words, and while we had access to a larger dataset, retraining the model on time was impractical. We had to develop an alternative approach to balance dataset limitations with real-time usability.
Step 2: Gender-Neutral Speech Generation
- When generating speech from ASL, we found that most available text-to-speech (TTS) models defaulted to female voices.
- To introduce gender diversity in voice synthesis, we designed a mathematical approach to alter pitch and frequency dynamically, allowing us to modify existing voice outputs instead of sourcing additional models.
Step 3: Real-Time Lip-Sync Optimization
- Synchronizing generated speech with lip movements was computationally intensive, causing latency issues.
- We evaluated multiple lip-syncing models to determine the fastest and most efficient approach for real-time performance.
- Ultimately, we selected an optimized model that significantly reduced sync time, ensuring fluid and natural lip synchronization.
Step 4: Prompt Engineering for Phrase Generation
- To improve ASL-to-text conversion accuracy, we needed to extract the most contextually relevant phrase from multiple predicted words.
- Using prompt engineering, we refined the model’s ability to select the phrase with the highest contextual weightage from the five most likely word predictions, improving the fluency of translated sentences.
Step 5: Handling Unrecognized Words via Fingerspelling
- Since the entire application relied on gesture recognition, there was always a possibility that a word was not present in our dataset.
- In such cases, we implemented fingerspelling (letter-by-letter spelling of words using ASL hand signs) instead of generating incorrect words, ensuring continued communication.
Accomplishments that we're proud of
One of our biggest accomplishments is creating a tool that has the potential to improve communication and accessibility for people with hearing and speech impairments. By successfully translating American Sign Language (ASL) into text and speech in real time, we’re helping bridge a gap that has long been a barrier for many.
We’re also proud of the technical achievements behind SignBridge. From training a computer vision model to recognize ASL gestures to fine-tuning real-time text and speech output, we tackled complex challenges in deep learning, natural language processing, and synchronization.
Beyond the technology, we’re proud of the impact SignBridge can have. It’s more than just a project—it’s a step toward a more inclusive world where everyone, regardless of how they communicate, has a voice.
What we learned
1) Computer Vision Model Implementation with Limited Data
- We learned how to train and optimize computer vision models with a constrained dataset. By leveraging data augmentation and transfer learning, we improved recognition accuracy despite the limited availability of ASL gesture datasets.
2) Real-Time Synchronization Challenges
- Achieving real-time synchronization between ASL gestures, speech output, and lip movements was a significant challenge. We optimized our neural network inference speed and reduced latency in video processing to ensure a seamless user experience.
3) Prompt Engineering for Improved Predictions
- We explored prompt engineering techniques to generate contextually accurate phrases from multiple ASL-to-text predictions. This significantly improved the fluency and accuracy of ASL translations, making communication more natural and effective.
What's next for SignBridge
SignBridge is just the beginning of a much larger vision. While it currently translates American Sign Language (ASL) into text and speech, we want to take it even further. We aim to expand its capabilities to include more sign languages from around the world, ensuring accessibility for a global audience.
We also aim to improve translation accuracy by incorporating more advanced deep learning models, enabling smoother, more natural conversations.
Beyond language expansion, we’re working on improving the user experience by making SignBridge accessible across multiple platforms, including mobile and web applications. Our goal is to integrate it into everyday environments—customer service, classrooms, workplaces—anywhere communication barriers exist.
Ultimately, we envision SignBridge as more than just a tool—it’s a step toward a more inclusive world where communication is truly universal.
Built With
- auth0
- beautiful-soup
- bert
- flask
- google-drive
- mediapipe
- next.js
- python
- sync
- typescript






Log in or sign up for Devpost to join the conversation.