-
-
1
-
4
-
3
-
2
Inspiration
Modern systems generate massive amounts of logs, but when something breaks, engineers and analysts still spend a lot of time manually searching through noisy data to understand what actually went wrong. From our own experience, log debugging often turns into guesswork: scanning thousands of lines, jumping between services, and trying to mentally piece together patterns under time pressure.
We were inspired to build LogLens AI to answer a simple question:
What if logs could explain themselves?
Instead of treating logs as raw text, we wanted to transform them into structured signals that surface incidents, explain likely causes, and help teams act faster.
What it does
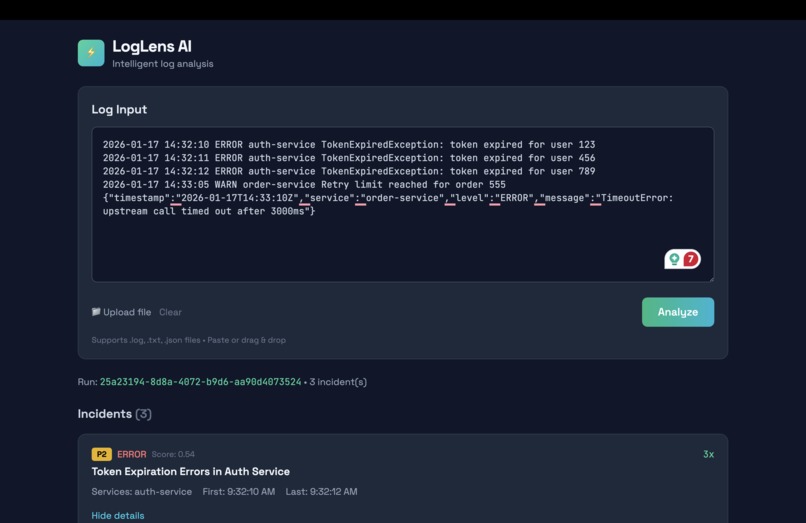
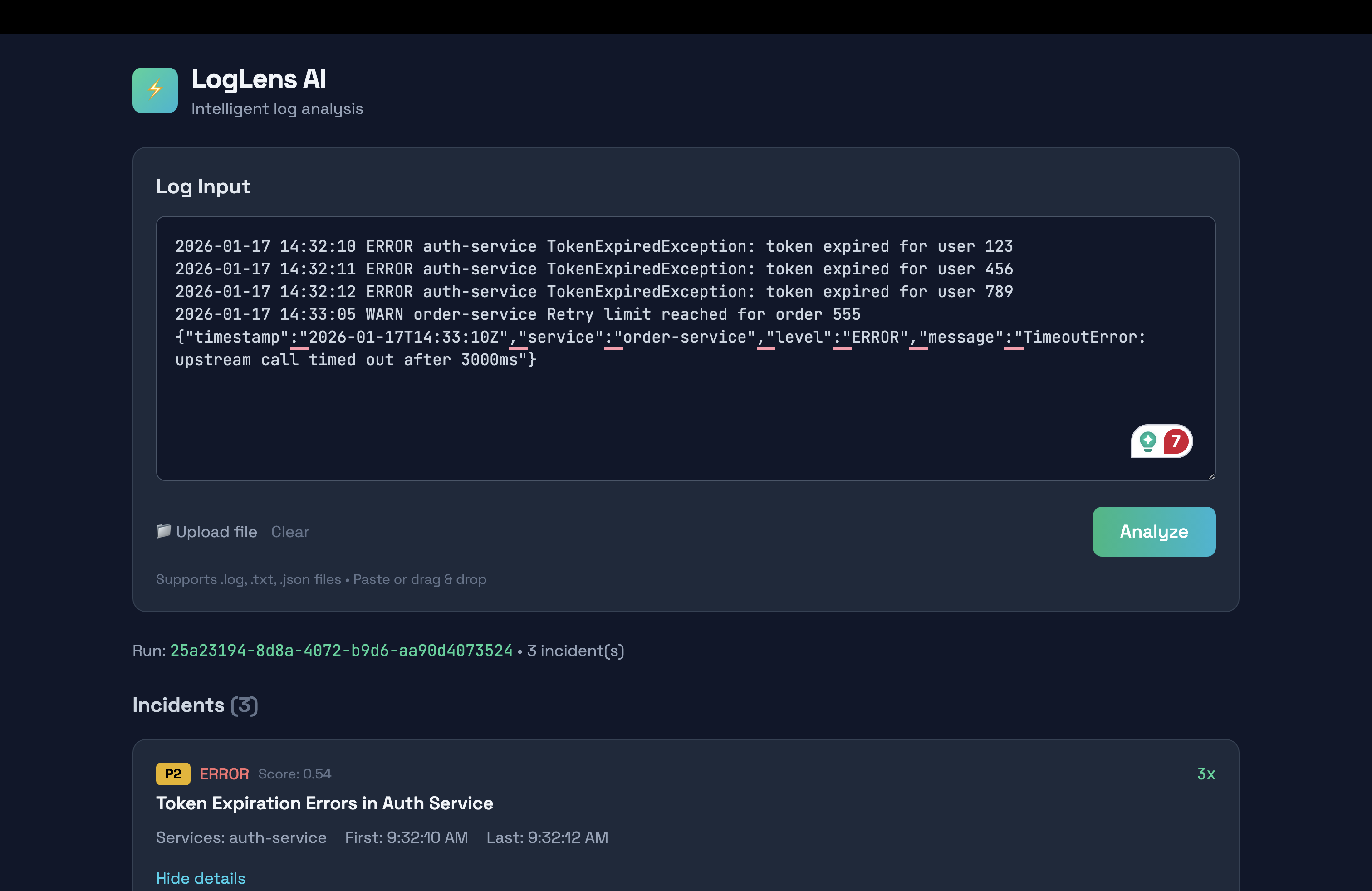
LogLens AI takes raw log files and transforms them into actionable incident reports. You upload a log file, and within seconds you get a prioritized list of incidents with severity scores, affected services, and AI-generated explanations.
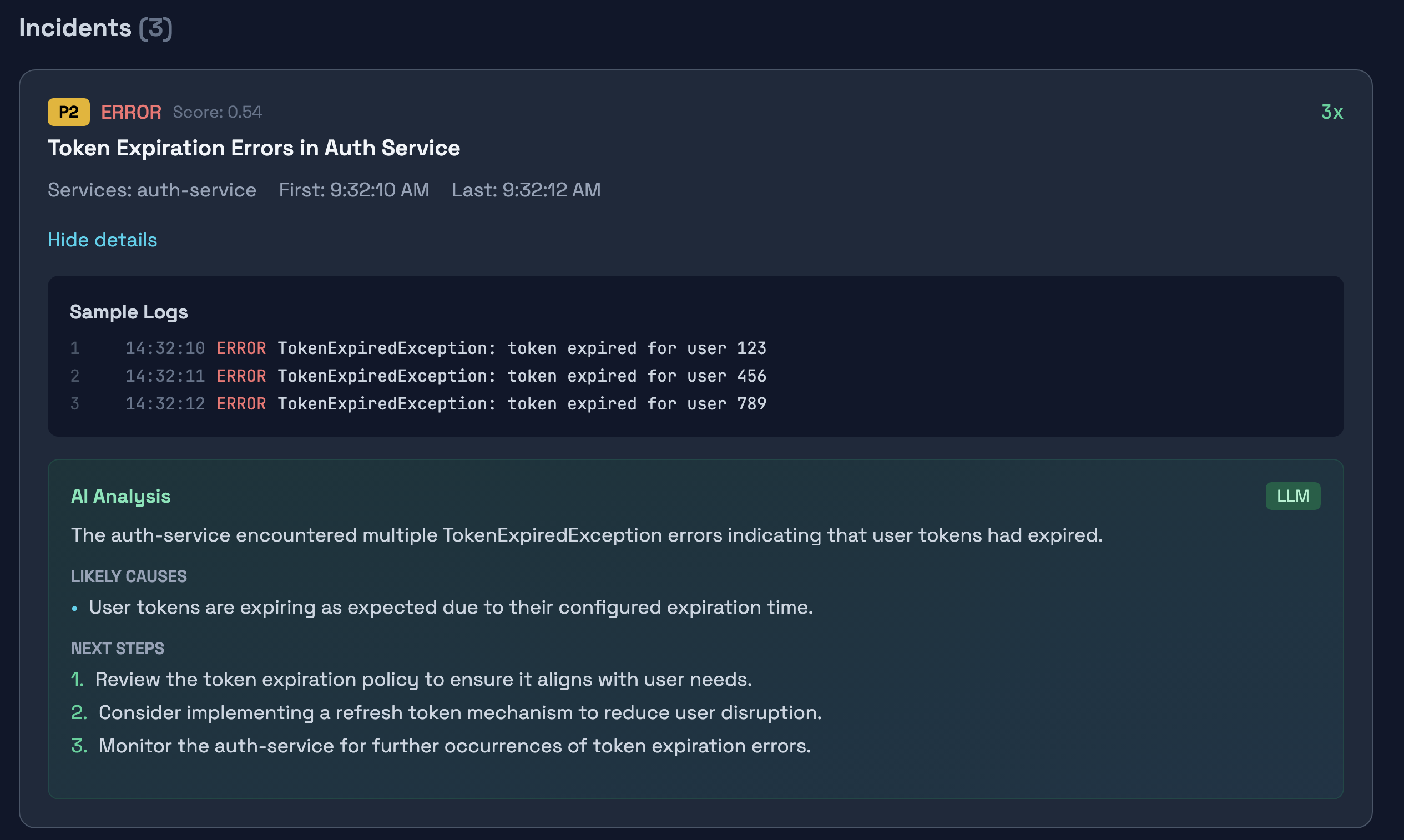
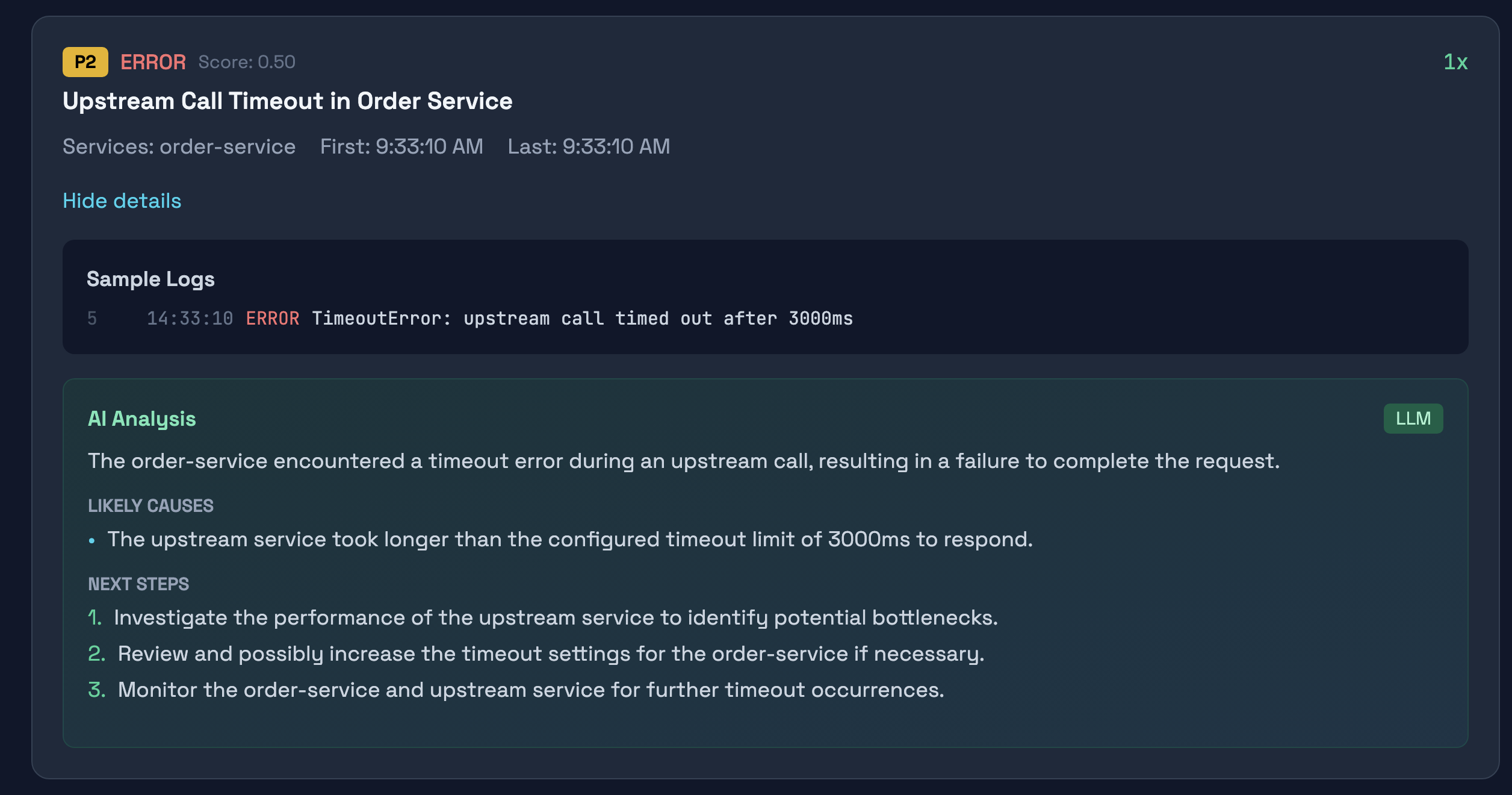
The system parses both plain text and JSON logs, groups similar errors together using message normalization, and ranks incidents by severity, frequency, and recency. Each incident gets a priority label from P0 to P3, helping teams focus on what matters most.
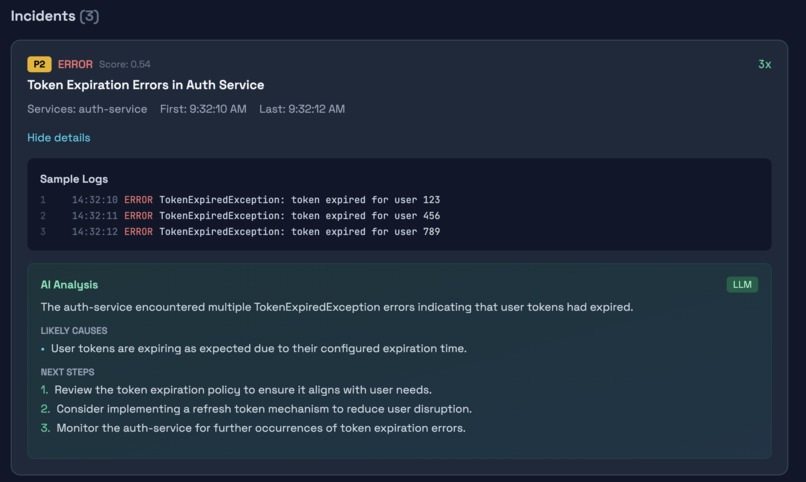
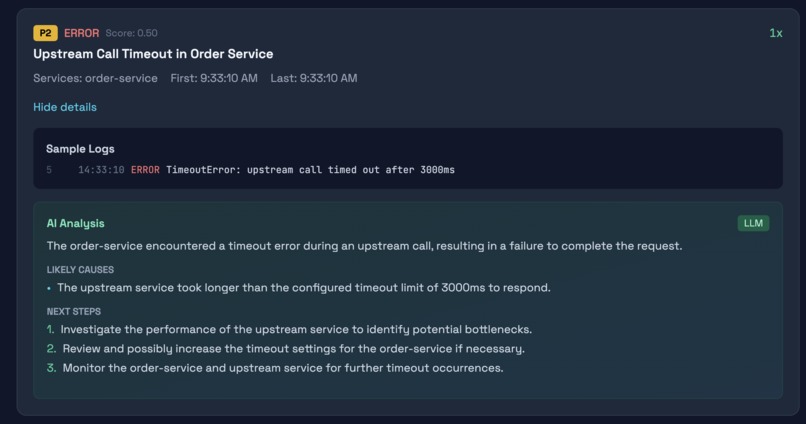
When you click into an incident, you see sample log lines with line numbers, timestamps, and an AI analysis that explains what happened, suggests likely causes with evidence from the actual logs, and recommends concrete next steps. The AI is grounded in the log data, so it cannot invent details that are not present in the evidence.
How we built it
We split the work across four roles on our team. One person handled the backend API and orchestration using FastAPI and SQLite. Another focused on log parsing and grouping logic, building a robust parser that handles multiple log formats and normalizes messages to detect patterns. A third teammate built the ranking and scoring system that calculates priority labels. The fourth worked on LLM grounding and hallucination detection to ensure AI explanations stay faithful to the actual log content.
The frontend is a React app with Tailwind CSS that connects to the backend through a REST API. We used OpenRouter to access GPT-4o-mini for generating explanations, with strict validation to catch any hallucinated details like invented IP addresses or overconfident claims.
We used Git branches and pull requests throughout to keep our changes organized and reviewable.
Challenges we ran into
Getting the log grouping right was harder than expected. Early versions would either over-group unrelated errors or under-group the same error with different user IDs. We had to iterate on the normalization logic, adding regex patterns to replace UUIDs, IP addresses, timestamps, and numeric values with placeholders.
Preventing LLM hallucinations was another challenge. During testing, we noticed the model would sometimes invent network details or make definitive claims about root causes that were not supported by the logs. We added validation that checks for invented IPs and ports, blocks overconfident phrases like "definitely" or "root cause is", and falls back to a deterministic explanation if grounding checks fail.
Integrating four teammates' code into one coherent backend also required careful coordination. Each person had their own data structures, so we built adapter layers to translate between them without breaking existing functionality.
Accomplishments that we're proud of
We built a working end-to-end product in a short time. You can paste logs into the UI, get prioritized incidents, and read AI explanations that actually reference the log lines.
The hallucination detection is something we are particularly proud of. It validates that every IP, port, and line number in the AI response actually exists in the evidence. This makes the output trustworthy enough to share with a team.
The priority scoring system gives useful rankings. P0 and P1 incidents surface high-severity, high-frequency, recent errors, while P3 catches low-priority warnings that might not need immediate attention.
What we learned
We learned that LLM grounding matters. Letting a model generate free-form explanations is easy, but making sure those explanations are accurate requires explicit validation. Adding banned phrase lists and evidence checks made a real difference in output quality.
We also learned the value of clean interfaces between components. By defining clear data contracts early, we could work in parallel and merge without major conflicts.
On the technical side, we got deeper experience with FastAPI, Pydantic validation, SQLite for lightweight persistence, and React with Tailwind for quick UI development.
What's next for LogLens AI
We want to add support for streaming log ingestion, so teams can analyze logs in real time instead of uploading files. We are also thinking about adding anomaly detection to flag unusual patterns that deviate from baseline behavior.
Integrating with alerting systems like PagerDuty or Slack would let teams get notified when a high-priority incident is detected. And we want to add a feedback loop where users can mark explanations as helpful or not, which could be used to fine-tune the prompts over time.
Long term, we see LogLens AI becoming a standard part of the incident response workflow, sitting alongside monitoring dashboards and helping teams go from alert to understanding in seconds instead of hours.




Log in or sign up for Devpost to join the conversation.