-
demo
-
start page
Inspiration
I've noticed that sending huge documents to LLMs is slow and expensive. We're all told to just "add more context," but this burns tokens and bogs down the model. I was inspired to see if I could build a "smart filter" that automatically cuts out the "fluff" from a document, reducing the cost while keeping the actual, important information.
What it does
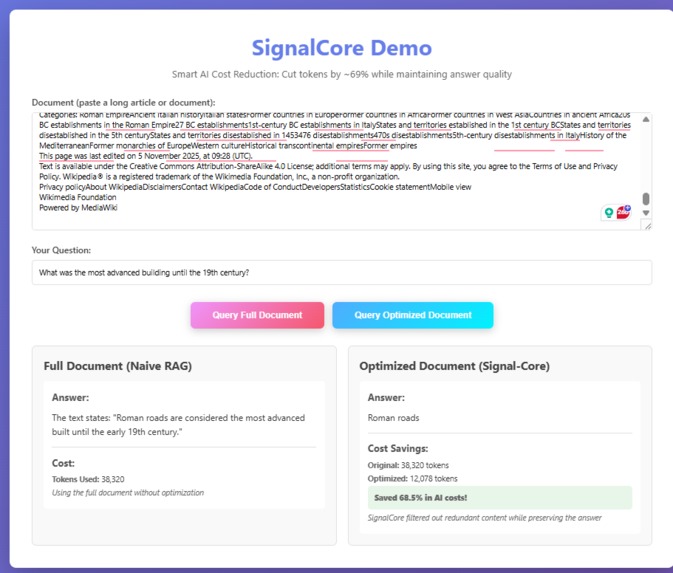
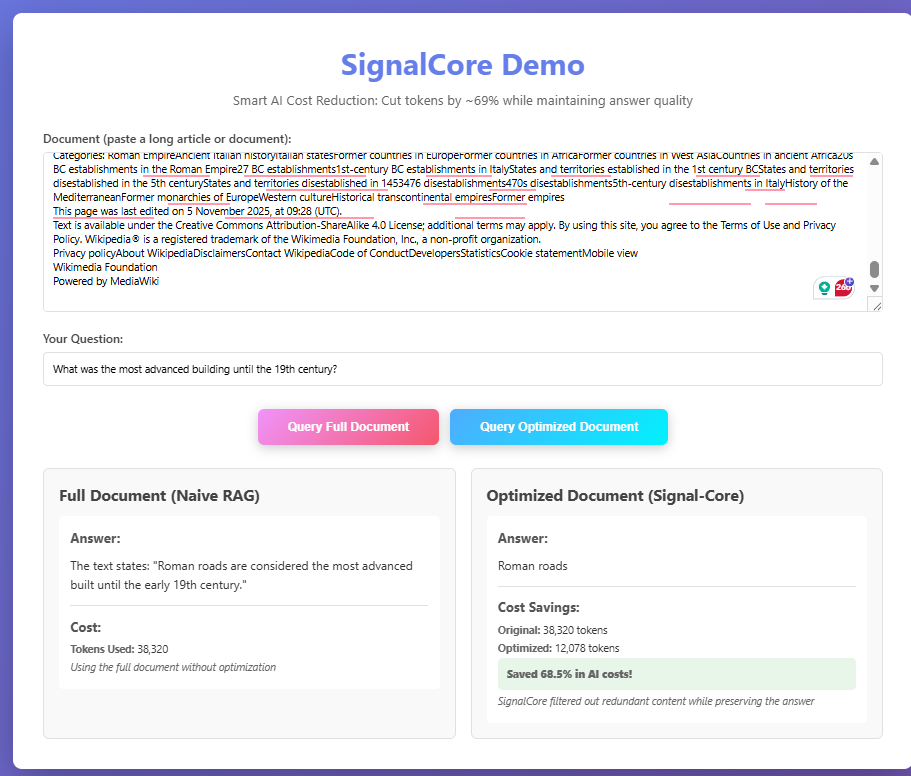
So I built SignalCore, a two-step "smart filter" that cleans up text before an AI sees it.
First, it reads a long document and chops it into logical pieces, making sure not to cut off a sentence or idea in the middle.
Then, it "reads" each piece and throws out all the filler sentences, keeping only the most important, "on-topic" ones.
The result is a much shorter, "high-signal" piece of text that gives the AI the same quality of answer for a fraction of the cost.
How we built it
Backend: A simple Python server using Flask.
Frontend: HTML, CSS, and Vanilla JavaScript
Algorithm: Complete Python Script. I built a chunker that respects sentence boundaries and a "centroid" pruner that finds the most on-topic sentences using simple word math.
Testing API: Google's gemini-2.5-flash-lite model.
Challenges we ran into
The biggest challenge was the algorithm itself, and keeping it simple given the time. I also had a major pivot: my first test (a "Needle in a Haystack") was invalidated. I found that modern models (like gemini-1.5-flash) are already good at that test, and my pruner correctly removed the "needle" because it saw it as semantic noise. This forced me to pivot to a more realistic test: proving I could reduce cost for on-topic, summary questions instead.
Accomplishments that we're proud of
Seeing that the tool actually works and is actually quite useful in the day-to-day is the most important thing for me. The fact is that almost everyone uses LLMs, and being able to make LLMs more productive by using 37.6% fewer tokens for each use—while getting the same quality answer—is the most important thing.
What we learned
I learned that there's a fundamental tradeoff between aggressively pruning text for cost and retrieving random, out-of-context facts. My key takeaway is that for realistic, on-topic queries, you can successfully prune away a lot of noise and save significant cost without hurting the AI's final answer.
What's next for SignalCore
The next step would be to build on this project even more and use a more powerful algorithm using TextRank and Dynamic Programming. Then I would turn this into a tool on VS Code or add it as a plugin on LangChain so that any developer could add it to their project.

Log in or sign up for Devpost to join the conversation.