-

App logo
-
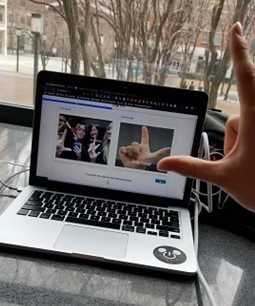
Demoing the webapp

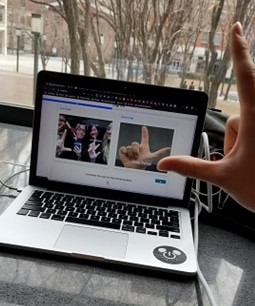
Inspiration
The goal of this project is to provide an interactive, accessible learning platform for users to learn American Sign Language. We were largely inspired by popular apps like Duolingo and the possibility of integrating intelligent vision systems in education.
What it does
This web application allows users to use just their webcam and their hand to learn American Sign Language and receive real time feedback. The learning environment is composed of three main parts. On the right, the user is shown a reference image of a signed letter. On the left, the user’s live camera feed is shown. On the top, a live feedback bar shows the user’s progress--the more correct letters they sign, the closer they become to advancing to the next learning module. On the right, new material is introduced for further learning.
How we built it
Our user feedback system was built in three stages. We had to:
- Design the learning experience.
We made a minimalist website with user friendly features, dividing the screen into three necessary interactive regions— one for learning new material, and one for user input, and one for feedback.
- Use object detection and bounding box segmentation to identify and locate users’ hands.
We used Handtrack.js, which trained on a dataset of annotated human hand pictures. We then implemented image preprocessing on detected hands, cropping them closely to reduce the noise in our data (environmental lighting/background) before sending it to our classifier. A live webcam video feed was added to our webapp, and a snapshot of the video would be saved if a hand was detected in the feed.
- Create a custom image classifier for American Sign Language
We took over 500 photos with our webcams to create a data set of signs, which we used as inputs to train our custom IBM Watson visual recognition model. We used REST API’s to send images from our node.js webapp to our classifier, which sent back json files including the classification with the highest confidence level.
Challenges we ran into
Choosing and creating an image classifier model. We started out by utilizing a premade dataset that we loaded into IBM Watson; however, after trial and error, we thought it best to create our own dataset and try other classification models. We also used the Google AutoML vision, which yielded 98.18% precision and 93.1% recall-- unfortunately, we didn't have time to switch to its API.
Accomplishments that we're proud of
Receiving a high overall classification accuracy with our handmade dataset.
Built With
- ibm-watson
- node.js
- tensorflow




Log in or sign up for Devpost to join the conversation.