-
-
landing page
-
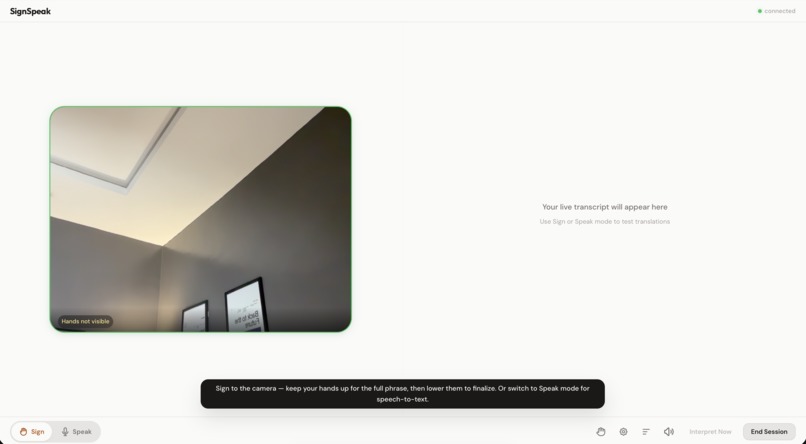
chat interface
-
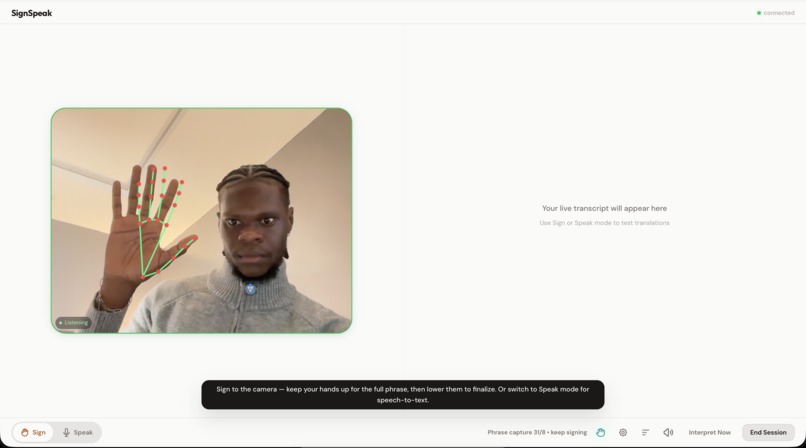
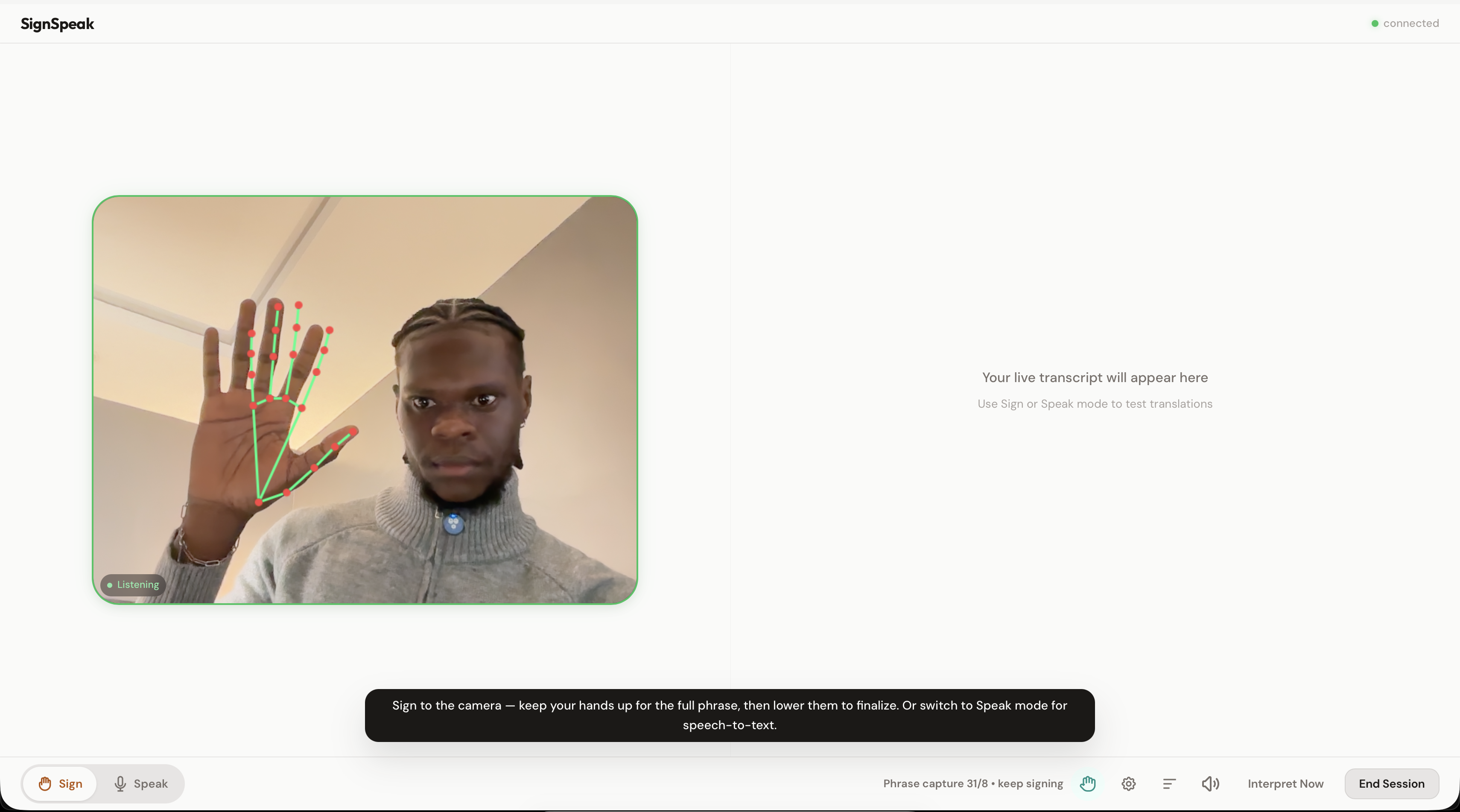
hand detection
Inspiration
When I saw the Gemini Live Agent Challenge, I wanted to think beyond typical SaaS use cases, live agents that actually integrate into people's lives in a meaningful way. My girlfriend's sister is hard of hearing, so accessibility was already on my mind. ASL interpretation just made sense. Real-time vision + audio is exactly what a live agent should be doing, and the gap between deaf and hearing communication felt like a problem worth solving. No scheduling an interpreter two weeks out, no expensive hardware just open a browser tab.
What it does
SignSpeak Live is a bidirectional ASL interpreter running entirely in the browser.
- Sign → Speech: Camera watches you sign, Gemini recognizes it, Google Cloud TTS speaks the English translation.
- Speech → Sign: Speak into your mic, get ASL gloss notation displayed in real time.
- Multi-party rooms: Multiple people join a shared session — signs and speech get translated and broadcast to everyone.
How we built it
Frontend: React + TypeScript + Vite. MediaPipe detects hands on the client side so we only send frames when someone is actually signing. Frames captured at 8 FPS, encoded as JPEG, sent over WebSocket.
Backend: FastAPI server with one WebSocket endpoint. Video frames get buffered (up to 48 frames) then batch-sent to Gemini's vision model. Audio gets debounced (500ms window) before transcription. A 230-line system prompt teaches the model ASL linguistics — handshape, movement, location, palm orientation — with 90+ defined signs as reference vocabulary.
Deploys to Cloud Run with Docker, autoscaling 1-10 replicas.
Challenges we ran into
Knowing when a sign ends. There's no "spacebar" in ASL. We used hands-down segmentation: when hands leave the frame, a 900ms grace timer starts. Hands come back? Keep buffering. They don't? Flush for interpretation.
Frame sampling. Sending 48 raw frames to Gemini would be slow and expensive. We sample 18 frames evenly across the buffer so the model sees the full motion arc.
Audio debouncing. Speech doesn't come in neat packets. We needed a 500ms quiet window plus a 1800ms hard max to avoid cutting people off or waiting forever.
Accomplishments that we're proud of
- Hands-down segmentation feels natural — the app knows when you're done signing
- Multi-party rooms actually work across locations
- Bidirectional: most apps only do sign→English, we also do English→ASL gloss
- Zero installs — runs in a browser tab
What we learned
- ASL is not "English with your hands." The grammar and structure are completely different. Building the prompt required studying actual ASL linguistics.
- Gemini's vision model needs temporal context, single frames are useless, you need the motion.
- Client-side hand detection as a gate saved us a ton of API costs. Don't send frames unless there's something to interpret.
- Real-time apps are 80% buffering strategy, 20% actual AI.
What's next for SignSpeak Live
- Fingerspelling recognition , currently the weakest area, needs better frame rates or a specialized model
- More sign languages — BSL, JSL, others with completely different grammars
- Mobile native app for a smoother camera experience
- Signing avatar — instead of gloss text, an animated avatar that signs back
Built With
- cloud
- docker
- fastapi
- google-cloud
- google-cloud-text-to-speech
- google-gemini-api
- mediapipe
- python
- react
- typescript
- vite
- websockets

Log in or sign up for Devpost to join the conversation.