-
-
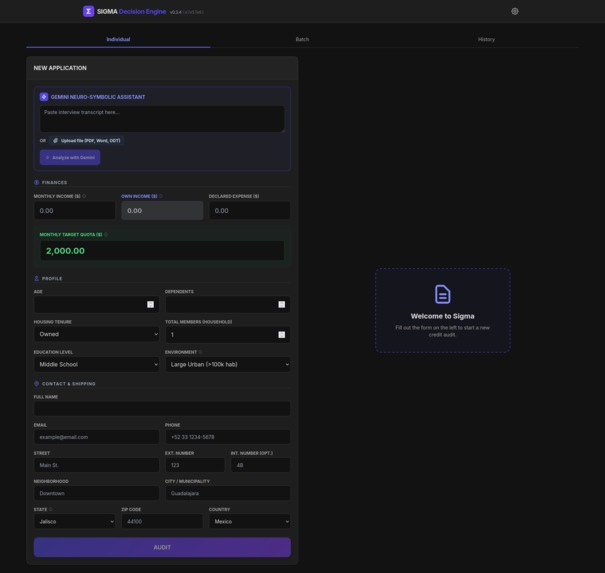
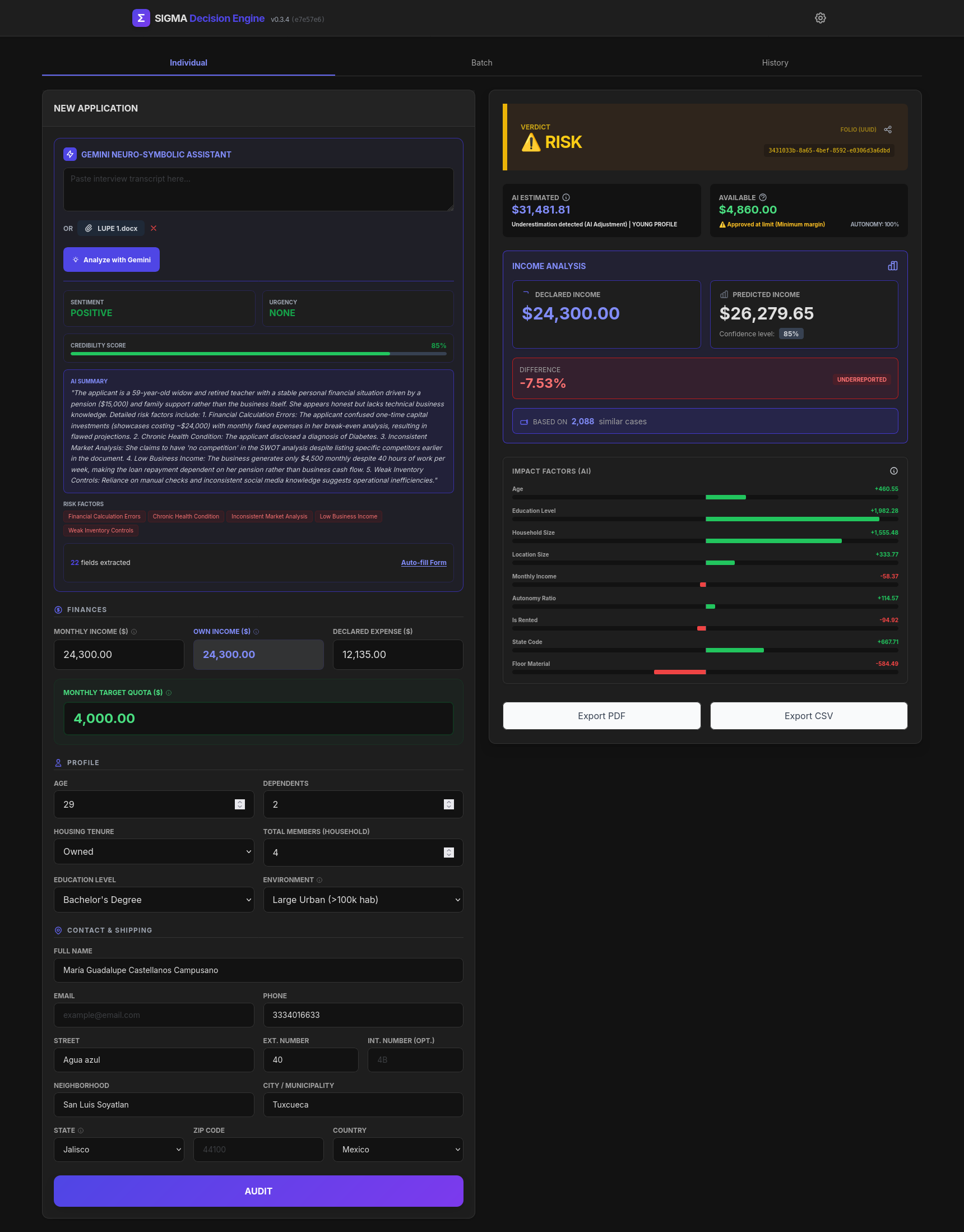
Individual - Empty
-
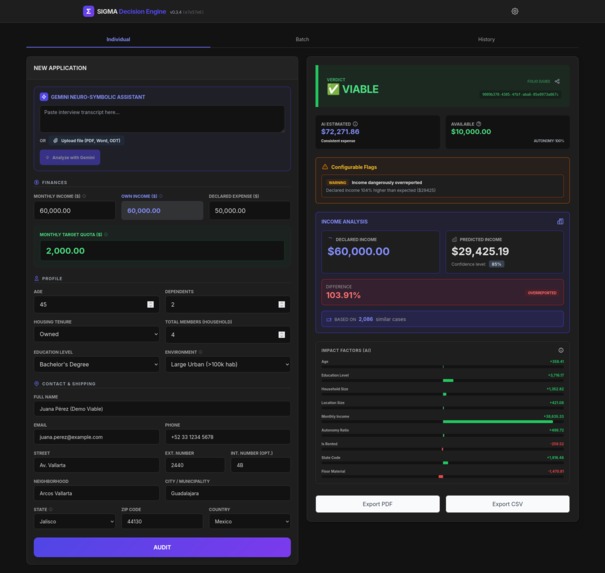
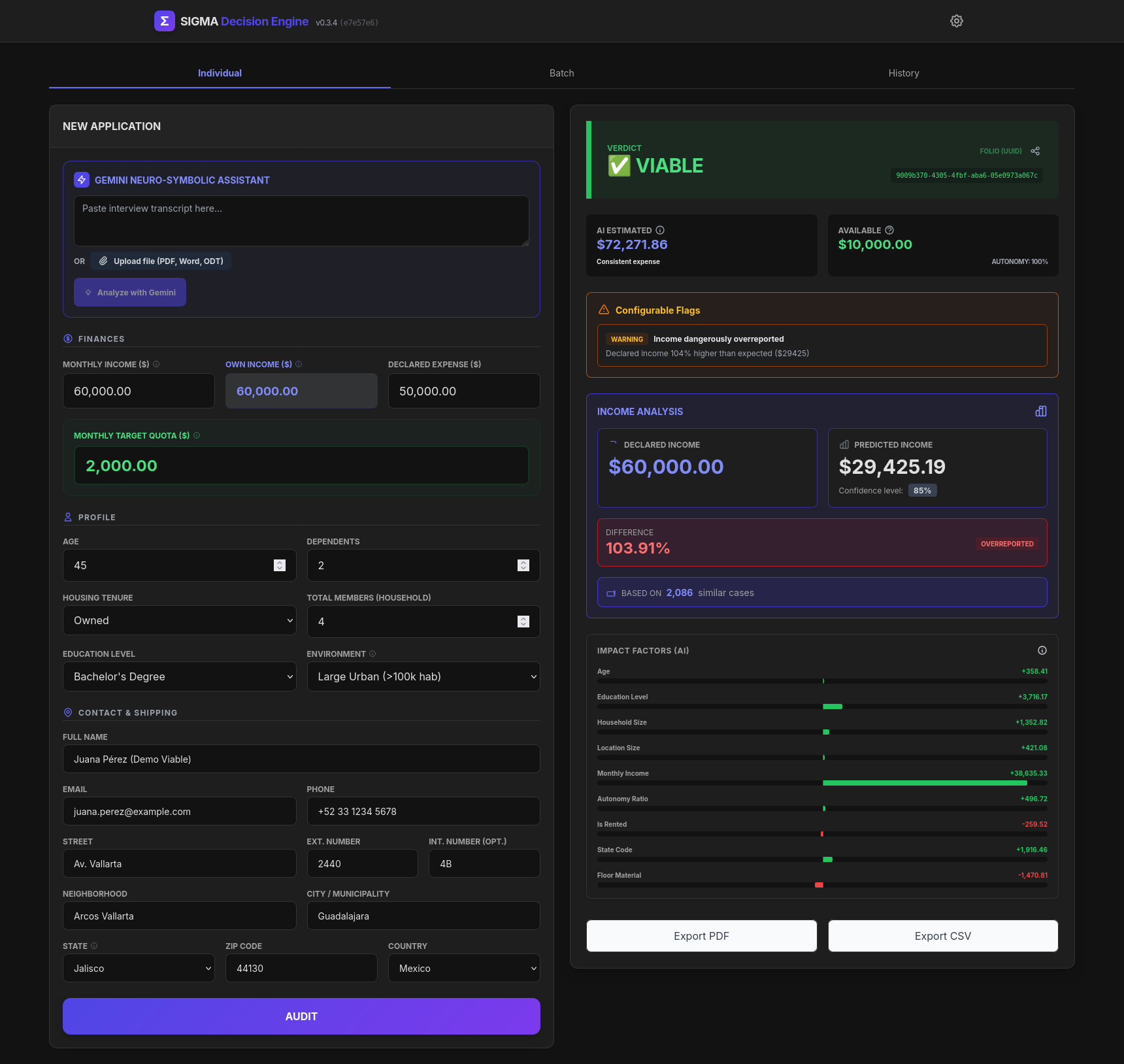
Individual - Viable
-
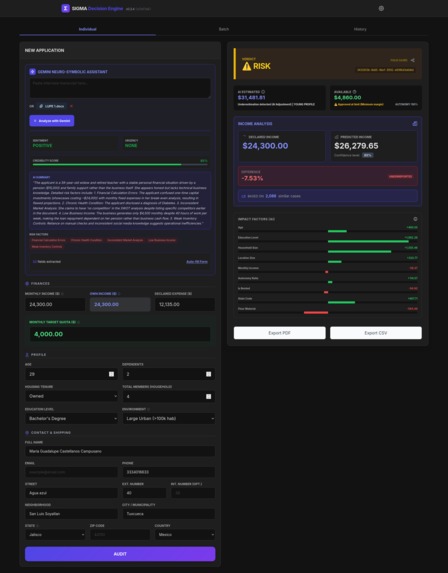
Individual analyzed by Gemini - Risk
-
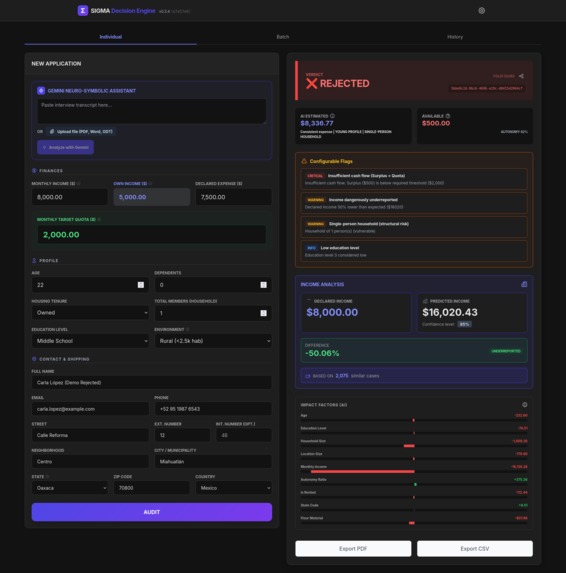
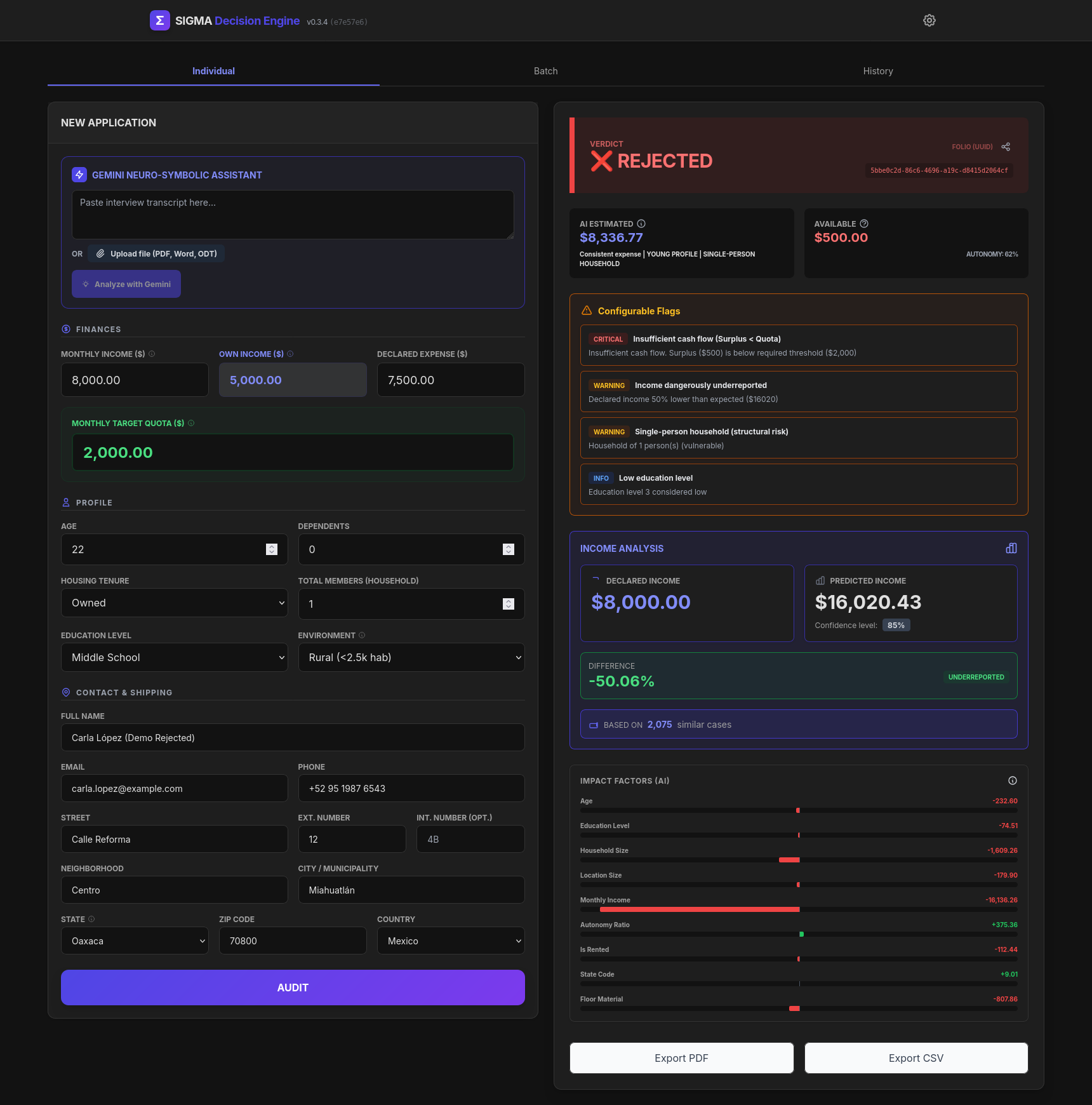
Individual - Rejected
-
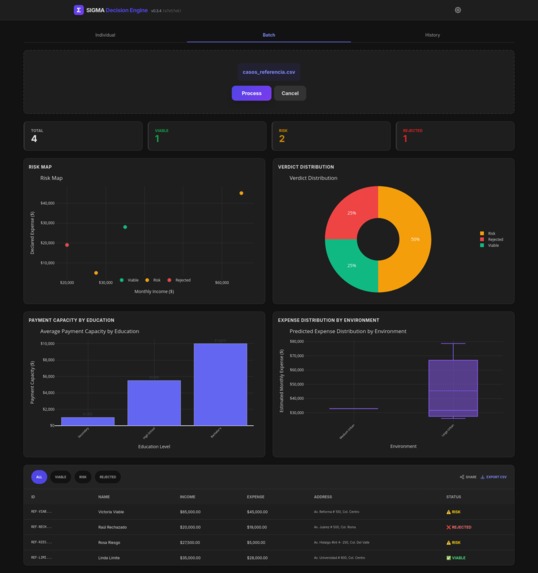
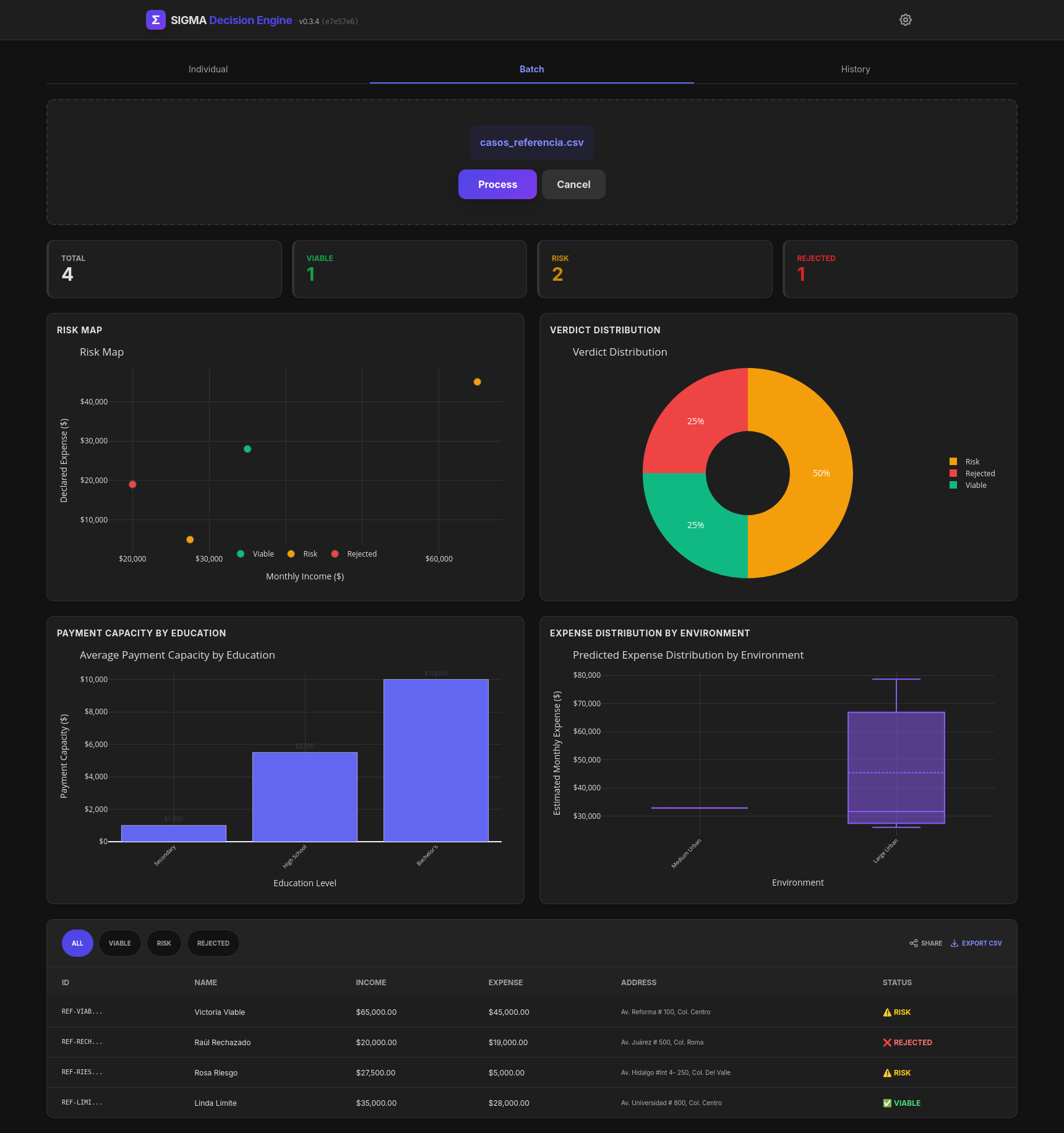
Batch processing
-
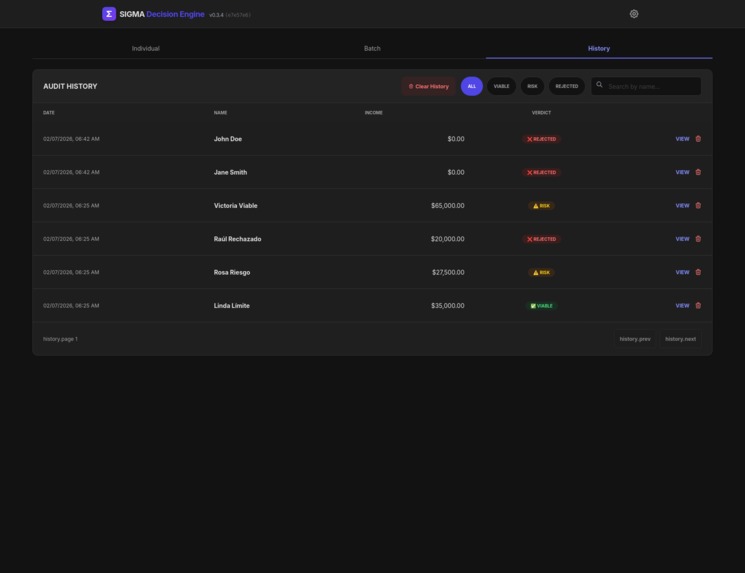
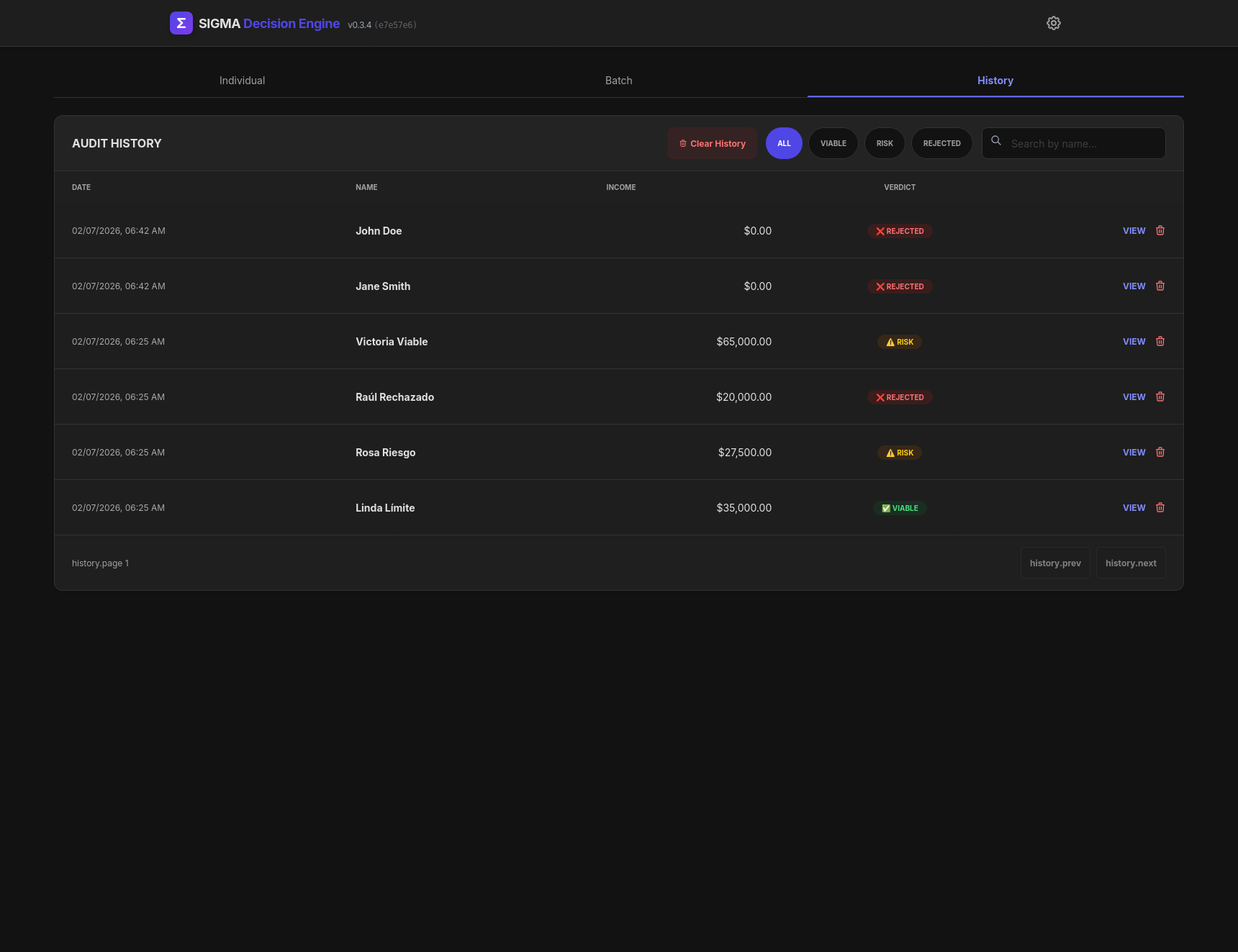
History management
Inspiration
The project began while observing the operations of Impeler Apoyo Social A.C., an NGO in Mexico providing microcredits to women. We noticed their credit evaluation relied heavily on manual Excel sheets and subjective intuition—what we locally call the "Ojímetro" (the "eyeball meter"). This process took up to 6 hours per applicant.
This manual process had two fatal flaws: operational fragility (one typo breaks the spreadsheet) and unconscious bias. We were inspired to build Sigma to replace subjectivity with statistical rigor, using the ENIGH 2024 (National Survey of Household Income and Expenditures) as the "Ground Truth" for financial behavior.
What it does
Sigma is a Neuro-Symbolic Decision Engine powered by Google Gemini 3 Pro. It acts as a digital auditor that:
Audits "Truthiness": It compares an applicant's declared expenses against their demographic profile (Income + Education + Geography). Gemini 3 analyzes unstructured interview data to feed the XGBoost model. If declared expenses are statistically impossible (below the threshold), Sigma detects the risk.
Calculates Real Solvency: Instead of accepting the user's optimistic numbers, it imputes the statistical reality to prevent predatory over-indebtedness.
Visualizes Risk: It generates interactive, mobile-first dashboards (powered by Plotly) allowing field officers to explore risk factors in real-time.
How we built it
As reflected in our v0.1.0 Release, we architected Sigma not just as a script, but as a production-grade cloud-native application:
The Neuro-Cortex: We utilize Gemini 3.0 Pro to ingest unstructured interview transcripts (PDF/Text) and extract structured sociodemographic data. Its massive context window allows us to process entire family histories in a single shot.
The Symbolic Core: Python 3.14 (Target) running XGBoost for inference, wrapped in a high-performance FastAPI backend.
The Face: A reactive Vue.js 3 + TailwindCSS frontend that handles batch processing of Excel files.
The Infrastructure: We rejected "works on my machine." We built a strictly FHS-compliant container system using Podman (Rootless) on a Fedora 43 base.
Security: We implemented a dedicated system identity (User:
sigma, UID: 1000) to ensure the application runs with least privilege.
Challenges we ran into
1. The "Poverty vs. Fraud" Dilemma (The Grey Zone)
The hardest part wasn't predicting spending, but defining the threshold between "Extreme Frugality" and "Under-reporting."
The Problem: If a woman spends very little, is she a financial wizard or is she hiding expenses?
The Solution: We moved away from a binary "True/False" flag. Instead, we calculated a Dynamic Credibility Interval using the model's Mean Absolute Error (MAE). We set a flexible lower bound () that statistically accepts 86% of deviations as "thrifty behavior," only flagging the statistical outliers as "Risk."
2. The "Negative Spending" Singularity
Our 1.5-Sigma tolerance worked perfectly for the middle class, but broke down at the bottom of the pyramid.
The Problem: For extremely low-income profiles, the mathematical subtraction () resulted in negative spending limits, which is physically impossible.
The Solution: We had to engineer a Hybrid Logic Gate in the inference engine. We implemented a "Vital Minimum" floor (derived from the basic food basket cost) that overrides the AI's output when the math drifts into unreality.
3. Unlearning Systemic Debt (Data Bias)
We realized that if we trained the AI on everyone, it would learn that being in debt is "normal."
The Problem: A large portion of the ENIGH dataset includes households operating at a deficit. If the AI learns from them, it normalizes bad financial health.
The Solution: We implemented a "Sustainability Filter" during training. We strictly trained the XGBoost model only on households where . This forced the AI to learn patterns of financial health, setting a "Gold Standard" for applicants to match, rather than just an average standard.
Accomplishments that we're proud of
Hyper-Efficiency: We successfully reduced the credit evaluation lifecycle from 6 hours to under 45 seconds, effectively multiplying the workforce capacity by 400x thanks to Gemini's speed.
Full Stack Release (v0.1.0): We successfully shipped a complete system—from the XGBoost math core to the Vue.js frontend—in a single, deployable artifact.
Interactive Visualization: We successfully migrated from static, server-side Matplotlib images to client-side Plotly JSONs, creating a responsive experience that works on the smartphones of field officers.
DevOps Maturity: We implemented a robust
GNUmakefileand OpenTofu integration, proving that a hackathon project can have enterprise-grade CI/CD standards.
What we learned
We learned that Data Science is only half the battle; Engineering is the other half. Having a precise model is useless if you cannot deploy it securely. The struggle to fix the build contexts and permission sets taught us that a robust directory structure and adherence to standards (like FHS) are just as important as the algorithm itself.
What's next for Sigma
We are moving to Phase 2: Expanded Neuro-Symbolic Integration.
We are already leveraging Gemini 3.0 Pro to extract structured data from unstructured interview transcripts. Our next phase involves expanding this capability to ingest additional document types (business plans, financial statements) and automating the entire end-to-end pipeline—from document upload to risk assessment—creating a fully autonomous credit evaluation system.
Built With
- fastapi
- fedora
- gnu-make
- opentofu
- pandas
- plotly
- podman
- python
- scikit-learn
- tailwind-css
- vue.js
- xgboost

Log in or sign up for Devpost to join the conversation.