-
-

home page
-

camera
-
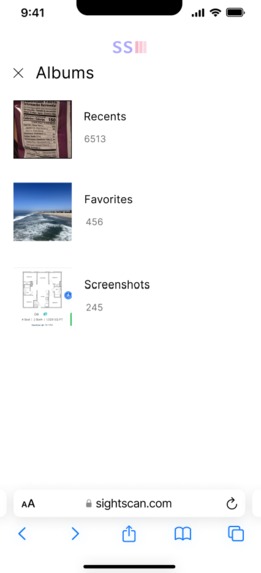
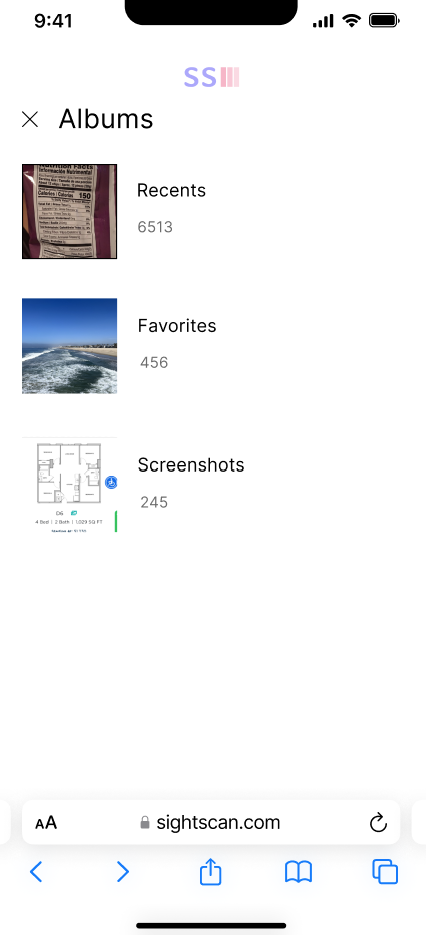
phone gallery to select image
-

selected image
-
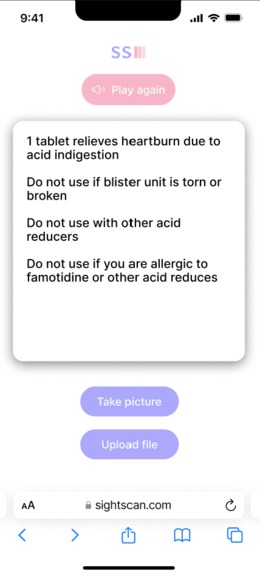
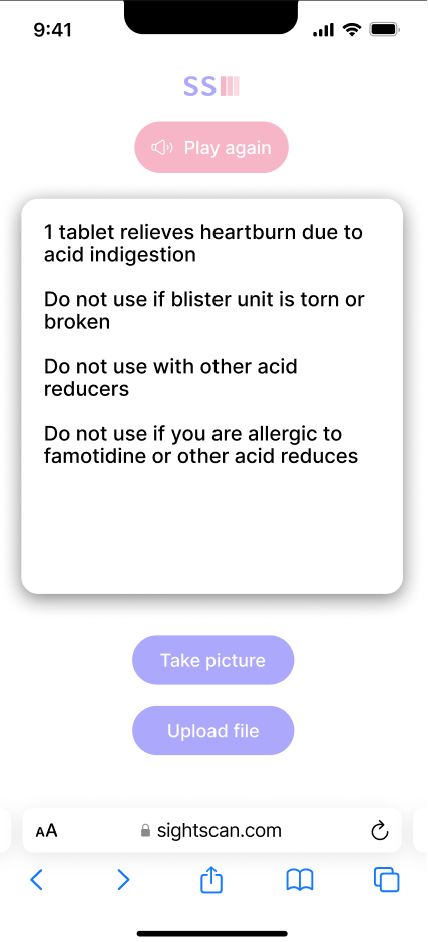
output text and TTS audio



👀 Inspiration
SightScan was born out of the desire to empower individuals with visual impairments or reading difficulties to access essential information on food, medicine, and other labels. Recognizing the barriers faced by many in understanding critical details, our team embarked on a mission to create a solution that enhances accessibility and independence in daily life.
🤖 What it does
SightScan extracts text from images of product packaging and labels to provide descriptions of ingredients, dosage instructions, and other important details. It offers text-to-speech functionality for accessibility and includes a summarization feature for easier understanding. Our goal is to modestly contribute to improving accessibility and inclusivity for users with varying needs.
👩🏻💻 How we built it
We built SightScan using Vue.js for the frontend to ensure a seamless and interactive user experience. The backend is powered by Python Flask, handling requests, orchestrating data flow, and interfacing with our OCR (Optical Character Recognition) model. This model, trained on diverse datasets, accurately identifies and extracts text from images, enabling our application to deliver reliable results.
❗️ Challenges we ran into
Developing SightScan presented several challenges, including optimizing the OCR model for accuracy and performance, ensuring compatibility across various browsers and devices, and implementing robust error handling and security measures. Additionally, integrating the frontend and backend components seamlessly required meticulous coordination and troubleshooting.
🌟 Accomplishments that we're proud of
We're proud to have developed a functional prototype of SightScan within the tight constraints of a 10 hour hackathon, demonstrating the feasibility and potential impact of our solution. Overcoming technical hurdles, refining the user interface for accessibility, and achieving satisfactory performance with the OCR model are significant accomplishments for our team.
📝 What we learned
Through the development of SightScan, we gained valuable insights into frontend and backend integration, image processing techniques, and the challenges of designing for accessibility. We also deepened our understanding of OCR technologies and learned strategies for optimizing their performance in real-world applications.
🔮 What's next for SightScan
Looking ahead, we envision expanding SightScan's capabilities to support additional languages, improving the accuracy and speed of text extraction through ongoing refinement of the OCR model to adapt to conditions like distorted text, and enhancing accessibility features based on user feedback. Furthermore, we aim to explore opportunities for collaboration with organizations dedicated to promoting accessibility and inclusivity.

Log in or sign up for Devpost to join the conversation.