-
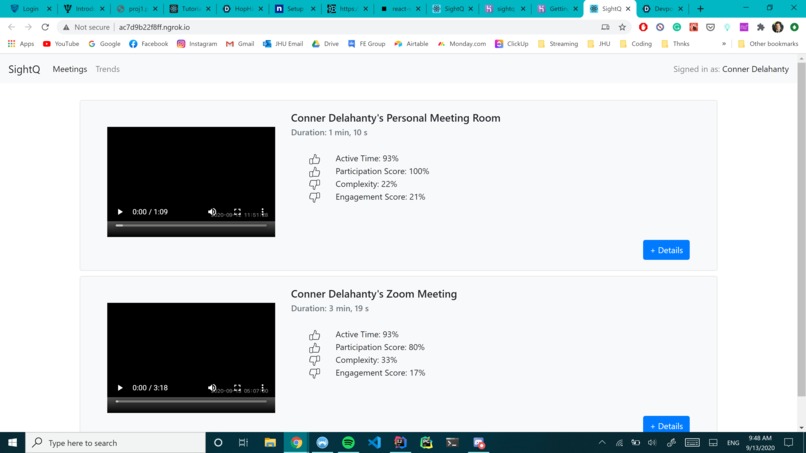
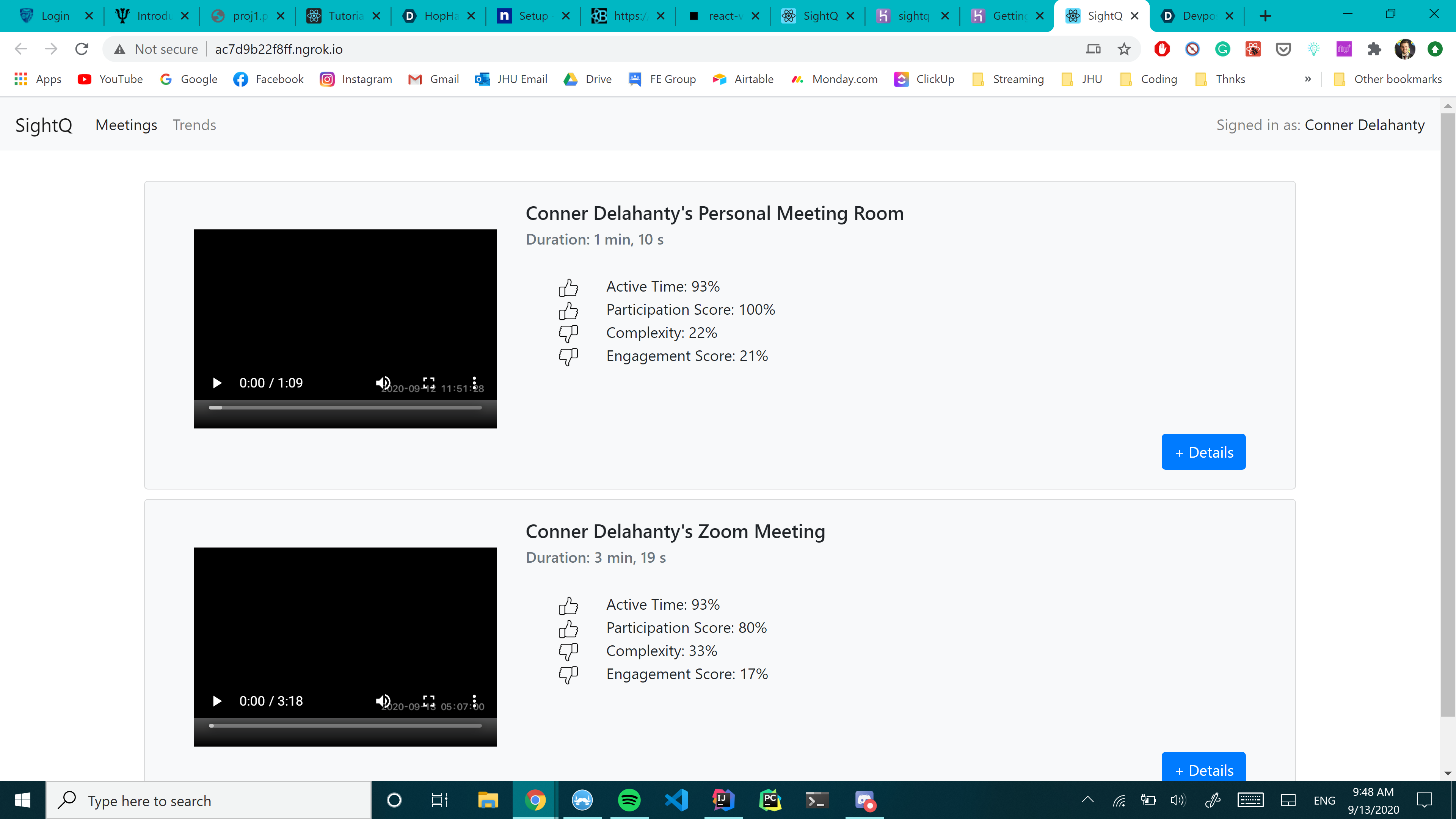
The main page, with an overview of all your analyzed meetings
-
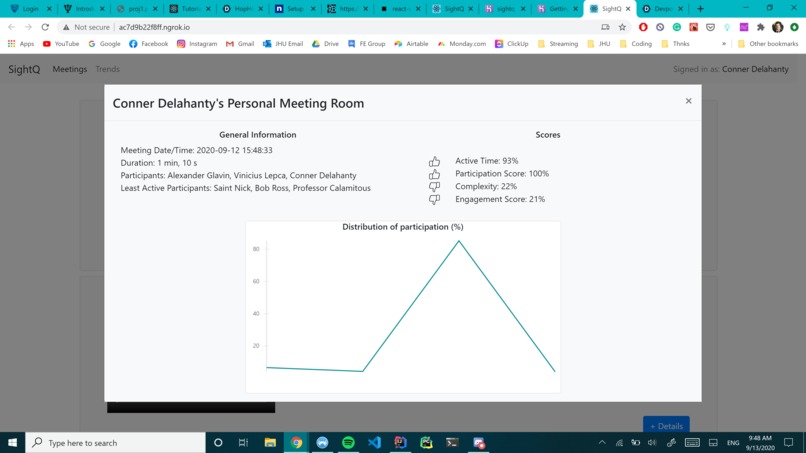
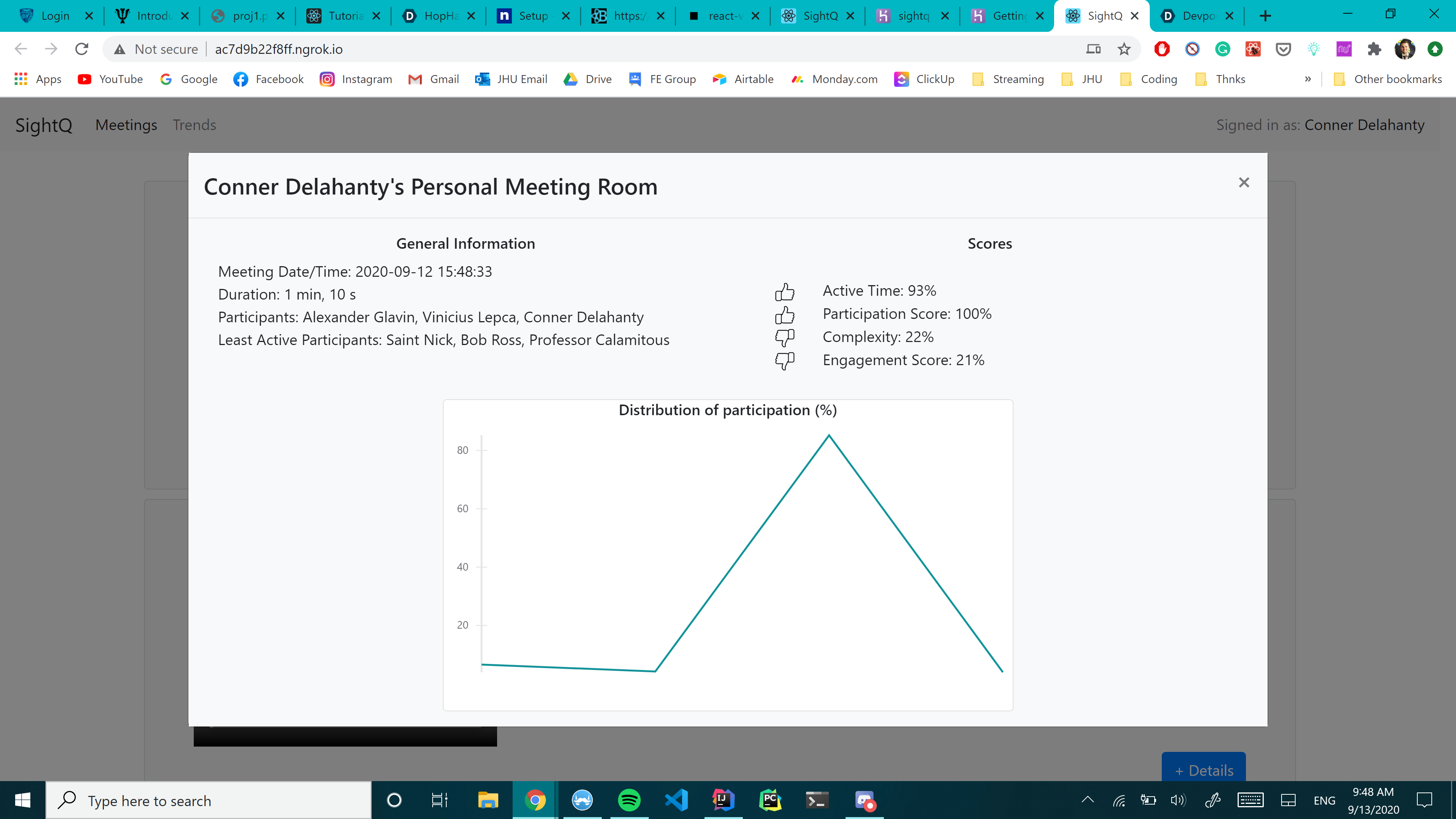
A detailed view of an analyzed meeting
-
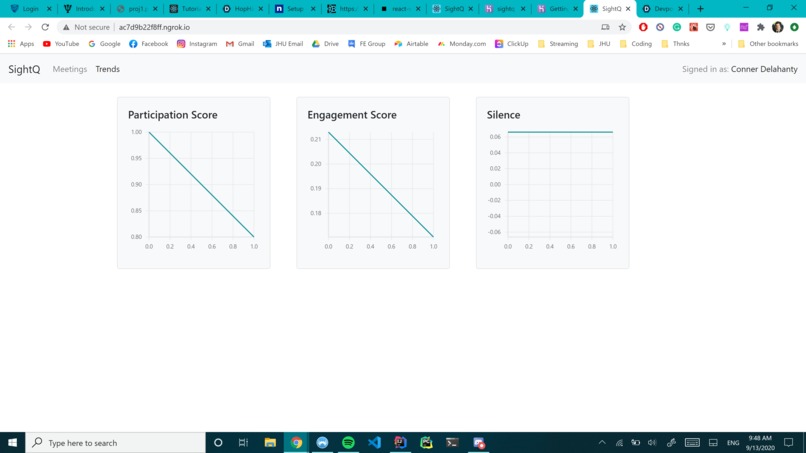
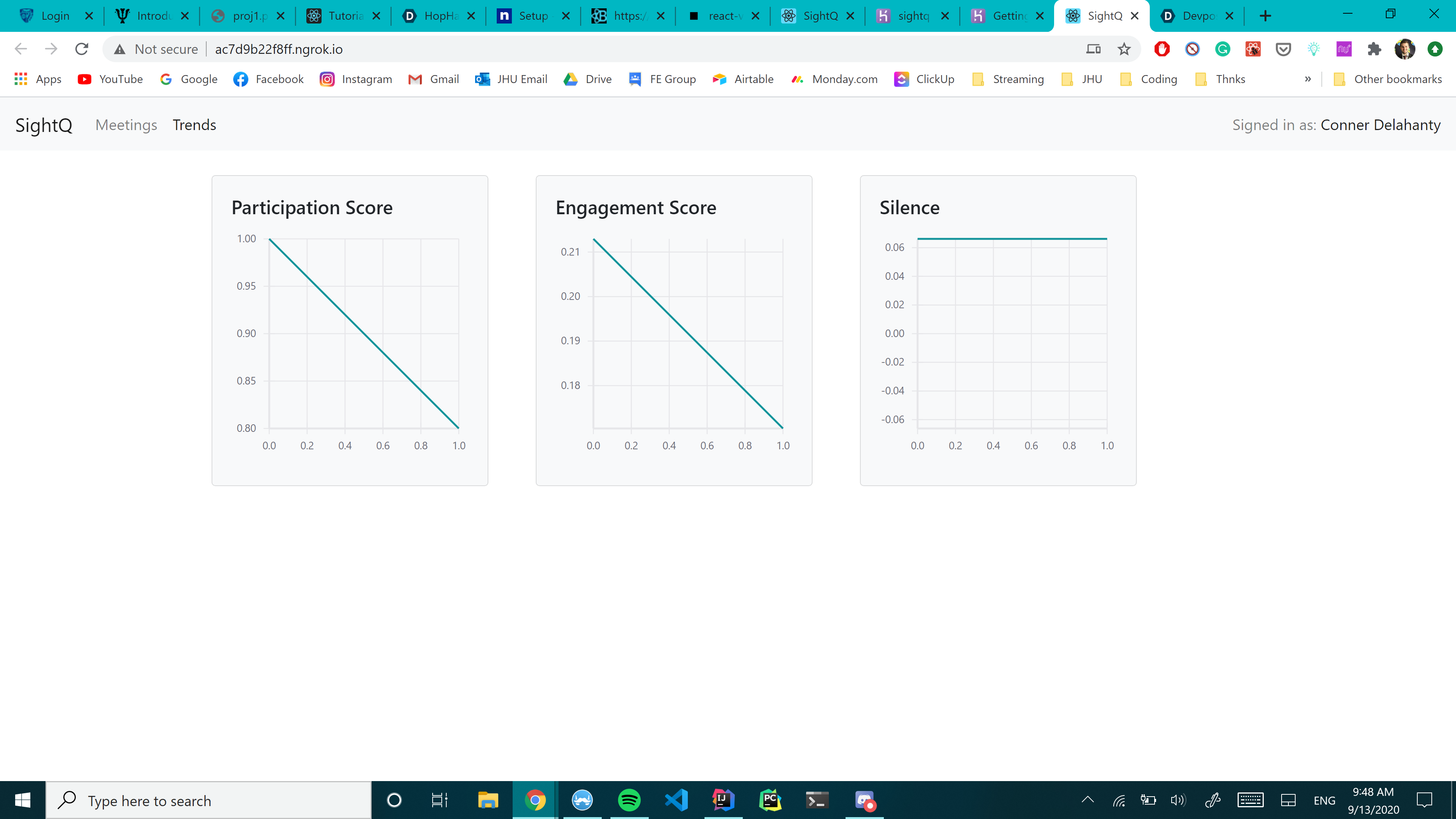
The trends page, where your historic scores can be found
-

How we built SightQ (general flow chart)
-

What we used to build SightQ


Our Inspiration and Mission
There's no denying Covid-19 has ushered in an era of working from home whose effects will be felt for a long time. Virtual meeting software has quickly become the norm, and Zoom has established itself as an leading platform for online communication. SightQ incorporates more data analytics for Zoom meetings to enable meeting hosts to conduct better meetings, whether that be by improving engagement, adapting presentation styles, or decreasing wasted time.
What SightQ does
SightQ leverages a linked Zoom sign-in along with custom data analysis in creating a web portal for instructors and business people to view analysis. This will provide insight into effectiveness of meetings, as well as giving suggestions for future improvement.
How we built it
The technical aspect was based on how SightQ listens on an authenticated user's Zoom cloud for newly posted recordings. Data from these recordings are read with a webhook and pushed to a python (flask) server. Data are then colsolidated, using sampling, statistical, and machine learning technologies (Google Cloud) for gain insights such as meeting quality (read through Google Cloud NLP transcription), audience participation (through dialog and length), awkward delays, and distribution of speaking. These are all consolidated, read by the React front-end and beautifully displayed on the front end, and shipped to Heroku for deployment.
The logistical aspect was based on a Google Forms survey completed by zoom meeting hosts (predominantly teachers or corporate employers), which allowed us to gain insight into which aspects of virtual meeting analytics to focus on, as we got feedback from people who frequently conduct these meetings.
Challenges we ran into
This is a common theme (as we elaborate on it more later on), but gathering trial data and creating mathematical models were difficult due to the time constraint. We still had relatively large sample sizes, but not nearly as large as desired for optimal data mining.
Accomplishments that we're proud of
We are extremely proud on the relatively large sample set of survey participants we were able to get with very limited time, as it was more than enough to provide crucial data that we used for our analytical implementation.
Likewise, we are proud about out ability to create and implement mathematical models for various analytics. We executed countless trials in order to determine effective formulas with logistic growth among other techniques (although we still are looking towards further improving them) where we were able to employ.
What we learned
Some of our prior assumptions were actually proven false based on the survey data, as we learned most hosts actually don't prioritize face-to-face discussion. Engagement and participation were expected to have high significance, but we underestimated how much more valued these metrics were over others. We also learned some new frameworks and technologies. Some of us were doing web development for the first time, while others were trying out Bootstrap. We also got some experience with the Zoom API and the Google Cloud Machine Learning API.
What's next for SightQ?
The primary focus for improvement revolves around the mathematical modeling for the analytics. We're hoping to gather much more survey data to gain even more insight into zoom hosts' thought processes and find additional metrics that could be created. With the limited sample of 22 participants we already saw new ideas, so we can't wait to see what other metrics people can come up with. Likewise, we would like to collect more trial data in order to optimize the mathematical models already implemented, as this is always best achieved with large data sets to allow for efficient noise filtering, higher order regressions, etc. Additionally, we would like to further develop our frontend visualization and support more users, allowing them to authenticate using their Zoom account, which will take a more detailed approach to cybersecurity.


Log in or sign up for Devpost to join the conversation.