Inspiration
Every QA engineer knows the frustration: you run your automated tests, they all pass, and then a user reports that a button is hidden behind an overlapping modal, a screen reader can't identify a login field, or the page takes 4 seconds to respond on a slow connection. Traditional tools test what they're told to test. They don't see.
I wanted to build a QA agent that works the way a human tester does — by actually looking at the screen, understanding what's there, and deciding what to do next. Not from a script. Not from a recorded sequence. From a live visual understanding of the application.
Gemini 2.5 Flash's multimodal capability — the ability to reason over a screenshot alongside structured DOM context — made this possible in a way that wasn't feasible before.
What it does
SightPilotQA is an autonomous QA agent that navigates a live web application and produces a structured quality report covering four dimensions simultaneously:
Visual / UI Defects — Gemini analyzes each screenshot and flags real visual issues: overlapping elements, clipped text, broken layouts, displaced components, abnormal spacing. These are things no DOM-based tool can detect — only something that can see the rendered page.
Accessibility Validation — At each step, the agent runs a dual-layer accessibility audit. DOM-level analysis catches missing aria-label attributes and placeholder-only inputs. axe-core (Deque's WCAG engine) catches deeper violations — color contrast failures, unlabeled interactive elements, and more.
Business Flow Validation — The agent autonomously navigates a login-to-catalog journey without any hardcoded steps. Gemini decides when the business goal (reaching the main catalog) has been achieved.
Performance Measurement — Every browser action is timed. Slow clicks, sluggish page transitions, and high-latency interactions are flagged with millisecond precision.
All findings are deduplicated, ranked by severity (Critical / Major / Minor), and presented in a clean dashboard with a consolidated Final QA Report table.
How we built it
The system follows a continuous Observe → Think → Act → Validate loop:
- Playwright opens the target application and auto-handles login
- A full-page screenshot is captured at each step
- DOM hints are extracted (inputs, buttons, links, visible text, current URL)
- axe-core runs a WCAG accessibility scan on the live page
- The screenshot + DOM context is sent to Gemini 2.5 Flash as a multimodal prompt
- Gemini returns a structured JSON decision: visual issue detected, action to take (click / type / scroll / finish), and the target element
- Playwright executes the action and measures latency
- Findings are accumulated, deduplicated across steps, and compiled into a final report
The agent is fully autonomous — it decides when to stop based on whether the business goal has been met, not a fixed script.
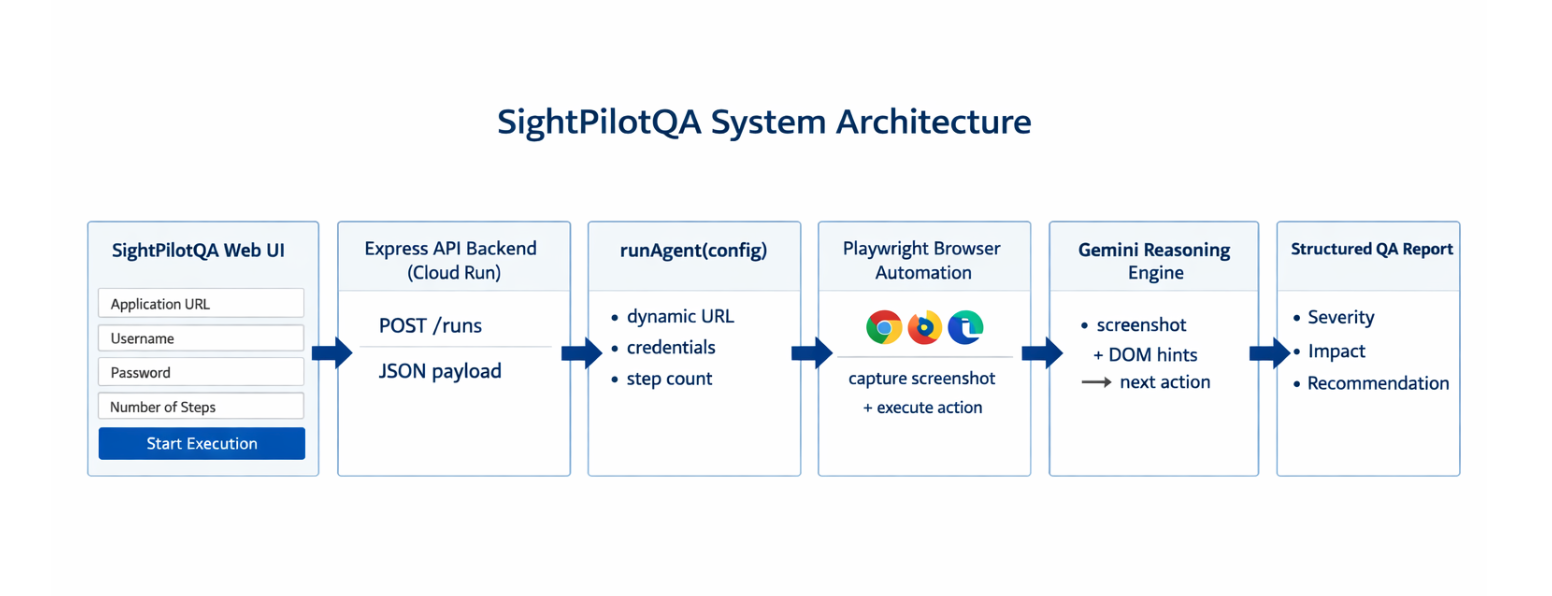
Architecture
The agent runs a continuous loop — Observe → Think → Act → Validate — across every step of the user journey.
Request flow: Browser UI → POST /runs → Express Server (Cloud Run) → Agent Loop (runner.ts)
Inside the agent loop, three engines run in parallel at every step:
Playwright — captures full-page screenshots, executes browser actions, measures action latency Gemini 2.5 Flash — receives screenshot + DOM context as a multimodal prompt, returns a structured JSON decision: visual defect detected, action to take, and why axe-core — runs a live WCAG accessibility scan on the rendered page All findings feed into a single Final QA Report covering: UI defects · Accessibility violations · Business flow status · Performance metrics
Tech Stack
- TypeScript · Node.js · Express
- Playwright
- Gemini 2.5 Flash (
@google/genaiSDK) - axe-core /
@axe-core/playwright - Google Cloud Run
- Google Cloud Build
Challenges we ran into
Getting Gemini to be a reliable decision engine, not just a classifier. The multimodal prompt had to simultaneously ask Gemini to detect visual defects, interpret accessibility context, track business flow progress, and return a single structured JSON action — without hallucinating actions or getting stuck in loops. Extensive prompt engineering was required to make this stable.
axe-core + Playwright integration. The @axe-core/playwright library requires pages created via browser.newContext() rather than browser.newPage(). This caused silent scan failures until the root cause was identified and fixed.
Platform-specific dependencies breaking Cloud Build. fsevents (a macOS-only file watcher) was locked in package-lock.json as a non-optional dependency. This caused npm ci to fail during Linux-based Cloud Build. The fix required moving it to optionalDependencies and using --omit=optional during the container build.
Deduplication across a multi-step loop. The same accessibility violation (e.g. "missing aria-label on password input") was being detected at every step. A content-based deduplication pass was added to ensure each unique finding appears exactly once in the final report.
Accomplishments that we're proud of
- Built a genuinely agentic QA system where Gemini acts as the decision-making core, not just a classifier
- Combined four QA disciplines (visual, accessibility, functional, performance) into a single autonomous loop — something no existing open-source QA tool does
- The agent correctly identifies WCAG violations, real visual layout instability, and business flow completion across completely different web applications without any app-specific configuration
- Successfully deployed on Google Cloud Run with automated container builds via Cloud Build
What we learned
- Gemini 2.5 Flash's vision capability is genuinely powerful for UI reasoning — it correctly identifies layout instability, overlapping elements, and visual anomalies that no DOM inspection could catch
- Prompt structure matters enormously for agentic reliability — separating concerns (Visual QA → Accessibility QA → Business goal → Action rules) into explicit numbered steps produces far more consistent JSON output
- Combining AI reasoning with deterministic tools (axe-core for WCAG, Playwright for execution timing) is more robust than trying to do everything with AI alone
What's next
- Multi-page journey testing — follow full user flows beyond login (checkout, form submission, multi-step wizards)
- Visual regression baselines — compare screenshots across runs to detect regressions automatically
- Severity analytics dashboard — trend critical/major/minor counts across deployments
- Exportable enterprise reports — PDF/CSV output for QA teams
- Support for more authentication patterns — OAuth, SSO, token-based flows
Technologies Used
- Gemini 2.5 Flash (Google GenAI SDK /
@google/genai) - Google Cloud Run
- Google Cloud Build
- Playwright
- axe-core /
@axe-core/playwright - TypeScript / Node.js
- Express
Built With
- gemini
- node.js
- playwright
- typescript

Log in or sign up for Devpost to join the conversation.