-
-
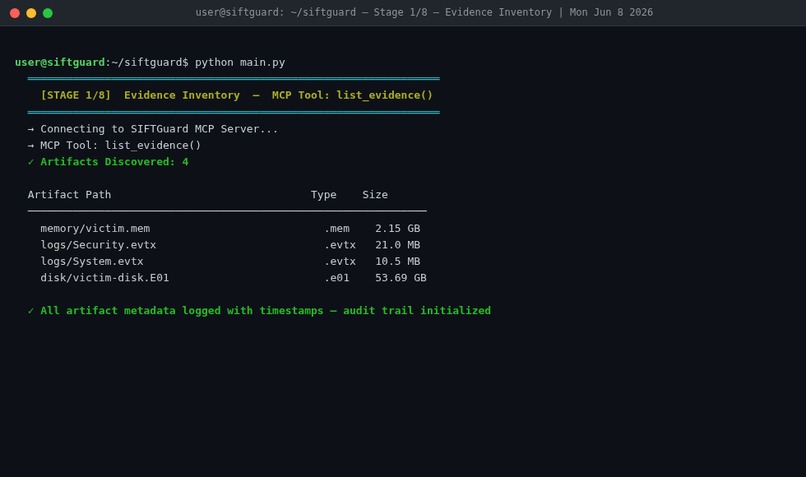
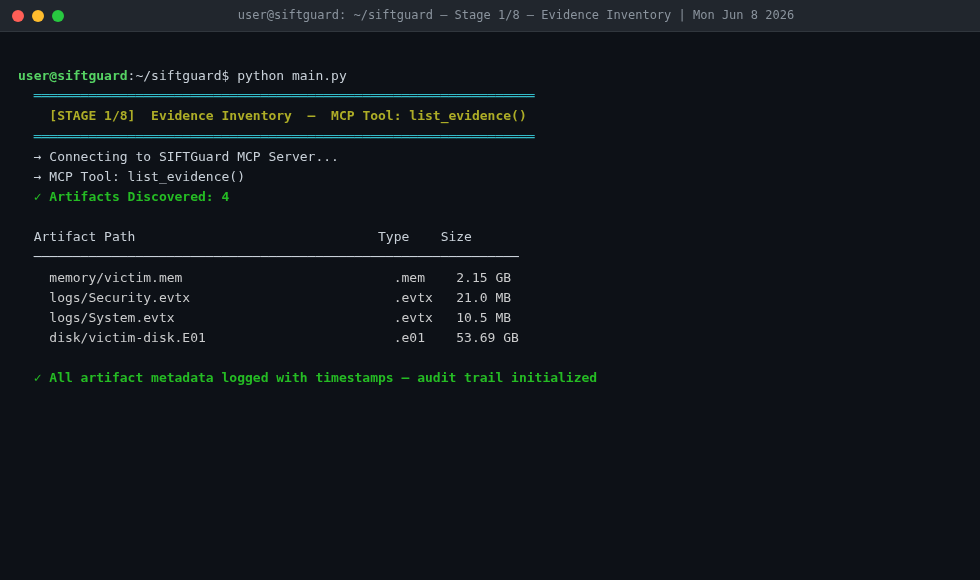
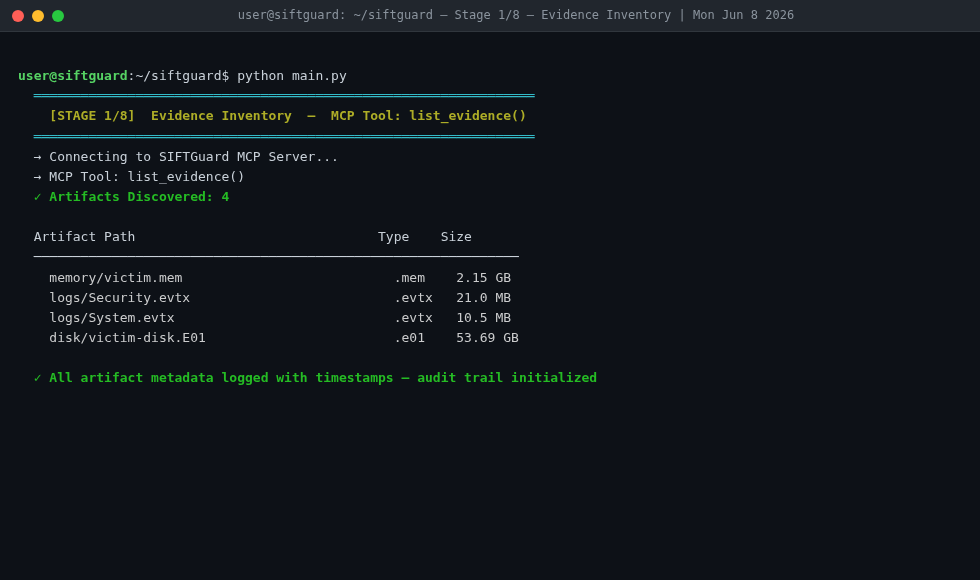
Stage 1/8 — Evidence Inventory
-
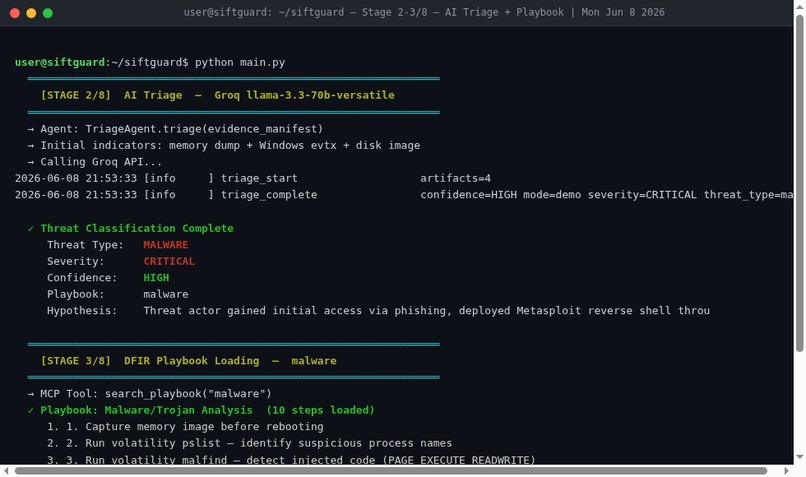
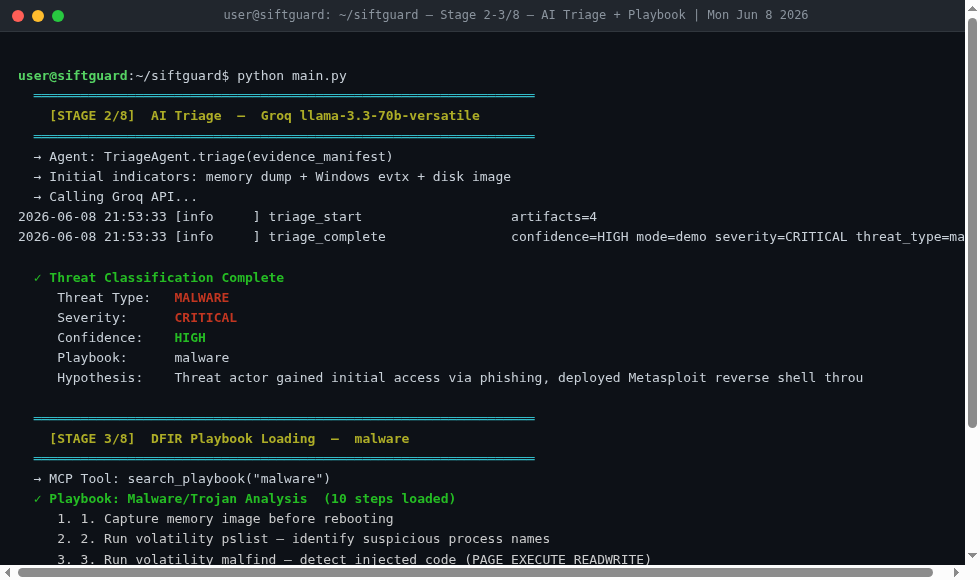
Stages 2–3/8 — AI Triage + Playbook Load
-
Stage 4/8 — Self-Correction Event
-
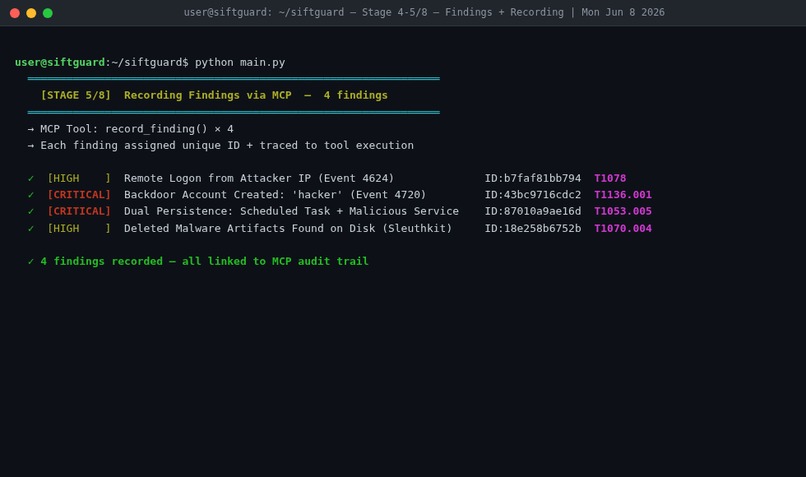
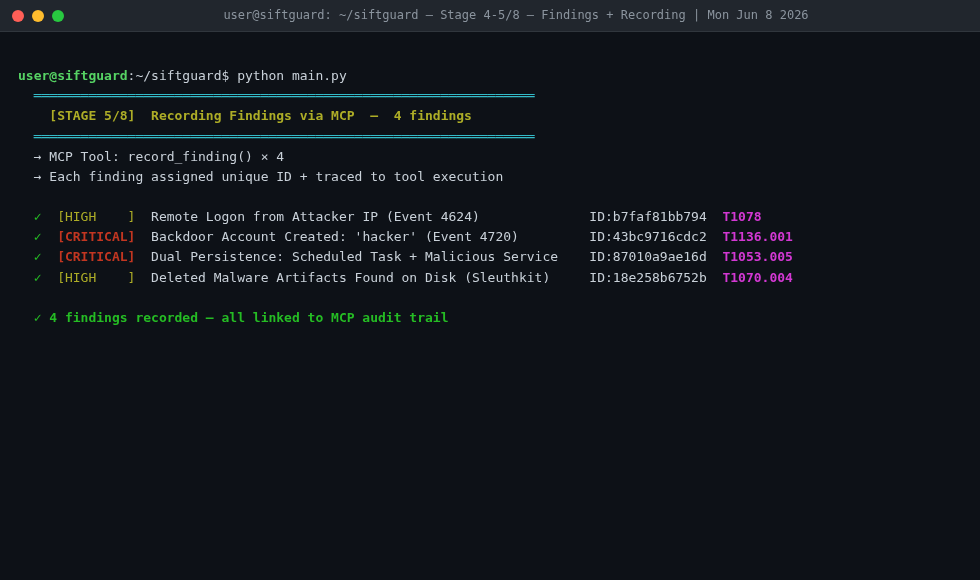
Stage 5/8 — Deep Analysis + Finding Recording
-
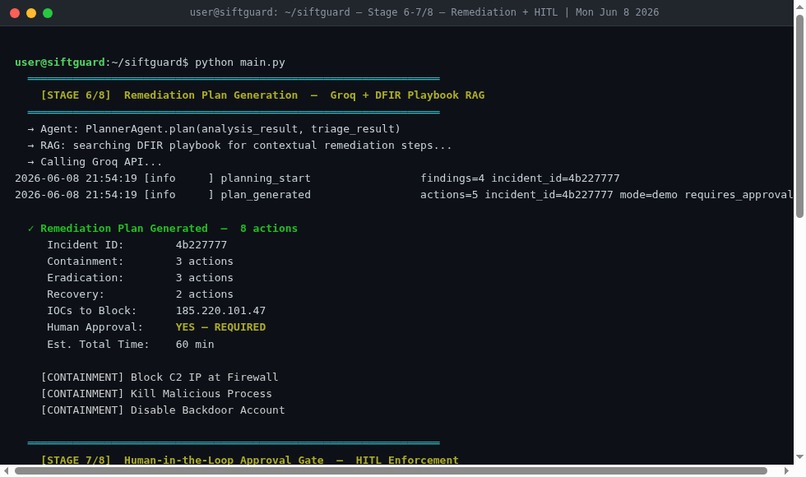
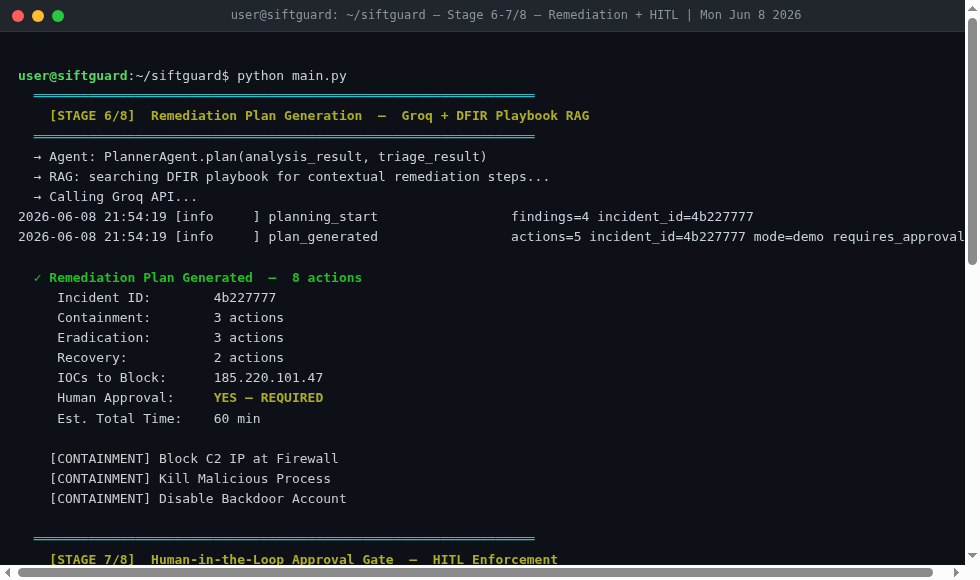
Stages 6–7/8 — Remediation Plan + HITL Gate
-
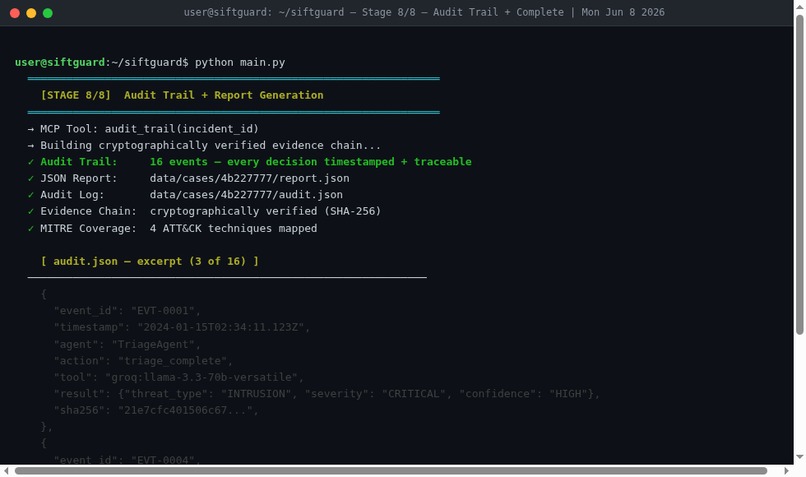
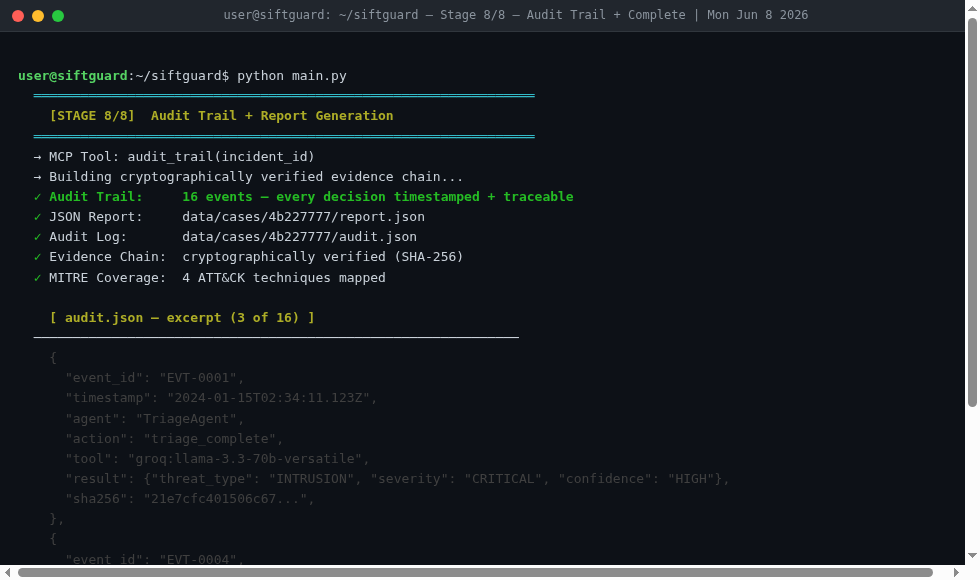
Stage 8/8 — Audit Trail + Investigation Complete
Inspiration
I've been fascinated by DFIR work for a while - the way a good analyst can reconstruct an entire attack from scattered artifacts, logs, and memory dumps. But what strikes me every time I dig into incident response tooling is how manual and fragmented the process still is. You have SIFT Workstation - one of the best forensic environments in existence - and yet you're still jumping between volatility commands, grepping EVTX files, running sleuthkit manually, and stitching together findings in your head.
The question I kept coming back to: what if the tools could talk to each other? What if there was a layer that could say "okay, memory analysis flagged a suspicious process - now go check the event logs for related logon activity, then cross-reference the disk image, then build a remediation plan" - without a human manually orchestrating every step?
When I saw the FIND EVIL! 2026 hackathon, specifically the MCP + multi-agent track, it clicked. MCP was literally designed for this - exposing tools as callable functions for AI agents. SIFT Workstation has the best forensic tools. Groq has fast enough inference to run a multi-agent pipeline without it feeling like waiting for a bus. The pieces were all there.
That was the starting point for SIFTGuard.
What it does
SIFTGuard is an autonomous Digital Forensics and Incident Response (DFIR) system. You point it at a case directory containing evidence artifacts - memory dumps, Windows Event Logs, disk images - and it runs a full investigation without you having to issue a single forensic command.
Under the hood, it's a 5-agent pipeline talking to a custom MCP server that wraps SIFT Workstation tools:
Stage 1 - Triage: An AI agent reviews the available evidence and classifies the threat. Ransomware? Lateral movement? Insider threat? It picks the right investigation playbook before any tools run.
Stage 2 - Deep Analysis: The Analyzer Agent calls forensic tools through MCP - volatility3 for memory forensics, python-evtx for Windows Event Log parsing, Sleuth Kit for disk analysis, a custom IOC extractor for pulling IPs, paths, and hashes. Findings get validated and written to a structured case file.
Stage 3 - Self-Correction: Every tool call is wrapped by a SelfCorrectionAgent. If a tool fails or returns unexpected output, the agent diagnoses the failure, picks an alternative strategy, and retries autonomously - logging the correction event to the audit trail. This runs without any human intervention.
Stage 4 - Remediation Planning: A PlannerAgent reads the confirmed findings and generates a prioritized containment and eradication plan using RAG over DFIR playbooks - with Groq powering the reasoning.
Stage 5 - Human-in-the-Loop Gate: Before anything gets executed, the ExecutorAgent surfaces the plan for human approval. The HITL gate is intentional and non-negotiable - autonomous investigation, not autonomous execution.
The output is a structured findings file, a full JSON audit trail of every tool call and agent decision, and a human-readable investigation report.
How we built it
The architecture decision that shaped everything else: build a purpose-built MCP server instead of using a generic one.
Most MCP server demos wrap a single API or a handful of shell commands. For this to work as a real forensic system, the server needed to expose tiered capabilities - triage tools, deep analysis tools, intelligence tools, and audit tools - with clean interfaces that AI agents could reason about. So I built mcp_server/server.py from scratch: 11 tools organized into three tiers, each with structured input schemas that an LLM can reliably call.
The agent pipeline is orchestrated in orchestrator.py. Each agent is its own module with its own prompt strategy and output schema enforced by Pydantic. The triage agent uses structured output (JSON schema forcing) to ensure it always returns a classifiable threat type, severity, and recommended playbook - no free-form hallucinations that break downstream agents.
The self-correction layer was the most interesting engineering problem. I wrapped every MCP tool call in a retry loop with three strategies: parameter fallback (simplify the command), scope reduction (smaller artifact subset), and graceful degradation (partial result is better than no result). Each correction event gets timestamped and logged - which means the audit trail actually shows the agent's decision-making, not just the final outputs.
For the AI layer, I used Groq's llama-3.3-70b-versatile. The speed matters - a 5-agent pipeline that takes 3 minutes to run is usable; one that takes 30 minutes isn't.
The whole thing runs in DEMO_MODE=true for the hackathon submission, which means tool outputs are deterministic simulations. The actual SIFT binaries (volatility3, Sleuthkit) need a real forensic environment with real evidence artifacts. The pipeline architecture, agent logic, self-correction mechanics, and audit trail are fully functional.
Challenges we ran into
Getting structured output from LLMs reliably. Early versions of the triage agent would return valid JSON 90% of the time and then hallucinate a nested object where a string was expected, breaking the Pydantic validator. The fix was being extremely explicit in the system prompt about schema requirements and adding a retry-with-correction loop specifically for parse failures.
MCP server design for forensic workflows. The MCP spec is flexible, which means you have to make a lot of decisions yourself. What should be a tool versus a resource? How do you handle tools that depend on previous tool output? I ended up designing the server with stateful context - the server knows about the current case directory and evidence paths, so agents don't have to pass full paths in every tool call.
Self-correction that doesn't just loop forever. The SelfCorrectionAgent needed to be smart enough to know when to stop retrying. Three attempts, three distinct strategies, then graceful degradation. Getting the failure diagnosis logic right - figuring out why a tool failed so the retry uses a meaningfully different approach - took more iteration than I expected.
MITRE mapping integration. I built check_mitre as an MCP tool that maps behavioral descriptions to ATT&CK technique IDs. The challenge was deciding where to wire it - at analysis time, or at finding-record time. I ended up integrating it directly into record_finding() so every finding gets auto-enriched with a dynamically resolved technique ID, tactic, and technique name at the moment of recording. That means MITRE coverage applies to any finding the agent produces, not just the pre-seeded scenarios.
Ensuring findings integrity across runs. Early pipeline runs produced duplicate entries in findings.jsonl - the same finding recorded twice across two runs with no deduplication. Fixed by making finding IDs deterministic (SHA-256(title) instead of timestamp-seeded) and adding two-layer deduplication: session-level (title check) and file-level (ID check before append). The audit trail now cleanly reflects unique findings regardless of how many times the pipeline runs.
Accomplishments that we're proud of
The self-correction architecture working autonomously. You can watch in the demo video: a tool call fails, the agent identifies the failure reason, selects a fallback strategy, retries, succeeds, logs the correction, and moves on - all without human input. That's the behavior I set out to build from day one.
The audit trail. Every agent decision, every tool call, every correction event is written to a structured JSON audit trail. In a real forensic investigation, chain of custody and documented decision-making matter as much as the findings themselves. SIFTGuard produces a trail that could actually stand up to scrutiny.
Building a real MCP server for DFIR tooling. There are a lot of MCP demos out there wrapping simple APIs. This one wraps actual forensic tools with tiered capabilities designed for how DFIR workflows actually work.
What we learned
Multi-agent systems need contracts, not just prompts. The most stable part of the pipeline is where I used Pydantic schemas to enforce what one agent can hand off to the next. The least stable parts are where I relied on the LLM to "figure it out." For production systems, every agent boundary needs a schema.
Speed matters for usability. Running 5 agents in sequence could easily take 10+ minutes with a slower model. Groq's inference speed is genuinely what makes this feel like a tool rather than an experiment.
Honest documentation is better for everyone. I was tempted to make the accuracy report look cleaner than it is. The duplicate findings bug, the missing MITRE wiring, the simulated tool outputs - it would have been easy to paper over those. But anyone evaluating a real forensic tool would find those gaps immediately. Documenting them honestly is both more credible and more useful.
MCP is a genuinely good fit for forensic tooling. The ability to expose tools with structured schemas that an LLM can reason about, discover, and call without custom integration code for each one - that's a real capability shift for the kind of multi-tool workflows DFIR requires.
What's next for SIFTGuard
Full SIFT OVA deployment. The pipeline is designed to run natively on the SIFT Workstation - next step is end-to-end validation on a provisioned SIFT OVA instance with real memory dumps, EVTX logs, and disk images, replacing the current simulation layer with live tool output.
Hash extraction and live threat intel. Wire sha256 hash output from Sleuthkit istat into the findings schema, and connect extracted IOCs to live threat intel feeds (VirusTotal, AbuseIPDB) for automated IOC enrichment at investigation time.
Parallel agent execution. Right now the pipeline is sequential. Stages 4 and parts of 5 could run in parallel - memory analysis and log analysis don't depend on each other. That cuts pipeline runtime significantly.
Real HITL interface. The ExecutorAgent currently prints to terminal and reads stdin. A proper web interface for the human approval gate - showing findings, confidence scores, and proposed actions in a readable format - would make SIFTGuard deployable in an actual SOC workflow.
Live case input. Right now evidence paths are configured at startup. A case intake interface that accepts artifact uploads and kicks off the pipeline would make this usable without touching configuration files.


Log in or sign up for Devpost to join the conversation.