What it does
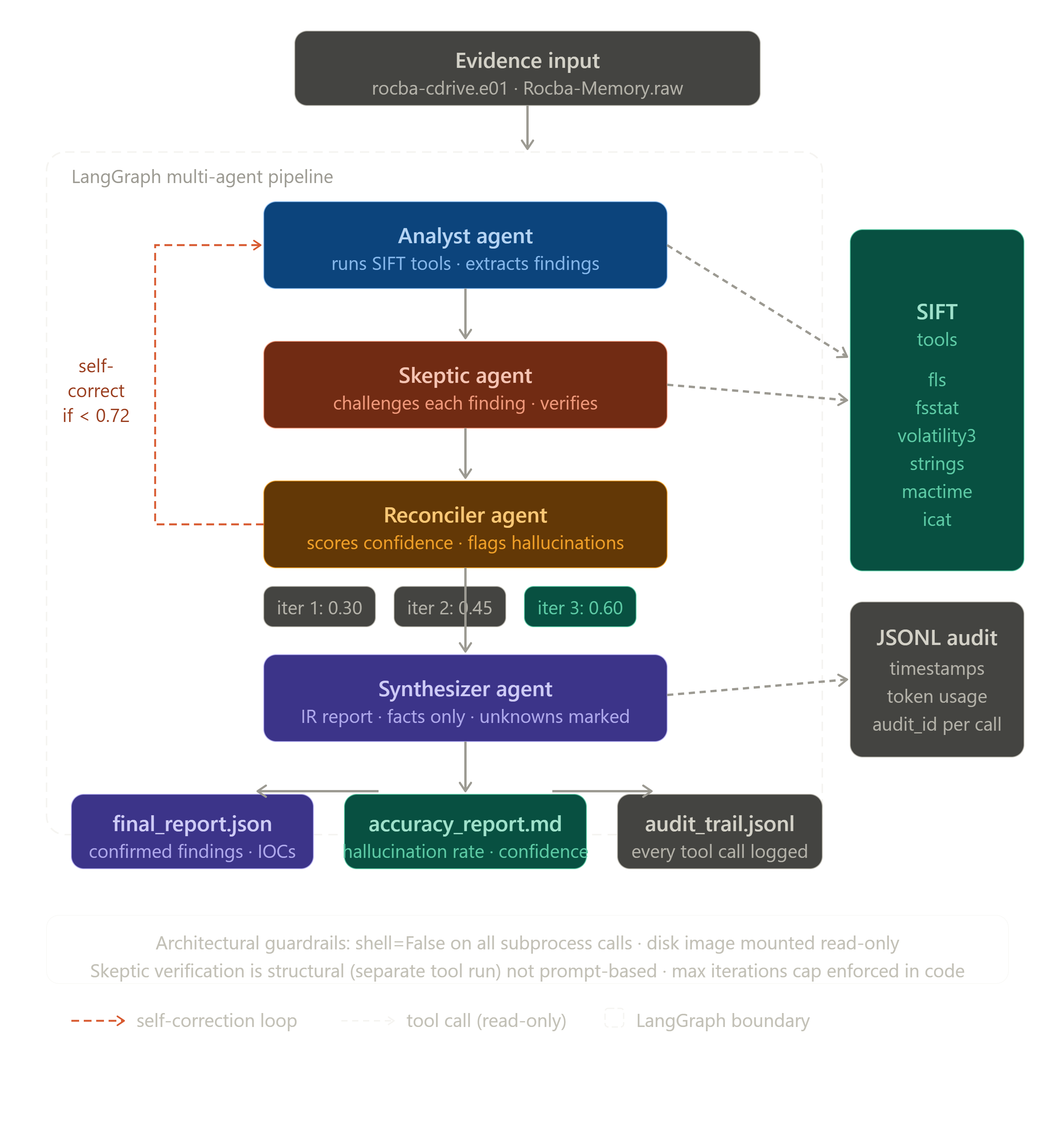
SIFT-Veritas is an autonomous, self-correcting DFIR agent built on the SANS SIFT Workstation. It analyzes forensic disk images using a 4-agent LangGraph pipeline Analyst, Skeptic, Reconciler, and Synthesizer where each agent has a single responsibility and agents check each other's work before anything reaches the final report.
The core problem it solves: Protocol SIFT hallucinates. When confidence is low, it fills gaps with plausible-sounding details rather than admitting uncertainty. SIFT-Veritas measures that hallucination rate, catches bad findings before they reach the report, and self-corrects across iterations until a confidence threshold is reached or explicitly stops and says what it cannot verify.
How I built it
Analyst Agent sequences SIFT tool calls (fls, fsstat, strings) against the disk image and extracts findings as structured JSON.
Skeptic Agent takes every finding and runs an adversarial verification command a separate tool call designed to disprove the finding if it is wrong. This is structural verification, not a prompt instruction.
Reconciler Agent scores overall confidence from 0 to 1, flags HALLUCINATION_RISK findings, and decides whether to self-correct. If confidence is below 0.72, a conditional edge in the LangGraph graph routes back to the Analyst. This loop is enforced in code not in a prompt.
Synthesizer Agent writes the final IR report using only raw tool output, explicitly marking every unknown rather than inferring details.
All tool calls use subprocess.run(shell=False). The disk image is mounted
read-only via ewfmount. Every execution is logged to a JSONL audit trail with
timestamps, agent name, and token usage. Any confirmed finding traces back to
its specific tool call via audit_id.
Challenges
The biggest challenge was the Synthesizer hallucinating a convincing but completely fabricated incident report when confidence was low fake username, fake IP address, sequential fake hashes, invented tool commands. This is documented in the accuracy report as a found failure mode. The fix was architectural: pass only raw tool output to the Synthesizer instead of the agent's interpretation, and require it to mark every unknown explicitly.
What I learned
Hallucination in DFIR follows a predictable pattern: when the model cannot verify something, it fills the gap with plausible-sounding details rather than admitting uncertainty. The fix is not a better prompt it is giving the Synthesizer less interpretive latitude and more raw evidence. An AI that says "I found a deleted PST and a drivedownload artifact, origin unknown" is more valuable to a responder than one that invents a complete attack chain.


Log in or sign up for Devpost to join the conversation.