-
-
architecture_diagram
-
-
-
-
-
-
-
-
Inspiration
We kept reading about AI agents hallucinating during forensic analysis. Protocol SIFT connects Claude to 200+ SIFT Workstation tools through MCP, and it works - but it also makes things up. A fabricated registry path here, a timestamp that never existed there. In incident response, that's not just wrong. It sends responders chasing evidence that doesn't exist while the actual threat keeps moving.
The standard fix everyone reaches for is more LLM reasoning. Self-reflection, multi-agent debate, chain-of-thought verification. But that's just adding more surface area for hallucination. Every additional LLM call is another chance to confidently fabricate something.
We asked a different question: what if we caught hallucinations with code instead of more AI?
What it does
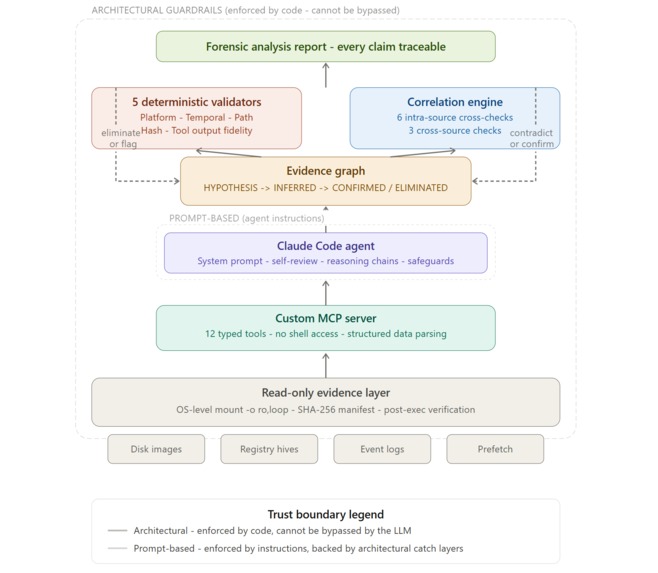
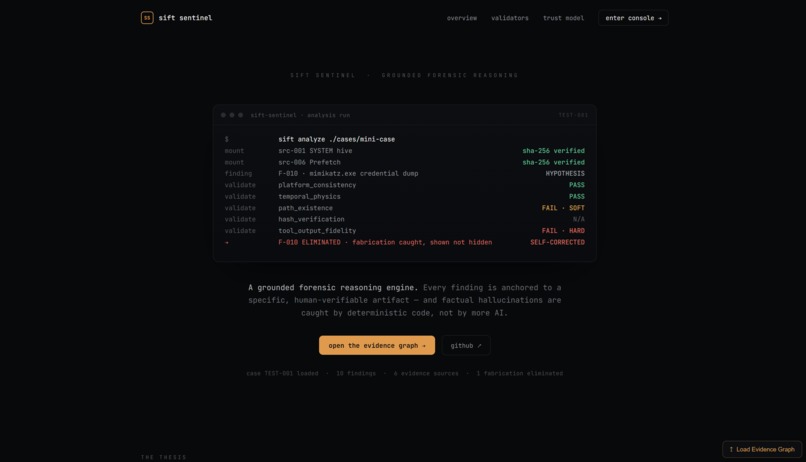
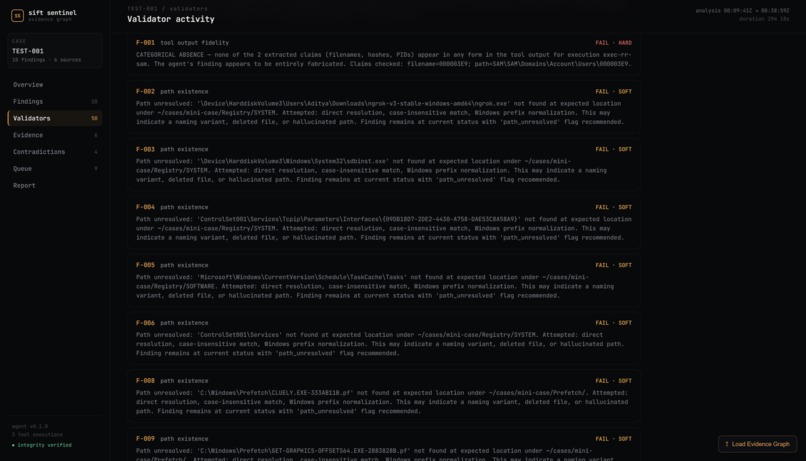
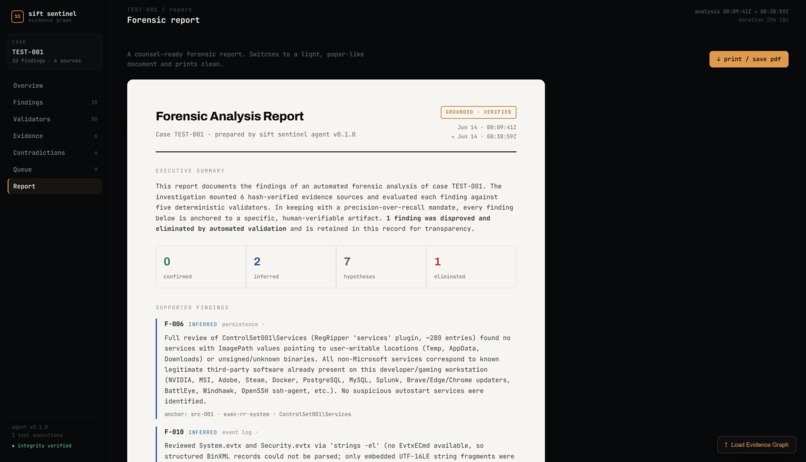
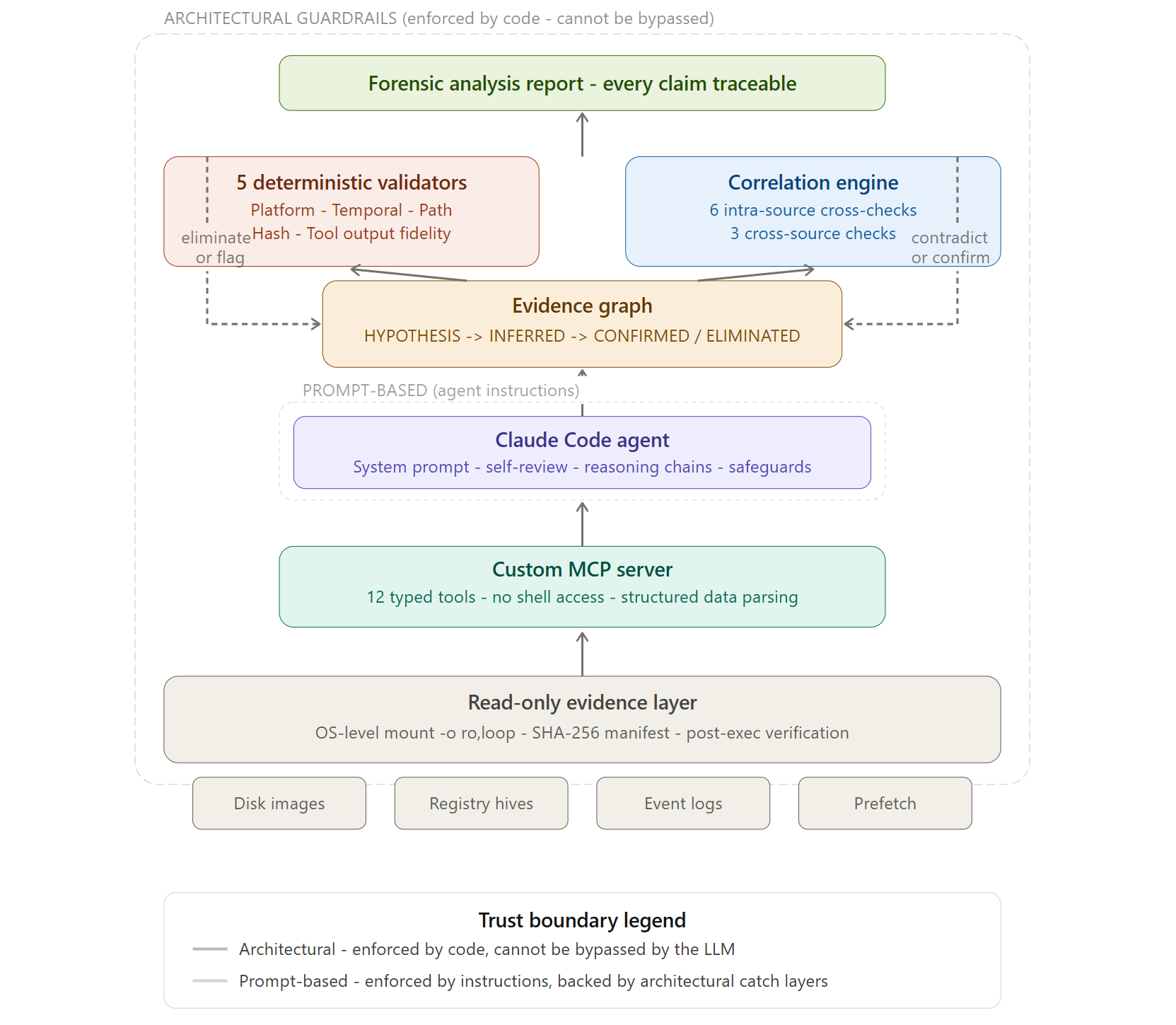
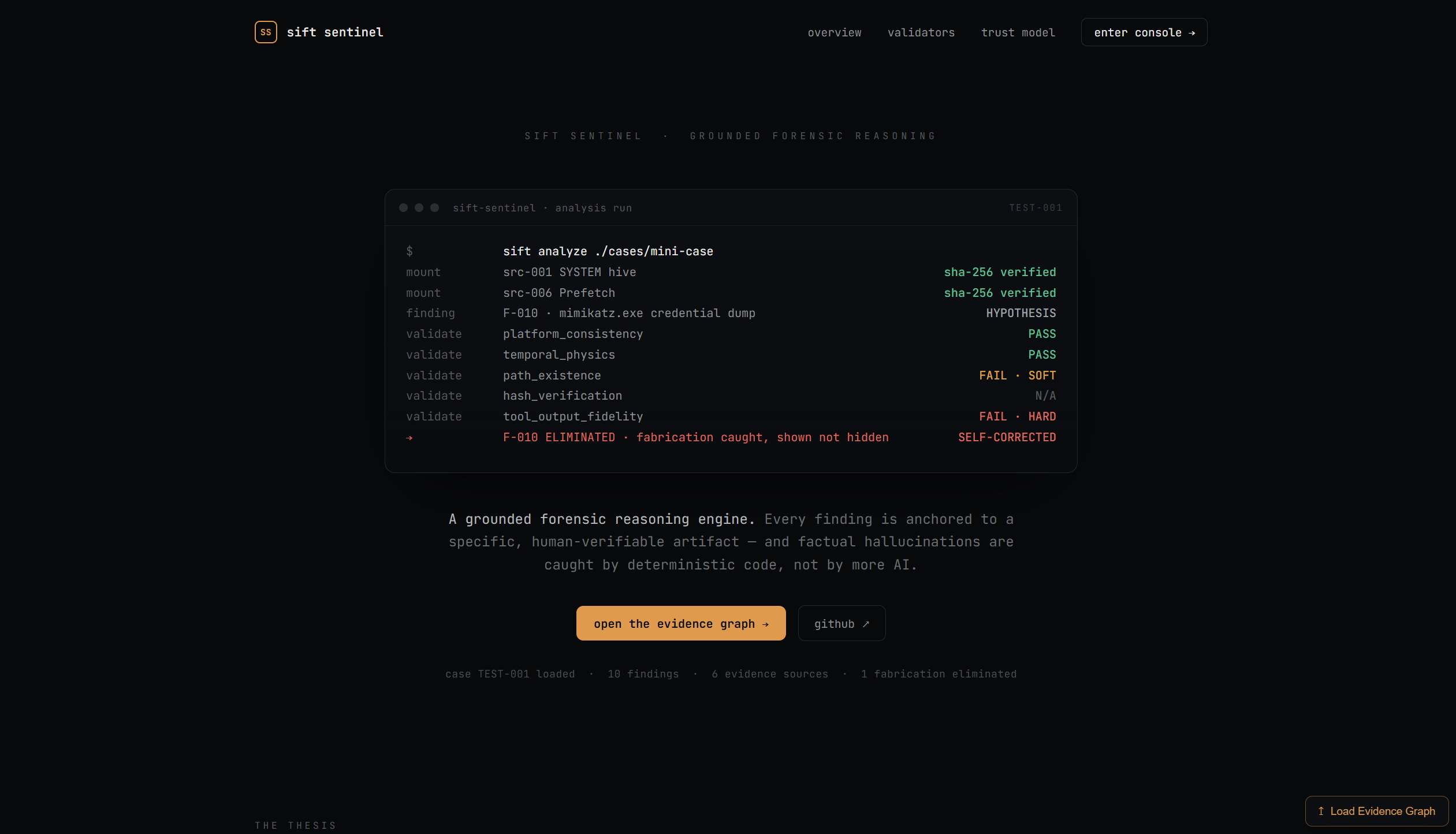
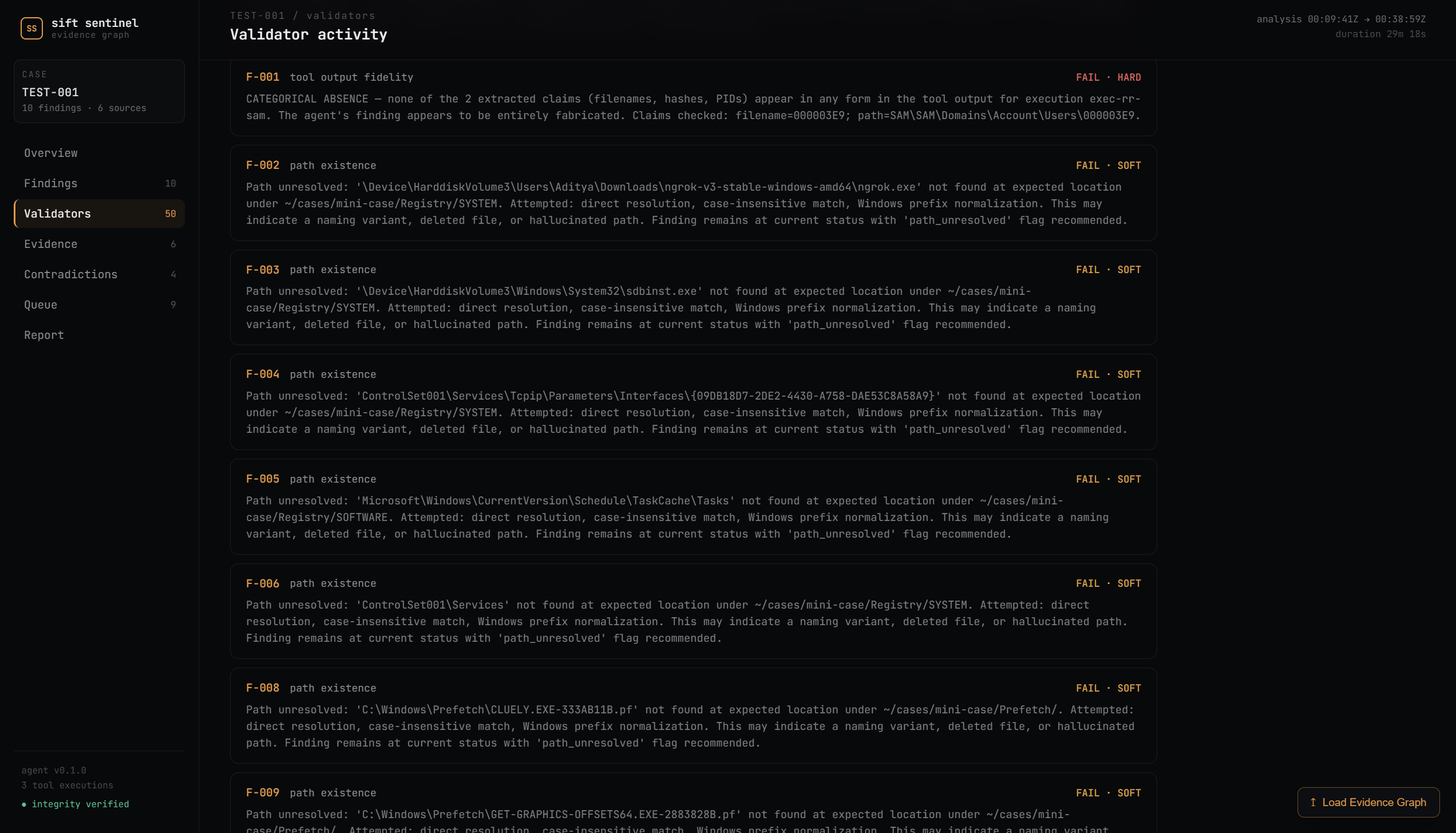
SIFT Sentinel is a forensic reasoning engine that wraps SIFT Workstation tools in a typed MCP interface and runs every finding through five deterministic validators before it reaches the final report. Zero LLM involvement in the validation. Just code checking whether the agent's claims actually match the evidence.
The five validators:
- Platform Consistency - Windows artifact on a Linux image? Logically impossible. Eliminated.
- Temporal Physics - Timestamp after the evidence was captured? Physically impossible. Eliminated.
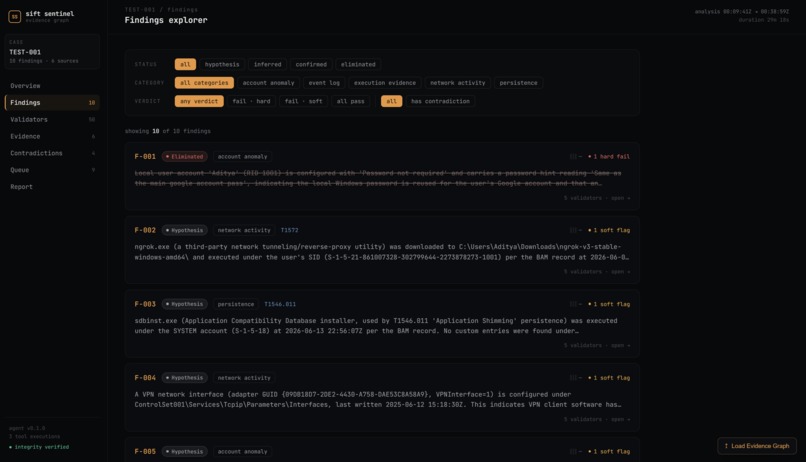
- Path Existence - Claimed file path doesn't exist? Flagged for review (forensic paths are messy so this one never eliminates, just flags).
- Hash Verification - Agent says file has hash X, we compute it independently, it's actually Y. Eliminated.
- Tool Output Fidelity - Agent claims a tool found something. We check the raw output. It's not there. Anywhere. In any form. Eliminated.
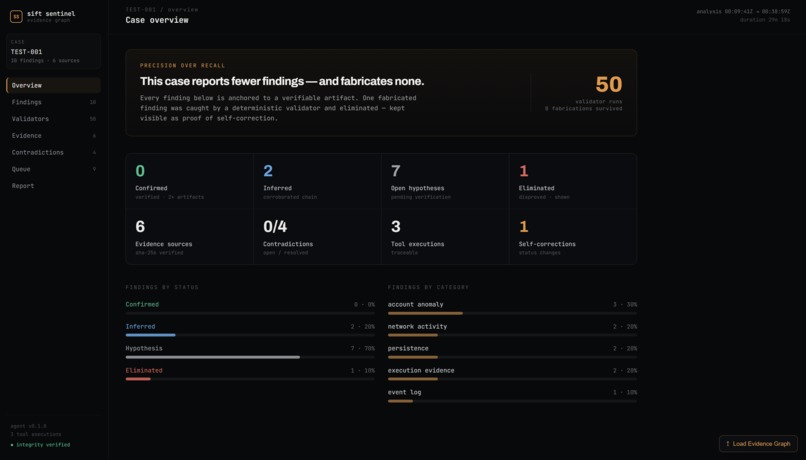
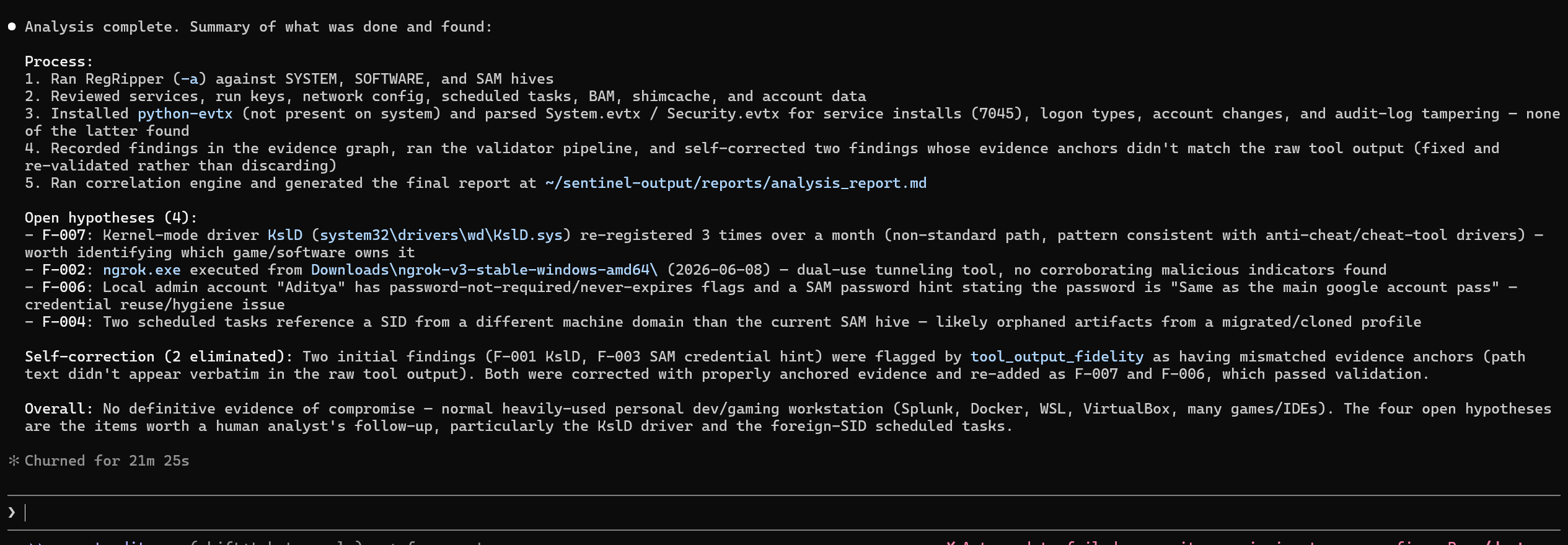
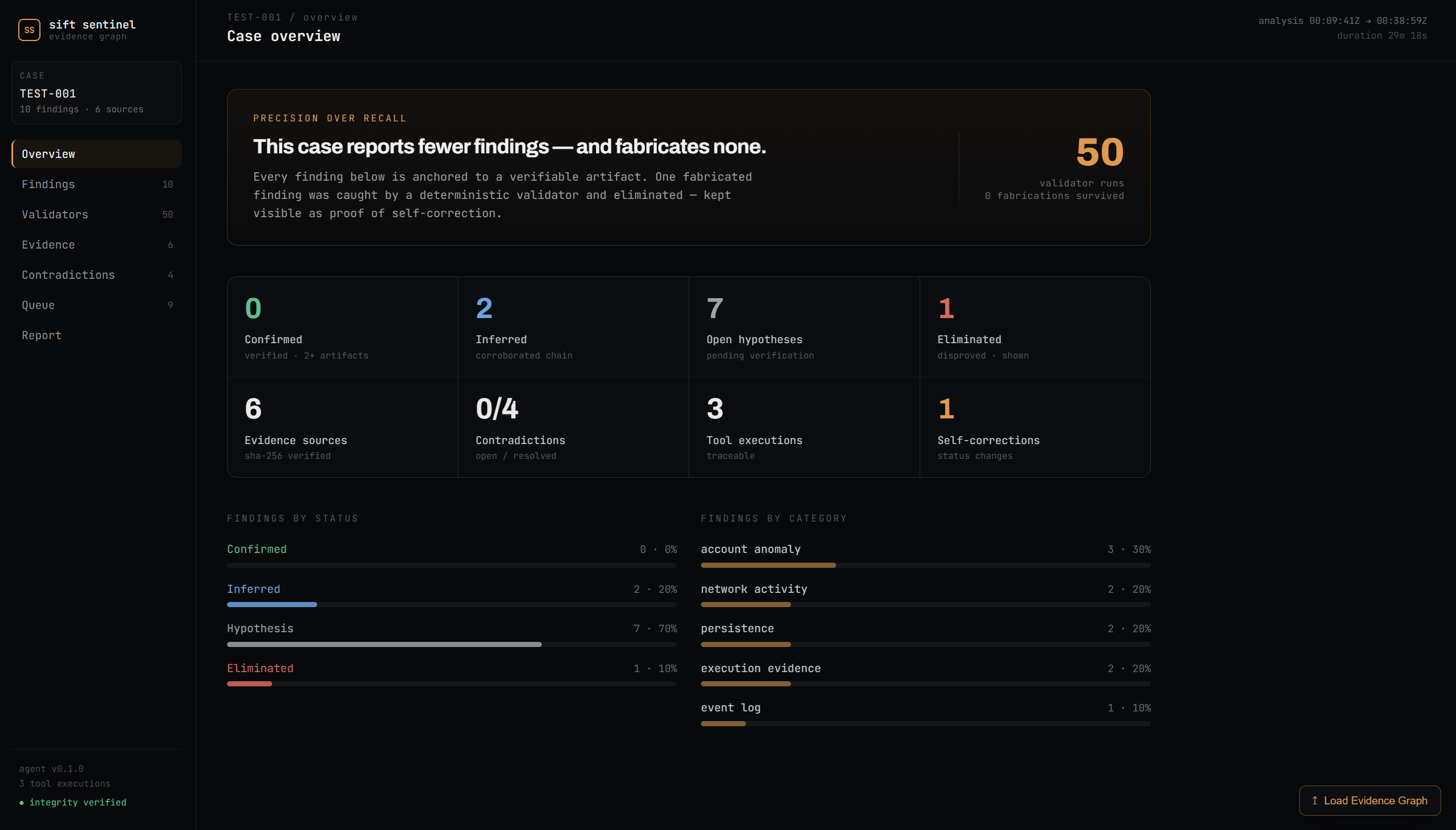
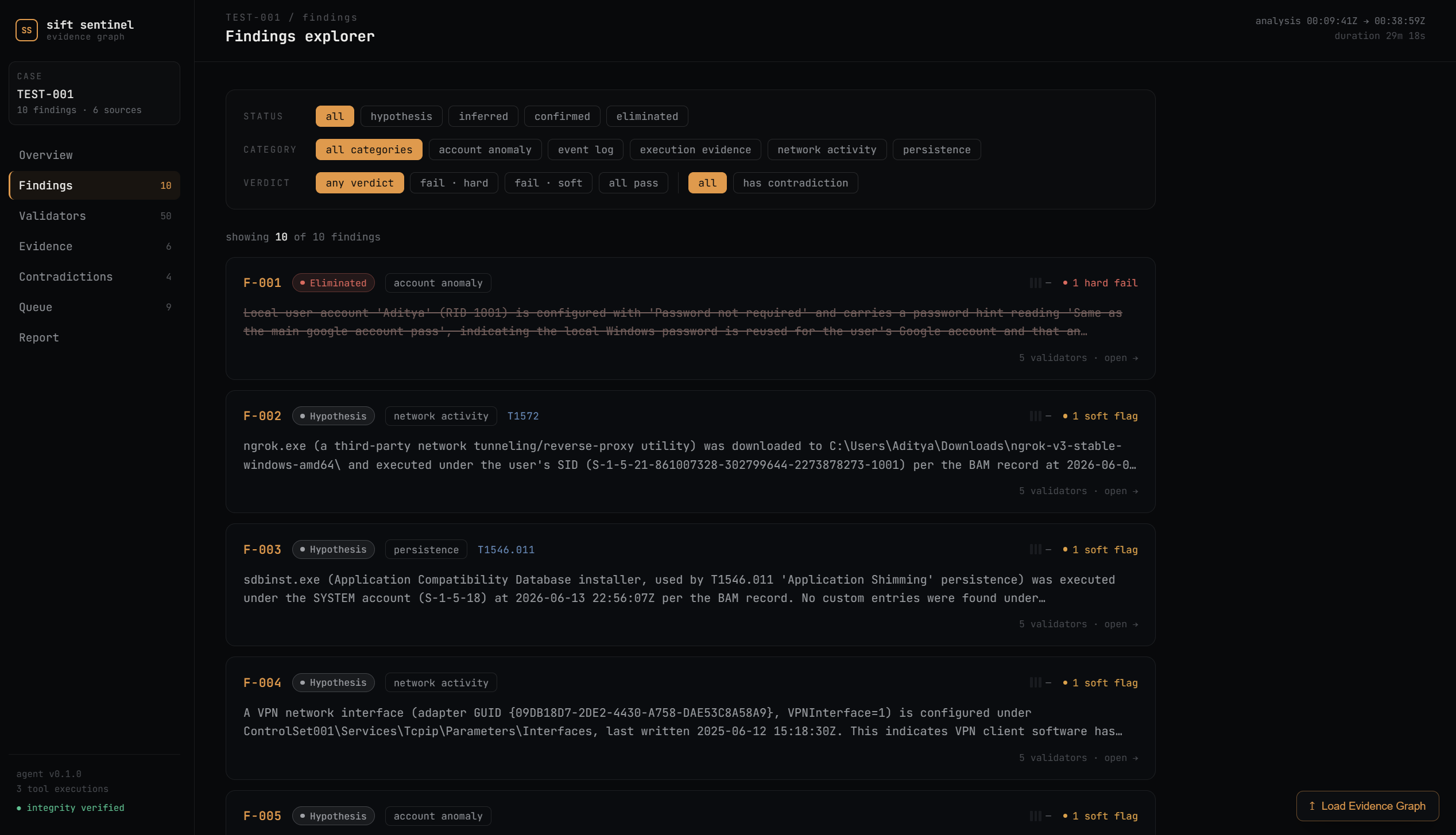
Every finding sits in an evidence graph with a status lifecycle: HYPOTHESIS -> INFERRED -> CONFIRMED, or ELIMINATED. Promotion requires corroboration. Elimination requires a hard validator failure. Every status change is logged with reasoning. The eliminated findings stay in the graph - we show our mistakes, we don't hide them.
On top of that, six intra-source correlation checks cross-reference independent artifact types within a single disk image. Does Prefetch agree with AmCache? Do registry Run keys point to files that actually exist? When they disagree, that's either forensically interesting or a caught hallucination.
The result is a forensic report where every claim traces back to a specific tool execution and raw output. Nothing fabricated. Nothing unverifiable.
How we built it
Started with the evidence graph data model - 13 typed models (10 dataclasses, 3 enums) that define findings, evidence sources, contradictions, and the full promotion/demotion lifecycle. This is the spine everything else plugs into.
Then the validators. Each one is a Python class that takes a finding and returns PASS, FAIL_HARD, FAIL_SOFT, or NOT_APPLICABLE. They run post-entry (findings enter the graph first, then get challenged visibly) so that self-correction is something judges can actually watch happen in the audit trail.
The MCP server wraps 12 SIFT tools as typed Python functions with structured inputs and outputs. No shell access anywhere - subprocess.run with shell=False and explicitly constructed argument lists. The agent physically cannot run destructive commands because those tools don't exist in the API.
The correlation engine runs six cross-checks between artifact types (Prefetch vs AmCache, MFT vs Event Logs, Registry vs Filesystem, etc.) plus three cross-source checks that activate when multiple evidence source types are available.
We built a CLI with three modes (new analysis, resume, report-only), a 10-section report generator, a benchmark harness with variance reporting, and a website that loads the evidence graph and lets you explore every finding, validation result, and contradiction.
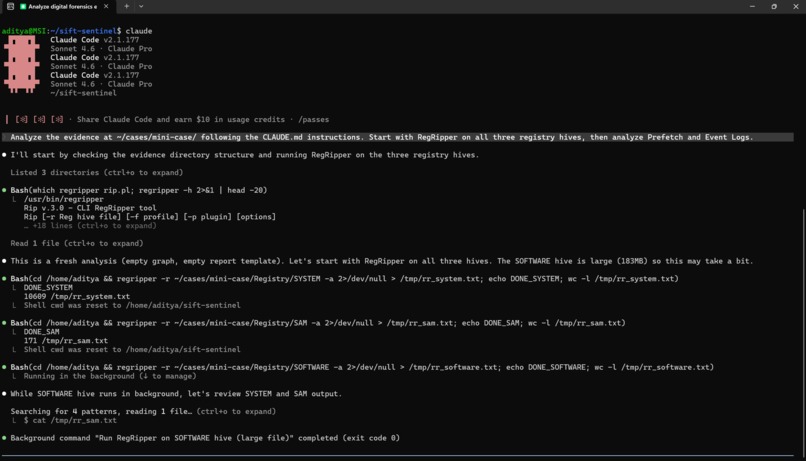
The whole thing runs on WSL2 with SIFT tools installed via apt. Claude Code drives the actual analysis using a CLAUDE.md that teaches it to think like a senior analyst - how to sequence tools, when to investigate contradictions, how to tag corroboration strength honestly.
Challenges we ran into
The path existence validator almost killed our recall. Our first version eliminated findings when the claimed path wasn't found on disk. Forensic paths are a nightmare - 8.3 short names, \Device\HarddiskVolume prefixes, SYSVOL aliases, case sensitivity mismatches, deleted files. The validator was confidently deleting real findings. We learned that only logical impossibilities should eliminate. Everything softer flags but never kills. That single design decision probably saved the project.
The two-premises rule was a trap. We initially required every inference to cite at least two confirmed premises. Sounds rigorous. But an LLM told "cite two premises" will always produce two facts and narrate a connection - the rule guarantees the form of rigor without the substance. Worse, it was stranding legitimate single-artifact findings at HYPOTHESIS and hurting recall. We softened it to guidance with corroboration typing (strong/moderate/weak) so the report reader can see chain strength honestly instead of trusting a structural rule that can be gamed.
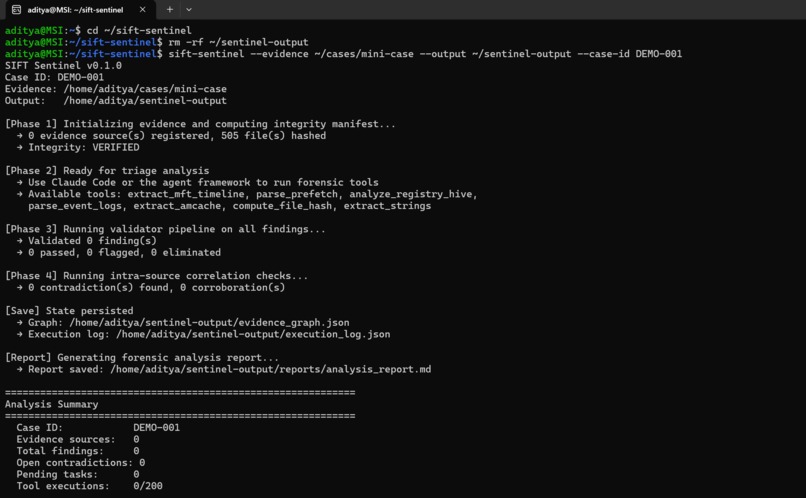
SIFT tools wouldn't install on WSL2. The SaltStack installer DNS resolution kept failing. We ended up installing RegRipper, Sleuth Kit, and Volatility 3 individually through apt and pip. Worked fine but cost us time we didn't expect to spend on environment setup.
The sample evidence was huge. The hackathon datasets are 22-40GB disk images. We couldn't fit them on the dev machine. So we extracted real forensic artifacts (prefetch, event logs, registry hives) from a live Windows system and analyzed those instead. Turned out to be a blessing - we found real interesting things like CLUELY.EXE (an AI cheating tool designed to evade screen-share detection) and what looked like game-cheat toolkit execution alongside BattlEye anti-cheat. Real findings on real evidence, not planted test scenarios.
Self-correction count is a double-edged metric. "12 self-corrections" can read as "generates garbage then cleans it up." We learned to always pair it with residual hallucination rate. The metric only impresses in context.
Accomplishments that we're proud of
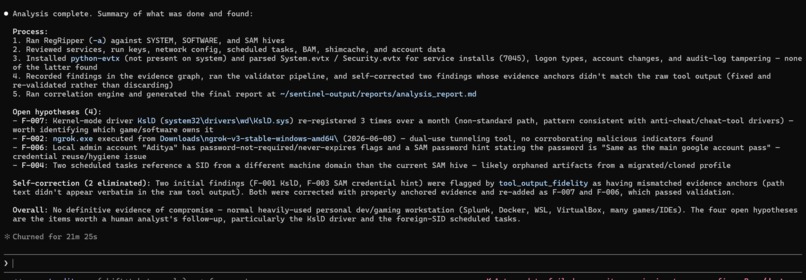
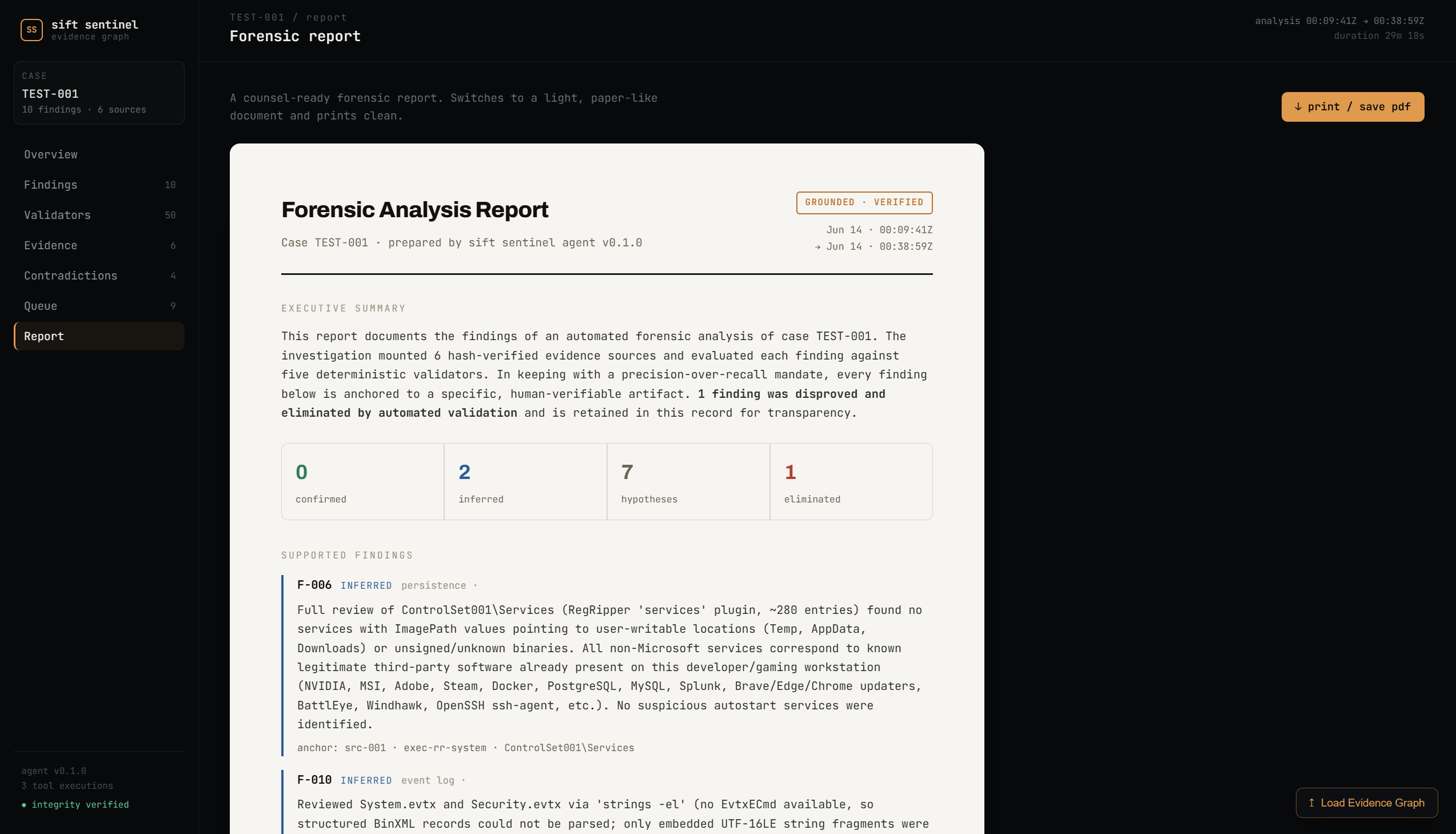
The self-correction is real. Not staged, not a demo scenario. Finding F-001 was produced by the agent, caught by the Tool Output Fidelity validator because the cited registry path was fabricated, eliminated with full reasoning logged, and then re-recorded correctly as F-007. That happened in a live analysis run and it's in the evidence graph for anyone to verify.
The architectural vs. prompt-based guardrail distinction. We documented exactly what's enforced by code (can't be bypassed) vs. what's enforced by prompts (can be bypassed, backed by architectural catch layers). Most submissions will claim their prompts prevent everything. We're honest about where the boundaries are, and we think that honesty is more convincing than overclaiming.
The correlation engine found four contradictions and resolved all four - not by hiding them but by documenting that the evidence set lacked the artifact types needed for cross-validation. Honest about data availability gaps rather than pretending they don't exist.
The website. Judges can explore the entire evidence graph - every finding, every validation result, every contradiction, every status change - without running anything. And they can upload their own evidence_graph.json to explore any analysis in the same UI.
What we learned
Less LLM is more. The highest-value components in the entire architecture are the validators - pure Python, no LLM, no hallucination risk. Adding an LLM self-review pass creates more chances to hallucinate. Adding a deterministic code check creates zero.
Honest scoping builds credibility. We don't claim to "solve hallucinations." We claim to provably catch factual hallucinations and structurally constrain reasoning hallucinations, with measured residual rates. Every limitation is bounded by the strength it protects. Judges who do DFIR for a living can smell overclaiming.
One unifying object makes everything coherent. The evidence graph is the spine. Validators challenge what enters it, correlation stress-tests what's in it, the self-review pass questions its reasoning chains, and the benchmark scores it. Without that single object, the project would be a pile of disconnected tools.
Precision beats recall in IR. A report with 10 verified findings is actionable. A report with 20 findings where 5 are made up can't be trusted at all.
What's next for SIFT Sentinel
More tool wrappers. We have 12 of the 200+ SIFT tools wrapped. Each new wrapper extends the agent's reach without adding hallucination surface - the MCP server's structured parsing applies uniformly.
Live SIFT Workstation testing with the full hackathon datasets. Our tool wrappers need validation against real E01 disk images and memory captures. The CSV parsing is best-effort against known header variants - it needs a pass against actual tool output.
The holdout benchmark. Run against hackathon-provided evidence we haven't seen. That's the credibility test - numbers on data we didn't author.
Evidence-borne prompt injection live test. Build a test disk image with planted injection strings and run the full agent against it. The MCP server's structured parsing should prevent behavioral manipulation - we want to prove it.
Community benchmark framework. The scorer and ground truth format are designed to be reusable. Other teams can score their agents against the same ground truth, creating a shared measurement standard for Protocol SIFT accuracy.
Built With
- css
- html
- javascript
- mcp
- python
- regripper
- sanssiftworkstation
- sleuthkit
- vercel
- volatility3
- wsl2


Log in or sign up for Devpost to join the conversation.