-
-
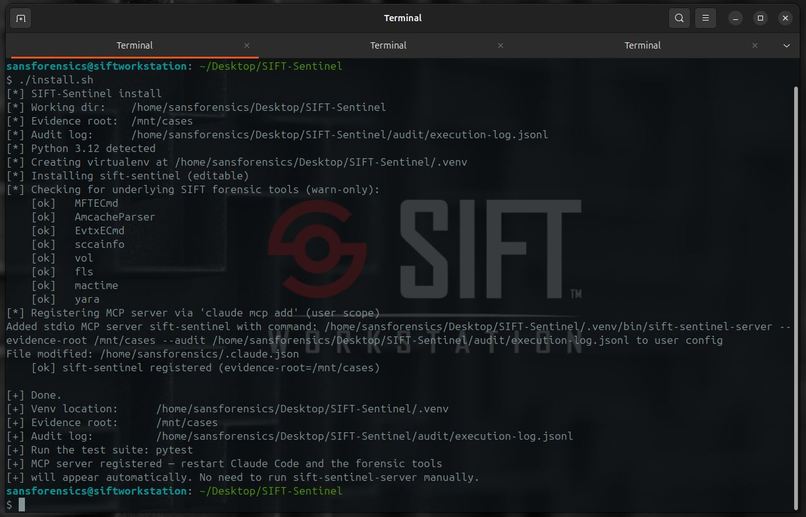
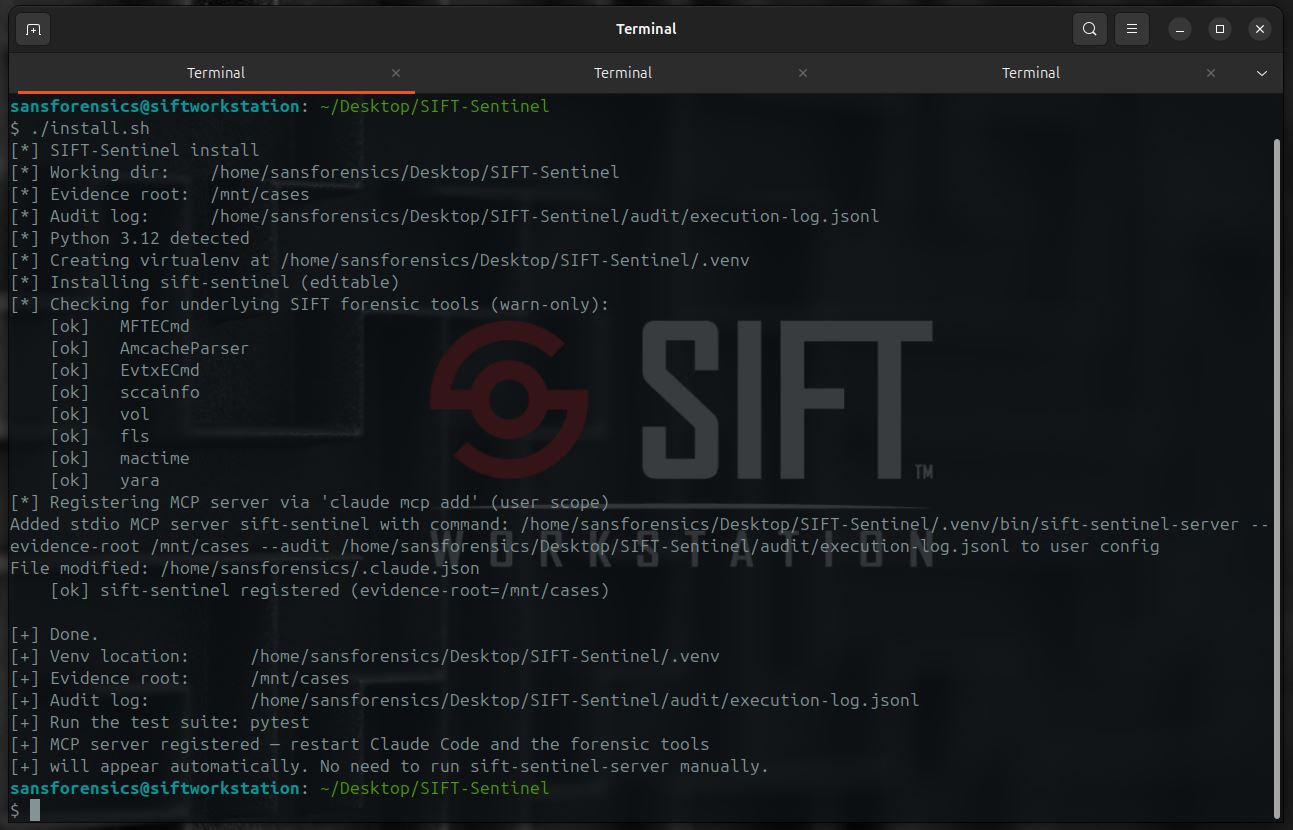
One Command Installation
-
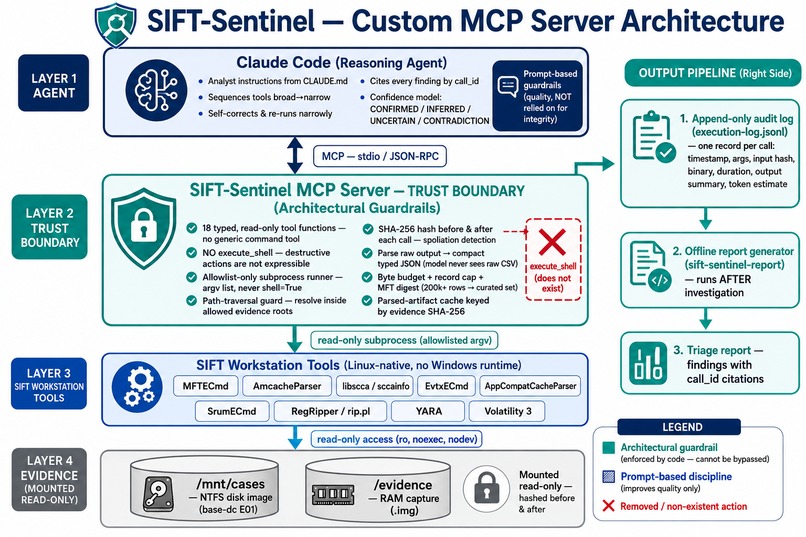
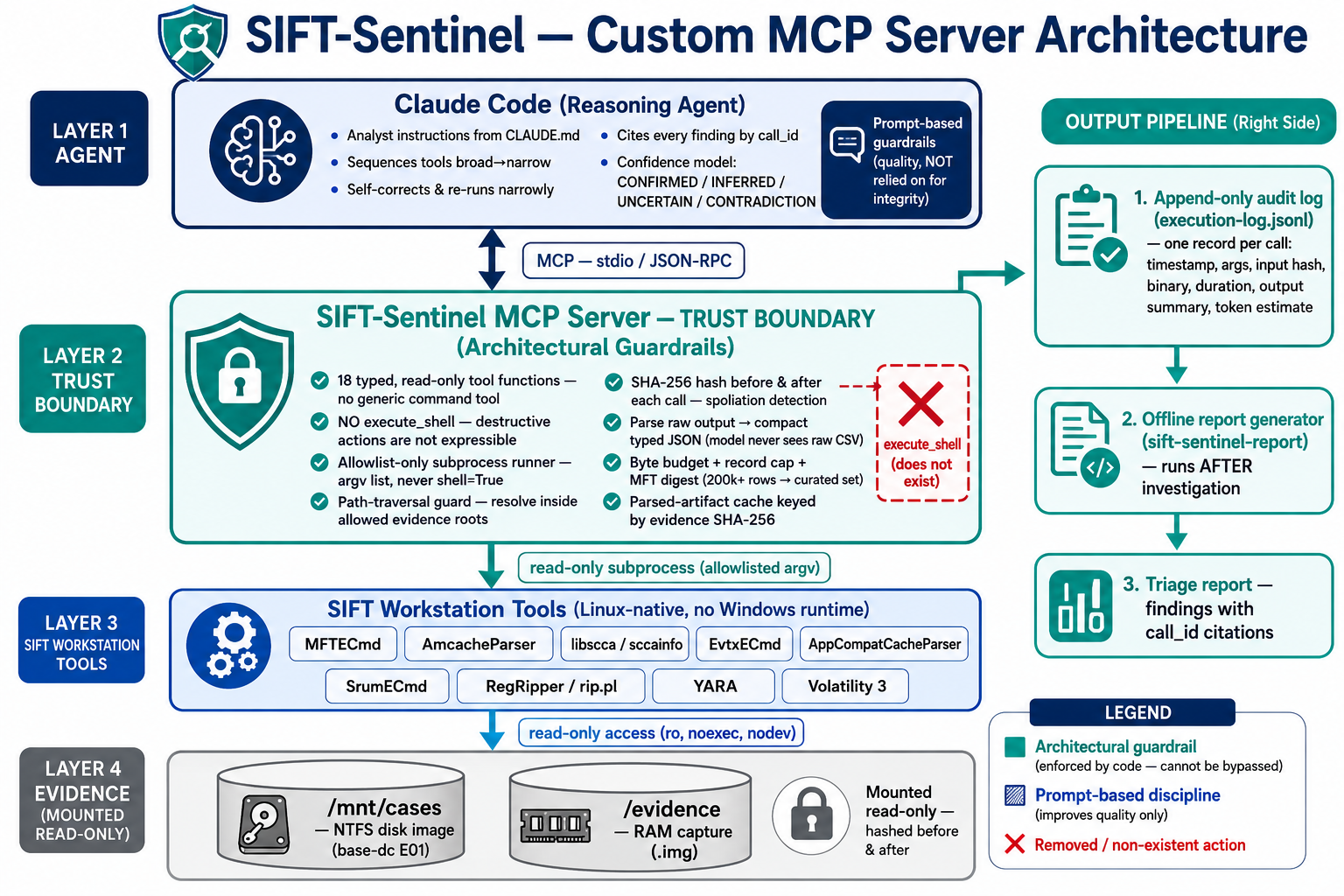
Architecture
SIFT-Sentinel
An autonomous, evidence-safe incident-response analyst for the SANS SIFT Workstation. Claude reasons over real disk and memory evidence, but physically cannot spoliate that evidence or assert an uncited finding — because the destructive and the unsupported are removed from its action space by architecture, not by a prompt asking it to behave.
Inspiration
An AI-driven adversary can go from initial access to domain control in under eight minutes. The defender is usually still pulling up their toolkit.
Protocol SIFT showed that connecting an agent to the SANS SIFT Workstation over MCP is viable — but it hallucinated more than is acceptable for evidence work, and a shell-capable agent pointed at original evidence is one careless command away from spoliation. In forensics, "the agent modified the disk image" is not a bug report, it is a destroyed chain of custody.
We wanted to know how much of that could be fixed structurally rather than with prompt tuning, and whether evidence integrity could be made an architectural guarantee instead of a rule the model is politely asked to follow.
What it does
Point SIFT-Sentinel at a mounted Windows disk image and a RAM capture and ask it
to triage. Claude Code, following the senior-analyst instructions in
CLAUDE.md, drives a fixed set of 18 typed, read-only forensic tools to:
- Work broad to narrow. Execution evidence and the filesystem timeline first, then pivot into memory, logons, and persistence.
- Corroborate across sources. A finding is only marked
CONFIRMEDwhen at least two independent artifacts agree (e.g. Prefetch + Amcache + MFT). One source is anINFERRED, explicitly flagged. - Surface contradictions. When disk and memory disagree, it reports a
CONTRADICTIONrather than quietly choosing the convenient answer. - Self-correct. If a gap remains it re-runs more narrowly — a tighter
path_filter, a specificevent_id— instead of concluding early. - Cite its work. Every claim references the
call_idof the tool execution that produced it, recorded in an append-only audit log. If it can't cite a call, it can't make the claim.
There is no execute_shell tool. The agent cannot run a destructive command
because no such function exists in its action space.
On the SANS "SRL-2018 Compromised Enterprise Network" domain-controller image,
it produced (full report with citations in
audit/triage-report-base-dc-2026-06-14.md):
- CONFIRMED — F-Response remote-forensics agent (
subject_srv.exe) and theMnemosyne.syskernel driver staged inC:\Windowson 2018-09-06/07, each corroborated by MFT and a 7045 service-install event, and correctly attributed to IR/acquisition tooling rather than an adversary. - INFERRED — a sustained series of 163 failed logons (4625) from
BASE-HUNT$at172.16.5.25against the DC over ~27 hours. - CONTRADICTION — memory tooling returned zero processes with no error, flagged as a silent tooling failure (a blind spot), not as evidence of a clean host. The agent refused to call the host clean on the strength of a result it could not trust.
How we built it
Architecture: a Custom MCP Server as the trust boundary, with Claude Code as the reasoning agent. Of the four hackathon approaches, the custom MCP server is the only one where evidence integrity is enforced by what code exists rather than by the model following instructions.
The pipeline is Claude Code → MCP (stdio/JSON-RPC) → SIFT-Sentinel server →
read-only subprocess → SIFT tools → read-only evidence, with an append-only
audit log tapped off the server. See docs/architecture.png.
The design rests on a few deliberate decisions:
- Typed functions, not a generic command tool. We expose
extract_mft_timeline(...), notrun("mftecmd ..."). The server decides which binaries run and with which arguments — and owns output handling, which is where the accuracy work happens. - One allowlist-only runner, no shell. Every external execution funnels
through a single function that takes an argument list, refuses any binary not
on the allowlist, and never uses
shell=True. The destructive-command and command-injection surface is one small, auditable chokepoint. - Path-traversal guard + hashing. Every tool-supplied path is resolved inside an allowed evidence root, and each file-backed artifact is SHA-256 hashed before and after a call. A changed post-call hash is returned as an integrity error and logged.
- Parse before the model sees anything. A full
$MFTis ~236k records and ~60 MB of CSV. We parse to small typed records and digest huge results, so the model reasons over signal instead of doing text-extraction over a truncated dump — a known source of hallucination. - Confidence as a data model, not a convention.
CONFIRMEDrequires ≥2 supportingcall_ids in the data structure, so an unsupported confident claim cannot be represented. - Append-only JSONL audit log. One immutable record per tool call —
timestamp, arguments, input hash, binary, duration, output summary, and an
estimated per-call token cost — and every finding cites its
call_id. This is both the chain-of-custody mechanism and the execution-log deliverable.
Underlying tools are Linux-native (sccainfo/libscca for Prefetch, rip.pl/
RegRipper for the registry, plus Zimmerman tools and Volatility 3), so the whole
pipeline runs on a stock SIFT Workstation with no Windows runtime. The test
suite runs with no real forensic tools and no API key, using captured fixtures
and an injected fake runner.
Challenges we ran into
- A row cap looked safe and still overran the transport. We first capped
responses by record count.
extract_mft_timelinethen returned 236,778 records and the response spilled to a temp file anyway — because record width, not count, is what matters (1,000 wide MFT rows are ~257 KB of mostly uninteresting metadata). We only caught it by running against real evidence. The fix was a hard byte budget plus an MFT digest that returns the forensically-interesting records (executables in user-writable paths, masquerading double extensions, ADS, deleted executables) instead of a head-of-list dump. - Logging "token usage" honestly from a read-only server. A read-only MCP server never sees the model's own prompt/completion tokens, and inventing them would be the exact hallucination we set out to remove. We instead record the one cost we can measure at the boundary — the deterministic, offline- estimated token size of the response payload each call returns into the agent's context.
- Keeping the read-only boundary intact meant rejecting convenient shortcuts, like letting the agent write its own report. Report generation is a separate offline command that runs after the investigation over data that already exists (the narrative + the audit log), so the action space stays read-only.
- Memory forensics silently returning nothing. Volatility returned zero processes with no error on a valid image. The hard part wasn't the bug — it was making the agent treat a silent zero as a contradiction to investigate, not a clean bill of health.
Accomplishments that we're proud of
- Evidence integrity is architectural, not aspirational: there is no destructive verb to misuse, and identical before/after hashes prove nothing was modified.
- The hallucination problem has a structural answer:
CONFIRMEDis unrepresentable without two cited sources. - The agent caught and reported a silent tooling failure instead of declaring the host clean — exactly the discipline a junior analyst usually lacks.
- It runs end-to-end on a stock SIFT Workstation with no Windows runtime, no extra service, and no API key to manage.
What we learned
The largest accuracy improvements were architectural, not prompt-based. Structured parsing and digesting of large results removed whole categories of hallucination before any prompt tuning, and made the claim that "the destructive tool simply does not exist" one we can actually stand behind. Asking a model to be careful is a hope; removing the dangerous action from its action space is a guarantee. We also learned that you only find the failures that matter by running against real evidence — the row-cap blowup and the silent memory failure were both invisible against fixtures.
What's next for SIFT-Sentinel
- Fix and re-run memory forensics. Resolve the Volatility symbol/profile
issue so
mem_pslist/mem_netscan/mem_malfind/mem_svcscanproduce real output — the single largest open gap in the current run. - Publish a populated accuracy report. Commit a ground-truth answer key for
the SRL-2018 dataset and run
benchmark/score.pyhead-to-head against the Protocol SIFT baseline, reporting concrete precision/recall, false positives, missed artifacts, and hallucination rate. - Expand the tool surface with $UsnJrnl and $LogFile parsing, browser and LNK/Jump List artifacts, and a YARA rules pack tuned for live-response triage — each added the same way: wrapper, typed MCP function, allowlist entry.
- Tighten cross-source correlation, automatically promoting an
INFERREDfinding toCONFIRMEDwhen a later tool call supplies the second source, and widening the super-timeline to merge memory artifacts alongside disk. - Harden auditability with per-call token totals rolled up into the offline report, and an optional signed/hash-chained audit log for tamper-evidence beyond append-only. ```

{kind=link}
Log in or sign up for Devpost to join the conversation.