-
-
Autonomous DFIR on SIFT: 186 forensic tools, a 4-model Claude ensemble, every finding proven
-

ARCHITECTURE DIAGRAM
-
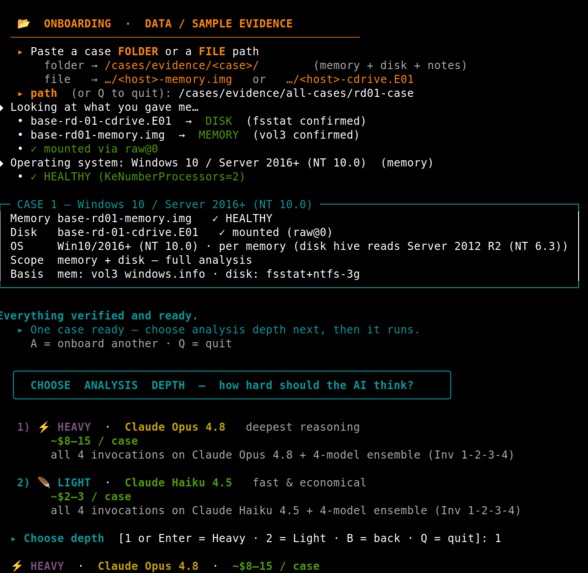
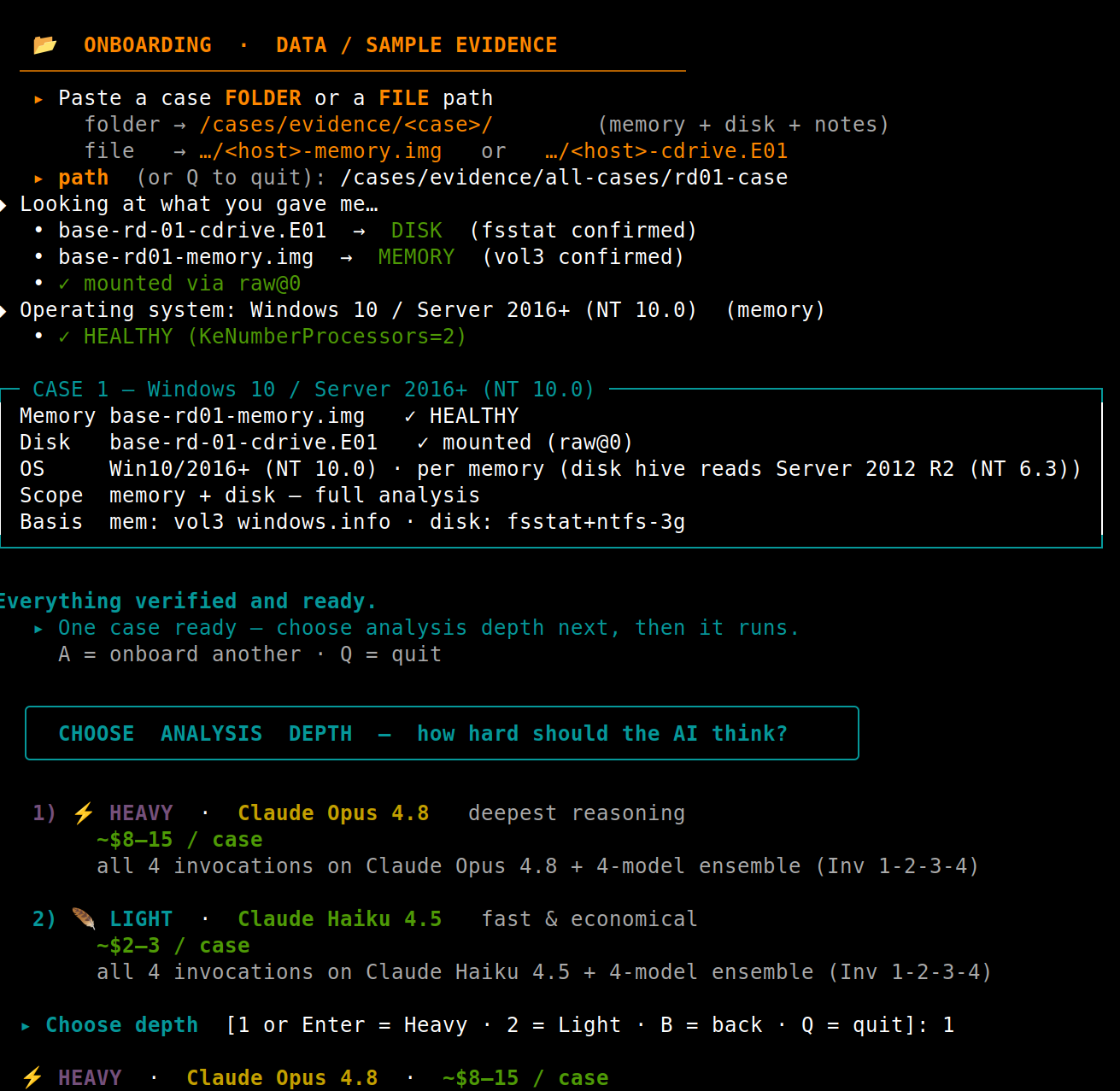
Onboarding Evidence
-
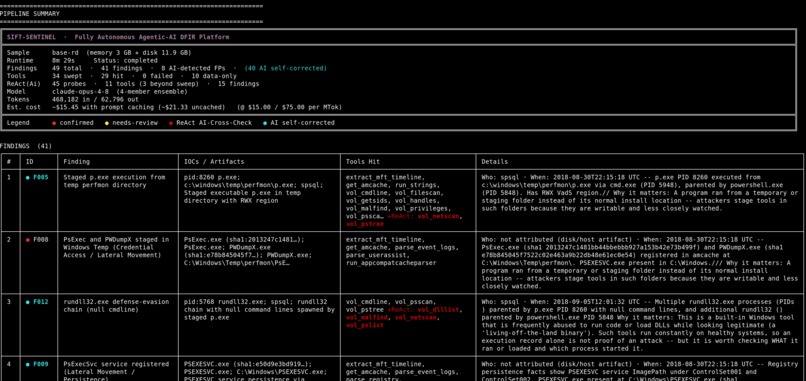
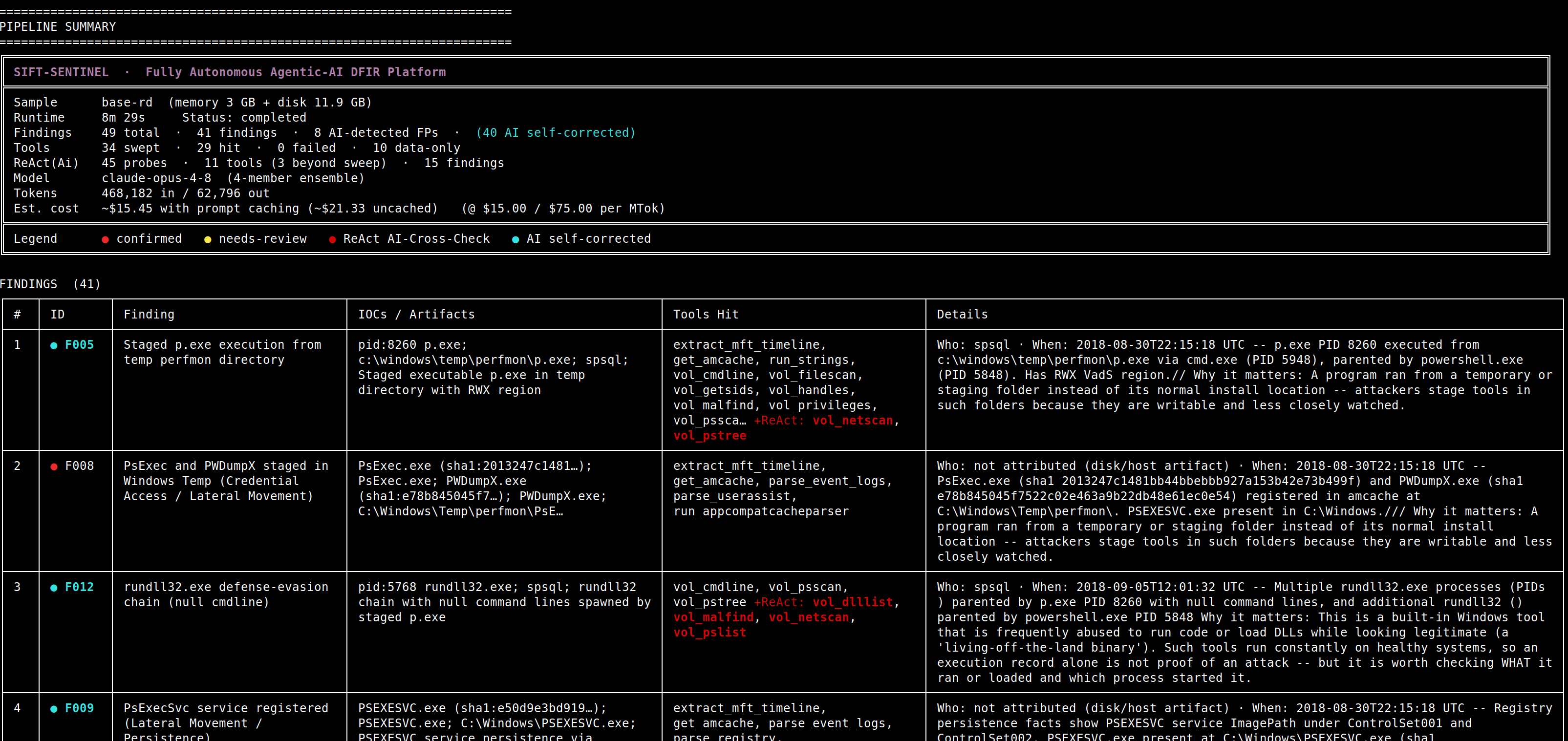
Findings Result Table

Inspiration
Forensic investigators don't fear AI that's wrong. They fear AI that's confidently wrong. An LLM that invents a process ID, hallucinates a registry key, or "confirms" a benign service as malware doesn't save time, it manufactures liability. Most agentic DFIR tools hand the model a shell and hope its prompt discipline holds. We wanted the opposite: an agent that is architecturally incapable of fabricating a finding, and that proves every claim before a human reads it. So we built Sentinel Ensemble around one rule: the AI reasons, but deterministic code keeps it honest.
What it does
Point Sentinel Ensemble at Windows evidence, a memory image, a disk image, event logs, and ask one question: "What happened on this system?" It runs a fully autonomous 16-step investigation with zero human steering and hands back an investigative report where every single claim has been validated against real tool output.
How the pipeline thinks:
- A deterministic Python "conductor" owns all 16 steps and calls the AI in 5 distinct stages. Between calls, plain code is in control, so the run is repeatable, not improvised.
- Evidence is mounted READ-ONLY and SHA-256 fingerprinted before and after the run. If one byte changed, the math catches it.
- The AI never touches a shell. It can only call 186 typed forensic tools (Volatility 3 plugins plus disk artifact parsers) through a guarded MCP server, removing prompt injection and command fabrication as an entire class of error.
- A mandatory tool sequence (kernel integrity and rootkit check, process tree, network, malware scan) runs first and cannot be skipped.
- AI stage 2 is an ENSEMBLE: four Claude models analyze the same evidence independently, and only what they agree on survives. Disagreements are flagged, not hidden.
- A deterministic VALIDATOR, code not a model, checks every finding against the raw tool output and stamps it MATCH, MISMATCH, or UNRESOLVED. Any mismatch blocks that finding from the report.
- The agent SELF-CORRECTS twice: a ReAct cross-check re-investigates suspicious findings and can overturn its own verdict, then a final adjudication pass re-judges everything still uncertain, promoted only with evidence, never silently dropped.
- Confidence is earned, not felt: a finding reaches HIGH only when independent evidence types agree (memory plus disk plus logs). The output is a human-readable report: a verdict, an attack timeline, per-user activity (who did what), and a concrete remediation step for each attacker tactic. Every line traces back to the raw evidence excerpt that supports it.
How we built it
- Platform: SANS SIFT Workstation (Volatility 3, Sleuth Kit, EWF tools, Plaso).
- Architecture: a deterministic Python conductor (the 16-step pipeline) plus a custom typed MCP server exposing 186 forensic tools as validated functions. The model receives only pre-parsed, validated JSON. It never constructs command syntax.
- The "paired reference set": every value a tool emits is linked back to its exact source output, so the validator can check claims deterministically instead of asking another AI.
- Confidence calibration and severity are computed in code from artifact-type diversity and cross-domain corroboration, not from the model's self-rating.
- Multi-model ensemble via the Anthropic API (Claude Opus, Sonnet, Haiku, and Fable 5 as members), with prompt-cache-aware cost accounting.
- Engineering discipline: test-driven, 4,800+ automated tests, MIT licensed, every behavioral change gated behind a kill-switch and proven zero-regression before merge.
Challenges we ran into
- "Correct facts, wrong interpretation." A finding can cite a real PID yet misread its meaning. We added a Process Ancestry Validator and cross-artifact corroboration so interpretation is checked against OS structure, not vibes.
- Degraded evidence. On a corrupted-kernel memory image, the usual memory-based user attribution goes blind. We built a graceful disk-pivot that raises the disk-tool budget and recovers "who did what" from on-disk UserAssist, so the agent degrades instead of failing.
- Ensemble disagreement without majority-vote shortcuts. Any FACT disagreement blocks a finding (no democratic averaging of a hash). Only interpretation disagreements accept the lower confidence.
- Determinism. Same code plus same evidence had to mean the same verdict. We hunted run-to-run nondeterminism down to sampling effects and added structural detectors so the result is reproducible.
Accomplishments that we're proud of
- Self-correction you can watch happen. The demo shows the agent re-judging 46 ambiguous findings live and reclassifying 39, promoting only with evidence, never silently dropping.
- A genuine architectural constraint: with no shell access, fabricating a tool result isn't "discouraged," it's impossible.
- A full audit chain: report line, tool calls, token usage, raw evidence excerpt, end to end.
- It runs on a fresh SIFT VM in a few commands, and every claim in the report is backed by an artifact, low false-positive and low false-negative by design.
What we learned
Trust in an AI investigator doesn't come from a smarter model. It comes from surrounding the model with deterministic checks it cannot talk its way past. The biggest accuracy lever wasn't a better prompt, it was refusing to let unproven claims survive. We also learned that four models agreeing on a hallucination is still a hallucination, which is why confidence comes from independent evidence, not from consensus.
What's next for Sentinel Ensemble - Autonomous DFIR AI-Agent
- With user friendly UI/GUI to make it more cyber folks invite DFIR world, Deeper attribution, broader evidence domains, and richer entity-and-time correlation across the whole timeline, all under the same unbreakable rule: every claim must prove itself.
- Broadening artifact coverage: more disk parsers, cloud and EDR telemetry.
- An interactive mode so an analyst can ask follow-up questions mid-investigation, reusing the same validated reference set.



Log in or sign up for Devpost to join the conversation.