-
-
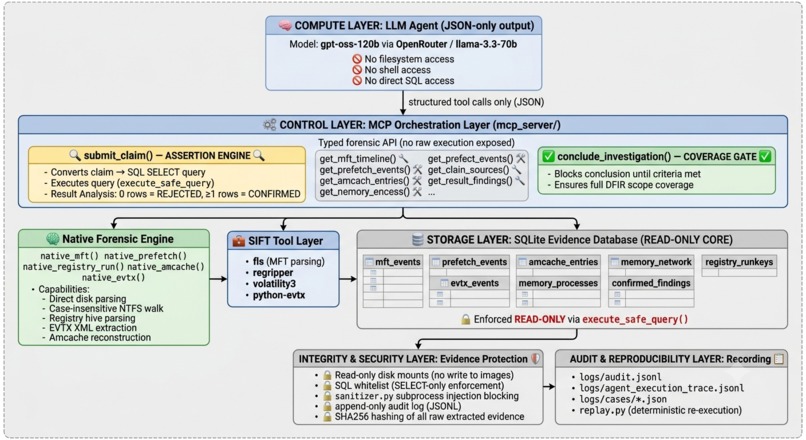
SIFT-PROOF ARCHITECTURE DIAGRAM
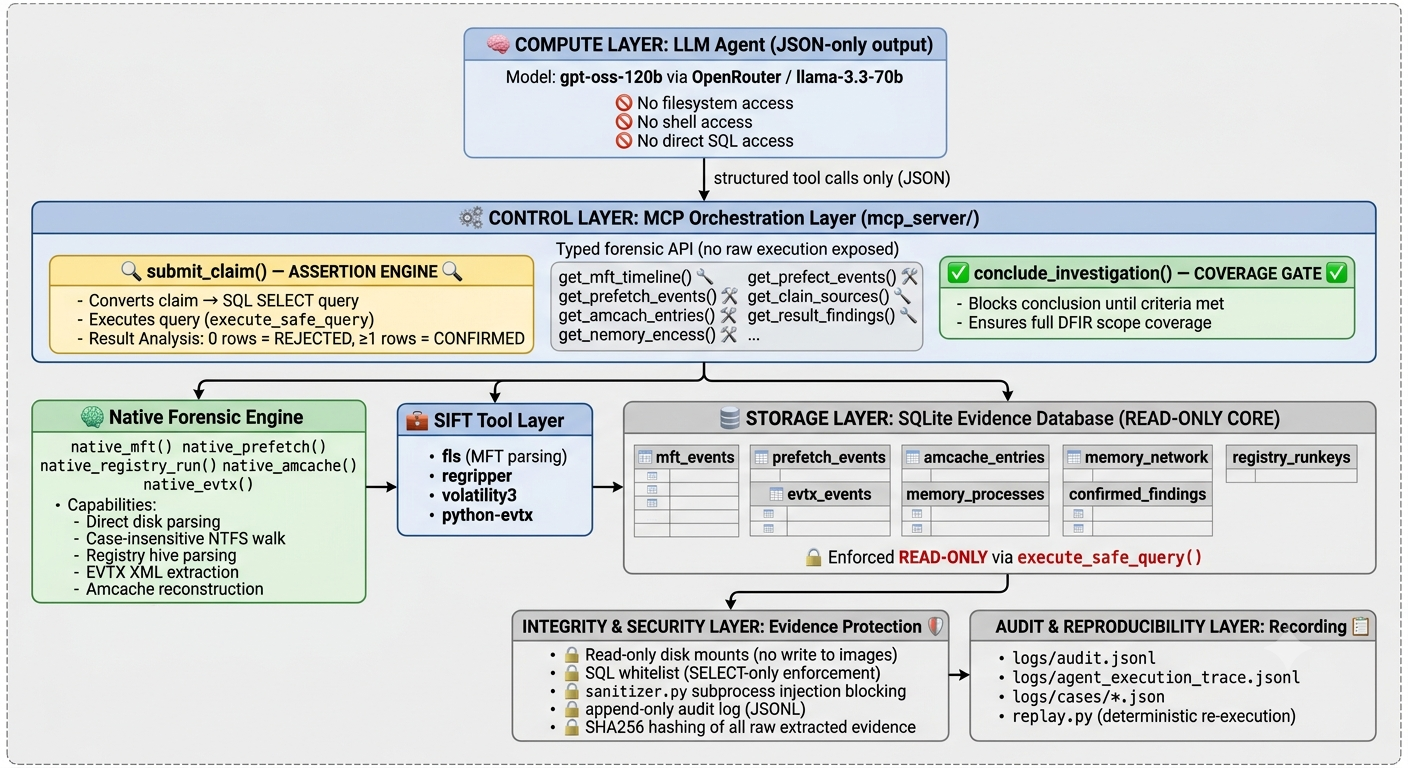
SIFT-PROOF
Inspiration
The inspiration did not come from a product idea. It came from a research paper.
In 2023, Scanlon, Breitinger, Hargreaves, Hilgert, and Sheppard published a landmark study in Forensic Science International: Digital Investigation assessing ChatGPT's suitability for digital forensic investigation. The headline finding was stark: the model delivered inconsistent results when asked to analyze the same forensic artifact 100 times. The conclusion was direct — most LLM applications to digital forensics are "unsuitable at present."
A year later, Chernyshev et al. diagnosed the root cause with precision: "The probabilistic nature of LLM output generation introduces non-determinism where identical inputs may produce varying outputs across multiple invocations. This characteristic **fundamentally conflicts* with the reproducibility requirements essential for digital forensic method acceptance and the legal admissibility of digital evidence."*
We read these papers and asked one question: what would it take to build an AI forensic agent where that conflict does not exist?
The field's answer so far has been better prompts. More careful wording. Confidence disclaimers. Chain-of-thought. These treat the symptom. The disease is that language model output is probabilistic — and no prompt changes that.
Our answer was different: make the wrong answer architecturally impossible.
We are students from Uganda, building on a SIFT Workstation VM, running on free API tiers, with zero budget. We did not have the resources to train a model or buy compute. What we had was the research literature, a clear problem statement, and the conviction that if you understand the failure mode precisely enough, you can engineer around it. That is what SIFT-PROOF is.
What It Does
SIFT-PROOF is an autonomous DFIR investigation agent that enforces a single, non-negotiable rule: every finding must be proved against the evidence before it enters a report.
The enforcement mechanism is a Python-executed SQL assertion gate. When the agent attempts to file a claim — any claim — the system runs a SQL query against the forensic evidence database. If the query returns zero rows, the claim is rejected. Not reconsidered. Not flagged for review. Rejected. The model cannot override this by generating more persuasive text. It is code, not instruction.
Agent claims: "evil.exe was present on the system"
System runs: SELECT * FROM mft_events WHERE filename = 'evil.exe'
→ 0 rows
Gate output: ASSERTION_FAILED → claim rejected
Agent queries: finds googleupdate.exe in a suspicious path
→ 3 rows confirmed
Gate output: CONFIRMED → finding_id: f47874f1 → enters report
Five architectural properties work together to make this possible:
Typed forensic functions. The agent cannot issue shell commands or access the filesystem directly. It can only call named, type-validated MCP functions — get_mft_timeline(), get_registry_runkeys(), get_prefetch(), get_evtx_events(), get_process_list(). Every input is sanitized before execution. Injection characters are blocked at the architectural level.
SQL assertion gate. Every claim routes through Python-executed SQL before acceptance. Zero rows means rejection. The gate is the boundary between probabilistic reasoning and deterministic evidence.
Coverage enforcement. The conclude_investigation() function is blocked until all mandatory artifact categories have been examined. The agent cannot produce a partial report and declare it complete.
Replayable audit trail. Every tool call, every assertion, every finding, and every rejection is written to an append-mode JSONL audit log. Any finding can be replayed by re-executing its SQL against the evidence database at any time.
Cross-artifact correlation. The agent reasons across MFT timelines, registry hives, prefetch records, event logs, and volatile memory simultaneously — enabling detection of attack patterns that exist only in the relationship between artifacts.
The system was validated against seven real forensic datasets, including SANS Find Evil! Hackathon competition images and publicly available Ali Hadi DFIR challenge images. Across all seven cases: zero hallucinations, zero false positives.
How We Built It
We started from architecture, not features.
The core insight came from Hilgert et al. (2025), who introduced the concept of the inference constraint level in MCP-based forensic systems — the idea that MCP design choices can deliberately constrain model behavior to enhance auditability and traceability. Their conclusion: MCP has significant potential as a foundational component for developing LLM-assisted forensic workflows that are "not only more transparent, reproducible, and legally defensible." We built that system.
The MCP layer defines every tool the agent can call. Each function is typed, validated, and sandboxed. The agent sees a clean interface. Under the interface, every subprocess call goes through an injection sanitizer that blocks shell chaining, destructive commands, and injection operators before any execution.
The SQL gate was the hardest design decision. The naive approach is to let the model generate findings and then validate them. The correct approach is to make unvalidated findings structurally unreachable — the gate fires before persistence, not after. We implemented this as a Python function that wraps every submit_claim() call, executes the assertion SQL, and either confirms or rejects before the claim touches the database.
The forensic parsers were built natively wherever possible — a direct NTFS filesystem walker for MFT extraction, native prefetch parsing, native registry extraction, native EVTX parsing. Volatility3 handles memory analysis. The MFT record ceiling started at 20,000 records as a development scaffold and was raised to 500,000 after the Vanko stress evaluation revealed the architectural need for full-scale analysis.
The test suite covers 1,700 tests across five blocks: command injection prevention, temporal anomaly detection, process/network C2 correlation, IOC/YARA format validation, and audit trail JSON integrity. Zero failures. The tests exist because a forensic tool that cannot verify its own guardrails is not a forensic tool.
The demo video — Case 4 Full-Scale Re-run — shows the agent running live against Ali Hadi Challenge #9 at full filesystem scale: 125,073 MFT records, every artifact category swept, zero malicious findings. The entire run takes 23 iterations. The agent tests a web server hypothesis, gets zero results, corrects course, and continues. It finds a 7-Zip installer and correctly does not escalate it. It concludes cleanly. The video is 5 minutes 03 seconds of live terminal execution.
Challenges We Ran Into
The record cap. The original 20,000 MFT record ceiling was a rational engineering decision during development — it kept runtimes predictable and forced correct reasoning on constrained inputs before trusting the system with full scale. It became a liability when the Vanko case presented 194,563 records and exposed the gap between development constraints and production requirements. Removing the cap cleanly, without breaking any existing case logs or validation results, required careful work.
The Vanko case itself. It was the largest dataset by an order of magnitude — 194,563 MFT records, 3,347 Amcache entries, 21 segmented disk images. At that scale, the system exposed four real failure modes: evidence dilution under high volume, query anchoring bias from earlier case hypotheses bleeding into new investigations, conclusion compression during summarization, and the mismatch between tool coverage metrics and actual investigative depth. One of these — the Recycle Bin payload — was identified only after targeted query expansion. We documented all four constraints in full because a system that knows its limits is more trustworthy than one that doesn't.
Injection prevention. The forensic environment involves real disk images, real subprocess calls, and real filesystem paths. A single unsanitized input reaching a shell command can be catastrophic. We implemented and tested over 400 injection patterns across the sanitization layer — not because we expected the model to try them, but because forensic tools get used in adversarial environments where evidence images may themselves contain crafted content.
Free tier constraints. Every run in this project — every case, every test, every replay — was executed on free API tiers. OpenRouter, Groq, Google AI Studio. No paid compute. This shaped the architecture: the system had to be efficient enough that a free-tier model could complete a full forensic investigation within a reasonable iteration budget. The 25-iteration limit per investigation was calibrated against this constraint.
The Case 4 precision problem. The Ali Hadi "Encrypt Them All" image is designed to trap over-eager systems. It contains AES encryption, BitLocker usage, and GPG artifacts. Any system prone to false positives will flag these. Our system found a 7-Zip installer and correctly classified it as benign. The challenge was not getting the right answer — the challenge was proving that the right answer held at both 20,000 records and 125,073 records, under two independent runs, in a way that a judge could verify directly from the committed logs.
Accomplishments That We're Proud Of
Zero hallucinations across seven real forensic cases. Not a synthetic benchmark. Real DFIR competition images from the SANS Find Evil! Hackathon 2026 evidence repository and the Ali Hadi challenge series. Cases spanning Windows 7, Windows XP, raw memory dumps, XAMPP web servers, and an encryption-focused challenge image. Seven cases, zero unproven findings in any final report.
Case 4 — the precision result that matters most. The assertion gate correctly produced zero malicious findings on an image full of encryption artifacts — at 20,000 records and at 125,073 records across two independent runs. Both logs are committed to the repository. Neither was removed. This is the result that separates a forensic tool from a liability.
The fileless malware detection (Cases 5 and 7). A disk image with zero suspicious artifacts. A memory dump from the same machine with 190 active C2 connections. No single-image tool reaches the correct conclusion. The system held both results simultaneously and derived the synthesis: fileless malware operating entirely in volatile memory, leaving no on-disk footprint. That is the kind of reasoning the research literature says AI forensic agents cannot reliably perform. We demonstrated it.
1,700 tests, zero failures. The test suite exists not to demonstrate performance but to prove the guardrails hold. Command injection is blocked. Temporal anomaly detection is correct. Audit trail integrity is maintained. These are not features — they are requirements for any tool that touches real evidence.
Full transparency on limitations. The Vanko case section in the documentation is not a concession — it is the most honest part of the submission. A system that documents exactly where its reasoning depth ends, derives a concrete roadmap from those observations, and acts on that roadmap immediately (removing the record cap, re-running Case 4) demonstrates something more valuable than a clean benchmark: it demonstrates engineering judgment.
What We Learned
The single most important lesson: the distinction between architectural guarantees and behavioral ones is not academic — it is the entire problem.
A model instructed to be careful will sometimes fail to be careful. A gate that rejects zero-row assertions will never accept a zero-row claim. These are not comparable reliability levels. The first depends on the model's internal state on a given token generation. The second depends on a Python if-statement. Forensic evidence standards require the second.
The Vanko case taught us that scaling forensic AI is not about adding more tools — it is about controlling reasoning depth under data pressure. At 20,000 records, the system performs well. At 194,000 records, it surfaces four distinct failure modes that were invisible at small scale. Evidence dilution, query anchoring bias, conclusion compression, and the mismatch between coverage metrics and investigative confidence are not edge cases — they are what happens when you stress any reasoning system against real-world data volume. Knowing this changes the architecture.
We also learned that the most important forensic result in our dataset is a zero. Case 4 produced no malicious findings — and that is harder to achieve correctly than any of the positive cases. Any system can find something. Knowing when to find nothing, and being able to prove that the nothing is correct, is the forensic discipline that separates evidence from noise.
Finally: free tier constraints are a forcing function for architectural efficiency. When you cannot throw compute at a problem, you have to understand the problem well enough to solve it cleanly. Every design decision in SIFT-PROOF was made under that constraint. We think the result is better for it.
What's Next for SIFT-PROOF
The Vanko case is the blueprint.
Evidence-first reasoning engine. Every conclusion backed by explicit SQL queries, reproducible result sets, and artifact-level provenance. No reasoning step accepted without a confirmable data source. This is the principle the current system implements — the next stage makes it mandatory at every layer of summarization, not just at claim submission.
Adaptive deep-search layer. A second-pass reasoning mode that activates when dataset size exceeds threshold or signal density falls below expected anomaly rate. At 194,000 records, the Recycle Bin payload was nearly lost in noise. The deep-search layer exists specifically to prevent that — targeted expansion when the evidence space is too large for linear traversal.
Multi-artifact correlation graph. Replace sequential artifact querying with a graph model: MFT ↔ Prefetch ↔ Amcache ↔ Registry ↔ EVTX, cross-linked by execution, persistence, and user activity chains. This enables kill chain reconstruction rather than isolated findings — the difference between "we found a suspicious executable" and "we traced its download, execution, persistence mechanism, and C2 communication as a single connected event chain."
Investigative confidence scoring. The current coverage metric measures tool execution completeness. The next metric measures artifact-level confidence — how well the evidence space has been explored relative to its anomaly density, not just whether each tool was called. This prevents false completion on large datasets where 100% tool coverage still leaves high-value artifacts unexplored.
Forensic explainability layer. Every finding ships with raw query, source table, evidence row preview, and explicit MITRE ATT&CK reasoning chain — not as documentation, but as a machine-readable output that investigators can audit independently of the agent's narrative summary.
The architecture is sound. The validation is real. The roadmap is derived from evidence, not aspiration.
We didn't prompt our way to precision. We engineered it. Then proved it.


Log in or sign up for Devpost to join the conversation.