-
-
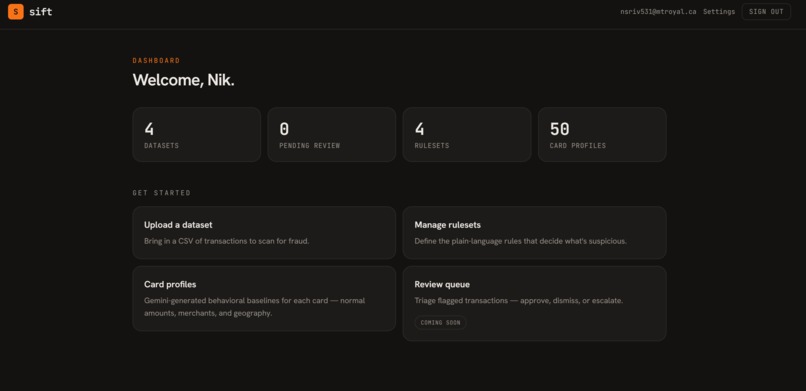
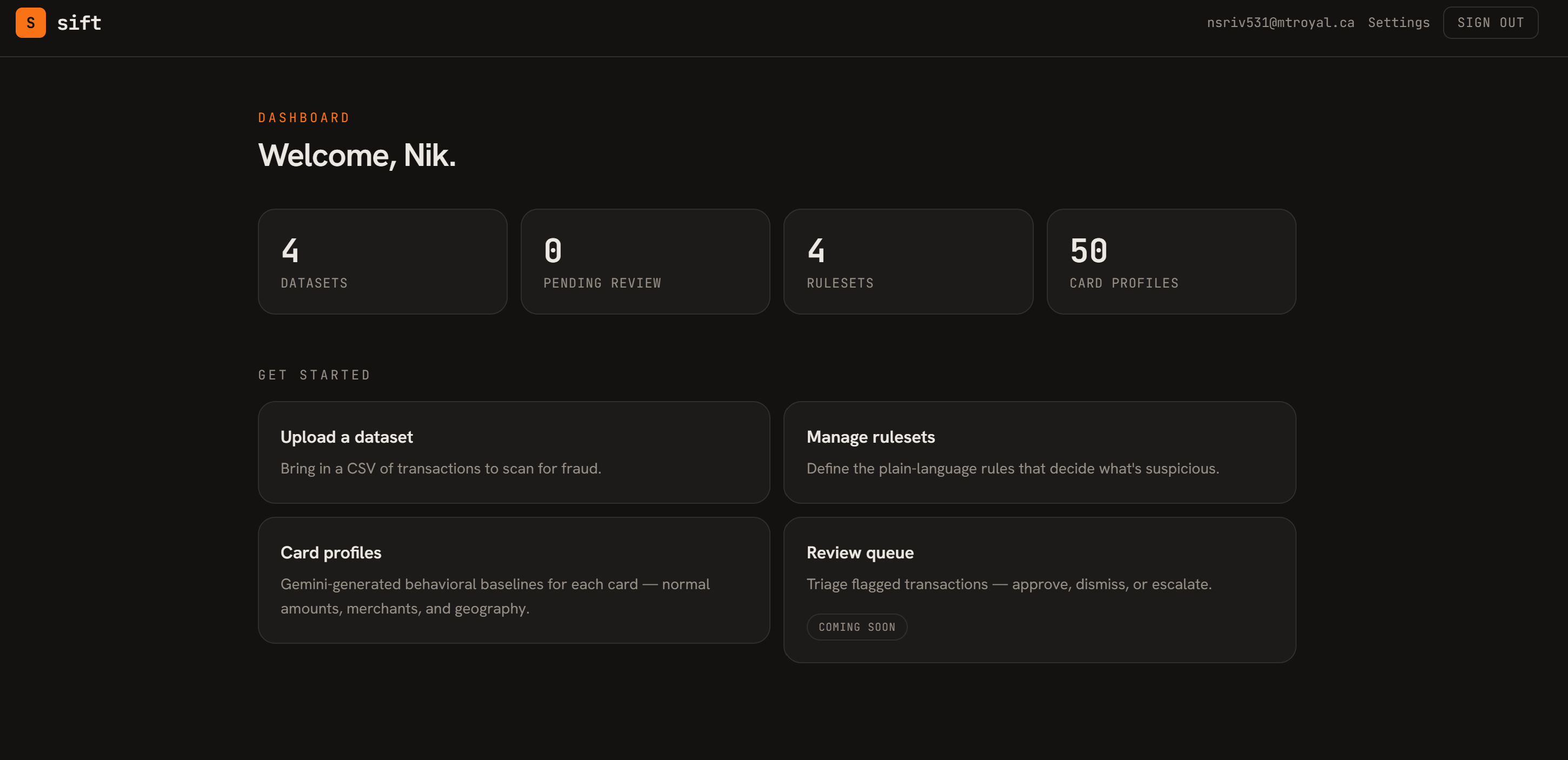
dashboard
-
-
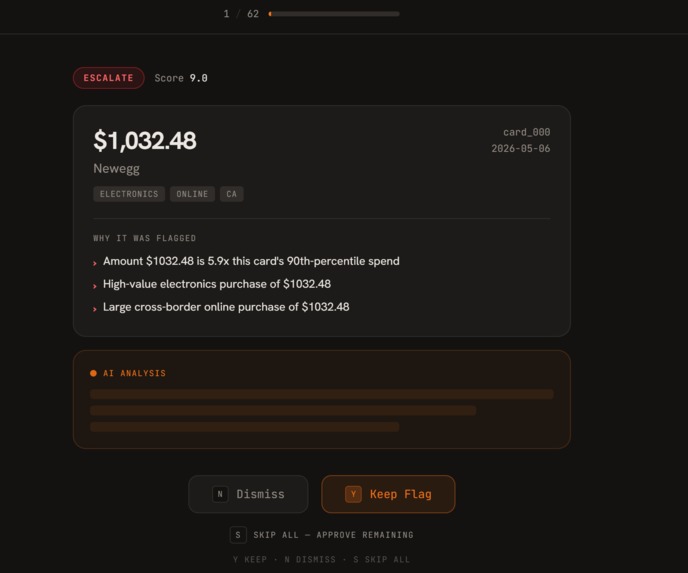
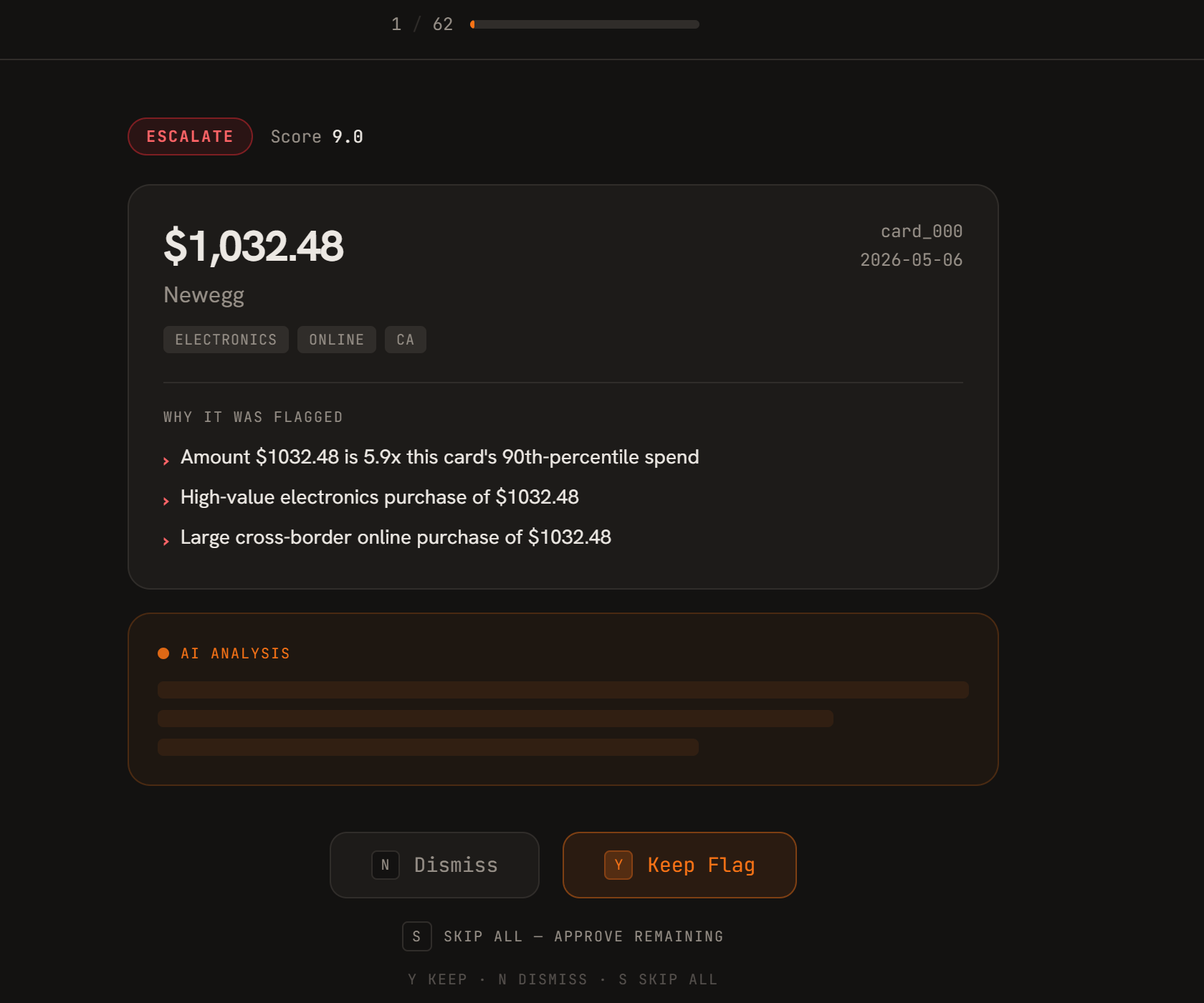
review process
Inspiration
I was inspired by the idea that fraud and anomaly detection should not only be available to large organizations with expensive enterprise tools. I wanted to build a web app that could act as a cheaper and easier-to-use alternative for people and teams that work with sensitive or messy data, especially in industries like finance, oil and gas, operations, and compliance.
I also wanted Sift to be useful for people who may not be deeply technical or data-literate. Instead of expecting users to understand complex machine learning outputs, I focused on clear flagged rows, plain-language explanations, and an interface that could fit naturally into an existing work environment.
What it does
Sift lets users upload tabular datasets, such as transaction CSV files, and automatically scans them for suspicious or unusual rows. The system applies a ruleset, calculates risk signals, and generates a separate flagged file that users can review or download.
Sift also uses generative AI to help explain why certain rows were flagged. Instead of only showing raw scores or rule names, the app can provide human-readable explanations that make the results easier to understand.
At its core, Sift is a human-in-the-loop triage tool. I did not want it to fully replace a reviewer. I wanted it to help surface the most suspicious records so that a person can approve, dismiss, escalate, or send them to someone else for further review.
How I built it
I built Sift as a web application with a layered detection pipeline.
The frontend provides a dashboard where users can upload datasets, view rulesets, and access flagged outputs. The backend handles file uploads, dataset records, generated files, and communication with the detection engine.
The detection engine is written in Python and processes uploaded CSV files using data analysis logic. It calculates signals such as transaction velocity, unusual amounts, shared identifiers, and relationship-based patterns. I also integrated graph-based analysis so the system can detect suspicious relationships across rows, such as shared devices, IPs, cards, or merchants.
On top of the rules and graph-based detection, I integrated generative AI so Sift can produce clearer explanations for flagged rows. This makes the system more useful for real review workflows because users can understand why something was flagged without needing to inspect every raw feature manually.
Challenges I ran into
One of the biggest challenges was implementing the full architecture in a way that actually worked end-to-end. Sift needed to handle file uploads, run Python-based detection, apply rulesets, generate new flagged files, and connect that output back to the web app in a stable way.
Another challenge was integrating generative AI in a way that worked with the Python graph and ruleset system. I did not want the AI to randomly decide what was fraud. Instead, I wanted it to explain the signals that the detection engine already found. Getting that balance right was difficult but important.
I also ran into challenges with the ruleset system. Rules can change over time, and different datasets may have different columns, formats, and types of data. I had to make the system flexible enough to support changing rules while still being structured enough to avoid breaking when the data looked different.
Accomplishments that I'm proud of
I am proud that Sift works as a fairly stable end-to-end prototype. A user can upload a dataset, run detection, generate a flagged output file, and use the system to better understand suspicious records.
I am also proud of how the project combines multiple ideas into one workflow: rule-based detection, graph-based analysis, human review, and generative AI explanations. Instead of building a simple AI wrapper, I built a system where AI supports the review process while the core detection logic remains explainable and structured.
Another accomplishment is that Sift feels like something that could be expanded into a real workplace tool. The workflow is practical, the interface is understandable, and the architecture leaves room for more advanced models later.
What I learned
I learned how to integrate generative AI in a way that is both useful and controlled. One major takeaway was that AI is most effective here when it explains and summarizes strong underlying signals rather than replacing the detection system entirely.
I also learned more about machine learning semantics, especially the difference between rule-based detection, graph-based detection, anomaly detection, and fine-tuned models. Sift helped me better understand where each type of model fits and why a fine-tuned model could be valuable when trained on the right review data.
Another key lesson was how useful it can be to host or integrate a fine-tuned model for a specific domain. A general AI model can explain patterns, but a domain-specific model could eventually learn what a specific team considers suspicious based on their own data and review history.
What's next for Sift
Next, I want to explore ways for Sift to integrate more naturally into real teams. For example, flagged files or high-risk rows could be sent directly to another user, such as a data scientist, analyst, compliance reviewer, or supervisor.
I also want to add team notifications so that important flagged results can be shared through email, dashboards, or workplace tools. This would make Sift more than just a file scanner. It could become part of an actual review workflow.
Something else I would like to add is more file-focused functionality. This could include support for more file types, batch uploads, file version history, file tagging, saved flagged reports, comparison between uploaded datasets, and easier ways to share generated files with other team members.
Another major next step is exploring how a fine-tuned model could improve the system over time. As reviewers approve, dismiss, or escalate flagged rows, that feedback could be used to train a model that better understands the patterns that matter to a specific company or industry.
Long term, I want Sift to become a flexible triage platform for many types of tabular data, not just financial transactions. The same architecture could be applied to fraud, operations, safety reports, compliance records, or any workflow where teams need to find risky rows quickly and explain why they matter.
Built With
- gemini
- mongodbatlas
- next.js
- python
- typescript


Log in or sign up for Devpost to join the conversation.