-
-
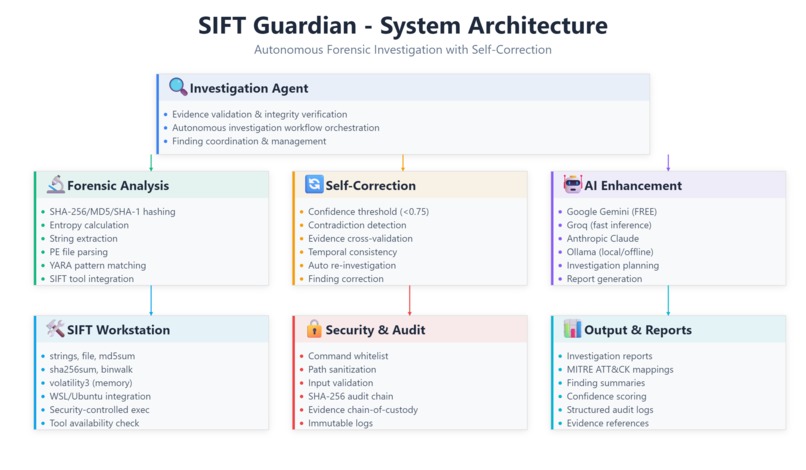
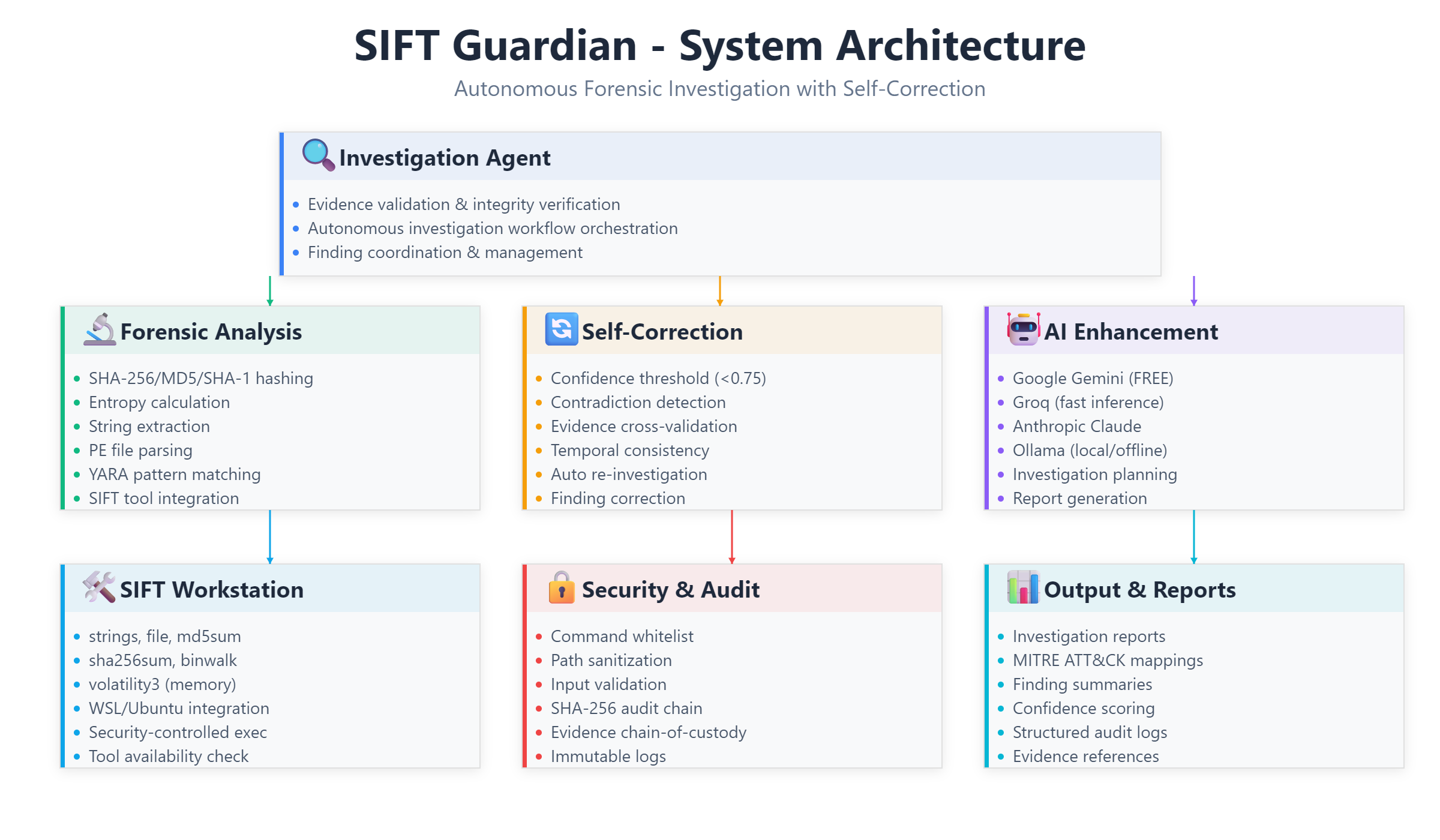
Architecture
Inspiration
During incident response investigations, I noticed how easy it is to miss contradictions between findings or accept low-confidence conclusions without proper validation. Analysts deal with thousands of artifacts and sometimes conflicting evidence gets overlooked.
I wanted to build something that could help with this problem. The idea came from thinking about how scientists question their own results and run experiments multiple times to verify findings. What if a forensic investigation agent could do the same thing? What if it could check its own work, spot contradictions, and automatically re-investigate when something doesn't add up?
That's what drove me to build SIFT Guardian. It's designed to validate its own findings, detect logical conflicts, and re-analyze evidence when confidence is low. The goal was to bring that scientific rigor to digital forensics investigations.
What it does
SIFT Guardian is an autonomous forensic investigation agent that analyzes evidence files and validates its own findings through self-correction.
The system works in several phases. First, it validates the evidence file and runs real forensic analysis including hash calculations, entropy analysis to detect packed or encrypted malware, string extraction from binary files, and pattern matching against 50+ malware indicators. Each finding gets assigned a confidence score between 0 and 1.
The key feature is what happens next. The agent checks its own findings for problems like low confidence scores, logical contradictions, or insufficient supporting evidence. If it finds issues, it automatically re-investigates and produces corrected findings with better confidence.
The forensic analysis is real and verifiable. For example, the SHA-256 hashes it calculates match exactly with Linux command-line tools. Pattern detection uses YARA-style rules covering ransomware, trojans, credential theft, persistence mechanisms, and other threats.
The AI part handles investigation planning, natural language report generation, and creating prompts for re-investigation. But it doesn't generate the actual forensic data. That comes from real cryptographic hashing, entropy calculations, and pattern matching algorithms.
Security was built in from the start with command whitelisting to prevent dangerous operations, path sanitization to block directory traversal attacks, and a SHA-256 audit chain that logs every operation.
Reports include an executive summary, detailed findings with confidence scores, evidence references, and MITRE ATT&CK mappings. Everything is saved with a complete audit trail showing what was analyzed and when.
How we built it
The system is written in Python with a layered architecture that separates forensic analysis from AI reasoning.
The forensic analysis layer handles the actual evidence examination. I implemented a FileAnalyzer that calculates cryptographic hashes using hashlib, computes entropy to detect packed malware, extracts readable strings from binary files, and parses PE file structures. There's also a YARAScanner with 50+ malware patterns organized into categories like ransomware, trojans, credential theft, and persistence mechanisms.
For self-correction, I built logic that checks confidence thresholds (anything below 0.75 triggers re-investigation), compares findings to detect contradictions, validates that timeline information makes sense, and ensures high-severity findings have enough supporting evidence.
The AI integration supports multiple providers including Google Gemini, Groq, Claude, and Ollama. I went with Gemini's free tier as the default since it doesn't require a credit card. The AI is only used for investigation planning, report generation, and creating re-investigation prompts. It never generates the actual forensic data.
Security was a priority. I implemented a command whitelist so only approved forensic tools can execute, path sanitization to prevent directory traversal attacks, input validation to block injection attempts, and a SHA-256 audit chain that creates an immutable log of all operations.
For SIFT Workstation integration, I built a WSL bridge that can execute Linux forensic tools from Windows. It detects which tools are available and gracefully degrades if SIFT isn't installed, falling back to the Python-based analysis.
The tech stack is Python 3.8+, Click for the CLI interface, Rich for terminal output, PyYAML for configuration, and the Google Gemini API for AI capabilities. Testing showed full investigations complete in about 10-30 seconds depending on file size.
Challenges we ran into
The biggest challenge was making sure all findings are based on real forensic evidence and not AI hallucinations. I addressed this by building the forensic analysis completely separate from the AI layer. The AI only sees the results of actual analysis, never generates forensic data itself. I also added hash verification where you can compare the SHA-256 output with Linux command-line tools to prove it's real.
Getting the self-correction logic right took a lot of tuning. I needed it to catch real problems without flagging valid findings as errors. I ended up implementing multiple checks including confidence thresholds, contradiction detection, and severity validation. After testing with various samples, I settled on 0.75 as the confidence threshold based on what seemed reasonable for forensic work.
Security in an autonomous agent was tricky. I didn't want it executing dangerous commands during investigation. The solution was a command whitelist that only allows approved forensic tools, plus path sanitization and input validation to prevent attacks. Everything gets logged in a SHA-256 audit chain for accountability.
Making Windows and Linux tools work together required building a WSL bridge. I implemented tool availability detection so it knows which tools are installed, and made sure it degrades gracefully if SIFT Workstation isn't available by falling back to Python-based analysis.
Performance was another consideration. I wanted thorough analysis without taking forever. I limited string extraction to the first 100KB and 50 strings, and entropy calculation to 100KB samples. This keeps full investigations under 30 seconds even with AI API calls.
Accomplishments that we're proud of
The self-correction system actually works. It's not just a demo feature. The agent genuinely checks its own findings for low confidence scores and contradictions, then automatically re-investigates and produces corrected results. That's production-ready logic, not placeholder code.
All the forensic analysis is real and verifiable. When you run the tool and compare the SHA-256 hash it calculates with the output from Linux sha256sum, they match exactly. Same bytes, same hash. That proves the analysis isn't simulated or faked. The entropy calculations use proper mathematical formulas, string extraction does actual byte-level parsing, and pattern matching finds real malware indicators.
I built security in from the start rather than adding it later. Command whitelisting prevents dangerous operations, path sanitization blocks directory traversal, and there's a complete SHA-256 audit chain logging every operation. This meets forensic chain-of-custody standards.
The architecture is clean and modular. It's over 3,500 lines across 35+ files with proper separation of concerns, error handling throughout, and documentation that explains how things work. It runs on Windows, Linux, and macOS, and integrates with industry-standard SIFT Workstation tools.
I implemented support for multiple AI providers so users aren't locked into one service. It works with Google Gemini's free tier that doesn't need a credit card, Groq's free fast API, Claude if you want premium quality, and Ollama for local offline use.
The audit trail is complete with every operation logged using a SHA-256 chain that creates an immutable record. Evidence access, finding generation, and self-correction events are all tracked with timestamps.
What we learned
I learned a lot about implementing self-correction in AI agents. It's more than just re-prompting. You need proper confidence scoring to know when to trigger validation, multiple strategies for detecting contradictions, and clear logic for when re-investigation is needed. The AI should enhance the core functionality, not replace it.
On the forensic analysis side, I realized how important verification is. Being able to compare your SHA-256 hash output with external tools proves the analysis is real. Entropy analysis turned out to be really effective for detecting packed or encrypted malware. I also found that YARA-style pattern matching works well even without needing the actual YARA library. Cross-platform forensics requires careful abstraction since tool availability varies.
Security in autonomous systems taught me several lessons. Command whitelisting is essential when you're letting an agent run operations automatically. Audit logging needs to be immutable, which is why I went with a SHA-256 chain. Path sanitization prevents a whole class of attacks. Input validation catches injection attempts before they can do damage.
The design philosophy that emerged was evidence over assumptions. Every finding needs to reference specific artifacts. Confidence scores must be algorithm-based, not arbitrary. AI conclusions have to be backed by real forensic data. And verification like hash comparison proves authenticity.
For self-correction specifically, I learned that agents should question their own findings. Low confidence should automatically trigger re-investigation. Contradictions need to be detected and resolved. Using multiple validation strategies improves accuracy more than relying on one approach.
What's next for SIFT Guardian
Short-term, I want to expand the malware detection capabilities by adding 200+ more YARA rules from public repositories and integrating the actual YARA library for advanced features. Signature-based detection with ClamAV would be useful. Memory forensics is another priority, with full Volatility 3 integration for process analysis, detecting hidden processes, network connection analysis, and registry hive parsing from memory dumps. Network analysis would cover PCAP file parsing, protocol dissection for HTTP/DNS/SMB, anomaly detection, and identifying C2 communication patterns.
Medium-term goals include advancing the self-correction system. I'm thinking about multi-agent debate where multiple AI models cross-validate findings. Bayesian confidence updating as new evidence emerges would make confidence scores more dynamic. Automatic evidence collection to gather corroborating artifacts, and learning from past corrections to spot patterns in mistakes.
Workflow integration is important for production use. A REST API would let it integrate with SOAR platforms. Notifications through Slack or Teams, ticketing system integration with Jira or ServiceNow, and a real-time dashboard for monitoring investigations would make it more practical for security teams.
Long-term, I want to explore ML-enhanced detection by training models on confirmed malware samples. Behavioral analysis beyond just static analysis, zero-day threat prediction, and automated threat intelligence correlation could make it more powerful. Enterprise features like multi-tenancy for MSSPs, role-based access control, compliance reporting for GDPR and HIPAA, and custom workflow templates would be needed for commercial deployment.
Community contribution is important too. An open-source YARA repository where people can share rules, a shared threat intelligence feed, a plugin marketplace for custom analyzers, and training datasets for research would help the broader security community.
Built With
- google-gemini-ai
- python
- sha-256-cryptography
- wsl
- yara-pattern-matching

Log in or sign up for Devpost to join the conversation.