-
-

Sift logo
-
100,377 → 15 verified, finding + ESR recommendation
-
3 agent roles + 4 read-only tools
-
Voyage retrieval scored 0.83 / 0.72 / 0.67
-
Hash-bound human approval gate
-
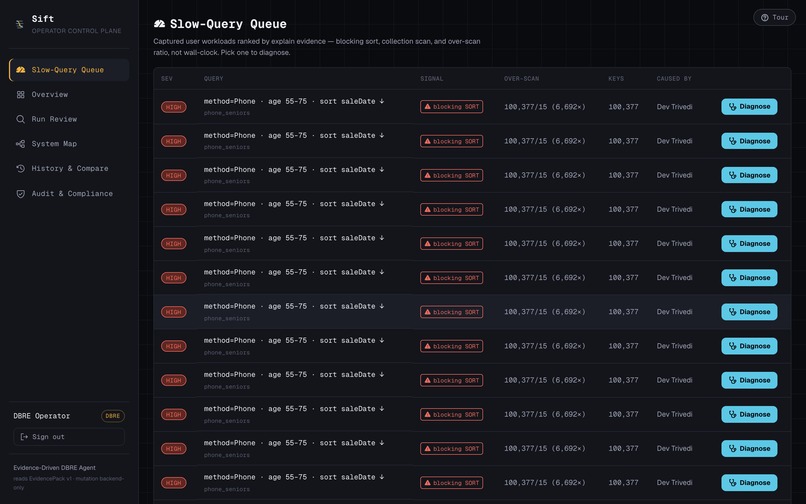
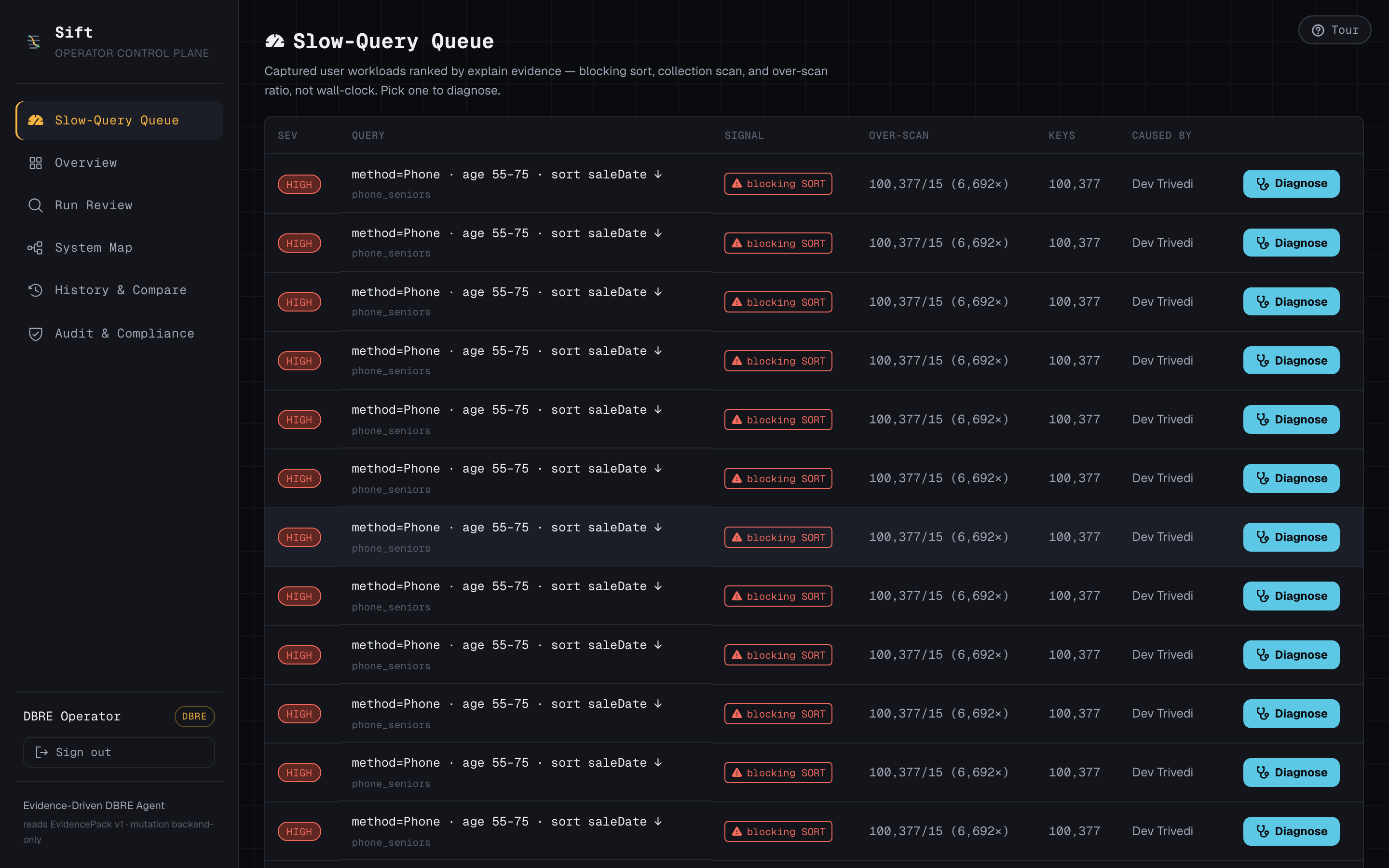
Evidence-ranked slow-query queue
-
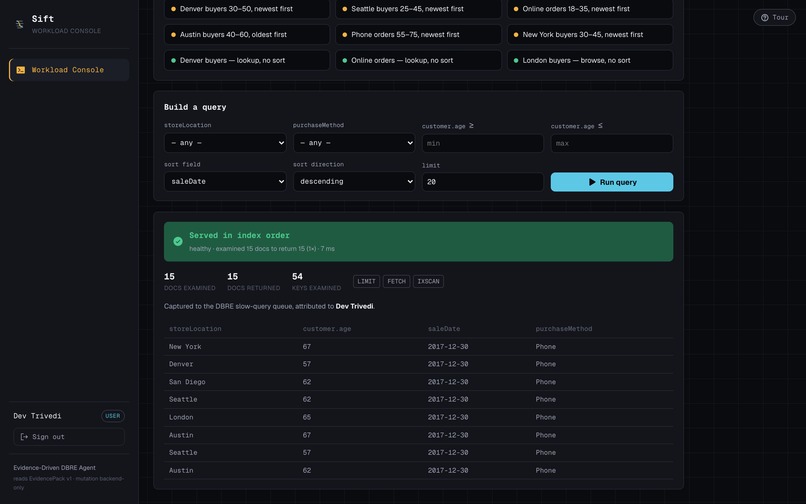
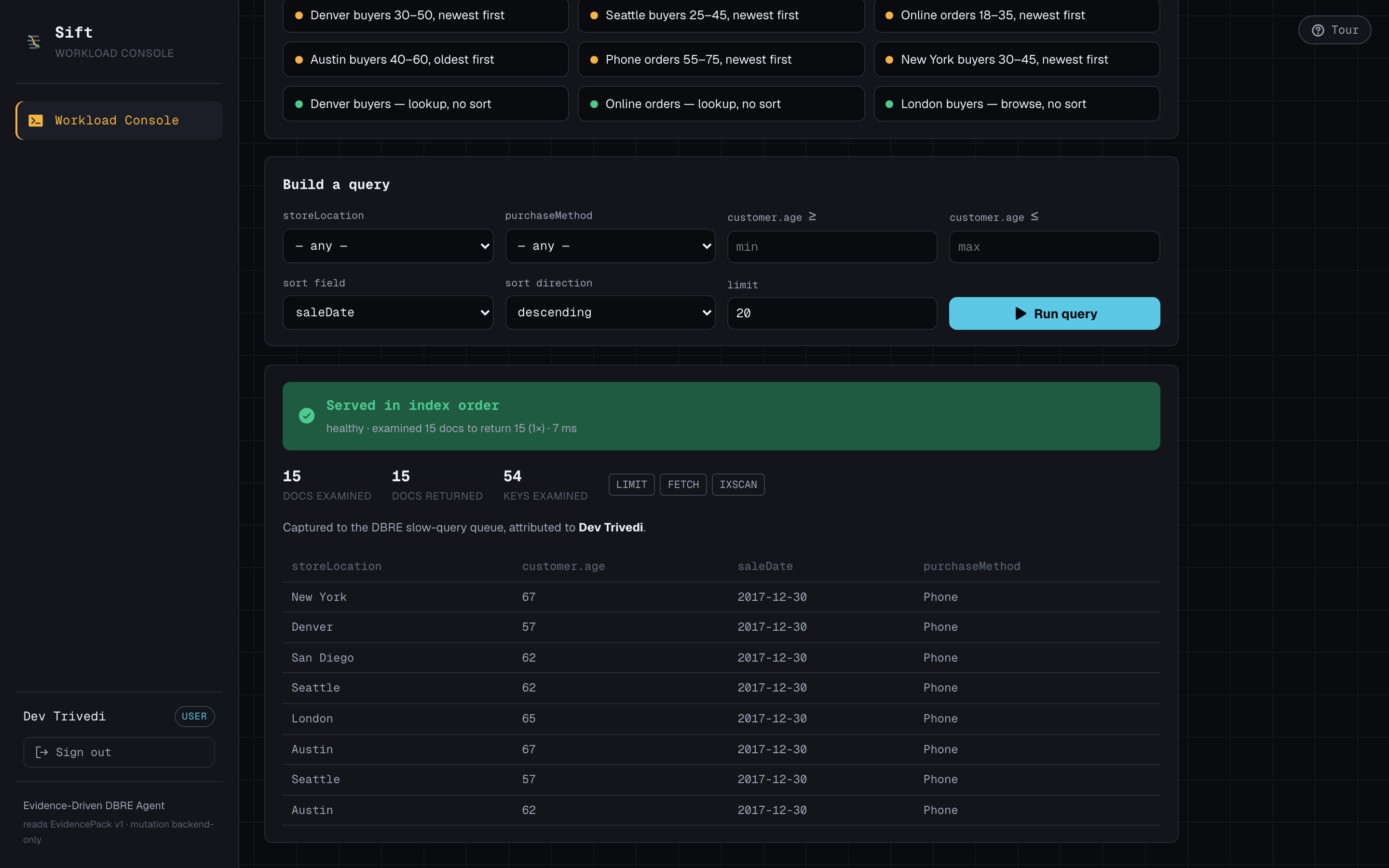
Live query, blocking sort, 100k docs
-
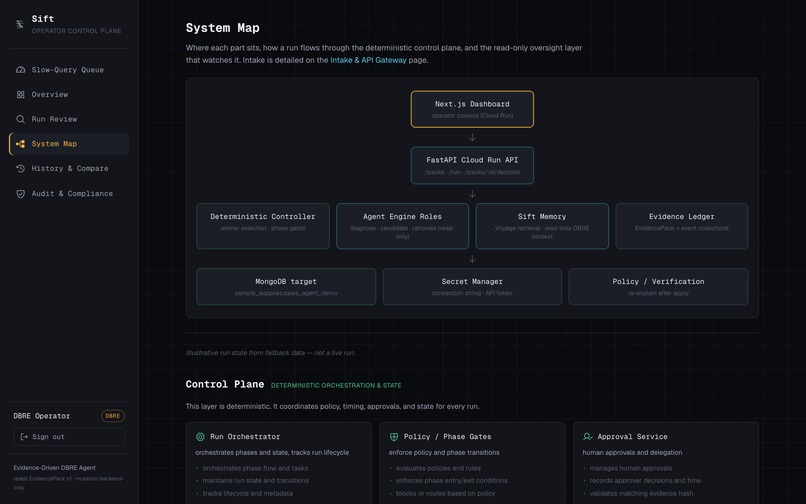
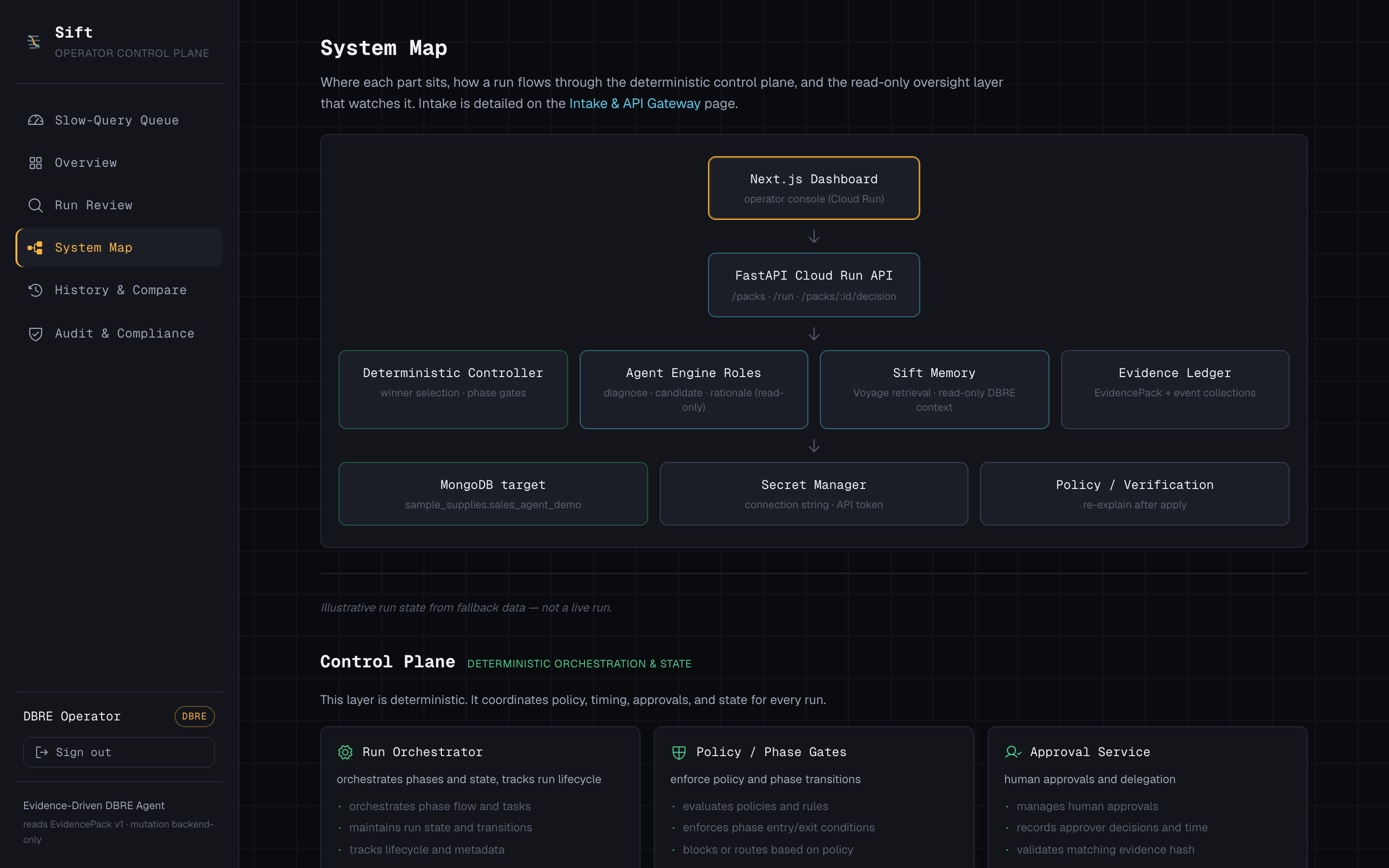
Architecture / safety boundary
-
Sift login

Inspiration
Most teams find out about a slow database query the worst way possible: an angry user, or a 2 a.m. page. By then it's already an incident. We kept asking a simpler question — the evidence was there the whole time, so why did a human have to get paged to go find it?
But we'd also seen the other failure mode: an "AI DBA" that confidently runs
ALTER/createIndex against production and gets it wrong. A wrong index isn't a
typo — it's a write to a live database. So we set out to build an agent that is
genuinely useful and can't hurt you: it finds your slowest MongoDB queries from
real evidence and fixes them safely, with a human in the loop and proof at the end.
We call it Sift.
What it does
Sift watches the queries your users actually run, ranks the worst offenders by hard
explain evidence, diagnoses the top one with a team of Gemini agents, and then —
only after a human approves — applies the fix and proves it worked by re-running
the real query.
The demo follows two developers and one DBRE:
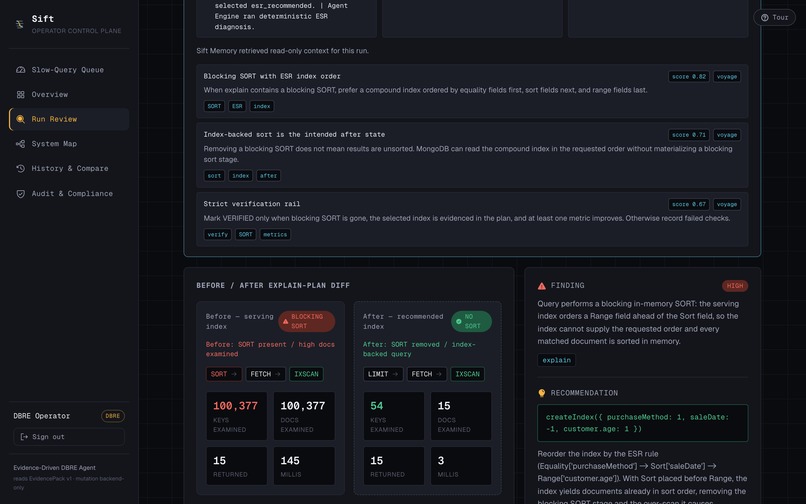
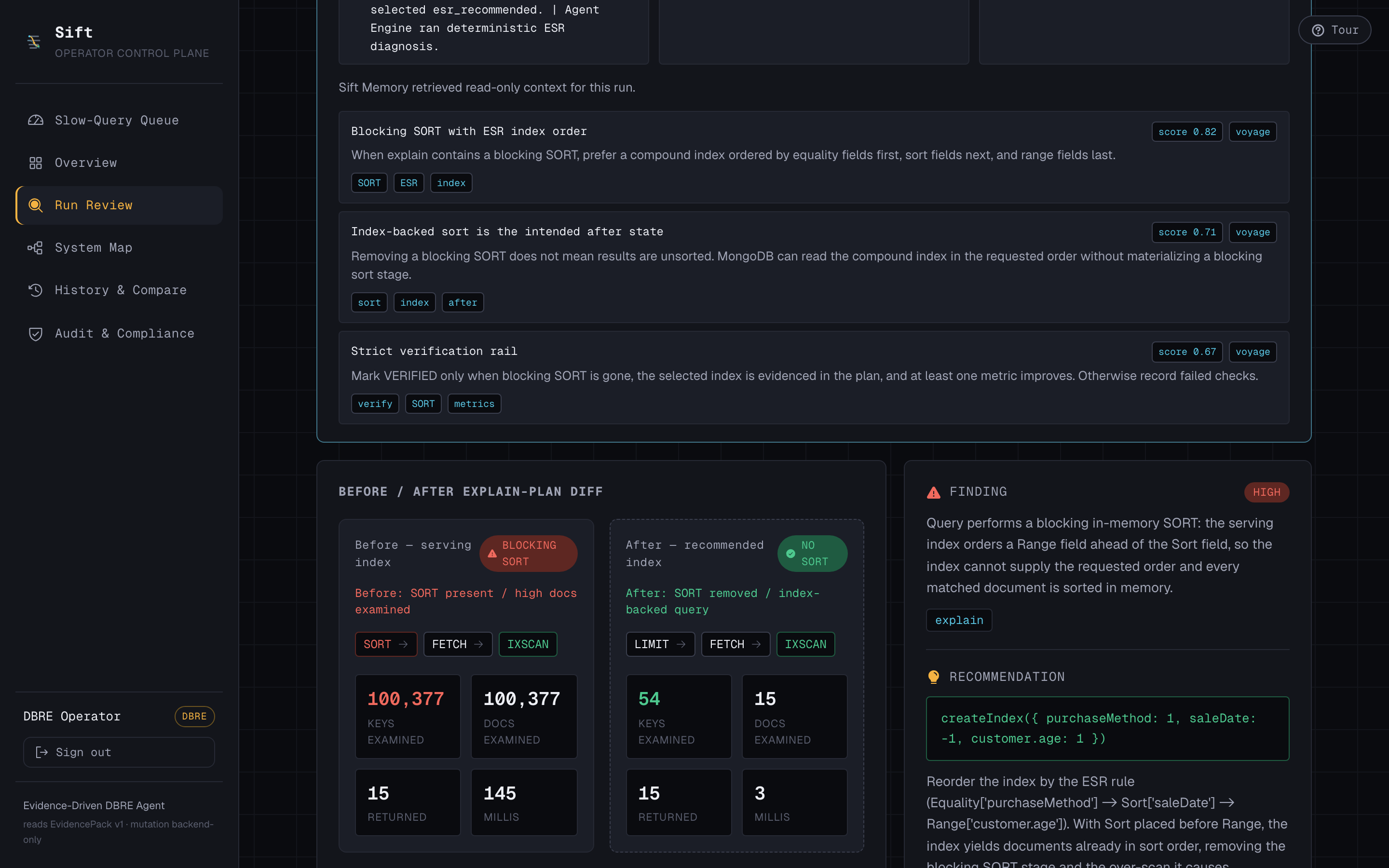
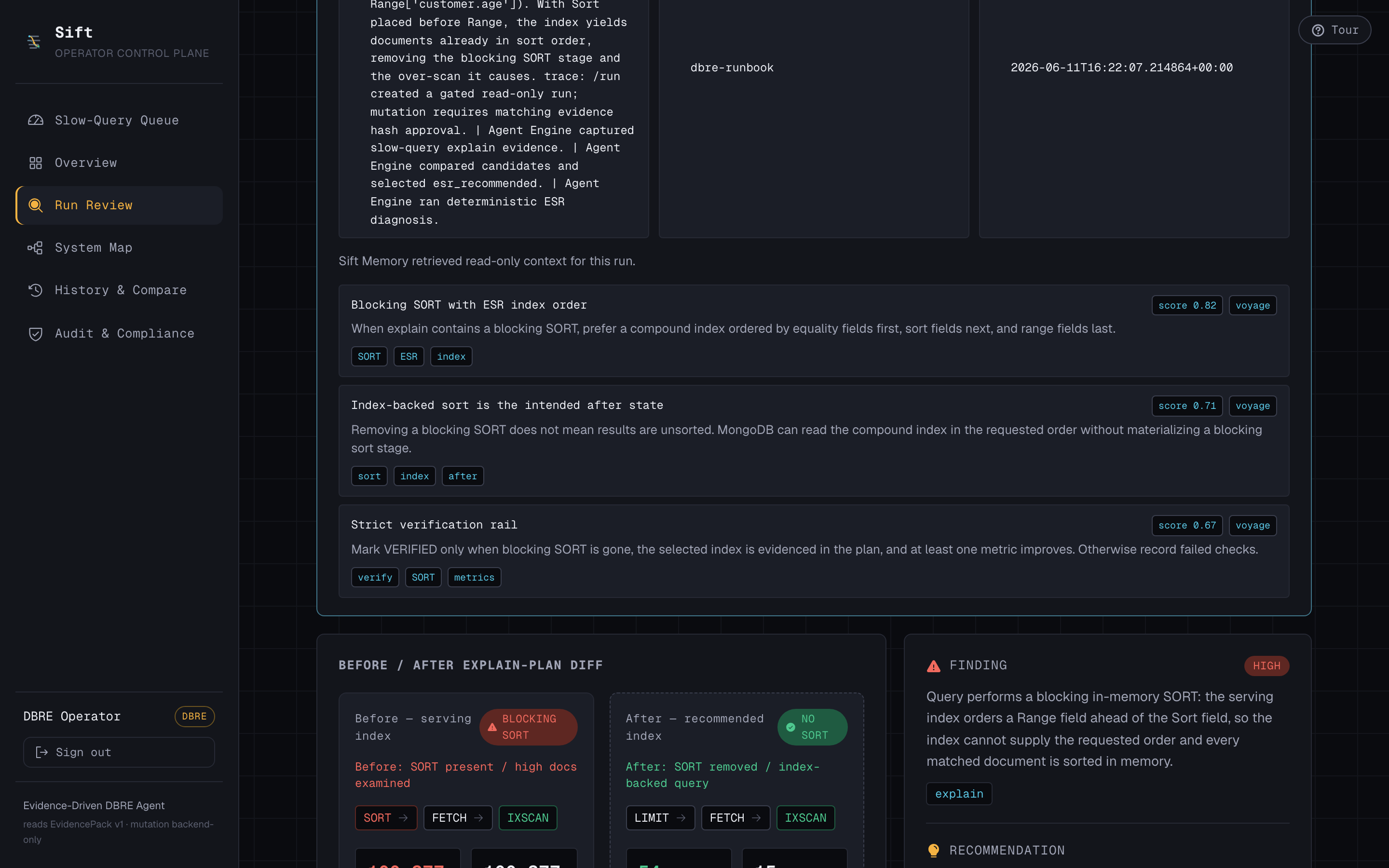
- Dev runs a phone-orders query against a live 300k-document Atlas collection. It's slow: a blocking in-memory sort scanning 100,377 documents to return 15. Sift captures the real explain plan and attributes it to Dev.
- Aakash runs a different slow query. Two users, two problems, both captured automatically with who caused them.
- The DBRE opens a queue ranked by evidence — over-scan ratio, blocking sorts, keys examined — not by guesswork.
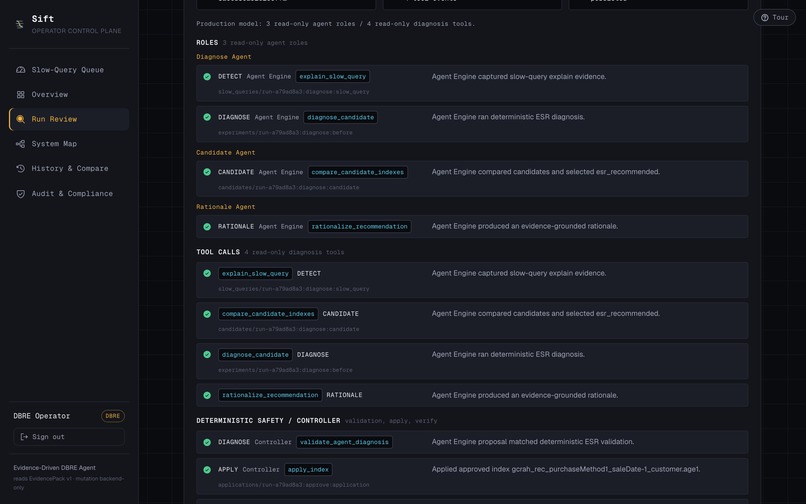
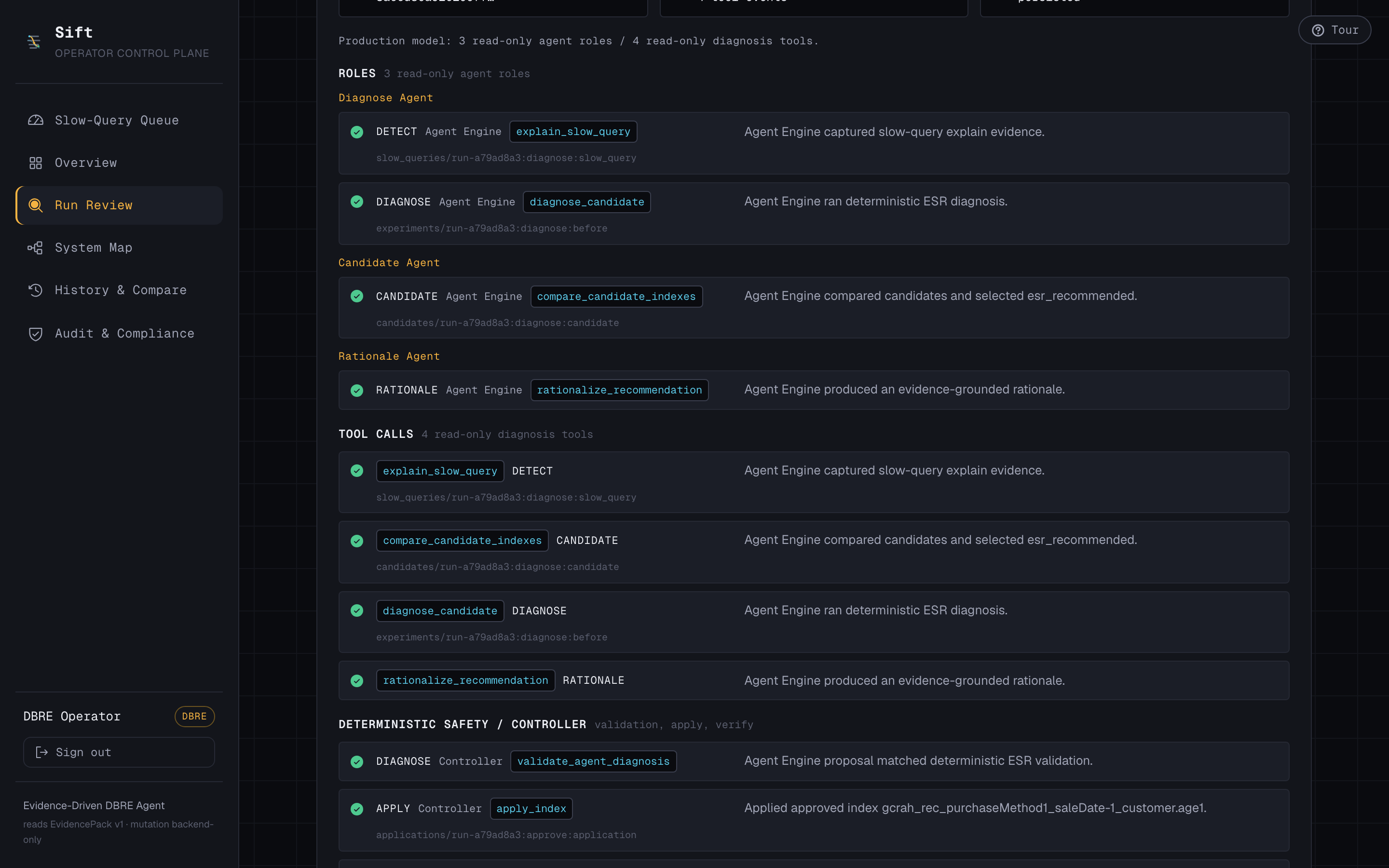
- They click Diagnose. Three read-only Gemini Agent Engine roles run four read-only tools and recommend an index.
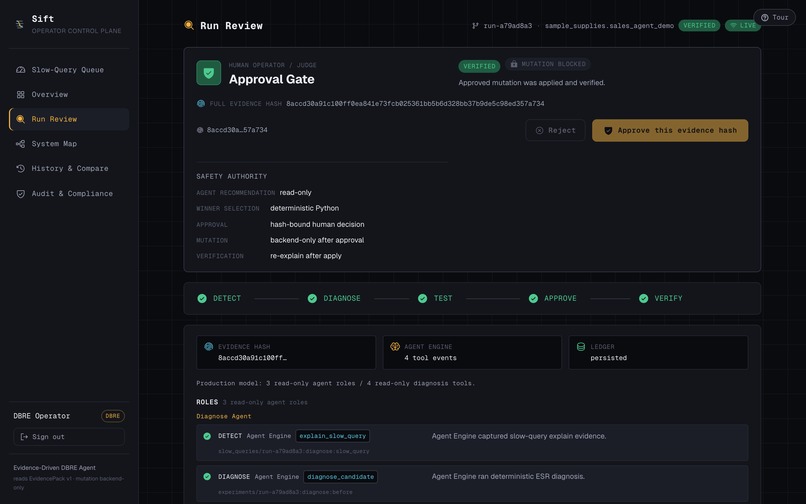
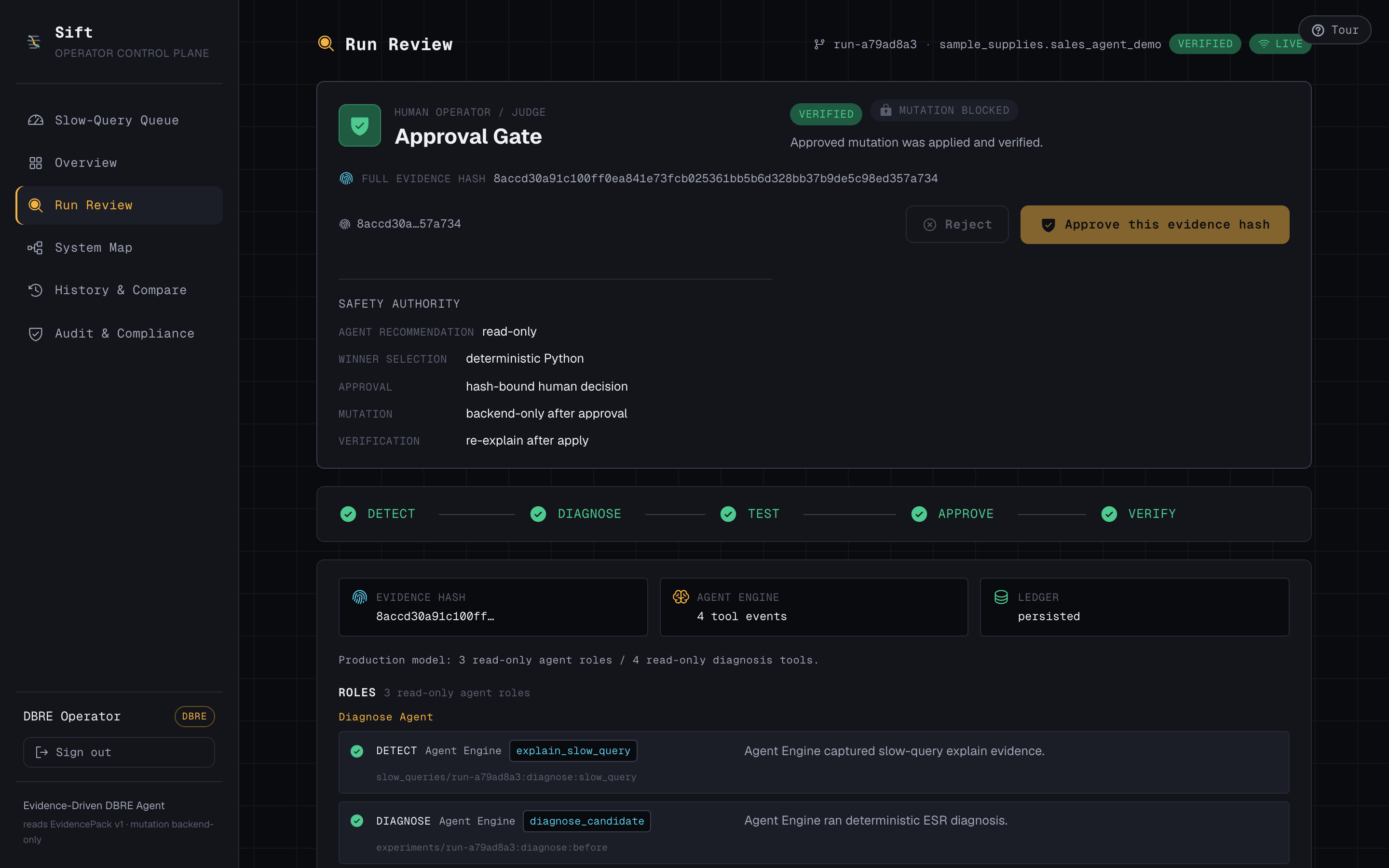
- Deterministic Python — not the model — selects the index, computes an evidence hash, and binds the human's approval to that exact hash.
- On approval, the backend builds the index and re-runs the query. Docs examined collapses 100,377 → 15, the blocking sort disappears, and the run flips to VERIFIED — because we measured it, not because the AI said so.
How we built it
- Agents: three split roles — diagnose, candidate, rationale — on Vertex
AI Agent Engine (ADK), each powered by Gemini. They have four read-only
tools:
explain_slow_query,compare_candidate_indexes,diagnose_candidate,rationalize_recommendation. None of them can write. - Partner integration (MongoDB track): the agents reach MongoDB through the MongoDB MCP server, and the whole system runs against a live Atlas collection.
- Deterministic controller: the actual decision is plain Python implementing the ESR rule (Equality → Sort → Range) for index ordering, plus an evidence hash and a hash-bound approval gate.
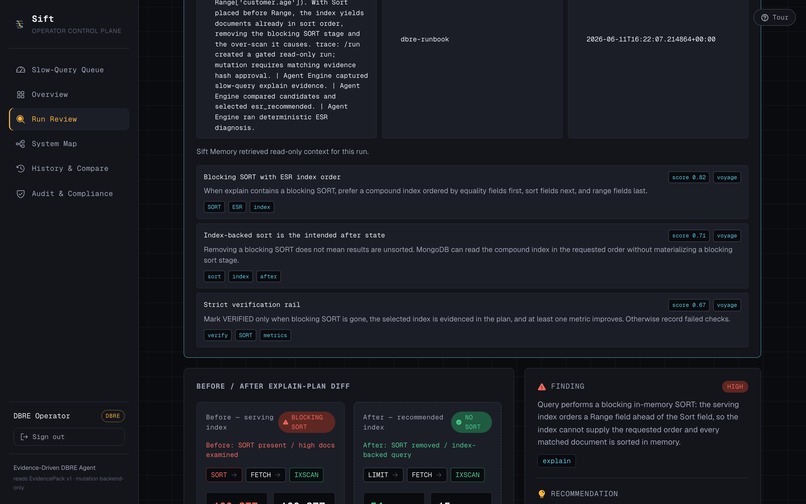
- Sift Memory: read-only runbook context retrieved and reranked by Voyage AI, scored and shown to the operator — advisory only, never a decision-maker.
- Surfaces: a FastAPI read API and a Next.js operator console, both on Cloud Run; an append-only evidence ledger for the audit trail.
The ranking is driven by a simple, honest signal — the over-scan ratio:
$$ r = \frac{\text{docsExamined}}{\text{docsReturned}} = \frac{100{,}377}{15} \approx 6{,}692\times $$
The safety model (the part we care about most)
AI recommends. Deterministic Python decides. A human approves. The fix is verified.
Every agent is read-only. The index choice is made by deterministic code, not the model. The human approves a specific evidence hash, so the thing they approve is exactly the thing that gets applied — no drift. And "fixed" is never the AI's word: it's the result of re-running the real query and measuring the new plan.
What we learned
- Let agents recommend, not decide. The moment a fix touches production, determinism and a human gate matter more than model cleverness.
- Verify by measurement, not assertion. Re-running the real query turns "the AI thinks this helps" into "docs examined went from 100,377 to 15."
- Read-only is a feature. Constraining the agents to read-only tools made the whole system easier to trust and easier to reason about.
Challenges we ran into
- Making the agent trace reliable. Live Agent Engine runs sometimes returned a thin trace (one tool event) and sometimes the full three-role / four-tool trace. We had to design around that variance so the evidence pack is always complete.
- Binding approval to evidence. Getting the evidence-hash gate right — so a human can't approve a plan that silently changed — took real care in the controller.
- Voyage rate limits. The free tier is 3 requests/minute; each memory lookup makes three calls, so retrieval kept falling back to local guidance. We added a per-run cache so a rate-limited request still serves the real Voyage-ranked context instead of a degraded fallback.
- Agent Engine + secrets. Wiring the deployed agents to fetch the MongoDB connection string from Secret Manager at tool-call time fixed a startup blocker and kept credentials out of the agent config.
What's next
Wire Sift into real slow-query logs (not just guided workloads), expand the deterministic playbook beyond index ordering (covered queries, shard keys), and add a rejection-learning loop so the DBRE's "no" teaches the next recommendation.
Sift: real users, real evidence — AI that recommends, deterministic Python that decides, a human who approves, and proof that it worked.
Built With
- atlas
- css
- fastapi
- gcp
- gemini
- javascript
- mcp
- mongodb
- nextjs
- pydantic
- python
- typescript
- vertex

Log in or sign up for Devpost to join the conversation.