
Inspiration
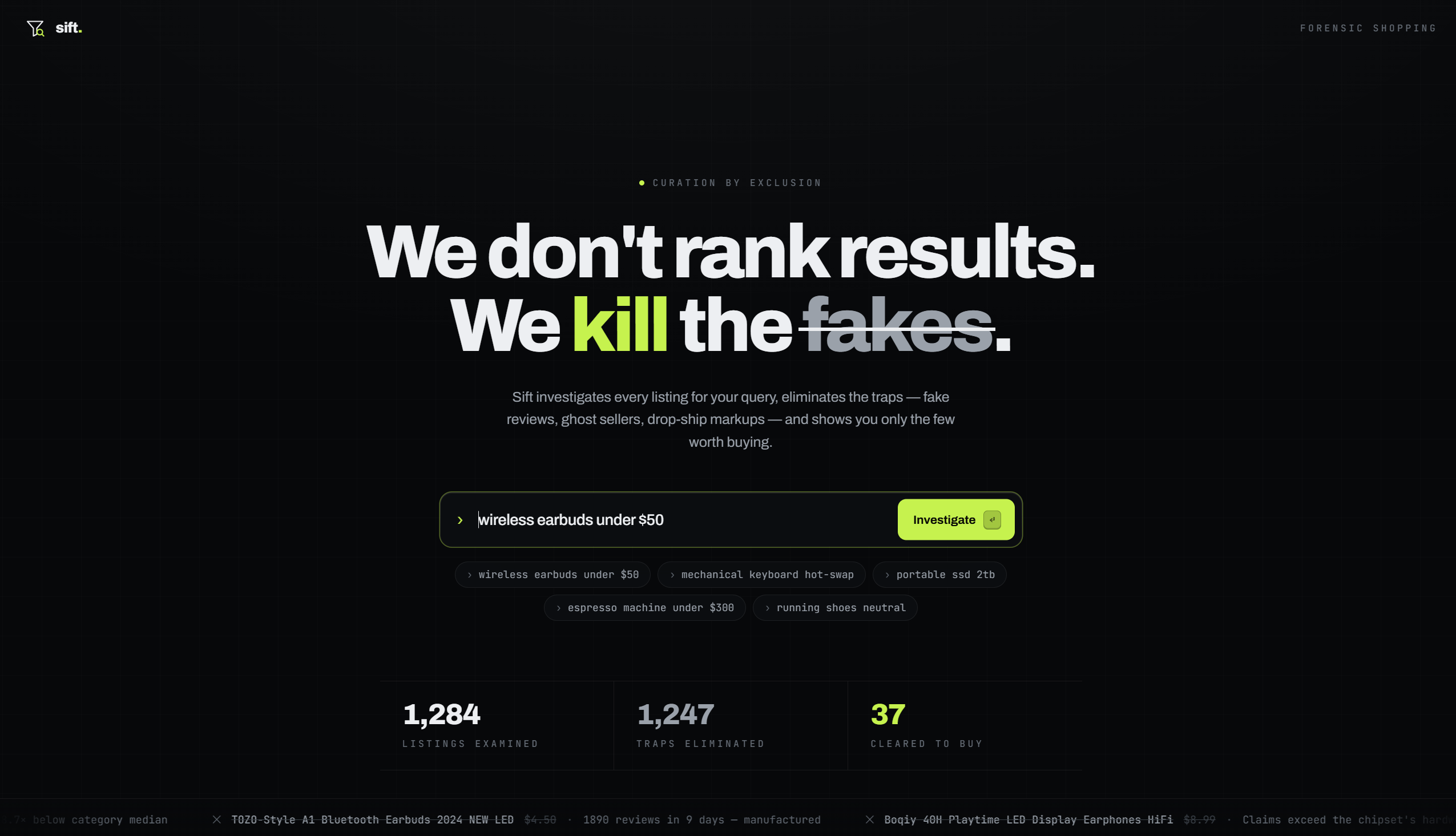
We picked the domain onlythebest.deals from Domain Roulette and the name clicked immediately. The only way to show "only the best deals" is to kill everything that isn't one. That's the whole idea: curation by exclusion.
The problem is real and personal. Every time you search for something like "wireless earbuds under $50" you get hit with 30+ listings. Most of them look fine on the surface. Star ratings, sale badges, "limited time" urgency. But if you actually dig in, half of them are $2 products from AliExpress marked up 8x, keyword-stuffed listings from sellers that registered last week, or "sales" where the original price was never real. Nobody has time to check all of that manually. So we built something that does.
What it does
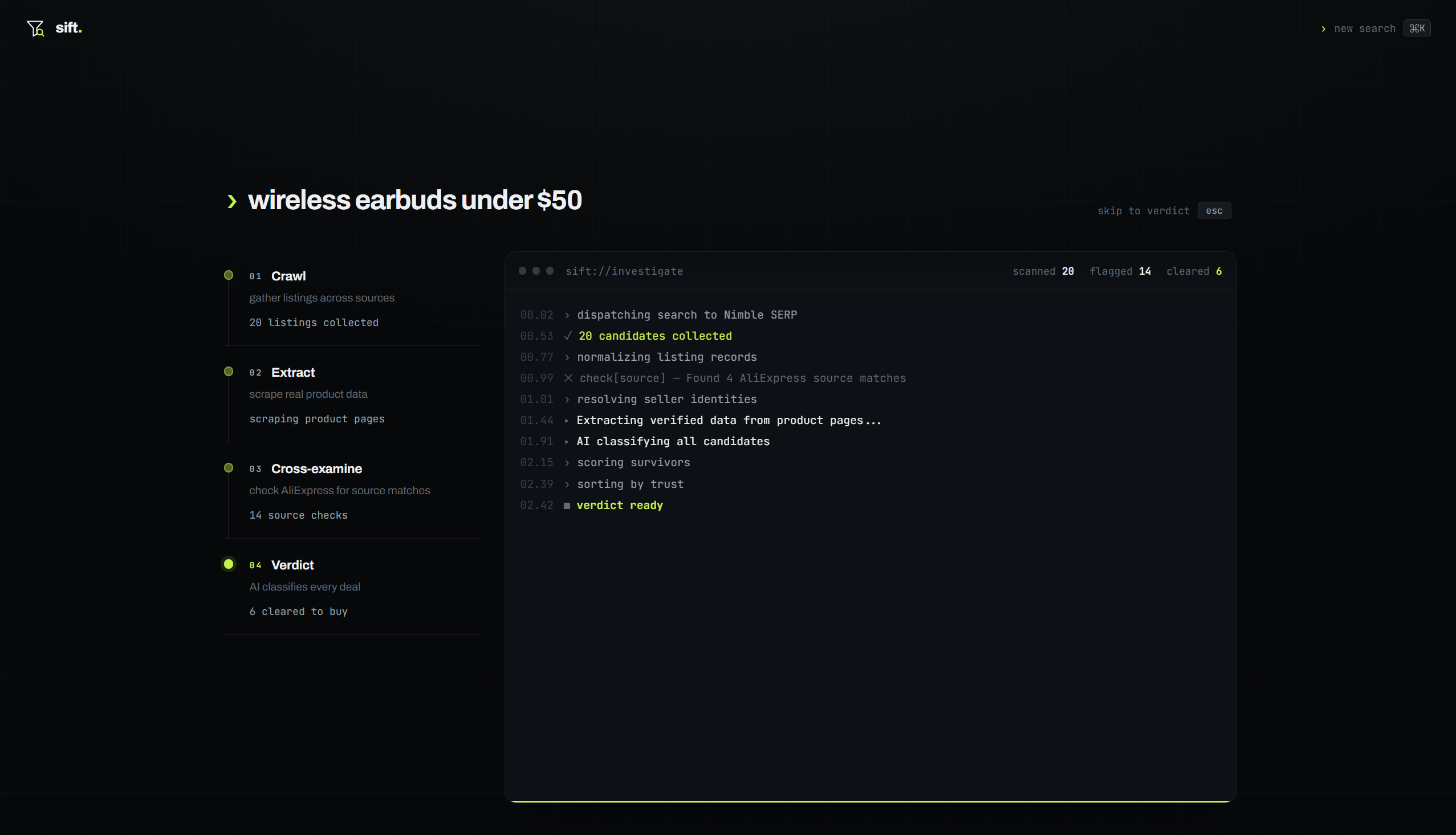
You type what you're looking for. Sift searches the web, finds 20-40 candidates, and investigates each one. It checks AliExpress to see if the same product exists at wholesale price. It scrapes real product pages from Walmart and Best Buy to verify the actual price, seller identity, review count, and rating distribution. Then it feeds everything into an LLM that classifies each deal as "trusted" or "trap" with specific evidence.
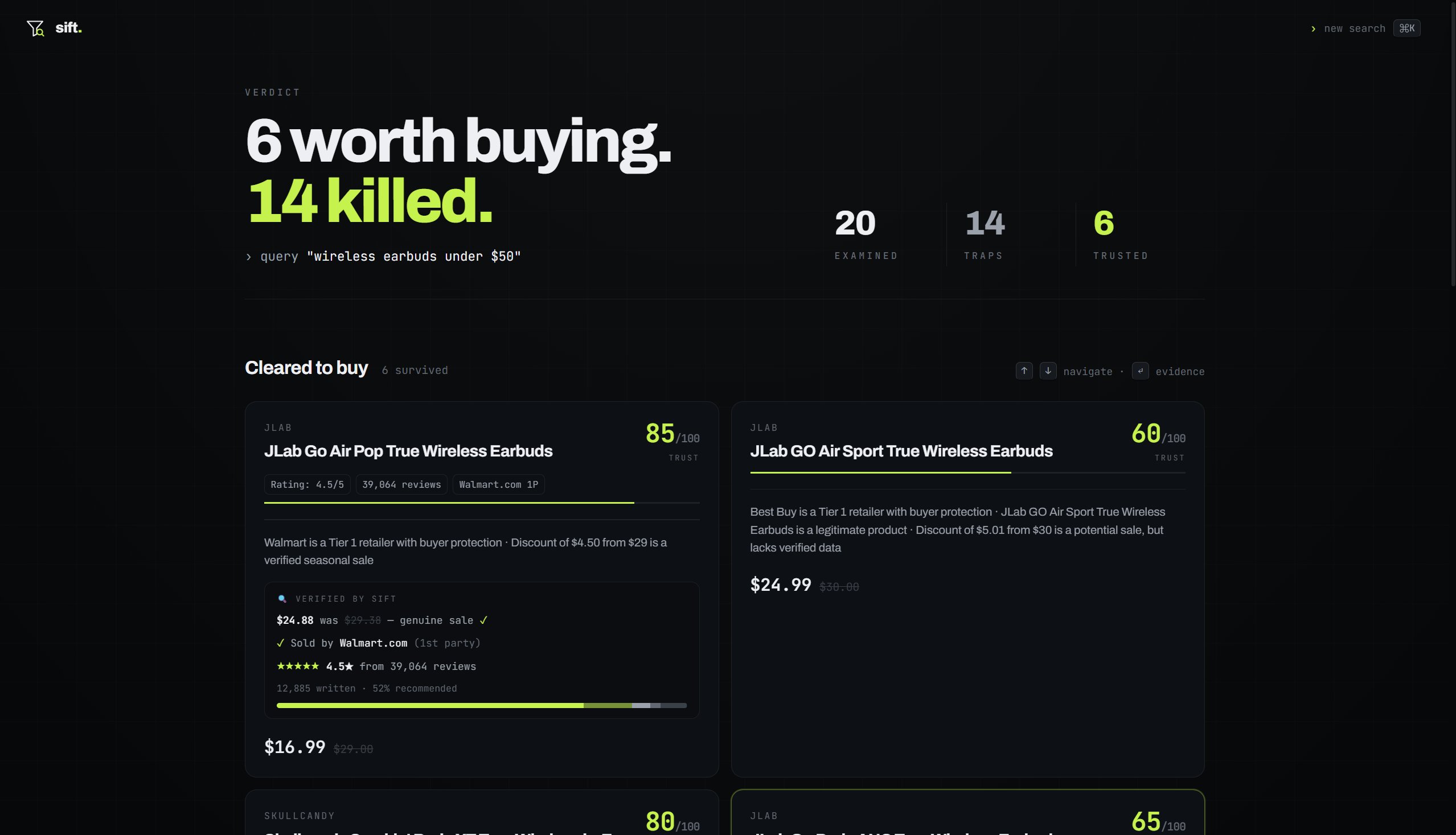
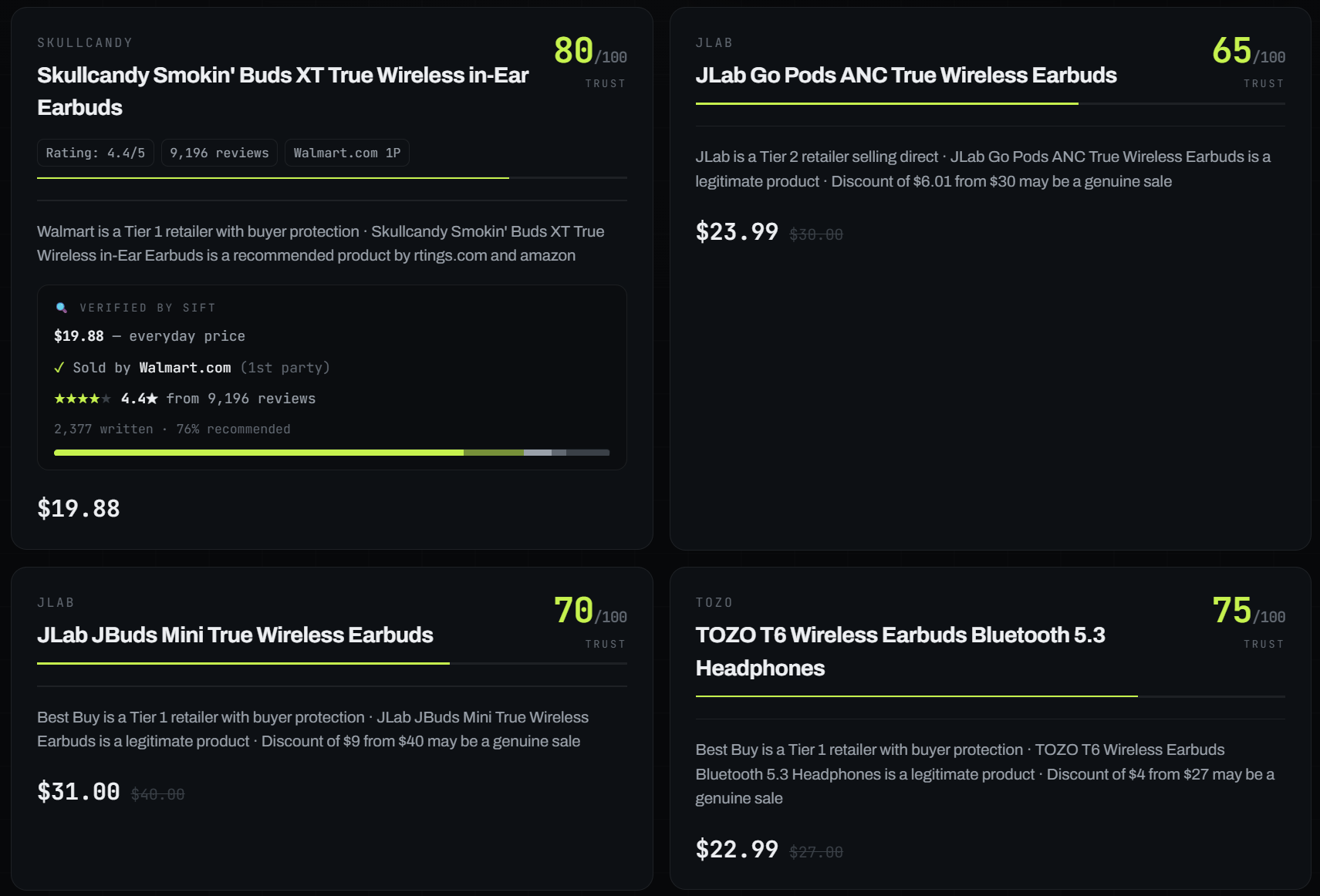
The result: "Checked 20 deals. 14 are traps. 6 you can trust."
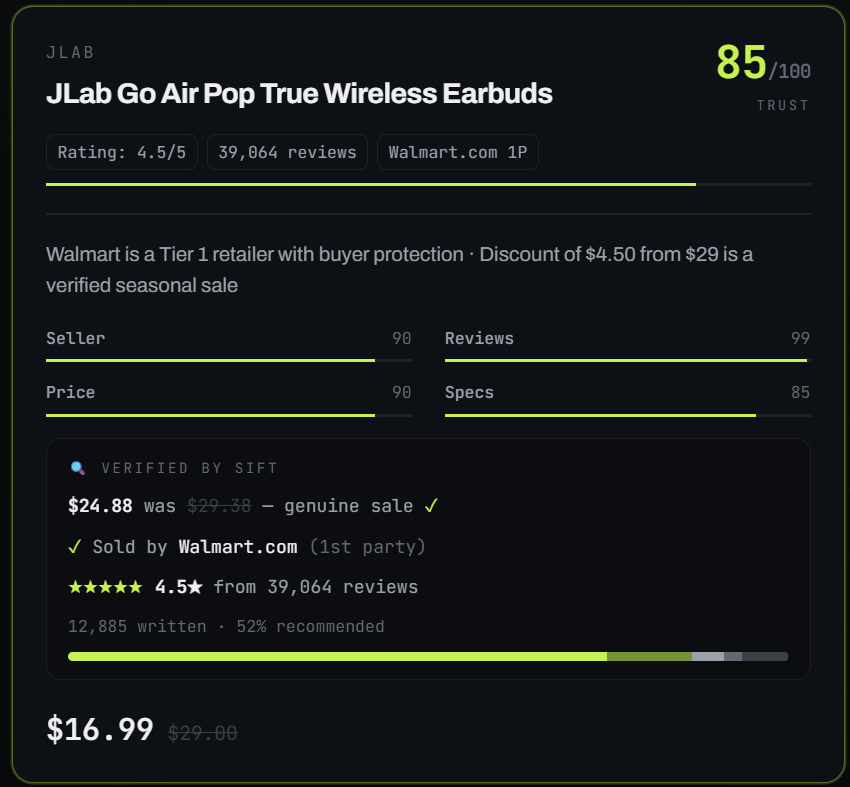
The trap wall shows everything we rejected. Hover any card and you get the rap sheet: "Found on AliExpress for $0.99, 5.1x markup" or "Title is keyword-stuffed spam" or "Unknown marketplace seller." The trusted shortlist shows what survived, with verified data from the actual product pages: real prices, seller identity, review counts, rating distributions.
The whole investigation streams live. You can watch the pipeline work in real time through a forensic console that shows each Nimble API call as it fires.
How we built it
The stack is Next.js 14 with TypeScript, deployed on Vercel. The investigation pipeline has four stages:
Search. We use Nimble's SERP API to find shopping candidates and organic review site context (rtings, CNET, etc). The organic results aren't treated as candidates but passed to the LLM as supporting evidence.
Source lookup. For suspicious candidates (low price, unknown merchant, keyword-stuffed title), we run a second Nimble SERP search against AliExpress to find the same product at wholesale. When we find a match, we calculate the markup.
Extract. For candidates from Walmart and Best Buy, we use Nimble's Web API to extract the real product page. This gives us verified price, seller name (1st party vs marketplace), review count, rating distribution, and whether the sale is genuine. We built separate parsers for Walmart's proprietary data shape and Best Buy's schema.org format.
Verdict. All the data goes into Groq (Llama 3.3 70B) with an aggressive investigation prompt. The LLM classifies each deal, assigns a trust score, and writes specific flags and evidence. We set temperature to 0 for deterministic results.
The API streams NDJSON progress events so the frontend can show the investigation happening in real time. For the demo, the golden query is pre-cached so it loads instantly.
The frontend follows a three-act structure: the landing manifesto, the forensic investigation console, and the verdict reveal with trap wall and trusted shortlist. Each component was built separately and then wired into the Next.js app.
Challenges we ran into
Nimble's response shapes were not what we expected. Google Shopping SERP results don't include product page URLs (item_link is empty), so we couldn't just scrape each listing directly. We had to build a URL discovery layer: search for the product title on the retailer's domain, find the product page, then extract it. Best Buy's canonical URLs also redirect to a new scheme that returns zero entities, so we had to target their reviews page instead, which is where the JSON-LD data actually lives.
AliExpress prices don't show up in search snippets. We planned to calculate exact markups by comparing the listing price to the AliExpress wholesale price, but only about 1 in 10 AliExpress snippets contain a price. We couldn't extract AliExpress pages directly either (they timeout without JS rendering). So we adjusted: when a price is available we show the exact markup, otherwise just the match itself is evidence of dropshipping.
The LLM kept being too lenient. Early runs classified 50%+ as trusted. Most SERP shopping results come from known retailers, and the LLM defaulted to trusting anything from Best Buy or Walmart. We had to iterate on the prompt heavily: adding tiered merchant trust rules, severity rules for deals without verified discounts, duplicate detection, and an explicit instruction to target 15-25% survival rate.
Accomplishments that we're proud of
The verified data is real. When a trusted card says "4.5 stars from 39,064 reviews, sold by Walmart.com (1st party), genuine sale," those numbers came from actually scraping the Walmart product page, not from the LLM making something up. That was the hardest part to get right and the most satisfying.
The AliExpress source matching works. Seeing "Found on AliExpress for $0.99, 5.1x markup" on a card that was listed for $5 on Walmart is exactly the kind of thing we wanted to expose.
The streaming investigation panel. Watching the pipeline work in real time, with each Nimble call showing up in the forensic console, makes the investigation feel tangible instead of just a loading spinner.
17/17 stress tests pass. Edge cases, concurrency, unicode, XSS injection, empty queries, all handled gracefully. The product doesn't crash.
What we learned
Test your APIs before you build against the docs. We burned time assuming Nimble's e-commerce endpoint accepted free-text queries (it needs a product URL), that Google Shopping results include item_link (they don't), and that Best Buy needs JS rendering (it doesn't). Every one of these assumptions was wrong. The de-risk script approach (one live call, inspect the response, then code) saved us from building on top of broken assumptions.
Cache your demo. The golden query is pre-cached and works without any API keys. This saved us multiple times when Nimble or Groq had hiccups during development. The demo never depends on live API calls.
LLM prompt engineering is iterative. Getting the trap/trusted ratio right took many rounds of tuning. The final prompt has tiered merchant trust, severity rules, product relevance filters, and explicit ratio targets. Each rule exists because a previous run produced a bad result.
What's next for Sift
More retailers. Right now we only extract from Walmart and Best Buy. Amazon, Target, and eBay are next. Each needs its own parser but the pipeline is built to support it.
Browser extension. The investigation engine could run as a browser extension that checks listings as you browse. Instead of coming to Sift with a query, Sift comes to you.
B2B risk API. The same investigation engine could be licensed to marketplaces to flag suspicious listings before they go live, or to payment providers for transaction risk scoring. Fake reviews and dropship markups cost the industry billions in chargebacks every year.
Real review analysis. Right now review authenticity is mostly LLM-inferred. We want to build temporal analysis (review velocity spikes, coordinated posting patterns) and verified-purchase ratio tracking using the review data we already extract.
Built With
- groq
- llama
- next.js
- nimble
- node.js
- react
- typescript
- vercel


Log in or sign up for Devpost to join the conversation.