-
-
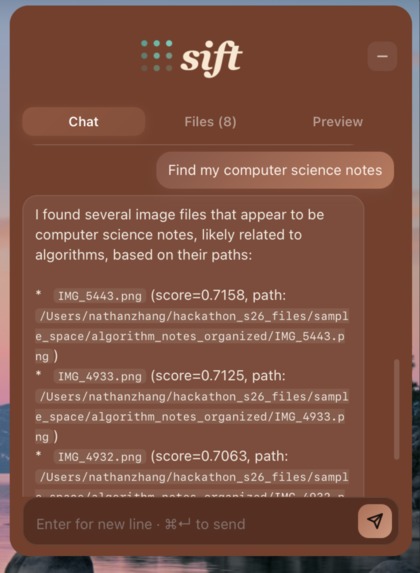
Embeddings are able to extract complex information from images, can semantically search
-

Preview files
-
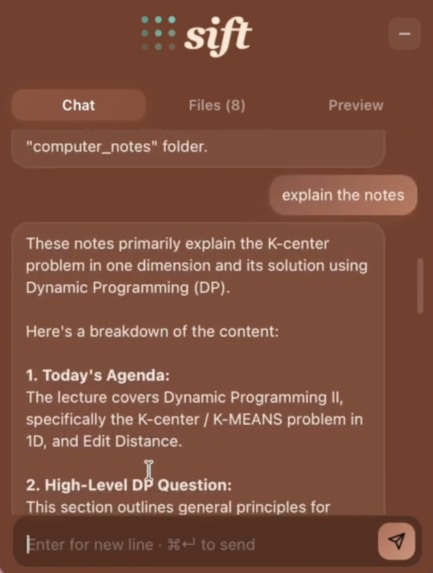
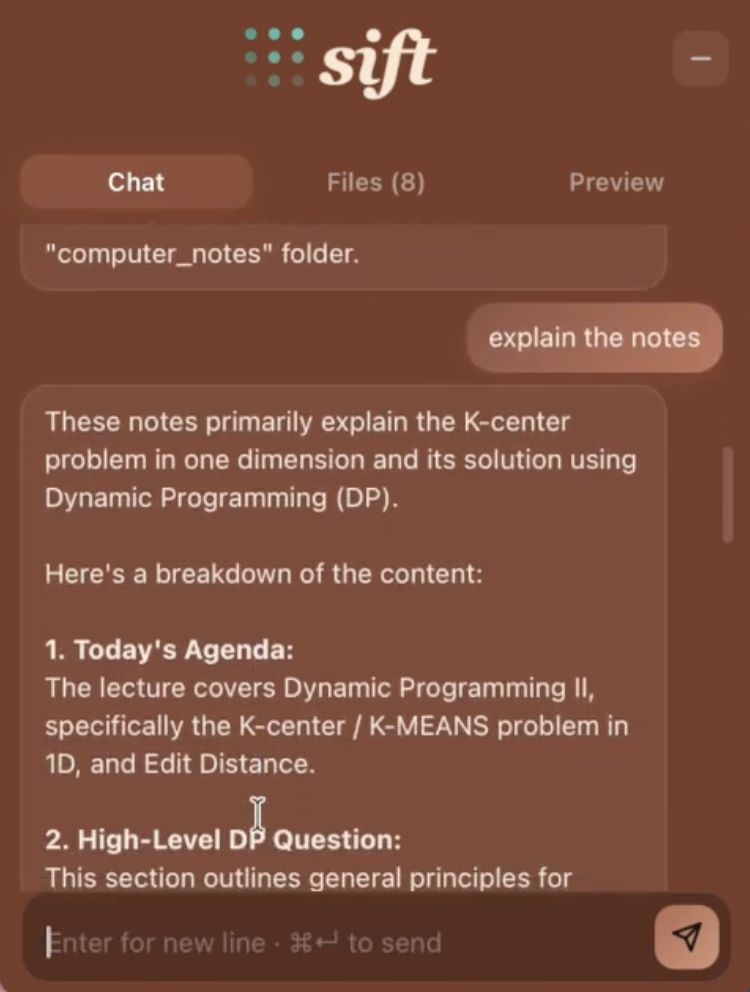
Can look through files and give explanations as needed
-
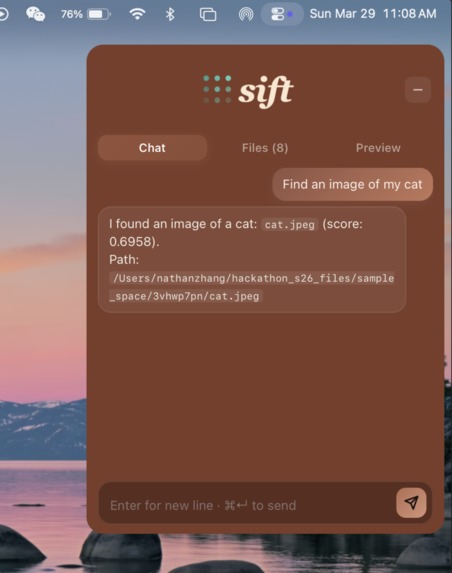
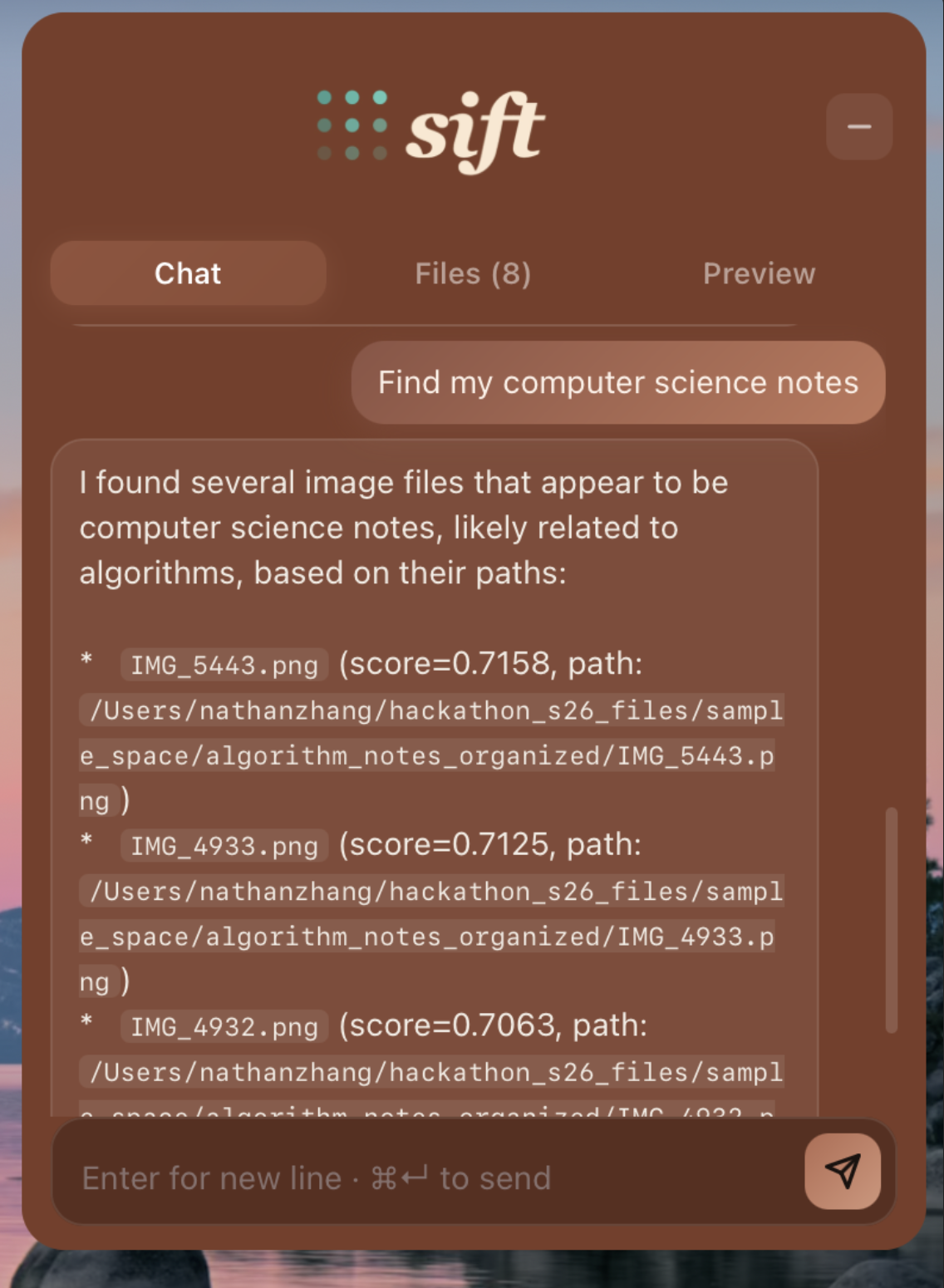
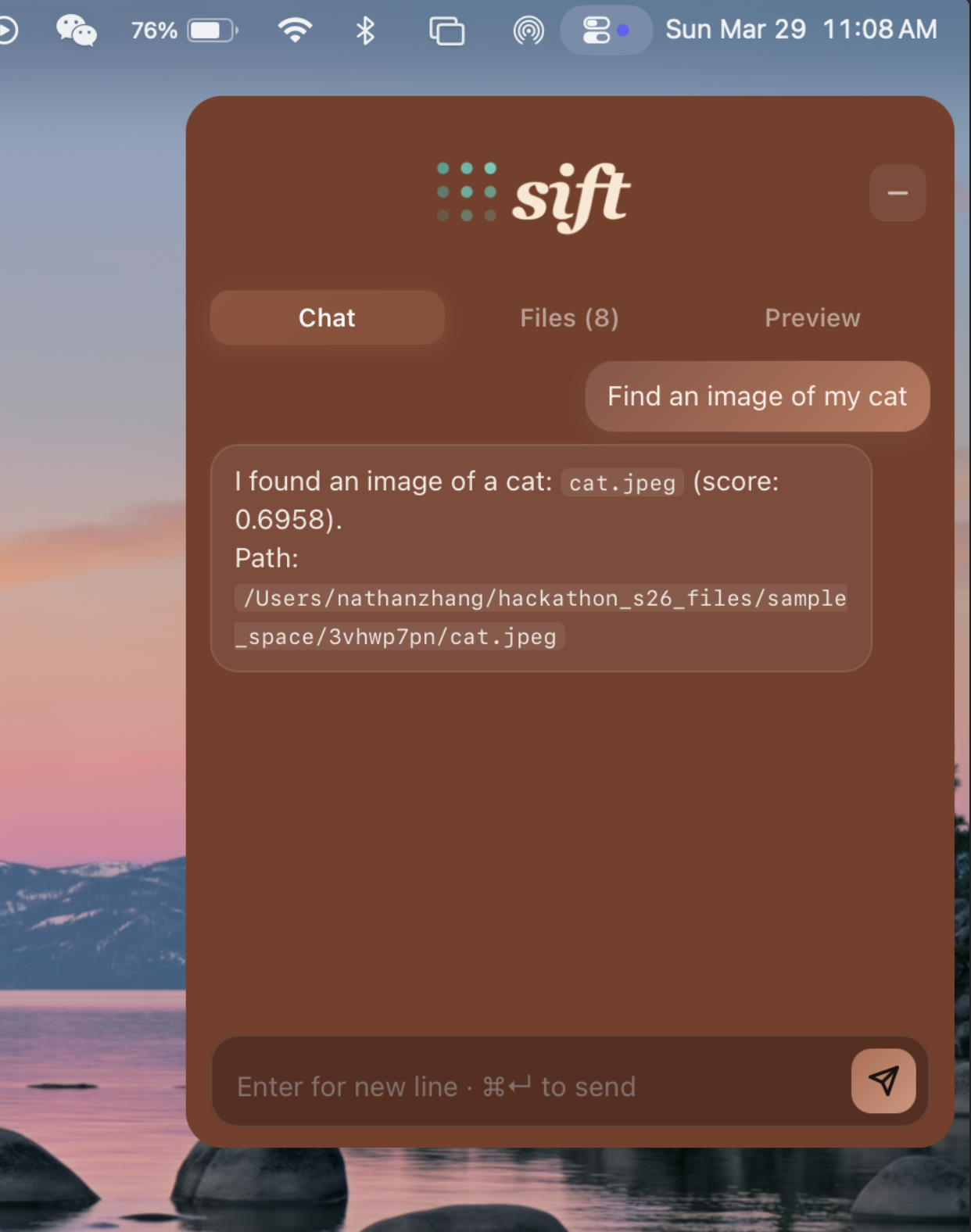
Semantically search for pictures, pdfs, etc.
-
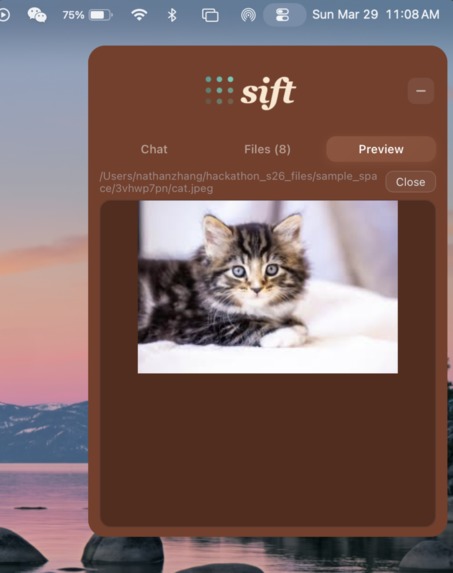
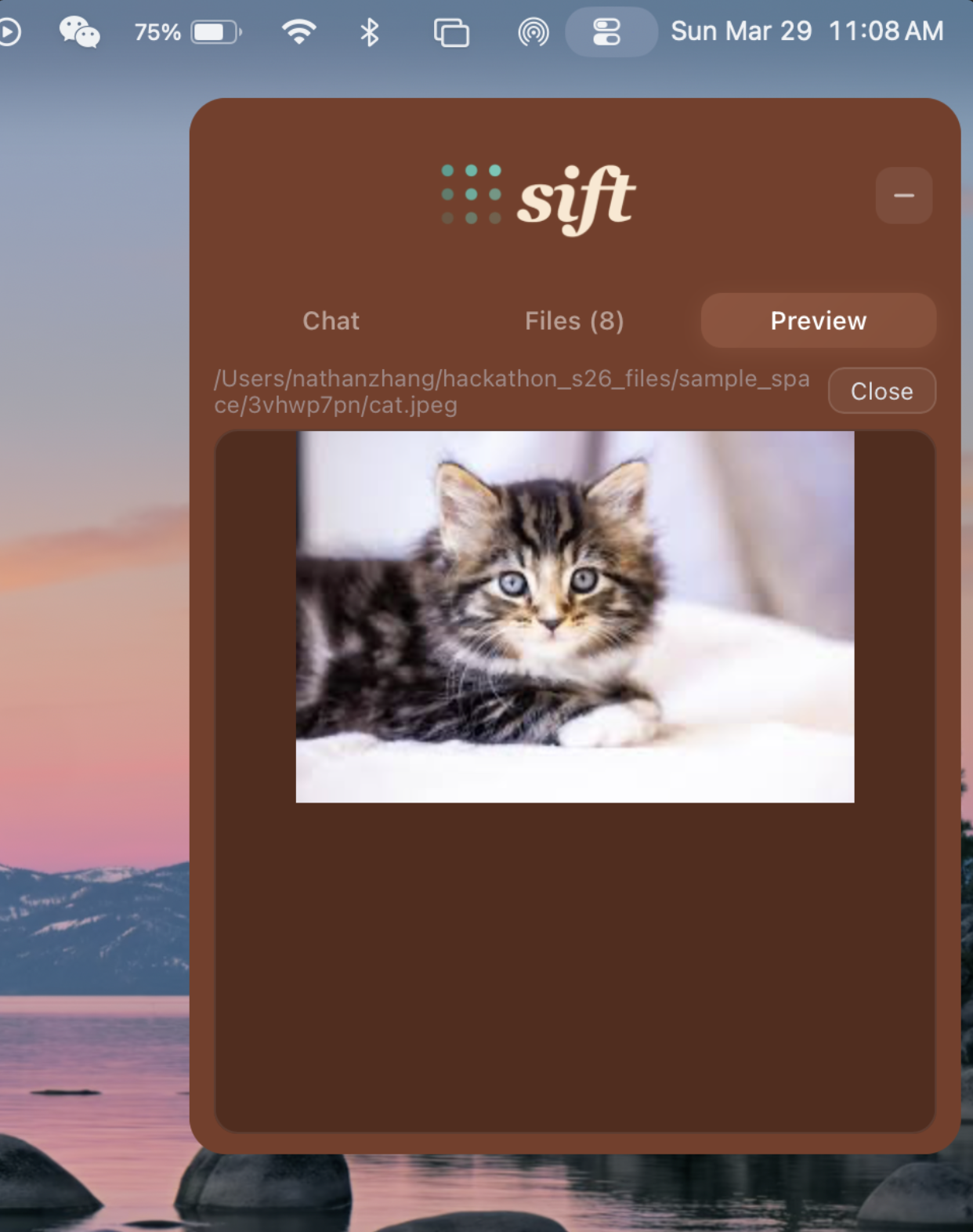
View pictures in our UI

Inspiration
We find embeddings fascinating, that a picture of a beach and a story describing a beach could have a similar representation in some embedding space. At the same time, finding files that have meaningless file names have always been really tedious. We believed that we could use the embeddings to streamline this process.
What it does
Sift indexes all your files into the same optimized embedding space. This allows us to semantically find the best match for any query across the board. Beyond that, we have functionality that allows us to manipulate files, create and execute plans to move, change, add, delete files, and also learn more about files through the power of GenAI.
How we built it
We built backend functionality first in Python, which includes embedding generation through Gemini Embedding 2 Preview, database storage and vector search through MongoDB Atlas, and chatbot functionality through LangChain. Our frontend functionality was built on the Tauri framework, and is powered by our backend through a FastAPI system that connects our frontend to the backend that we built.
Challenges we ran into
Learning MongoDB Atlas and setting up the database was challenging, but very rewarding. It was also all about making sure that each step was as efficient as possible and that the entire system is cohesive.
Accomplishments that we're proud of
We are very proud of our algorithm for being efficient, in that we index quickly and store our entries very efficiently. We are also proud of the broad range of functionality that it offers, such as being able to move, and learn about our documents beyond the searching part. We believe that this app could be genuinely helpful for many industries where people juggle lots of files and messy folders on their computer, such as in research labs, legal settings, and for students, where file management is very time consuming.
What we learned
Building a desktop experience on top of an API, embeddings, and a database taught us that a lot of things have to line up to ensure smooth sailing for the user. The UI, the local server, environment variables, python dependencies and other external services such as MongoDB and Gemini all have to agree and work together seamlessly. As programmers, we have to constantly trace through the full stack in order to find errors.
What's next for Sift
More tools to enhance learning and document explanations. We would target richer summaries and clearer citations back to the files the model used. We would support more files such as csv files or perhaps audio files. Support for more documents, like spreadsheets, audio recordings, etc.


Log in or sign up for Devpost to join the conversation.