


Sift
Inspiration
Anti-money-laundering teams are buried in alerts. The overwhelming majority are false positives — but every alert is a regulatory decision, and clearing the wrong one is a liability. The bottleneck isn't classification; it's judgment under asymmetry, where a missed launderer and a wasted analyst-hour are nowhere near equal in cost.
While building agentic systems, one thing kept bothering me about how we monitor them: observability is almost always post-hoc. We ship a decision, then open the trace later to understand what happened. But the question that actually matters in production triage isn't "what did the agent decide?" — it's:
How reliable has this agent been on cases like the one in front of it right now — and should it be deciding this alone at all?
That question can only be answered if the agent can read its own operational history while it reasons. Arize's Model Context Protocol server makes exactly that possible: it lets an agent query its own traces, evaluations, and experiments as runtime tools. Sift is built around inverting observability from a postmortem artifact into a live input to the decision itself.
What it does
Sift is an AML alert-triage agent built on a two-loop, self-observing architecture. It sorts incoming alerts into three actions:
- auto-clear — high-confidence non-laundering, closed without analyst time
- auto-escalate — high-confidence laundering, pushed to investigation
- route-to-analyst — an explicit abstention when the agent shouldn't decide alone
route-to-analyst is treated as a real "I don't know," not a failure. It's excluded from accuracy denominators, so the agent is never rewarded for confidently guessing on a case it should have deferred.
Three cooperating agents run the loop:
- A triage agent that makes the routing decision.
- A judge agent that grades the quality of the reasoning — blind to the true label.
- A lesson-consolidation agent that consolidates the rationales analysts attach to their dispositions and distills them into a lesson proposal that feeds the self-healing loop.
Correctness itself is never graded by an LLM — it's scored deterministically against ground truth (lBM AML Dataset ). That separation is the backbone of the whole system.
How I built it
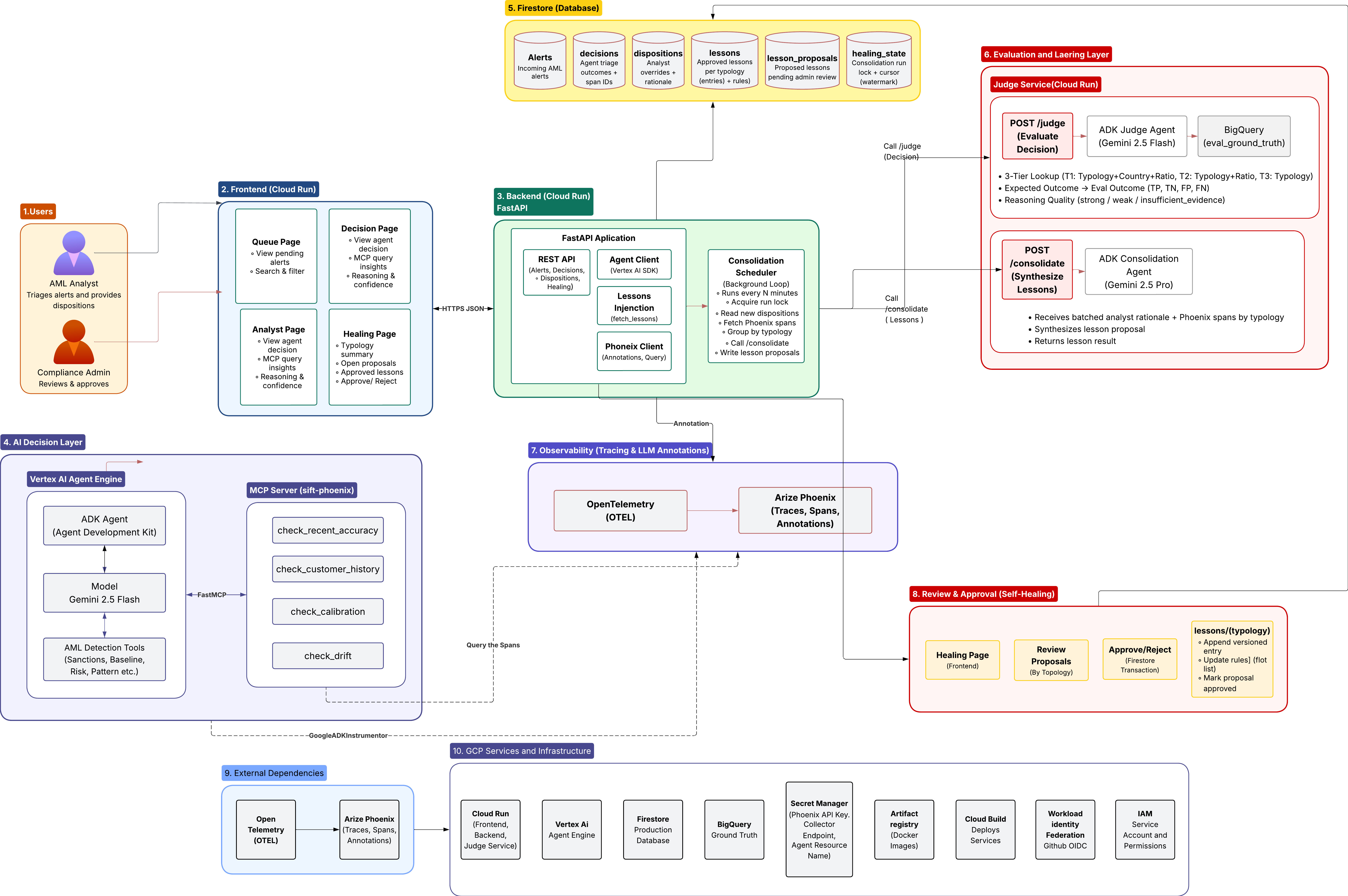
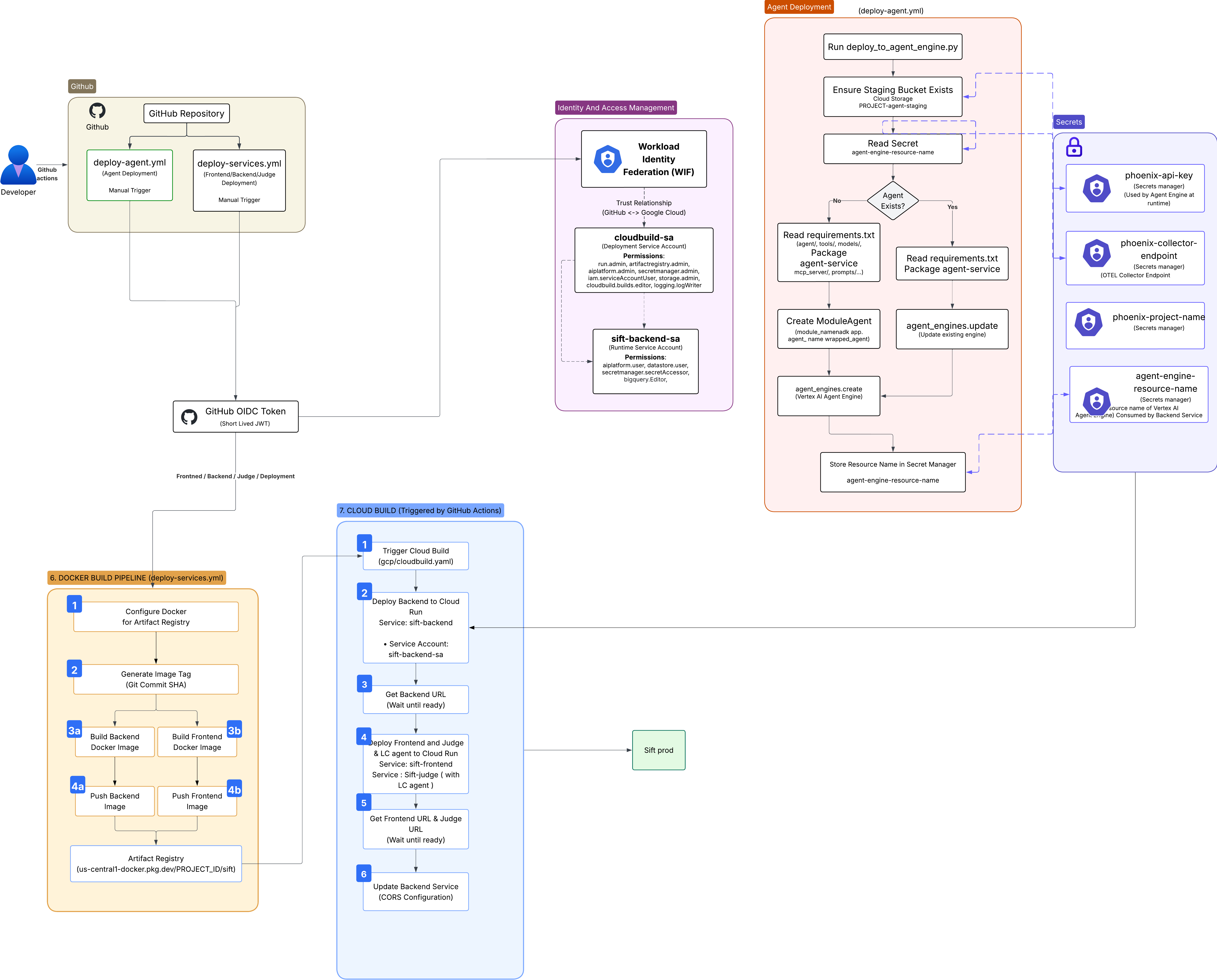
System architecture
- Gemini 2.5 Flash on the Google Agent Development Kit (ADK) — the high-volume triage agent.
- Gemini 2.5 Pro — the reasoning-quality judge and the lesson consolidation agent.
- Vertex AI (ADC) for authentication end-to-end.
- Cloud Run — hosted FastAPI backend.
- Firestore — live decision state.
- BigQuery — analytics and static ground truth.
- Arize Phoenix — tracing, annotation and evaluation, via OpenTelemetry / OpenInference.
- A thin Python FastMCP server — exposes Phoenix-backed tools to the agent at runtime.
- React + Vite + TypeScript + Tailwind — the triage, evaluation, and healing UI.
- IBM AML dataset (LI-Small) — used as ground truth.
Innovation 1 — The inner loop: observability as a reasoning input
Before the triage agent commits to a decision, it interrogates its own track record. Through the Phoenix MCP server it calls three tools mid-decision:
check_recent_accuracy— how often it's been right on recent, similar casescheck_calibration— whether its confidence has been earning its keepcheck_drift— whether the current input distribution still resembles what it was evaluated on
It uses those signals to calibrate how much confidence it's allowed to act on. Weak recent accuracy on a cohort, poor calibration, or detected drift all push the agent toward abstention (route-to-analyst) rather than an automated action. Observability stops being a dashboard and becomes a live guardrail the agent consults about itself.
Innovation 2 — Two orthogonal evaluations, kept deliberately separate
Every decision is annotated two independent ways on its call_llm span — and never allowed to bleed into each other:
reasoning_quality— the Gemini 2.5 Pro judge, blind to the ground-truth label, grading whether the agent's reasoning was sound.eval_outcome— deterministic Python, never LLM-graded, scoring the decision against IBM ground truth into a five-way confusion matrix.
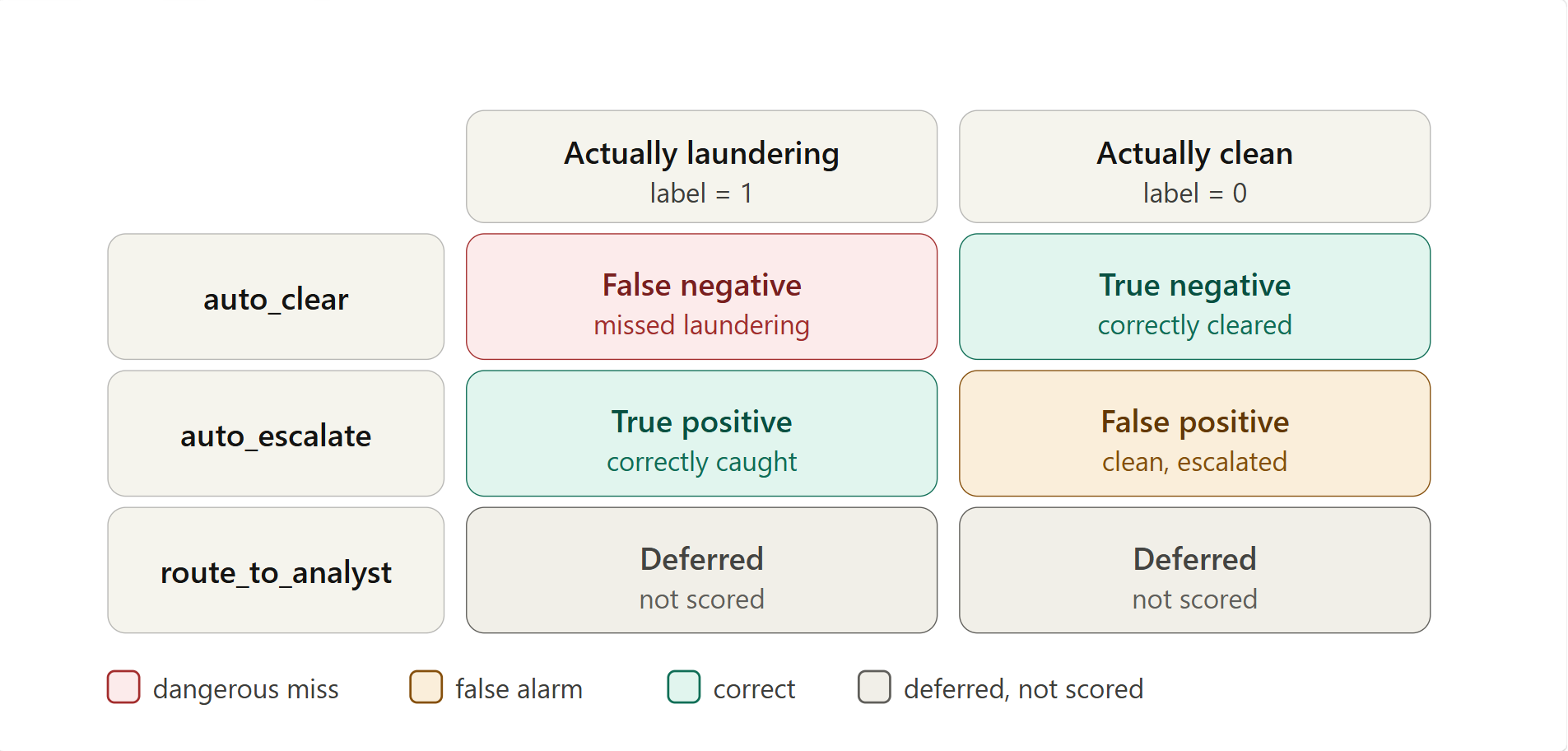
Every decision lands in exactly one cell, defined by the action the agent took versus what the transaction actually was:
true_positive— the agent auto-escalated a transaction that was genuinely laundering. Correctly caught.true_negative— the agent auto-cleared a transaction that was genuinely clean. Correctly cleared.false_negative— the agent auto-cleared a transaction that was actually laundering. The dangerous miss — the cell Sift is most conservative about, and the one self-healing is biased to reduce.false_positive— the agent auto-escalated a transaction that was actually clean. A false alarm: costly in analyst time, but not a regulatory miss.deferred— the agent chose route-to-analyst. Not scored either way, because the agent never claimed the decision.
That asymmetry — a false negative is a regulatory liability while a false positive is merely expensive — is precisely why conservative repairs (which shrink false negatives) can auto-apply while permissive ones (which risk new false negatives) stay human-gated.
Innovation 3 — The outer loop: asymmetric self-healing
The outer loop closes through the human. When an analyst resolves a case, they post a disposition — the correct outcome plus the rationale for it. As those dispositions accumulate, the scheduler will send the analyst's rationals to the lesson-consolidation agent which consolidates rationales into a single lesson proposal: a distilled, human-grounded statement of what the agent keeps getting wrong and why. That proposal is what drives the self-healing repair — so fixes are anchored in expert analyst reasoning, not just statistical drift in the numbers. Because AML risk is asymmetric, the resulting repairs are gated by direction:
- Conservative changes (catch more laundering) are lower regulatory risk and can auto-apply — but only after replay validation against a held dataset.
- Permissive changes (clear more alerts) carry real regulatory risk and require human approval before they ship.
And drift acts as a guard, not a trigger: if check_drift shows the input distribution has shifted enough to make the replay dataset unreliable, self-healing is blocked rather than allowed to "fix" the agent against stale evidence.
Challenges I ran into
1. Instrumenting Phoenix on Agent Engine — debugging blind. Getting Phoenix tracing to attach correctly to the agent running on Vertex AI Agent Engine was almost entirely trial and error, because misconfigurations didn't raise anything — they just produced missing, empty, or wrong spans. There was no stack trace to chase. One example: spans were silently being written as __REDACTED__, which would have quietly broken the inner loop since the agent self-queries those very spans, and nothing surfaced to flag it. Every fix meant changing one thing, re-running, and inspecting the resulting traces by hand to see whether it had actually worked.
2. No Python-native Phoenix MCP server. As far as I could find, Phoenix's MCP server was only available as a Node package — there was no Python-native option. Since the rest of the stack (and Agent Engine compatibility) was Python, I ended up building my own thin FastMCP server to expose Phoenix's trace and evaluation data as runtime tools the agent could call.
3. Agent Engine 429s (resource exhaustion). Agent Engine frequently returned 429 RESOURCE_EXHAUSTED errors under load. Because the inner loop issues extra self-querying calls on top of the triage call itself, the request volume per decision is higher than a normal agent's — so I kept hitting quota limits mid-decision and had to work around them rather than let triage calls fail.
4. Token cost from oversized Phoenix spans. Phoenix spans are large and richly nested, which made token optimization hard: feeding trace history back into the agent for inner-loop self-querying ballooned token usage fast. Trimming was awkward because the relevant signal was buried inside heavy span payloads, and getting the agent the context it needed without paying for the entire span remains an open optimization.
Accomplishments that I'm proud of
1. Observability as an active reasoning input. The agent literally consults its own past performance before deciding — not after.
2. Self-healing that respects regulatory asymmetry. Conservative fixes auto-apply after replay; permissive fixes are human-gated; drift blocks repair on stale data. The automation policy itself encodes the asymmetry of the domain.
3. Deterministic correctness, fully separated from LLM judgment. The accuracy reported is mechanically grounded against ground truth, not an LLM's opinion of itself.
4. Abstention as a first-class outcome. By excluding deferred cases from the denominator, the agent is measured only on the decisions it actually claims.
5. A multi-agent loop that closes under human control. Triage, judging, and lesson consolidation form a complete observe-evaluate-repair cycle — with a human in the loop exactly where the regulatory stakes demand it.
What I learned
- A distribution shift shouldn't cause a repair; it should block one, because the evidence you'd repair against is no longer trustworthy.
- The inner loop compensates per decision; the outer loop repairs the system. Both read aggregated trace data — the real distinction is per-decision vs. systematic, not single-span vs. aggregate.
- Asymmetric risk has to live in the automation policy, not just the metrics.
- The abstention is a signal, not an absence of one.
- Deterministic outcomes and label-blind reasoning quality stay orthogonal, so neither can launder the other's mistakes.
What's next for Sift
- Higher decision-reconstructability. Instrument decisions against an explicit governance question battery, so a trace doesn't just exist but provably answers "under what authority, and on what evidence, was this alert cleared?" — moving toward the record-keeping and traceability expectations that regulation (e.g. the EU AI Act) is converging on.
- Guarded prompt diffs. Have the lesson agent emit reviewable unified diffs that modify only adaptive sections of the prompt while leaving the agent's core identity immutable.
- Adaptive, SLO-aware thresholds. Tune the inner-loop confidence and drift thresholds dynamically based on live evaluation health rather than fixed cutoffs.
- A wider auto-apply envelope. As replay coverage grows, safely expand the set of conservative changes that can self-apply without human review — while never relaxing the gate on permissive ones.
Built With
- arize
- docker
- docker-compose
- fastmcp
- firestore
- google-adk
- google-agent-engine
- google-artifacts
- google-bigquery
- google-bucket
- google-cloud-build
- google-cloud-run
- google-iam
- google-secret-manager
- google-wif
- python
- react
- vertex-ai



Log in or sign up for Devpost to join the conversation.